

Ingenieur – aus dem Lateinischen übersetzt – inspiriert.
Ein Ingenieur kann alles. (c) R. Diesel.
Epigraphen.

Oder eine Geschichte darüber, warum sich ein Datenbankadministrator an seine Programmiervergangenheit erinnern muss.
Vorwort
Alle Namen wurden geändert. Übereinstimmungen sind zufällig. Das Material stellt ausschließlich die persönliche Meinung des Autors dar.
Gewährleistungsausschluss: In der geplanten Artikelserie wird es keine detaillierte und genaue Beschreibung der verwendeten Tabellen und Skripte geben. Materialien können nicht sofort „WIE BESEHEN“ verwendet werden.
Erstens aufgrund der großen Menge an Material,
Zweitens aufgrund der Schärfe mit der Produktionsbasis eines echten Kunden.
Daher werden in den Artikeln nur Ideen und Beschreibungen in allgemeinster Form gegeben.
Vielleicht wird das System in Zukunft auf das Niveau der Veröffentlichung auf GitHub heranwachsen, vielleicht auch nicht. Die Zeit wird zeigen.
Der Anfang der Geschichte-".
Was als Ergebnis geschah, kann man ganz allgemein sagen: „»
Warum brauche ich das alles?
Nun, erstens, um sich selbst nicht zu vergessen und sich an die herrlichen Tage im Ruhestand zu erinnern.
Zweitens, um das Geschriebene zu systematisieren. Denn ich selbst fange manchmal an, verwirrt zu sein und einzelne Teile zu vergessen.
Nun, und das Wichtigste: Plötzlich kann es für jemanden nützlich sein und dabei helfen, das Rad nicht neu zu erfinden und keinen Rechen einzusammeln. Mit anderen Worten: Verbessern Sie Ihr Karma (nicht Khabrovsky). Denn das Wertvollste auf dieser Welt sind Ideen. Die Hauptsache ist, eine Idee zu finden. Und die Idee in die Realität umzusetzen, ist bereits eine rein technische Angelegenheit.
Fangen wir also langsam an...
Formulierung des Problems.
Es gibt:
PostgreSQL(10.5), gemischte Last (OLTP+DSS), mittlere bis leichte Last, gehostet in der AWS-Cloud.
Es gibt keine Datenbanküberwachung, die Infrastrukturüberwachung wird als Standard-AWS-Tools in einer minimalen Konfiguration dargestellt.
benötigt:
Überwachen Sie die Leistung und den Status der Datenbank, finden Sie erste Informationen und verfügen Sie über diese, um umfangreiche Datenbankabfragen zu optimieren.
Kurze Einführung oder Analyse von Lösungen
Versuchen wir zunächst, die Möglichkeiten zur Lösung des Problems unter dem Gesichtspunkt einer vergleichenden Analyse der Vorteile und Probleme für den Ingenieur zu analysieren und diejenigen, die auf der Personalliste stehen sollen, mit den Vorteilen und Verlusten befassen zu lassen des Managements.
Option 1 – „Arbeiten auf Abruf“
Wir lassen alles so wie es ist. Wenn der Kunde mit dem Zustand, der Leistung der Datenbank oder der Anwendung nicht zufrieden ist, benachrichtigt er die DBA-Ingenieure per E-Mail oder durch Erstellen eines Vorfalls im Ticketfeld.
Ein Ingenieur, der eine Benachrichtigung erhalten hat, wird das Problem verstehen, eine Lösung anbieten oder das Problem auf Eis legen, in der Hoffnung, dass sich alles von selbst löst und dass alles bald vergessen wird.
Lebkuchen und Donuts, blaue Flecken und BeulenLebkuchen und Donuts:
1. Es gibt nichts extra zu tun
2. Es gibt immer die Möglichkeit rauszugehen und sich schmutzig zu machen.
3. Viel Zeit, die Sie alleine verbringen können.
Prellungen und Beulen:
1. Früher oder später wird der Kunde über das Wesen des Seins und der universellen Gerechtigkeit in dieser Welt nachdenken und sich erneut die Frage stellen: Warum zahle ich ihm mein Geld? Die Konsequenz ist immer die gleiche – die einzige Frage ist, wann sich der Kunde langweilt und zum Abschied winkt. Und der Feeder ist leer. Es ist traurig.
2. Die Entwicklung eines Ingenieurs ist Null.
3. Schwierigkeiten bei der Arbeits- und Ladeplanung
Option 2 – „Mit Tamburinen tanzen, Schuhe anziehen und anziehen“
Absatz 1-Warum brauchen wir ein Überwachungssystem? Wir werden alle Anfragen erhalten. Wir starten eine Reihe aller möglichen Abfragen an das Datenwörterbuch und dynamische Ansichten, aktivieren alle möglichen Zähler, bringen alles in Tabellen und analysieren sozusagen regelmäßig Listen und Tabellen. Als Ergebnis erhalten wir schöne oder weniger schöne Grafiken, Tabellen und Berichte. Hauptsache, das wäre mehr, mehr.
Absatz 2-Generieren Sie Aktivitäten – führen Sie die Analyse all dessen durch.
Absatz 3-Wir bereiten ein bestimmtes Dokument vor, wir nennen dieses Dokument einfach: „Wie statten wir die Datenbank aus?“
Absatz 4- Der Kunde, der all diese Pracht an Grafiken und Zahlen sieht, ist in einer kindisch-naiven Zuversicht: Jetzt wird bei uns bald alles klappen. Und sich einfach und schmerzlos von ihren finanziellen Ressourcen trennen. Das Management ist sich auch sicher, dass unsere Ingenieure hart arbeiten. Maximale Belastung.
Absatz 5- Wiederholen Sie Schritt 1 regelmäßig.
Lebkuchen und Donuts, blaue Flecken und BeulenLebkuchen und Donuts:
1. Das Leben von Managern und Ingenieuren ist einfach, vorhersehbar und voller Aktivität. Alles brummt, alle sind beschäftigt.
2. Das Leben des Kunden ist auch nicht schlecht – er ist sich immer sicher, dass man sich ein wenig gedulden muss und alles gut wird. Es wird nicht besser, na ja, diese Welt ist ungerecht, im nächsten Leben wirst du Glück haben.
Prellungen und Beulen:
1. Früher oder später wird es einen intelligenteren Anbieter eines ähnlichen Dienstes geben, der das Gleiche tut, aber etwas günstiger. Und wenn das Ergebnis das gleiche ist, warum dann mehr bezahlen? Was wiederum zum Verschwinden des Feeders führen wird.
2. Es ist langweilig. Wie langweilig jede kleine sinnvolle Aktivität.
3. Wie in der Vorgängerversion – keine Entwicklung. Für einen Ingenieur besteht der Nachteil jedoch darin, dass Sie hier im Gegensatz zur ersten Option ständig eine IDB generieren müssen. Und das braucht Zeit. Die Sie zum Wohle Ihrer Liebsten ausgeben können. Denn du kannst nicht auf dich selbst aufpassen, jeder kümmert sich um dich.
Option 3 – Sie müssen kein Fahrrad erfinden, Sie müssen es kaufen und damit fahren.
Ingenieure anderer Unternehmen essen bewusst Pizza mit Bier (oh, die glorreichen Zeiten von St. Petersburg in den 90er Jahren). Lassen Sie uns Überwachungssysteme verwenden, die erstellt, debuggt und funktionieren und im Allgemeinen Vorteile bringen (zumindest für ihre Entwickler).
Lebkuchen und Donuts, blaue Flecken und BeulenLebkuchen und Donuts:
1. Sie müssen keine Zeit damit verschwenden, bereits Erfundenes zu erfinden. Nehmen und verwenden.
2. Überwachungssysteme werden nicht von Dummköpfen geschrieben und sind natürlich nützlich.
3. Funktionierende Überwachungssysteme liefern normalerweise nützliche gefilterte Informationen.
Prellungen und Beulen:
1. Der Ingenieur ist in diesem Fall kein Ingenieur, sondern nur ein Benutzer des Produkts eines anderen. Oder ein Benutzer.
2. Der Kunde muss von der Notwendigkeit überzeugt sein, etwas zu kaufen, das er im Allgemeinen nicht verstehen möchte, und das sollte er auch nicht, und im Allgemeinen ist das Budget für das Jahr genehmigt und wird sich nicht ändern. Dann müssen Sie eine separate Ressource zuweisen und sie für ein bestimmtes System konfigurieren. Diese. Zuerst müssen Sie bezahlen, bezahlen und noch einmal bezahlen. Und der Kunde ist geizig. Das ist die Norm dieses Lebens.
Was tun, Tschernyschewski? Ihre Frage ist sehr relevant. (Mit)
In diesem speziellen Fall und der aktuellen Situation können Sie etwas anders vorgehen – Lassen Sie uns unser eigenes Überwachungssystem erstellen.

Na ja, natürlich kein System im wahrsten Sinne des Wortes, das ist zu laut und anmaßend, aber machen Sie es sich zumindest irgendwie leichter und sammeln Sie mehr Informationen, um Leistungsvorfälle zu lösen. Um nicht in eine Situation zu geraten: „Geh dorthin, ich weiß nicht wo, finde das, ich weiß nicht was.“
Was sind die Vor- und Nachteile dieser Option:
Profis:
1. Es ist interessant. Na ja, zumindest interessanter als das ständige „Datendatei verkleinern, Tablespace ändern usw.“
2. Dies sind neue Fähigkeiten und neue Entwicklungen. Was in Zukunft früher oder später wohlverdiente Lebkuchen und Donuts bescheren wird.
Nachteile:
1. Muss arbeiten. Viel arbeiten.
2. Sie müssen regelmäßig die Bedeutung und Perspektiven aller Aktivitäten erläutern.
3. Es muss etwas geopfert werden, denn die einzige dem Ingenieur zur Verfügung stehende Ressource – Zeit – ist durch das Universum begrenzt.
4. Das Schlimmste und Unangenehmste - Dadurch kann Müll entstehen wie „Keine Maus, kein Frosch, sondern ein unbekanntes kleines Tier“.
Wer nichts riskiert, trinkt keinen Champagner.
So, der Spaß beginnt.
Allgemeine Idee – schematisch
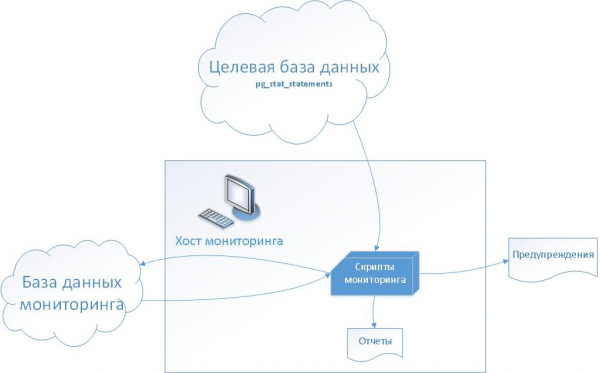
(Abbildung aus Artikel entnommen «")
Erklärung:
- Die Zieldatenbank wird mit der Standard-PostgreSQL-Erweiterung „pg_stat_statements“ installiert.
- In der Überwachungsdatenbank erstellen wir eine Reihe von Servicetabellen, um den pg_stat_statements-Verlauf in der Anfangsphase zu speichern und in der Zukunft Metriken und Überwachung zu konfigurieren
- Auf dem Überwachungshost erstellen wir eine Reihe von Bash-Skripten, darunter solche zum Generieren von Vorfällen im Ticketsystem.
Servicetische
Zunächst ein schematisch vereinfachtes ERD, was am Ende passiert ist:
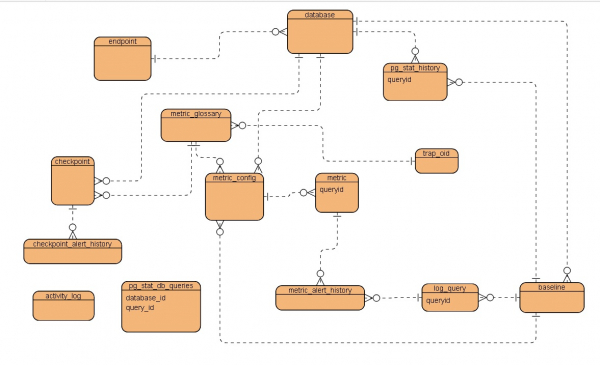
Kurze Beschreibung der TabellenEndpunkt - Host, Verbindungspunkt zur Instanz
Datenbank - Datenbankoptionen
pg_stat_history – eine historische Tabelle zum Speichern temporärer Snapshots der pg_stat_statements-Ansicht der Zieldatenbank
metric_glossary - Wörterbuch der Leistungsmetriken
metric_config - Konfiguration einzelner Metriken
Metrisch – eine spezifische Metrik für die Anfrage, die überwacht wird
metric_alert_history - Verlauf der Leistungswarnungen
log_query – Servicetabelle zum Speichern geparster Datensätze aus der von AWS heruntergeladenen PostgreSQL-Protokolldatei
Baseline - Parameter des als Basis verwendeten Zeitraums
Kontrollpunkt - Konfiguration von Metriken zur Überprüfung des Status der Datenbank
checkpoint_alert_history - Warnverlauf der Datenbankstatus-Prüfmetriken
pg_stat_db_queries — Diensttabelle der aktiven Anfragen
Aktivitätsprotokoll – Aktivitätsprotokoll-Diensttabelle
trap_oid - Trap-Konfigurationsdiensttabelle
Stufe 1 – Leistungsstatistiken sammeln und Berichte abrufen
Eine Tabelle wird zum Speichern statistischer Informationen verwendet. pg_stat_history
pg_stat_history-Tabellenstruktur
Tabelle „public.pg_stat_history“ Spalte | Typ | Modifikatoren--------------------+--------+---- ---------------------------------ID | Ganzzahl | nicht null Standard nextval('pg_stat_history_id_seq'::regclass) snapshot_timestamp | Zeitstempel ohne Zeitzone | Datenbank_ID | Ganzzahl | dbid | oid | Benutzer-ID | oid | Abfrage-ID | bigint | Abfrage | Text | Anrufe | bigint | total_time | doppelte Präzision | min_time | doppelte Präzision | max_time | doppelte Präzision | mittlere_zeit | doppelte Präzision | stddev_time | doppelte Präzision | Reihen | bigint | shared_blks_hit | bigint | shared_blks_read | bigint | shared_blks_dirtied | bigint | shared_blks_geschrieben | bigint | local_blks_hit | bigint | local_blks_read | bigint | local_blks_dirtied | bigint | local_blks_geschrieben | bigint | temp_blks_read | bigint | temp_blks_geschrieben | bigint | blk_read_time | doppelte Präzision | blk_write_time | doppelte Präzision | baseline_id | Ganzzahl | Indizes: „pg_stat_history_pkey“ PRIMARY KEY, btree (id) „database_idx“ btree (database_id) „queryid_idx“ btree (queryid) „snapshot_timestamp_idx“ btree (snapshot_timestamp) Fremdschlüsseleinschränkungen: „database_id_fk“ FOREIGN KEY (database_id) REFERENZEN Datenbank(id). ) AUF DELETE CASCADEWie Sie sehen, handelt es sich bei der Tabelle nur um eine kumulative Datenansicht pg_stat_statements in der Zieldatenbank.
Die Verwendung dieser Tabelle ist sehr einfach.
pg_stat_history stellt die gesammelten Statistiken der Abfrageausführung für jede Stunde dar. Zu Beginn jeder Stunde, nach dem Ausfüllen der Tabelle, Statistiken pg_stat_statements zurücksetzen mit pg_stat_statements_reset().
Hinweis: Statistiken werden für Anfragen mit einer Dauer von mehr als 1 Sekunde erfasst.
Füllen der pg_stat_history-Tabelle
--pg_stat_history.sql
CREATE OR REPLACE FUNCTION pg_stat_history( ) RETURNS boolean AS $$
DECLARE
endpoint_rec record ;
database_rec record ;
pg_stat_snapshot record ;
current_snapshot_timestamp timestamp without time zone;
BEGIN
current_snapshot_timestamp = date_trunc('minute',now());
FOR endpoint_rec IN SELECT * FROM endpoint
LOOP
FOR database_rec IN SELECT * FROM database WHERE endpoint_id = endpoint_rec.id
LOOP
RAISE NOTICE 'NEW SHAPSHOT IS CREATING';
--Connect to the target DB
EXECUTE 'SELECT dblink_connect(''LINK1'',''host='||endpoint_rec.host||' dbname='||database_rec.name||' user=USER password=PASSWORD '')';
RAISE NOTICE 'host % and dbname % ',endpoint_rec.host,database_rec.name;
RAISE NOTICE 'Creating snapshot of pg_stat_statements for database %',database_rec.name;
SELECT
*
INTO
pg_stat_snapshot
FROM dblink('LINK1',
'SELECT
dbid , SUM(calls),SUM(total_time),SUM(rows) ,SUM(shared_blks_hit) ,SUM(shared_blks_read) ,SUM(shared_blks_dirtied) ,SUM(shared_blks_written) ,
SUM(local_blks_hit) , SUM(local_blks_read) , SUM(local_blks_dirtied) , SUM(local_blks_written) , SUM(temp_blks_read) , SUM(temp_blks_written) , SUM(blk_read_time) , SUM(blk_write_time)
FROM pg_stat_statements WHERE dbid=(SELECT oid from pg_database where datname=current_database() )
GROUP BY dbid
'
)
AS t
( dbid oid , calls bigint ,
total_time double precision ,
rows bigint , shared_blks_hit bigint , shared_blks_read bigint ,shared_blks_dirtied bigint ,shared_blks_written bigint ,
local_blks_hit bigint ,local_blks_read bigint , local_blks_dirtied bigint ,local_blks_written bigint ,
temp_blks_read bigint ,temp_blks_written bigint ,
blk_read_time double precision , blk_write_time double precision
);
INSERT INTO pg_stat_history
(
snapshot_timestamp ,database_id ,
dbid , calls ,total_time ,
rows ,shared_blks_hit ,shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,local_blks_hit ,
local_blks_read,local_blks_dirtied,local_blks_written,temp_blks_read,temp_blks_written,
blk_read_time, blk_write_time
)
VALUES
(
current_snapshot_timestamp ,
database_rec.id ,
pg_stat_snapshot.dbid ,pg_stat_snapshot.calls,
pg_stat_snapshot.total_time,
pg_stat_snapshot.rows ,pg_stat_snapshot.shared_blks_hit ,pg_stat_snapshot.shared_blks_read ,pg_stat_snapshot.shared_blks_dirtied ,pg_stat_snapshot.shared_blks_written ,
pg_stat_snapshot.local_blks_hit , pg_stat_snapshot.local_blks_read , pg_stat_snapshot.local_blks_dirtied , pg_stat_snapshot.local_blks_written ,
pg_stat_snapshot.temp_blks_read , pg_stat_snapshot.temp_blks_written , pg_stat_snapshot.blk_read_time , pg_stat_snapshot.blk_write_time
);
RAISE NOTICE 'Creating snapshot of pg_stat_statements for queries with min_time more than 1000ms';
FOR pg_stat_snapshot IN
--All queries with max_time greater than 1000 ms
SELECT
*
FROM dblink('LINK1',
'SELECT
dbid , userid ,queryid,query,calls,total_time,min_time ,max_time,mean_time, stddev_time ,rows ,shared_blks_hit ,
shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,
local_blks_hit , local_blks_read , local_blks_dirtied ,
local_blks_written , temp_blks_read , temp_blks_written , blk_read_time ,
blk_write_time
FROM pg_stat_statements
WHERE dbid=(SELECT oid from pg_database where datname=current_database() AND min_time >= 1000 )
'
)
AS t
( dbid oid , userid oid , queryid bigint ,query text , calls bigint ,
total_time double precision ,min_time double precision ,max_time double precision , mean_time double precision , stddev_time double precision ,
rows bigint , shared_blks_hit bigint , shared_blks_read bigint ,shared_blks_dirtied bigint ,shared_blks_written bigint ,
local_blks_hit bigint ,local_blks_read bigint , local_blks_dirtied bigint ,local_blks_written bigint ,
temp_blks_read bigint ,temp_blks_written bigint ,
blk_read_time double precision , blk_write_time double precision
)
LOOP
INSERT INTO pg_stat_history
(
snapshot_timestamp ,database_id ,
dbid ,userid , queryid , query , calls ,total_time ,min_time ,max_time ,mean_time ,stddev_time ,
rows ,shared_blks_hit ,shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,local_blks_hit ,
local_blks_read,local_blks_dirtied,local_blks_written,temp_blks_read,temp_blks_written,
blk_read_time, blk_write_time
)
VALUES
(
current_snapshot_timestamp ,
database_rec.id ,
pg_stat_snapshot.dbid ,pg_stat_snapshot.userid ,pg_stat_snapshot.queryid,pg_stat_snapshot.query,pg_stat_snapshot.calls,
pg_stat_snapshot.total_time,pg_stat_snapshot.min_time ,pg_stat_snapshot.max_time,pg_stat_snapshot.mean_time, pg_stat_snapshot.stddev_time ,
pg_stat_snapshot.rows ,pg_stat_snapshot.shared_blks_hit ,pg_stat_snapshot.shared_blks_read ,pg_stat_snapshot.shared_blks_dirtied ,pg_stat_snapshot.shared_blks_written ,
pg_stat_snapshot.local_blks_hit , pg_stat_snapshot.local_blks_read , pg_stat_snapshot.local_blks_dirtied , pg_stat_snapshot.local_blks_written ,
pg_stat_snapshot.temp_blks_read , pg_stat_snapshot.temp_blks_written , pg_stat_snapshot.blk_read_time , pg_stat_snapshot.blk_write_time
);
END LOOP;
PERFORM dblink_disconnect('LINK1');
END LOOP ;--FOR database_rec IN SELECT * FROM database WHERE endpoint_id = endpoint_rec.id
END LOOP;
RETURN TRUE;
END
$$ LANGUAGE plpgsql;Dadurch wird nach einer gewissen Zeit in der Tabelle angezeigt pg_stat_history Wir werden eine Reihe von Schnappschüssen des Inhalts der Tabelle haben pg_stat_statements Zieldatenbank.
Eigentlich berichten
Mit einfachen Abfragen können Sie sehr nützliche und interessante Berichte erhalten.
Aggregierte Daten für einen bestimmten Zeitraum
Wunsch
SELECT
database_id ,
SUM(calls) AS calls ,SUM(total_time) AS total_time ,
SUM(rows) AS rows , SUM(shared_blks_hit) AS shared_blks_hit,
SUM(shared_blks_read) AS shared_blks_read ,
SUM(shared_blks_dirtied) AS shared_blks_dirtied,
SUM(shared_blks_written) AS shared_blks_written ,
SUM(local_blks_hit) AS local_blks_hit ,
SUM(local_blks_read) AS local_blks_read ,
SUM(local_blks_dirtied) AS local_blks_dirtied ,
SUM(local_blks_written) AS local_blks_written,
SUM(temp_blks_read) AS temp_blks_read,
SUM(temp_blks_written) temp_blks_written ,
SUM(blk_read_time) AS blk_read_time ,
SUM(blk_write_time) AS blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY database_id ;D.B. Zeit
to_char(Intervall '1 Millisekunde' * pg_total_stat_history_rec.total_time, 'HH24:MI:SS.MS')
E/A-Zeit
to_char(Intervall '1 Millisekunde' * ( pg_total_stat_history_rec.blk_read_time + pg_total_stat_history_rec.blk_write_time ), 'HH24:MI:SS.MS')
TOP10 SQL von total_time
Wunsch
SELECT
queryid ,
SUM(calls) AS calls ,
SUM(total_time) AS total_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid
ORDER BY 3 DESC
LIMIT 10-------------------------------------------------- ------------------------------------ | TOP10 SQL NACH GESAMTAUSFÜHRUNGSZEIT | #| queryid| Anrufe| ruft %| auf total_time (ms) | dbtime % +----+-----------+-----------+-----------+------ ------+---------- | 1| 821760255| 2| .00001|00:03:23.141( 203141.681 ms.)| 5.42 | 2| 4152624390| 2| .00001|00:03:13.929( 193929.215 ms.)| 5.17 | 3| 1484454471| 4| .00001|00:02:09.129( 129129.057 ms.)| 3.44 | 4| 655729273| 1| .00000|00:02:01.869( 121869.981 ms.)| 3.25 | 5| 2460318461| 1| .00000|00:01:33.113( 93113.835 ms.)| 2.48 | 6| 2194493487| 4| .00001|00:00:17.377( 17377.868 ms.)| .46 | 7| 1053044345| 1| .00000|00:00:06.156( 6156.352 ms.)| .16 | 8| 3644780286| 1| .00000|00:00:01.063( 1063.830 ms.)| .03
TOP10 SQL nach Gesamt-E/A-Zeit
Wunsch
SELECT
queryid ,
SUM(calls) AS calls ,
SUM(blk_read_time + blk_write_time) AS io_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid
ORDER BY 3 DESC
LIMIT 10-------------------------------------------------- -------------------------------------- | TOP10 SQL NACH GESAMT-E/A-ZEIT | #| queryid| Anrufe| ruft %| auf E/A-Zeit (ms)|db E/A-Zeit % +----+-----------+-----------+------ -----+--------------------------------+----------- -- | 1| 4152624390| 2| .00001|00:08:31.616( 511616.592 ms.)| 31.06. Juni | 2| 821760255| 2| .00001|00:08:27.099( 507099.036 ms.)| 30.78 | 3| 655729273| 1| .00000|00:05:02.209( 302209.137 ms.)| 18.35 | 4| 2460318461| 1| .00000|00:04:05.981( 245981.117 ms.)| 14.93 | 5| 1484454471| 4| .00001|00:00:39.144( 39144.221 ms.)| 2.38 | 6| 2194493487| 4| .00001|00:00:18.182( 18182.816 ms.)| 1.10 | 7| 1053044345| 1| .00000|00:00:16.611( 16611.722 ms.)| 1.01 | 8| 3644780286| 1| .00000|00:00:00.436( 436.205 ms.)| .03
TOP10 SQL nach maximaler Ausführungszeit
Wunsch
SELECT
id AS snapshotid ,
queryid ,
snapshot_timestamp ,
max_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
ORDER BY 4 DESC
LIMIT 10-------------------------------------------------- ------------------------------------ | TOP10 SQL NACH MAXIMALER AUSFÜHRUNGSZEIT | #| Schnappschuss| snapshotID| queryid| max_time (ms) +----+------------------+-------------------------+--------- ---+--------------------------------------- | 1| 05.04.2019 01:03 | 4169| 655729273| 00:02:01.869( 121869.981 ms.) | 2| 04.04.2019 17:00 | 4153| 821760255| 00:01:41.570( 101570.841 ms.) | 3| 04.04.2019 16:00 | 4146| 821760255| 00:01:41.570( 101570.841 ms.) | 4| 04.04.2019 16:00 | 4144| 4152624390| 00:01:36.964( 96964.607 ms.) | 5| 04.04.2019 17:00 | 4151| 4152624390| 00:01:36.964( 96964.607 ms.) | 6| 05.04.2019 10:00 | 4188| 1484454471| 00:01:33.452( 93452.150 ms.) | 7| 04.04.2019 17:00 | 4150| 2460318461| 00:01:33.113( 93113.835 ms.) | 8| 04.04.2019 15:00 | 4140| 1484454471| 00:00:11.892( 11892.302 ms.) | 9| 04.04.2019 16:00 | 4145| 1484454471| 00:00:11.892( 11892.302 ms.) | 10| 04.04.2019 17:00 | 4152| 1484454471| 00:00:11.892( 11892.302 ms.)
TOP10 SQL durch SHARED-Puffer-Lesen/Schreiben
Wunsch
SELECT
id AS snapshotid ,
queryid ,
snapshot_timestamp ,
shared_blks_read ,
shared_blks_written
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( shared_blks_read > 0 OR shared_blks_written > 0 )
ORDER BY 4 DESC , 5 DESC
LIMIT 10-------------------------------------------------- ------------------------------------ | TOP10 SQL NACH GEMEINSAMEM BUFFER LESEN/SCHREIBEN | #| Schnappschuss| snapshotID| queryid| gemeinsam genutzte Blöcke lesen| Gemeinsame Blöcke schreiben +----+----+-------------------------+---------- -+---------------------+--------------------- | 1| 04.04.2019 17:00 | 4153| 821760255| 797308| 0 | 2| 04.04.2019 16:00 | 4146| 821760255| 797308| 0 | 3| 05.04.2019 01:03 | 4169| 655729273| 797158| 0 | 4| 04.04.2019 16:00 | 4144| 4152624390| 756514| 0 | 5| 04.04.2019 17:00 | 4151| 4152624390| 756514| 0 | 6| 04.04.2019 17:00 | 4150| 2460318461| 734117| 0 | 7| 04.04.2019 17:00 | 4155| 3644780286| 52973| 0 | 8| 05.04.2019 01:03 | 4168| 1053044345| 52818| 0 | 9| 04.04.2019 15:00 | 4141| 2194493487| 52813| 0 | 10| 04.04.2019 16:00 | 4147| 2194493487| 52813| 0 ------------------------------------------------- -------------------------------------------------
Histogramm der Abfrageverteilung nach maximaler Ausführungszeit
Anfragen
SELECT
MIN(max_time) AS hist_min ,
MAX(max_time) AS hist_max ,
(( MAX(max_time) - MIN(min_time) ) / hist_columns ) as hist_width
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT ;
SELECT
SUM(calls) AS calls
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id =DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( max_time >= hist_current_min AND max_time < hist_current_max ) ;
|------------------------------------------------- ---------------------------------------- | MAX_TIME HISTOGRAMM | ANRUFE INSGESAMT: 33851920 | MIN. ZEIT: 00:00:01.063 | MAX. ZEIT: 00:02:01.869 ---------------------------------- -------- ------------- | Mindestdauer| maximale Dauer| Anrufe +----------------------------------+------------- -------+---------- | 00:00:01.063( 1063.830 ms.) | 00:00:13.144( 13144.445 ms.) | 9 | 00:00:13.144( 13144.445 ms.) | 00:00:25.225( 25225.060 ms.) | 0 | 00:00:25.225( 25225.060 ms.) | 00:00:37.305( 37305.675 ms.) | 0 | 00:00:37.305( 37305.675 ms.) | 00:00:49.386( 49386.290 ms.) | 0 | 00:00:49.386( 49386.290 ms.) | 00:01:01.466( 61466.906 ms.) | 0 | 00:01:01.466( 61466.906 ms.) | 00:01:13.547( 73547.521 ms.) | 0 | 00:01:13.547( 73547.521 ms.) | 00:01:25.628( 85628.136 ms.) | 0 | 00:01:25.628( 85628.136 ms.) | 00:01:37.708( 97708.751 ms.) | 4 | 00:01:37.708( 97708.751 ms.) | 00:01:49.789( 109789.366 ms.) | 2 | 00:01:49.789( 109789.366 ms.) | 00:02:01.869( 121869.981 ms.) | 0
TOP10 Snapshots nach Abfrage pro Sekunde
Anfragen
--pg_qps.sql
--Calculate Query Per Second
CREATE OR REPLACE FUNCTION pg_qps( pg_stat_history_id integer ) RETURNS double precision AS $$
DECLARE
pg_stat_history_rec record ;
prev_pg_stat_history_id integer ;
prev_pg_stat_history_rec record;
total_seconds double precision ;
result double precision;
BEGIN
result = 0 ;
SELECT *
INTO pg_stat_history_rec
FROM
pg_stat_history
WHERE id = pg_stat_history_id ;
IF pg_stat_history_rec.snapshot_timestamp IS NULL
THEN
RAISE EXCEPTION 'ERROR - Not found pg_stat_history for id = %',pg_stat_history_id;
END IF ;
--RAISE NOTICE 'pg_stat_history_id = % , snapshot_timestamp = %', pg_stat_history_id ,
pg_stat_history_rec.snapshot_timestamp ;
SELECT
MAX(id)
INTO
prev_pg_stat_history_id
FROM
pg_stat_history
WHERE
database_id = pg_stat_history_rec.database_id AND
queryid IS NULL AND
id < pg_stat_history_rec.id ;
IF prev_pg_stat_history_id IS NULL
THEN
RAISE NOTICE 'Not found previous pg_stat_history shapshot for id = %',pg_stat_history_id;
RETURN NULL ;
END IF;
SELECT *
INTO prev_pg_stat_history_rec
FROM
pg_stat_history
WHERE id = prev_pg_stat_history_id ;
--RAISE NOTICE 'prev_pg_stat_history_id = % , prev_snapshot_timestamp = %', prev_pg_stat_history_id , prev_pg_stat_history_rec.snapshot_timestamp ;
total_seconds = extract(epoch from ( pg_stat_history_rec.snapshot_timestamp - prev_pg_stat_history_rec.snapshot_timestamp ));
--RAISE NOTICE 'total_seconds = % ', total_seconds ;
--RAISE NOTICE 'calls = % ', pg_stat_history_rec.calls ;
IF total_seconds > 0
THEN
result = pg_stat_history_rec.calls / total_seconds ;
ELSE
result = 0 ;
END IF;
RETURN result ;
END
$$ LANGUAGE plpgsql;
SELECT
id ,
snapshot_timestamp ,
calls ,
total_time ,
( select pg_qps( id )) AS QPS ,
blk_read_time ,
blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( select pg_qps( id )) IS NOT NULL
ORDER BY 5 DESC
LIMIT 10
|------------------------------------------------- ---------------------------------------- | TOP10 Snapshots sortiert nach QueryPerSeconds-Nummern -------------------------------------- ------ -------------------------------------------- ------ ------------------------------------------- | #| Schnappschuss| snapshotID| Anrufe| Gesamtdbtime| QPS | E/A-Zeit | E/A-Zeit % +-----+------------------+-------------------------+------- ----+----------------------------------+---------- -+----------------------------------+----------- | 1| 04.04.2019 20:04| 4161| 5758631| 00:06:30.513( 390513.926 ms.)| 1573.396| 00:00:01.470( 1470.110 ms.)| .376 | 2| 04.04.2019 17:00 | 4149| 3529197| 00:11:48.830( 708830.618 ms.)| 980.332| 00:12:47.834( 767834.052 ms.)| 108.324 | 3| 04.04.2019 16:00 | 4143| 3525360| 00:10:13.492( 613492.351 ms.)| 979.267| 00:08:41.396( 521396.555 ms.)| 84.988 | 4| 04.04.2019 21:03 | 4163| 2781536| 00:03:06.470( 186470.979 ms.)| 785.745| 00:00:00.249( 249.865 ms.)| .134 | 5| 04.04.2019 19:03 | 4159| 2890362| 00:03:16.784( 196784.755 ms.)| 776.979| 00:00:01.441( 1441.386 ms.)| .732 | 6| 04.04.2019 14:00 | 4137| 2397326| 00:04:43.033( 283033.854 ms.)| 665.924| 00:00:00.024( 24.505 ms.)| .009 | 7| 04.04.2019 15:00 | 4139| 2394416| 00:04:51.435( 291435.010 ms.)| 665.116| 00:00:12.025( 12025.895 ms.)| 4.126 | 8| 04.04.2019 13:00 | 4135| 2373043| 00:04:26.791( 266791.988 ms.)| 659.179| 00:00:00.064( 64.261 ms.)| .024 | 9| 05.04.2019 01:03 | 4167| 4387191| 00:06:51.380( 411380.293 ms.)| 609.332| 00:05:18.847( 318847.407 ms.)| 77.507 | 10| 04.04.2019 18:01 | 4157| 1145596| 00:01:19.217( 79217.372 ms.)| 313.004| 00:00:01.319( 1319.676 ms.)| 1.666
Stündlicher Ausführungsverlauf mit QueryPerSeconds und E/A-Zeit
Wunsch
SELECT
id ,
snapshot_timestamp ,
calls ,
total_time ,
( select pg_qps( id )) AS QPS ,
blk_read_time ,
blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
ORDER BY 2
|----------------------------------------------------------------------------------------------- | HOURLY EXECUTION HISTORY WITH QueryPerSeconds and I/O Time ----------------------------------------------------------------------------------------------------------------------------------------------- | QUERY PER SECOND HISTORY | #| snapshot| snapshotID| calls| total dbtime| QPS| I/O time| I/O time % +-----+------------------+-----------+-----------+----------------------------------+-----------+----------------------------------+----------- | 1| 04.04.2019 11:00| 4131| 3747| 00:00:00.835( 835.374 ms.)| 1.041| 00:00:00.000( .000 ms.)| .000 | 2| 04.04.2019 12:00| 4133| 1002722| 00:01:52.419( 112419.376 ms.)| 278.534| 00:00:00.149( 149.105 ms.)| .133 | 3| 04.04.2019 13:00| 4135| 2373043| 00:04:26.791( 266791.988 ms.)| 659.179| 00:00:00.064( 64.261 ms.)| .024 | 4| 04.04.2019 14:00| 4137| 2397326| 00:04:43.033( 283033.854 ms.)| 665.924| 00:00:00.024( 24.505 ms.)| .009 | 5| 04.04.2019 15:00| 4139| 2394416| 00:04:51.435( 291435.010 ms.)| 665.116| 00:00:12.025( 12025.895 ms.)| 4.126 | 6| 04.04.2019 16:00| 4143| 3525360| 00:10:13.492( 613492.351 ms.)| 979.267| 00:08:41.396( 521396.555 ms.)| 84.988 | 7| 04.04.2019 17:00| 4149| 3529197| 00:11:48.830( 708830.618 ms.)| 980.332| 00:12:47.834( 767834.052 ms.)| 108.324 | 8| 04.04.2019 18:01| 4157| 1145596| 00:01:19.217( 79217.372 ms.)| 313.004| 00:00:01.319( 1319.676 ms.)| 1.666 | 9| 04.04.2019 19:03| 4159| 2890362| 00:03:16.784( 196784.755 ms.)| 776.979| 00:00:01.441( 1441.386 ms.)| .732 | 10| 04.04.2019 20:04| 4161| 5758631| 00:06:30.513( 390513.926 ms.)| 1573.396| 00:00:01.470( 1470.110 ms.)| .376 | 11| 04.04.2019 21:03| 4163| 2781536| 00:03:06.470( 186470.979 ms.)| 785.745| 00:00:00.249( 249.865 ms.)| .134 | 12| 04.04.2019 23:03| 4165| 1443155| 00:01:34.467( 94467.539 ms.)| 200.438| 00:00:00.015( 15.287 ms.)| .016 | 13| 05.04.2019 01:03| 4167| 4387191| 00:06:51.380( 411380.293 ms.)| 609.332| 00:05:18.847( 318847.407 ms.)| 77.507 | 14| 05.04.2019 02:03| 4171| 189852| 00:00:10.989( 10989.899 ms.)| 52.737| 00:00:00.539( 539.110 ms.)| 4.906 | 15| 05.04.2019 03:01| 4173| 3627| 00:00:00.103( 103.000 ms.)| 1.042| 00:00:00.004( 4.131 ms.)| 4.010 | 16| 05.04.2019 04:00| 4175| 3627| 00:00:00.085( 85.235 ms.)| 1.025| 00:00:00.003( 3.811 ms.)| 4.471 | 17| 05.04.2019 05:00| 4177| 3747| 00:00:00.849( 849.454 ms.)| 1.041| 00:00:00.006( 6.124 ms.)| .721 | 18| 05.04.2019 06:00| 4179| 3747| 00:00:00.849( 849.561 ms.)| 1.041| 00:00:00.000( .051 ms.)| .006 | 19| 05.04.2019 07:00| 4181| 3747| 00:00:00.839( 839.416 ms.)| 1.041| 00:00:00.000( .062 ms.)| .007 | 20| 05.04.2019 08:00| 4183| 3747| 00:00:00.846( 846.382 ms.)| 1.041| 00:00:00.000( .007 ms.)| .001 | 21| 05.04.2019 09:00| 4185| 3747| 00:00:00.855( 855.426 ms.)| 1.041| 00:00:00.000( .065 ms.)| .008 | 22| 05.04.2019 10:00| 4187| 3797| 00:01:40.150( 100150.165 ms.)| 1.055| 00:00:21.845( 21845.217 ms.)| 21.812
Text aller SQL-Auswahlen
Wunsch
SELECT
queryid ,
query
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid , query
Ergebnis
Wie Sie sehen, können Sie mit relativ einfachen Mitteln viele nützliche Informationen über die Arbeitslast und den Zustand der Datenbank erhalten.
Hinweis:Wenn Sie die Abfrage-ID in den Abfragen festlegen, erhalten wir den Verlauf für eine separate Anfrage (um Platz zu sparen, werden Berichte für eine separate Anfrage weggelassen).
Somit sind statistische Daten zur Abfrageleistung verfügbar und werden gesammelt.
Die erste Stufe „Erhebung statistischer Daten“ ist abgeschlossen.
Sie können mit der zweiten Stufe fortfahren – „Leistungsmetriken konfigurieren“.

Aber das ist eine ganz andere Geschichte.
To be continued ...
Source: habr.com
