

Viele verwenden spezielle Tools, um Verfahren zum Extrahieren, Transformieren und Laden von Daten in relationale Datenbanken zu erstellen. Der Prozess der Arbeitswerkzeuge wird protokolliert, Fehler werden behoben.
Im Fehlerfall enthält das Protokoll Informationen darüber, dass das Tool die Aufgabe nicht abschließen konnte und welche Module (oft Java) wo angehalten haben. In den letzten Zeilen finden Sie einen Datenbankfehler, beispielsweise eine Verletzung eines eindeutigen Tabellenschlüssels.
Um die Frage zu beantworten, welche Rolle ETL-Fehlerinformationen spielen, habe ich alle in den letzten zwei Jahren aufgetretenen Probleme in einem ziemlich großen Repository klassifiziert.
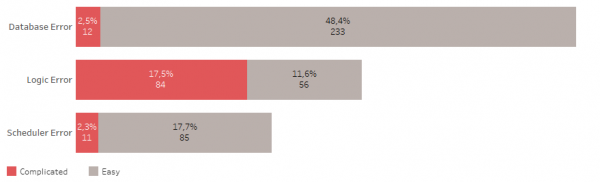
Zu den Datenbankfehlern gehören nicht genügend Speicherplatz, Verbindungsverlust, Sitzungsblockierung usw.
Zu den logischen Fehlern gehören beispielsweise die Verletzung von Tabellenschlüsseln, ungültige Objekte, fehlender Zugriff auf Objekte usw.
Der Planer startet möglicherweise nicht rechtzeitig, friert ein usw.
Einfache Fehler lassen sich schnell beheben. Ein gutes ETL kann die meisten davon alleine bewältigen.
Komplexe Fehler machen es erforderlich, Verfahren für die Arbeit mit Daten zu entdecken und zu testen, um Datenquellen zu erkunden. Dies führt häufig dazu, dass Änderungen getestet und bereitgestellt werden müssen.
Somit hängt die Hälfte aller Probleme mit der Datenbank zusammen. 48 % aller Fehler sind einfache Fehler.
Ein Drittel aller Probleme hängen mit der Änderung der Speicherlogik oder des Speichermodells zusammen, mehr als die Hälfte dieser Fehler sind komplex.
Und weniger als ein Viertel aller Probleme hängen mit dem Taskplaner zusammen, 18 % davon sind einfache Fehler.
Im Allgemeinen sind 22 % aller auftretenden Fehler komplex und ihre Korrektur erfordert die meiste Aufmerksamkeit und Zeit. Sie passieren etwa einmal pro Woche. Einfache Fehler hingegen passieren fast jeden Tag.
Es liegt auf der Hand, dass die Überwachung von ETL-Prozessen effektiv ist, wenn der Ort des Fehlers im Protokoll so genau wie möglich angegeben wird und die minimale Zeit benötigt wird, um die Ursache des Problems zu finden.
Effektive Überwachung
Was wollte ich im ETL-Überwachungsprozess sehen?
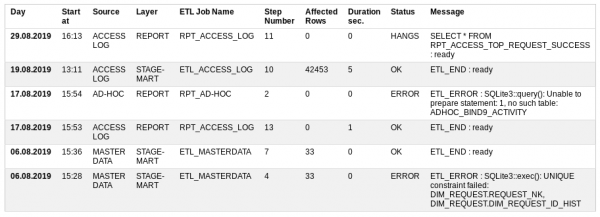
Beginnen Sie mit - als er mit der Arbeit begann,
Quelle – Datenquelle,
Layer – welche Speicherebene geladen wird,
ETL-Jobname – Upload-Vorgang, der aus vielen kleinen Schritten besteht,
Schrittnummer – die Nummer des ausgeführten Schritts,
Betroffene Zeilen – wie viele Daten bereits verarbeitet wurden,
Dauer Sek. – wie lange es dauert,
Status – ob alles in Ordnung ist oder nicht: OK, FEHLER, LÄUFT, HÄNGT
Nachricht – Letzte erfolgreiche Nachricht oder Fehlerbeschreibung.
Basierend auf dem Status der Datensätze können Sie eine E-Mail senden. Brief an andere Mitglieder. Wenn keine Fehler vorliegen, ist das Schreiben nicht erforderlich.
Somit ist im Fehlerfall eindeutig der Ort des Vorfalls angegeben.
Manchmal kommt es vor, dass das Überwachungstool selbst nicht funktioniert. In diesem Fall ist es möglich, direkt in der Datenbank eine Ansicht (View) aufzurufen, auf deren Grundlage der Bericht erstellt wird.
ETL-Überwachungstabelle
Um die Überwachung von ETL-Prozessen zu implementieren, genügen eine Tabelle und eine Ansicht.
Dazu können Sie zu zurückkehren und einen Prototyp in einer SQLite-Datenbank erstellen.
DDL-Tabellen
CREATE TABLE UTL_JOB_STATUS (
/* Table for logging of job execution log. Important that the job has the steps ETL_START and ETL_END or ETL_ERROR */
UTL_JOB_STATUS_ID INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
SID INTEGER NOT NULL DEFAULT -1, /* Session Identificator. Unique for every Run of job */
LOG_DT INTEGER NOT NULL DEFAULT 0, /* Date time */
LOG_D INTEGER NOT NULL DEFAULT 0, /* Date */
JOB_NAME TEXT NOT NULL DEFAULT 'N/A', /* Job name like JOB_STG2DM_GEO */
STEP_NAME TEXT NOT NULL DEFAULT 'N/A', /* ETL_START, ... , ETL_END/ETL_ERROR */
STEP_DESCR TEXT, /* Description of task or error message */
UNIQUE (SID, JOB_NAME, STEP_NAME)
);
INSERT INTO UTL_JOB_STATUS (UTL_JOB_STATUS_ID) VALUES (-1);DDL anzeigen/melden
CREATE VIEW IF NOT EXISTS UTL_JOB_STATUS_V
AS /* Content: Package Execution Log for last 3 Months. */
WITH SRC AS (
SELECT LOG_D,
LOG_DT,
UTL_JOB_STATUS_ID,
SID,
CASE WHEN INSTR(JOB_NAME, 'FTP') THEN 'TRANSFER' /* file transfer */
WHEN INSTR(JOB_NAME, 'STG') THEN 'STAGE' /* stage */
WHEN INSTR(JOB_NAME, 'CLS') THEN 'CLEANSING' /* cleansing */
WHEN INSTR(JOB_NAME, 'DIM') THEN 'DIMENSION' /* dimension */
WHEN INSTR(JOB_NAME, 'FCT') THEN 'FACT' /* fact */
WHEN INSTR(JOB_NAME, 'ETL') THEN 'STAGE-MART' /* data mart */
WHEN INSTR(JOB_NAME, 'RPT') THEN 'REPORT' /* report */
ELSE 'N/A' END AS LAYER,
CASE WHEN INSTR(JOB_NAME, 'ACCESS') THEN 'ACCESS LOG' /* source */
WHEN INSTR(JOB_NAME, 'MASTER') THEN 'MASTER DATA' /* source */
WHEN INSTR(JOB_NAME, 'AD-HOC') THEN 'AD-HOC' /* source */
ELSE 'N/A' END AS SOURCE,
JOB_NAME,
STEP_NAME,
CASE WHEN STEP_NAME='ETL_START' THEN 1 ELSE 0 END AS START_FLAG,
CASE WHEN STEP_NAME='ETL_END' THEN 1 ELSE 0 END AS END_FLAG,
CASE WHEN STEP_NAME='ETL_ERROR' THEN 1 ELSE 0 END AS ERROR_FLAG,
STEP_NAME || ' : ' || STEP_DESCR AS STEP_LOG,
SUBSTR( SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), 1, INSTR(SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), '***')-2 ) AS AFFECTED_ROWS
FROM UTL_JOB_STATUS
WHERE datetime(LOG_D, 'unixepoch') >= date('now', 'start of month', '-3 month')
)
SELECT JB.SID,
JB.MIN_LOG_DT AS START_DT,
strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS LOG_DT,
JB.SOURCE,
JB.LAYER,
JB.JOB_NAME,
CASE
WHEN JB.ERROR_FLAG = 1 THEN 'ERROR'
WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 AND strftime('%s','now') - JB.MIN_LOG_DT > 0.5*60*60 THEN 'HANGS' /* half an hour */
WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 THEN 'RUNNING'
ELSE 'OK'
END AS STATUS,
ERR.STEP_LOG AS STEP_LOG,
JB.CNT AS STEP_CNT,
JB.AFFECTED_ROWS AS AFFECTED_ROWS,
strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS JOB_START_DT,
strftime('%d.%m.%Y %H:%M', datetime(JB.MAX_LOG_DT, 'unixepoch')) AS JOB_END_DT,
JB.MAX_LOG_DT - JB.MIN_LOG_DT AS JOB_DURATION_SEC
FROM
( SELECT SID, SOURCE, LAYER, JOB_NAME,
MAX(UTL_JOB_STATUS_ID) AS UTL_JOB_STATUS_ID,
MAX(START_FLAG) AS START_FLAG,
MAX(END_FLAG) AS END_FLAG,
MAX(ERROR_FLAG) AS ERROR_FLAG,
MIN(LOG_DT) AS MIN_LOG_DT,
MAX(LOG_DT) AS MAX_LOG_DT,
SUM(1) AS CNT,
SUM(IFNULL(AFFECTED_ROWS, 0)) AS AFFECTED_ROWS
FROM SRC
GROUP BY SID, SOURCE, LAYER, JOB_NAME
) JB,
( SELECT UTL_JOB_STATUS_ID, SID, JOB_NAME, STEP_LOG
FROM SRC
WHERE 1 = 1
) ERR
WHERE 1 = 1
AND JB.SID = ERR.SID
AND JB.JOB_NAME = ERR.JOB_NAME
AND JB.UTL_JOB_STATUS_ID = ERR.UTL_JOB_STATUS_ID
ORDER BY JB.MIN_LOG_DT DESC, JB.SID DESC, JB.SOURCE;SQL prüft, ob es möglich ist, eine neue Sitzungsnummer zu erhalten
SELECT SUM (
CASE WHEN start_job.JOB_NAME IS NOT NULL AND end_job.JOB_NAME IS NULL /* existed job finished */
AND NOT ( 'y' = 'n' ) /* force restart PARAMETER */
THEN 1 ELSE 0
END ) AS IS_RUNNING
FROM
( SELECT 1 AS dummy FROM UTL_JOB_STATUS WHERE sid = -1) d_job
LEFT OUTER JOIN
( SELECT JOB_NAME, SID, 1 AS dummy
FROM UTL_JOB_STATUS
WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */
AND STEP_NAME = 'ETL_START'
GROUP BY JOB_NAME, SID
) start_job /* starts */
ON d_job.dummy = start_job.dummy
LEFT OUTER JOIN
( SELECT JOB_NAME, SID
FROM UTL_JOB_STATUS
WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */
AND STEP_NAME in ('ETL_END', 'ETL_ERROR') /* stop status */
GROUP BY JOB_NAME, SID
) end_job /* ends */
ON start_job.JOB_NAME = end_job.JOB_NAME
AND start_job.SID = end_job.SIDTischmerkmale:
- Auf den Beginn und das Ende des Datenverarbeitungsvorgangs müssen die Schritte ETL_START und ETL_END folgen
- Im Fehlerfall sollte der Schritt ETL_ERROR mit seiner Beschreibung erstellt werden
- Die Menge der verarbeiteten Daten sollte beispielsweise durch Sternchen hervorgehoben werden
- Mit dem Parameter force_restart=y kann die gleiche Prozedur gleichzeitig gestartet werden, ohne ihn wird die Sitzungsnummer nur an die abgeschlossene Prozedur vergeben
- Im Normalmodus können Sie denselben Datenverarbeitungsvorgang nicht parallel ausführen
Die notwendigen Vorgänge zum Arbeiten mit einer Tabelle sind wie folgt:
- Abrufen der Sitzungsnummer der laufenden ETL-Prozedur
- Protokolleintrag in Tabelle einfügen
- Abrufen des letzten erfolgreichen Datensatzes einer ETL-Prozedur
In Datenbanken wie Oracle oder Postgres können diese Operationen als integrierte Funktionen implementiert werden. SQLite erfordert einen externen Mechanismus, und in diesem Fall diesen .
Abschluss
Daher spielen Fehlermeldungen in Datenverarbeitungstools eine überaus wichtige Rolle. Es ist jedoch schwierig, sie als optimal zu bezeichnen, um die Ursache des Problems schnell zu finden. Wenn die Zahl der Eingriffe auf die Hundert zugeht, wird die Prozessüberwachung zu einem komplexen Projekt.
Der Artikel liefert ein Beispiel für eine mögliche Lösung des Problems in Form eines Prototyps. Der gesamte Prototyp des kleinen Repositorys ist in Gitlab verfügbar .
Source: habr.com
