

Wir setzen unsere Geschichte darüber fort, wie wir das BMS-System in unseren Rechenzentren geändert haben (, ). Dabei haben wir nicht einfach die Lösung eines Anbieters gegen die eines anderen ausgetauscht, sondern ein System von Grund auf neu nach unseren Anforderungen entwickelt. Zum Abschluss unserer Geschichte teilen wir die Ergebnisse unserer Arbeiten und interessante Lösungen, die für Sie von Nutzen sein könnten.
Die neue Benutzeroberfläche
Hier, wie man so schön sagt, sieht man besser einmal als tausendmal hören.
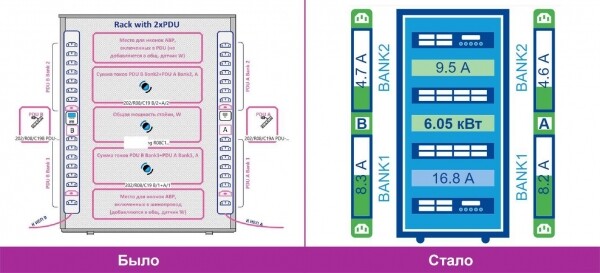 Racks.
Racks.
Lassen Sie uns die Unterschiede betrachten.
- Zunächst einmal ist das schön komfortabel. Beachten Sie, wie einfach es jetzt ist, die Lasten auf den Modulen („Banks“ oder einfach „Bänke“) der PDU und die Summe der parallelen Lasten der Paarmodule zu verfolgen. Bei dem neuen BMS-Rack-Modell sehen wir sofort, dass die unteren PDU-Paarmodule überlastet sind (der Gesamtstrom übersteigt die zulässigen 16A – „blaues“ Benachrichtigungssignal), während die oberen unterlastet sind. Im Falle eines Ausfalls eines der Einspeisungen wird die gesamte Last auf den zweiten übertragen, und das verbleibende unter Spannung stehende untere Modul wird aufgrund von Überlastung abgeschaltet. Um dies zu vermeiden, wird der Support des Rechenzentrums den Kunden im Voraus informieren und Empfehlungen zur Lastverteilung senden.
- Einfache Hinzufügung von Equipment. In der neuen BMS wurden virtuelle Sensoren zur Summe der Ströme der Module und der Leistung des Racks bereits in die Vorlagen für Standardracks integriert und werden automatisch erstellt, nachdem sie zum PDU-Rack hinzugefügt wurden. In der alten BMS mussten sie manuell erstellt und anschließend auf die Karte gezogen werden, was die Fehleranfälligkeit durch den „menschlichen Faktor“ erhöhte.
- Unbegrenzter Raum für Kreativität. Jetzt gibt es keine Einschränkungen mehr bei der Erstellung von virtuellen Sensoren. Es können beliebige mathematische Modelle beliebiger Variablen erstellt werden. Das bedeutet, dass wir in der Lage sind, komplexe virtuelle Sensoren zu schaffen (früher konnten nur Werte addiert werden) und die Statistiken sowie Trends im Betrieb ingenieurtechnischer Systeme besser zu analysieren. Dies verbessert die Qualität der Entscheidungen zur Systemanpassung, zum Austausch von Anlagen und zur Ressourcenverwaltung.
- Intuitive Benutzeroberfläche. Die neue Benutzeroberfläche kommt ohne ein Übermaß an Symbolen aus, die Ventilatoren laufen leise und die Schalter klicken. Besonders praktisch ist die Möglichkeit, den Status der PDU-Leitungen A/B innerhalb der Racks anzuzeigen. Wir haben versucht, etwas Ähnliches in der alten BMS zu realisieren, aber die Anzahl der überlappenden Symbole pro Quadratzentimeter auf der Karte hat uns davon abgehalten.
Jetzt ist es angenehm, die Ansicht zu genießen:
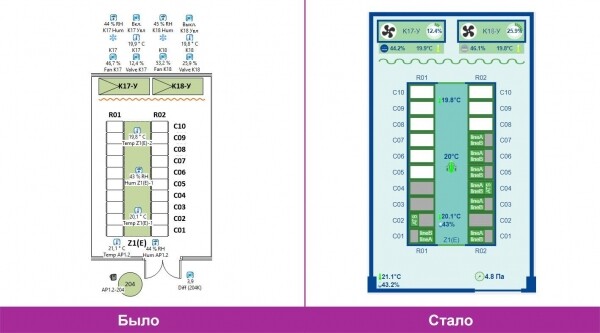
Serverräume.
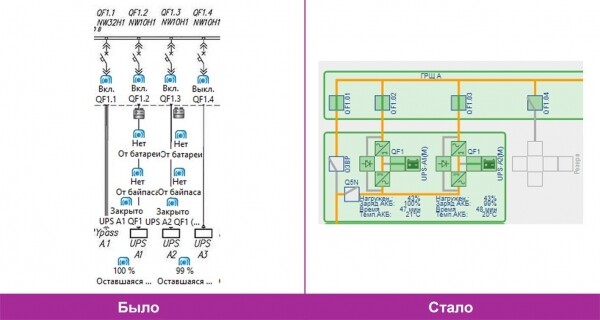
Ausschnitt des HV-Energieverteilungssystems.
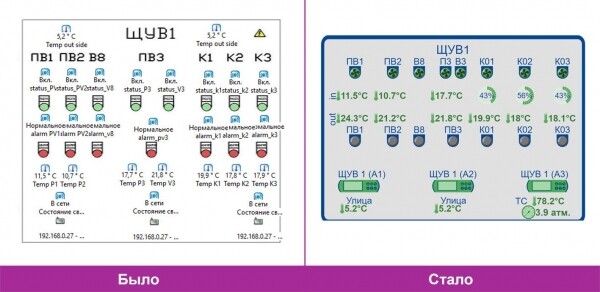
Steuerungsschild für die Lüftung.
Und die neue BMS kann sogar für das neue Jahr dekoriert werden 🙂
Eine Seite – Verständigung mit halben Wörtern und ohne Lastenheft
Wir haben schon lange darüber nachgedacht, ein weiteres „Feature“ in die BMS zu integrieren: die wichtigsten Parameter des Rechenzentrums auf einer Seite zusammenzustellen, um mit einem Blick auf den Bildschirm den Zustand der Hauptsysteme beurteilen zu können. Allerdings hatten wir kein abschließendes Bild davon, wie es aussehen sollte.
Noch vor Beginn der Entwicklung der neuen BMS haben wir mit Gruppenführungen ein Dutzend Rechenzentren in den Niederlanden besucht. Eines der Ziele war es, Beispiele für die Umsetzung einer solchen Seite zu sehen.
In keinem unserer Rechenzentren wurde sie uns gezeigt – irgendwo fehlte sie, irgendwo „wurde sie gerade entwickelt“, und woanders war es ein „großes Geschäftsgeheimnis“. Daher enthielt unser Lastenheft zur Erstellung des neuen BMS keine genaue Beschreibung dieser für uns sehr wichtigen Seite.
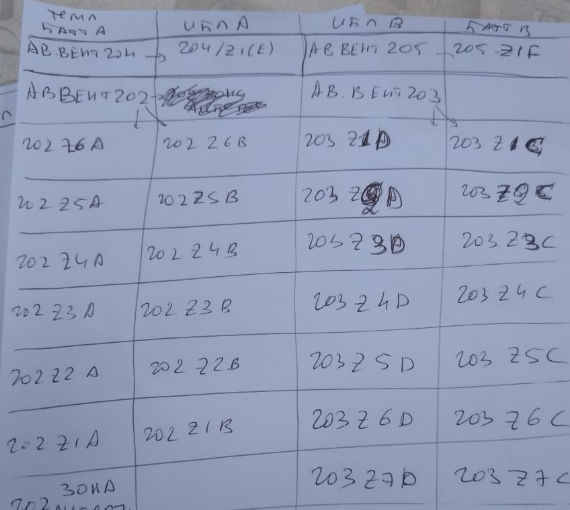
Letztendlich haben wir sie buchstäblich „im Vorbeigehen“ erfunden. Gerade in diesem Moment musste ich Kollegen im Rechenzentrum fernberaten. Die BMS-Seiten auf dem Handy durchzublättern, während ich nach verstreuten Informationen suchte, war äußerst unpraktisch, und tatsächlich wurde die erste Version auf einer Serviette skizziert. Eine Seite. Diese wurde von den Entwicklern anhand des Fotos umgesetzt.
Dem Beispiel unserer vorsichtigen niederländischen Kollegen folgend, werden wir die endgültige Version unserer Hauptseite nicht zeigen, zumal jedes Rechenzentrum einzigartig ist und es keinen Sinn macht, zu kopieren. Aber wir werden zwei Hauptprinzipien ihrer Gestaltung beschreiben:
- Es handelt sich um eine Tabelle, die für den vertikal angebrachten Bildschirm eines Smartphones (oder Monitors, aber im vertikalen Layout) gestaltet ist, die alle wichtigen Informationen auf einem Bildschirm anzeigt. Über der Tabelle wird eine „Zusammenfassung“ aktiver Vorfälle angezeigt, und es stellte sich heraus, dass es am praktischsten ist, diese im vertikalen Format zusammen zu platzieren.
- Die Anordnung der Zellen in der Tabelle spiegelt die Architektur des Rechenzentrums (physisch oder logisch) wider. Wir haben uns von der alphabetischen Anordnung der Systeme, die auf den ersten Blick naheliegend scheint, verabschiedet. Die Reihenfolge entspricht den visuellen Assoziationen des Rechenzentrumspersonals – als ob sie physisch alle Räume und Systeme überwachen. Das vereinfacht die Informationssuche.
Im Grunde sind nun alle wichtigen Merkmale des Rechenzentrums gruppiert und auf einem Bildschirm des Smartphones/Monitors des verantwortlichen Ingenieurs oder Managers dargestellt, wobei die Verbindung zur physischen und logischen Topografie des Rechenzentrums hergestellt wird.
Hier ist das Foto des ursprünglichen Entwurfs, obwohl diese Version natürlich später überarbeitet und verfeinert wurde.
Quittierung und Zusammenfassung von Vorfällen
Wir werden ein weiteres neues Konzept vorstellen, das im Rahmen des Projekts zur Aktualisierung des Überwachungssystems entstanden ist.
Quittierung ist ein relativ selten verwendeter Begriff, den der Entwickler des neuen BMS vorgeschlagen hat. Er bedeutet die Bestätigung, dass der Betreiber einen Vorfall gesehen, diesen bestätigt und die Verantwortung für dessen Behebung übernommen hat.
Das Wort hat sich etabliert, und nun „bestätigen“ wir Vorfälle.
Der Algorithmus, der in die Grundversion des neuen BMS integriert wurde, hat uns nicht überzeugt. Tatsächlich handelte es sich dabei um Kommentare zum Ereignisprotokoll; das heißt, beseitigte Vorfälle verschwanden nicht aus dem Protokoll, während bestätigte („quittierte“) nicht von neuen sortiert wurden.
Infolgedessen wurde ein Fenster mit dem Namen „Übersicht“ entwickelt, in dem:
- Nur aktive Vorfälle und Geräte im Servicemodus angezeigt werden (ohne kommerzielle „blaue“ Benachrichtigungen).
- NEUE und BESTÄTIGTE Vorfälle deutlich voneinander unterschieden werden.
- Anggeben wird, wer den Vorfall angenommen hat.
Der Algorithmus für die Bereitschaftsdienste im neuen BMS funktioniert wie folgt:
- Neue Vorfälle gelangen in die Übersicht und warten auf Bestätigung. Sie können sich dort nicht lange aufhalten; der zuständige Bereitschaftsdienst muss den Vorfall sofort annehmen.
- Der Mitarbeiter nimmt den Vorfall an, indem er auf das Häkchen rechts klickt. Da alle Mitarbeiter unter einzigartigen Konten arbeiten, wird automatisch angezeigt, wer den Vorfall angenommen hat. Bei Bedarf kann ein Kommentar hinterlassen werden.
- Der Vorfall wird in den Bereich „Bestätigte Vorfälle“ verschoben, die anderen Bereitschaftsdienste und die Leitung verstehen, dass der Vorfall von dem zuständigen Mitarbeiter bearbeitet wird.

Beispiel eines Zusammenfassungsfensters mit neuer und bereits bestätigter Nachricht.
Durch die Verbindung des Zusammenfassungsfensters mit der One Page-Tabelle haben wir eine umfassende Hauptansicht des BMS-Systems, auf der sofort Folgendes sichtbar ist:
- der Status der Hauptsysteme des Rechenzentrums;
- die Existenz neuer unbearbeiteter Vorfälle;
- die Existenz bestäligter Vorfälle und Angaben dazu, wer diese konkret behebt.
Zugriff über den Browser und Benachrichtigungen auf dem Telefon
Die Weboberfläche, die von jedem Gerät aus jederzeit und überall zugänglich ist, steht im krassen Gegensatz zum „dicken“ Client, der vollständig für externe Benutzer geschlossen ist.
Der alte Ansatz brachte eine Reihe von Unannehmlichkeiten mit sich, von Problemen bei der Organisation der Fernarbeit der Überwachungsmitarbeiter bis hin zur Notwendigkeit, „dicke“ Clients aus Verteilungen auf die Arbeitsplätze der Mitarbeiter im Rechenzentrum zu installieren.
Jetzt hat jede Seite im BMS eine einzigartige Adresse, was es ermöglicht, nicht nur die direkte Adresse der Seite oder des Geräts zu teilen, sondern auch Links zu einzigartigen Grafiken/ Berichten.
Der Zugang zum System erfolgt nun über LDAP-Authentifizierung über Active Directory, was das Schutzniveau deutlich erhöht.
Mobilität ist heute ein entscheidender Faktor für die effiziente Arbeit der Bereitschaftsingenieure. Neben der Überwachung im Bereitschaftsraum führen die Ingenieure Rundgänge durch und erledigen aktuelle Aufgaben außerhalb des Bereitschaftsraums. Dank des für mobile Bildschirme optimierten Hauptbildschirms der BMS behalten sie jederzeit den Überblick über die Situation in den Maschinenräumen.
Die Qualität der Kontrolle wird auch durch die Funktionen von Arbeits-Chats verbessert. Diese beschleunigen die Arbeitsprozesse und ermöglichen es, die Kommunikation der Bereitschaftsingenieure mit der BMS zu verknüpfen. Wir verwenden beispielsweise die App Teams, die es ermöglicht, interne Nachrichten auszutauschen und alle Mitteilungen aus der BMS als Push-Benachrichtigungen auf das Telefon zu erhalten. Dies befreit den Bereitschaftsingenieur von der ständigen Notwendigkeit, auf den Bildschirm des Telefons zu schauen.
Push-Benachrichtigung auf dem Smartphone-Bildschirm.
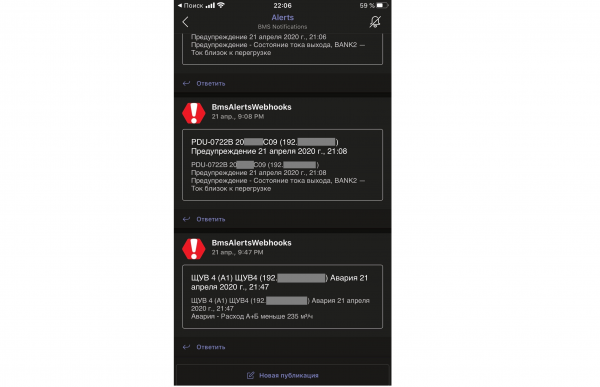
So sehen die Benachrichtigungen in der App Teams aus.
Die Push-Benachrichtigungen sind ausschließlich auf Vorfälle eingestellt, wodurch Ablenkungen minimiert werden. Das Personal weiß: Wenn ein Push-Benachrichtigung von Teams auf dem Smartphone angezeigt wird, muss die BMS-Seite aufgerufen und der Vorfall angenommen werden. Die Meldungen über die Behebung von Vorfällen werden bereits auf der BMS-Seite verfolgt.

Auf dem Foto ist die BMS-Oberfläche auf einem Smartphone zu sehen.
Zusammenfassend
Bei den Kosten für das BMS-Upgrade unseres alten Anbieters, die mit der Neuentwicklung eines Systems von Grund auf vergleichbar sind (etwa 100.000 $), stellte sich der Unterschied in der Funktionalität der Produkte als enorm heraus. Wir erhielten ein flexibles System, das auf unsere Geschäftsaufgaben und Prozesse optimiert ist. Außerdem konnten wir erhebliche Einsparungen bei den aktuellen Kosten für die Systemwartung und -aktualisierung erzielen.
Aber natürlich gab es auch Herausforderungen.
- Zunächst einmal haben wir das Ausmaß der erforderlichen Änderungen an der Grundversion des neuen BMS unterschätzt und konnten die vorher festgelegten Termine nicht einhalten. Für uns war das jedoch kein kritisches Problem, da wir bis zum Schluss auf der alten Systemversion gearbeitet haben und der Prozess kreativ sowie anspruchsvoll war, wodurch er manchmal langsamer voranging, als erwartet. Zudem waren wir uns stets bewusst, dass unser Entwickler sein Bestes gab, um ein optimales Ergebnis zu erzielen. Allerdings stellte sich heraus, dass die Geschichte viel länger dauerte, und unsere Schlüsselmitarbeiter haben deutlich mehr Zeit und Mühe hineingesteckt, als sie ursprünglich geplant hatten.
- Zweitens benötigten wir mehrere Testphasen, um den Algorithmus für die Reservierung von virtuellen Maschinen und Kommunikationskanälen zu optimieren. Ursprünglich gab es sowohl auf Seiten des BMS-Systems als auch bei der Konfiguration der virtuellen Maschinen und des Netzwerks Fehler. Auch diese Fehlersuche hat Zeit in Anspruch genommen. Zum Glück wurde dem Auftragnehmer eine Testumgebung in Form eines Cloud-Dienstes bereitgestellt, in der anfangs alle Einstellungen und Neuerungen getestet wurden.
- Drittens erwies sich das endgültige System als schwieriger für die Bearbeitung durch den Endbenutzer. Früher war die Karte eine einfache Unterlage (Grafikdatei) mit Symbolen, deren Bearbeitung oder Verschiebung keine Herausforderung darstellte. Jetzt ist es eine komplexe grafische Benutzeroberfläche mit Animationen, die bestimmte Fähigkeiten zur Bearbeitung erfordert.
Das radikale Update unseres BMS-Systems kann bereits heute als eines der wichtigsten Projekte des letzten Jahres betrachtet werden, das die Qualität des operativen Managements unserer Standorte erheblich beeinflussen wird.
Den alten physischen Server haben wir natürlich nicht entsorgt, sondern "abgespeckt": Wir haben ihn von Tausenden "kommerziellen" virtuellen Sensoren und PDUs befreit und nur noch einige Dutzend der kritischsten Geräte wie Generatoren, USVs, Klimaanlagen, Pumpen, Leckage- und Temperatursensoren übrig gelassen. In diesem Betrieb hat er seine frühere Geschwindigkeit zurückgewonnen und kann als "Reserve der Reserve" fungieren. Übrigens haben wir nach der Entfernung der PDUs aus dem alten BMS etwa 1000 nun überflüssige Lizenzen frei, wissen Sie zufällig, was wir damit tun sollen?
Quelle: habr.com
