

Warten! Warten! Es stimmt, dies ist kein weiterer Artikel über Arten von SQL Server-Backups. Ich werde nicht einmal auf die Unterschiede zwischen den Wiederherstellungsmodellen und den Umgang mit einem überwucherten Baumstamm eingehen.
Vielleicht (nur vielleicht) können Sie nach dem Lesen dieses Beitrags sicherstellen, dass das Backup, das mit Standardmitteln von Ihnen entfernt wurde, morgen Abend 1.5-mal schneller entfernt wird. Und das nur, weil Sie etwas mehr BACKUP DATABASE-Parameter verwenden.
Wenn der Inhalt des Beitrags für Sie offensichtlich war, tut es mir leid. Ich habe alles gelesen, was Google zum Begriff „Habr-SQL-Server-Backup“ gefunden hat, und in keinem einzigen Artikel habe ich einen Hinweis darauf gefunden, dass die Backup-Zeit irgendwie über Parameter beeinflusst werden kann.
Ich werde Sie sofort auf den Kommentar von Alexander Gladchenko aufmerksam machen ():
Ändern Sie niemals die Parameter BUFFERCOUNT, BLOCKSIZE, MAXTRANSFERSIZE in der Produktion. Sie sind nur zum Schreiben solcher Artikel gedacht. In der Praxis werden Sie Gedächtnisprobleme im Handumdrehen los.
Es wäre natürlich cool, der Klügste zu sein und exklusive Inhalte zu posten, aber leider ist das nicht der Fall. Es gibt sowohl englischsprachige als auch russischsprachige Artikel/Beiträge (ich bin immer verwirrt, wie ich sie richtig nennen soll) zu diesem Thema. Hier sind einige von denen, die mir begegnet sind: , , .
Daher füge ich zunächst eine etwas abgespeckte BACKUP-Syntax von hinzu (Übrigens habe ich oben über BACKUP DATABASE geschrieben, aber das gilt alles sowohl für die Transaktionsprotokollsicherung als auch für die differenzielle Sicherung, aber vielleicht mit einem weniger offensichtlichen Effekt):
BACKUP DATABASE { database_name | @database_name_var }
TO <backup_device> [ ,...n ]
<...>
[ WITH { <...>
| <general_WITH_options> [ ,...n ] } ]
[;]
<general_WITH_options> [ ,...n ]::=
<...>
--Media Set Options
<...>
| BLOCKSIZE = { blocksize | @blocksize_variable }
--Data Transfer Options
BUFFERCOUNT = { buffercount | @buffercount_variable }
| MAXTRANSFERSIZE = { maxtransfersize | @maxtransfersize_variable }
<...><…> – es bedeutet, dass da etwas war, aber ich habe es entfernt, weil es jetzt für das Thema nicht relevant ist.
Wie erstellen Sie normalerweise ein Backup? Wie „lehren“ sie, wie man Backups in Milliarden von Artikeln erstellt? Wenn ich eine einmalige Sicherung einer nicht sehr großen Datenbank erstellen muss, schreibe ich im Allgemeinen automatisch so etwas:
BACKUP DATABASE smth
TO DISK = 'D:Backupsmth.bak'
WITH STATS = 10, CHECKSUM, COMPRESSION, COPY_ONLY;
--ладно, CHECKSUM я написал только чтобы казаться умнееUnd im Allgemeinen sind hier wahrscheinlich 75–90 % aller Parameter aufgeführt, die normalerweise in Artikeln über Backups erwähnt werden. Nun, es gibt auch INIT, SKIP. Haben Sie MSDN besucht? Haben Sie gesehen, dass es Optionen für eineinhalb Bildschirme gibt? Ich habe auch gesehen...
Sie haben wahrscheinlich bereits erkannt, dass wir im Folgenden über die drei Parameter sprechen werden, die im ersten Codeblock übrig geblieben sind – BLOCKSIZE, BUFFERCOUNT und MAXTRANSFERSIZE. Hier sind ihre Beschreibungen von MSDN:
BLOCK GRÖSSE = { Block Größe | @ blocksize_variable } – gibt die physische Blockgröße in Bytes an. Unterstützte Größen sind 512, 1024, 2048, 4096, 8192, 16, 384 und 32 Byte (768 KB). Der Standardwert ist 65 für Bandgeräte und 536 für andere Geräte. Normalerweise ist dieser Parameter nicht erforderlich, da die BACKUP-Anweisung automatisch die geeignete Blockgröße für das Gerät auswählt. Durch das explizite Festlegen der Blockgröße wird die automatische Auswahl der Blockgröße außer Kraft gesetzt.
Pufferanzahl = { Pufferanzahl | @ buffercount_variable } – Definiert die Gesamtzahl der E/A-Puffer, die für den Sicherungsvorgang verwendet werden. Sie können einen beliebigen positiven Ganzzahlwert angeben, aber eine große Anzahl von Puffern kann aufgrund des übermäßigen virtuellen Adressraums im Sqlservr.exe-Prozess zu einem Fehler wegen unzureichendem Arbeitsspeicher führen.
Der von Puffern insgesamt genutzte Speicherplatz wird durch die folgende Formel bestimmt:
BUFFERCOUNT * MAXTRANSFERSIZE.
MAXÜBERTRAGUNGSGRÖSSE = { maximale Übertragungsgröße | @ maxtransfersize_variable } gibt die größte Datenpaketgröße in Bytes an, die zwischen SQL Server und dem Sicherungssatzmedium ausgetauscht werden soll. Es werden Vielfache von 65 Byte (536 KB) bis zu 64 Byte (4 MB) unterstützt.
Ich schwöre – ich habe das schon einmal gelesen, aber es ist mir nie in den Sinn gekommen, welchen Einfluss sie auf die Produktivität haben könnten. Darüber hinaus muss ich offenbar eine Art „Coming-out“ machen und zugeben, dass ich selbst jetzt noch nicht ganz verstehe, was genau sie tun. Ich muss wahrscheinlich mehr über gepufferte E/A und die Arbeit mit einer Festplatte lesen. Eines Tages werde ich das tun, aber im Moment kann ich einfach ein Skript schreiben, das prüft, wie sich diese Werte auf die Geschwindigkeit auswirken, mit der das Backup erstellt wird.
Ich habe eine kleine Datenbank erstellt, etwa 10 GB groß, sie auf der SSD abgelegt und das Verzeichnis für Backups auf der Festplatte.
Ich erstelle eine temporäre Tabelle, um die Ergebnisse zu speichern (ich habe sie nicht temporär, sodass ich mich detaillierter mit den Ergebnissen befassen kann, aber Sie entscheiden selbst):
DROP TABLE IF EXISTS ##bt_results;
CREATE TABLE ##bt_results (
id int IDENTITY (1, 1) PRIMARY KEY,
start_date datetime NOT NULL,
finish_date datetime NOT NULL,
backup_size bigint NOT NULL,
compressed_size bigint,
block_size int,
buffer_count int,
transfer_size int
);Das Prinzip des Skripts ist einfach: Verschachtelte Schleifen, von denen jede den Wert eines Parameters ändert, diese Parameter in den BACKUP-Befehl einfügen, den letzten Datensatz mit Verlauf aus msdb.dbo.backupset speichern, die Sicherungsdatei löschen und die nächste Iteration durchführen . Da die Backup-Ausführungsdaten aus dem Backup-Set entnommen werden, geht die Genauigkeit etwas verloren (es gibt keine Bruchteile von Sekunden), aber wir werden das überleben.
Zuerst müssen Sie xp_cmdshell aktivieren, um Backups zu löschen (vergessen Sie dann nicht, es zu deaktivieren, wenn Sie es nicht benötigen):
EXEC sp_configure 'show advanced options', 1;
EXEC sp_configure 'xp_cmdshell', 1;
RECONFIGURE;
EXEC sp_configure 'show advanced options', 0;
GONaja eigentlich:
DECLARE @tmplt AS nvarchar(max) = N'
BACKUP DATABASE [bt]
TO DISK = ''D:SQLServerbackupbt.bak''
WITH
COMPRESSION,
BLOCKSIZE = {bs},
BUFFERCOUNT = {bc},
MAXTRANSFERSIZE = {ts}';
DECLARE @sql AS nvarchar(max);
/* BLOCKSIZE values */
DECLARE @bs int = 4096,
@max_bs int = 65536;
/* BUFFERCOUNT values */
DECLARE @bc int = 7,
@min_bc int = 7,
@max_bc int = 800;
/* MAXTRANSFERSIZE values */
DECLARE @ts int = 524288, --512KB, default = 1024KB
@min_ts int = 524288,
@max_ts int = 4194304; --4MB
SELECT TOP 1
@bs = COALESCE (block_size, 4096),
@bc = COALESCE (buffer_count, 7),
@ts = COALESCE (transfer_size, 524288)
FROM ##bt_results
ORDER BY id DESC;
WHILE (@bs <= @max_bs)
BEGIN
WHILE (@bc <= @max_bc)
BEGIN
WHILE (@ts <= @max_ts)
BEGIN
SET @sql = REPLACE (REPLACE (REPLACE(@tmplt, N'{bs}', CAST(@bs AS nvarchar(50))), N'{bc}', CAST (@bc AS nvarchar(50))), N'{ts}', CAST (@ts AS nvarchar(50)));
EXEC (@sql);
INSERT INTO ##bt_results (start_date, finish_date, backup_size, compressed_size, block_size, buffer_count, transfer_size)
SELECT TOP 1 backup_start_date, backup_finish_date, backup_size, compressed_backup_size, @bs, @bc, @ts
FROM msdb.dbo.backupset
ORDER BY backup_set_id DESC;
EXEC xp_cmdshell 'del "D:SQLServerbackupbt.bak"', no_output;
SET @ts += @ts;
END
SET @bc += @bc;
SET @ts = @min_ts;
WAITFOR DELAY '00:00:05';
END
SET @bs += @bs;
SET @bc = @min_bc;
SET @ts = @min_ts;
ENDWenn Sie plötzlich Klarheit darüber benötigen, was hier passiert, schreiben Sie in die Kommentare oder per PN. Im Moment erzähle ich Ihnen nur von den Parametern, die ich in BACKUP DATABASE eingegeben habe.
Für BLOCKSIZE haben wir eine „geschlossene“ Liste von Werten, und ich habe kein Backup mit BLOCKSIZE < 4 KB durchgeführt. MAXTRANSFERSIZE jede Zahl, die ein Vielfaches von 64 KB ist – von 64 KB bis 4 MB. Der Standardwert auf meinem System ist 1024 KB, ich habe 512 - 1024 - 2048 - 4096 genommen.
Bei BUFFERCOUNT war es schwieriger – es kann jede positive Zahl sein, aber der Link sagt es . Dort steht auch, wie man an Informationen darüber kommt, mit welchem BUFFERCOUNT das Backup tatsächlich erstellt wurde – bei mir sind es 7. Es hatte keinen Sinn, es zu reduzieren, und die Obergrenze wurde experimentell entdeckt – bei BUFFERCOUNT = 896 und MAXTRANSFERSIZE = 4194304 fiel das Backup mit ein Fehler (über den im obigen Link geschrieben wurde):
Meldung 3013, Ebene 16, Status 1, Zeile 7: BACKUP DATABASE wird abnormal beendet.
Meldung 701, Ebene 17, Status 123, Zeile 7. Im Ressourcenpool „Standard“ ist nicht genügend Systemspeicher vorhanden, um diese Abfrage auszuführen.
Zum Vergleich zeige ich zunächst die Ergebnisse einer Sicherung ohne Angabe von Parametern:
BACKUP DATABASE [bt]
TO DISK = 'D:SQLServerbackupbt.bak'
WITH COMPRESSION;Na ja, Backup und Backup:
1070072 Seiten für Datenbank „bt“, Datei „bt“ in Datei 1 verarbeitet.
2 Seiten für Datenbank „bt“, Datei „bt_log“ in Datei 1 verarbeitet.
BACKUP DATABASE hat 1070074 Seiten erfolgreich in 53.171 Sekunden (157.227 MB/s) verarbeitet.
Das Skript selbst, das die Parameter testet, funktionierte in ein paar Stunden, alle Messungen waren vorhanden . Und hier ist eine Auswahl der Ergebnisse mit den drei besten Ausführungszeiten (ich habe versucht, eine schöne Grafik zu erstellen, aber im Beitrag muss ich mich mit einer Tabelle begnügen, und in den Kommentaren hinzugefügt ).
SELECT TOP 7 WITH TIES
compressed_size,
block_size,
buffer_count,
transfer_size,
DATEDIFF(SECOND, start_date, finish_date) AS backup_time_sec
FROM ##bt_results
ORDER BY backup_time_sec ASC;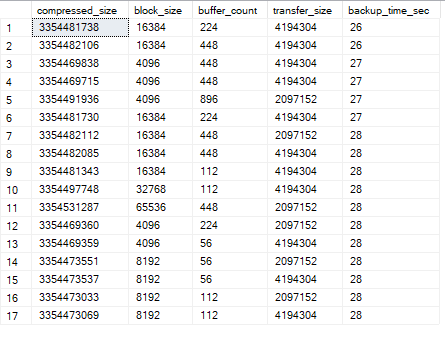
Achtung, ein sehr wichtiger Hinweis von von :
Wir können mit Sicherheit sagen, dass die Beziehung zwischen den Parametern und der Backup-Geschwindigkeit innerhalb dieser Wertebereiche zufällig ist, es gibt kein Muster. Aber die Abkehr von den eingebauten Parametern hatte offensichtlich einen guten Einfluss auf das Ergebnis
Diese. Nur durch die Verwaltung der standardmäßigen BACKUP-Parameter konnte die Backup-Entfernungszeit verdoppelt werden: 2 Sekunden gegenüber 26 zu Beginn. Das ist nicht schlecht, oder? Aber wir müssen sehen, was mit der Restaurierung passiert. Was wäre, wenn die Genesung jetzt viermal länger dauert?
Lassen Sie uns zunächst messen, wie lange es dauert, ein Backup mit den Standardeinstellungen wiederherzustellen:
RESTORE DATABASE [bt]
FROM DISK = 'D:SQLServerbackupbt.bak'
WITH REPLACE, RECOVERY;Nun, Sie wissen selbst, dass es Möglichkeiten gibt, Ersetzen ist nicht Ersetzen, Wiederherstellung ist keine Wiederherstellung. Und ich mache es so:
1070072 Seiten für Datenbank „bt“, Datei „bt“ in Datei 1 verarbeitet.
2 Seiten für Datenbank „bt“, Datei „bt_log“ in Datei 1 verarbeitet.
RESTORE DATABASE hat 1070074 Seiten erfolgreich in 40.752 Sekunden (205.141 MB/s) verarbeitet.
Jetzt werde ich versuchen, Backups wiederherzustellen, die mit geänderter BLOCKSIZE, BUFFERCOUNT und MAXTRANSFERSIZE erstellt wurden.
BLOCKSIZE = 16384, BUFFERCOUNT = 224, MAXTRANSFERSIZE = 4194304RESTORE DATABASE hat 1070074 Seiten erfolgreich in 32.283 Sekunden (258.958 MB/s) verarbeitet.
BLOCKSIZE = 4096, BUFFERCOUNT = 448, MAXTRANSFERSIZE = 4194304RESTORE DATABASE hat 1070074 Seiten erfolgreich in 32.682 Sekunden (255.796 MB/s) verarbeitet.
BLOCKSIZE = 16384, BUFFERCOUNT = 448, MAXTRANSFERSIZE = 2097152RESTORE DATABASE hat 1070074 Seiten erfolgreich in 32.091 Sekunden (260.507 MB/s) verarbeitet.
BLOCKSIZE = 4096, BUFFERCOUNT = 56, MAXTRANSFERSIZE = 4194304RESTORE DATABASE hat 1070074 Seiten erfolgreich in 32.401 Sekunden (258.015 MB/s) verarbeitet.
Die RESTORE DATABASE-Anweisung ändert sich während der Wiederherstellung nicht; diese Parameter werden darin nicht angegeben; SQL Server selbst ermittelt sie aus der Sicherung. Und es ist klar, dass es auch bei Erholung einen Gewinn geben kann – fast 20 % schneller (Um ehrlich zu sein, habe ich nicht viel Zeit mit der Wiederherstellung verbracht, sondern mehrere der „schnellsten“ Backups durchgesehen und sichergestellt, dass es zu keiner Verschlechterung kam).
Für alle Fälle möchte ich klarstellen, dass dies nicht einige Parameter sind, die für jeden optimal sind. Die für Sie optimalen Parameter können Sie nur durch Ausprobieren ermitteln. Ich habe diese Ergebnisse erhalten, Sie werden andere erhalten. Aber Sie sehen, dass Sie Ihre Backups „tunen“ können und sie tatsächlich schneller erstellen und bereitstellen können.
Ich empfehle Ihnen außerdem dringend, die Dokumentation vollständig zu lesen, da es systemspezifische Nuancen geben kann.
Da ich angefangen habe, über Backups zu schreiben, möchte ich sofort über eine weitere „Optimierung“ schreiben, die häufiger vorkommt als die „Optimierung“ von Parametern (soweit ich weiß, wird sie von zumindest einigen Backup-Dienstprogrammen verwendet, vielleicht zusammen mit den Parametern). beschrieben), wurde aber auch bei Habré noch nicht beschrieben.
Wenn wir uns die zweite Zeile in der Dokumentation direkt unter BACKUP DATABASE ansehen, sehen wir:
TO <backup_device> [ ,...n ]Was wird Ihrer Meinung nach passieren, wenn Sie mehrere Backup-Geräte angeben? Die Syntax erlaubt es. Und es wird etwas sehr Interessantes passieren: Das Backup wird einfach auf mehrere Geräte „verteilt“. Diese. Jedes einzelne „Gerät“ ist unbrauchbar, eines geht verloren, das gesamte Backup geht verloren. Aber wie wirkt sich eine solche Verschmierung auf die Backup-Geschwindigkeit aus?
Versuchen wir, ein Backup auf zwei „Geräten“ zu erstellen, die sich nebeneinander im selben Ordner befinden:
BACKUP DATABASE [bt]
TO
DISK = 'D:SQLServerbackupbt1.bak',
DISK = 'D:SQLServerbackupbt2.bak'
WITH COMPRESSION;Weltväter, warum wird das getan?
1070072 Seiten für Datenbank „bt“, Datei „bt“ in Datei 1 verarbeitet.
2 Seiten für Datenbank „bt“, Datei „bt“ verarbeitetlog‘ in Datei 1.
BACKUP DATABASE hat 1070074 Seiten erfolgreich in 40.092 Sekunden (208.519 MB/s) verarbeitet.
Ist das Backup aus heiterem Himmel 25 % schneller geworden? Was wäre, wenn wir noch ein paar weitere Geräte hinzufügen würden?
BACKUP DATABASE [bt]
TO
DISK = 'D:SQLServerbackupbt1.bak',
DISK = 'D:SQLServerbackupbt2.bak',
DISK = 'D:SQLServerbackupbt3.bak',
DISK = 'D:SQLServerbackupbt4.bak'
WITH COMPRESSION;BACKUP DATABASE hat 1070074 Seiten erfolgreich in 34.234 Sekunden (244.200 MB/s) verarbeitet.
Insgesamt beträgt der Zeitgewinn bei der Erstellung eines Backups etwa 35 %, da das Backup gleichzeitig in 4 Dateien auf einer Festplatte geschrieben wird. Ich habe eine größere Anzahl überprüft – auf meinem Laptop gibt es keinen Gewinn, optimalerweise – 4 Geräte. Für Sie – ich weiß es nicht, Sie müssen es überprüfen. Übrigens, wenn Sie diese Geräte haben – das sind wirklich unterschiedliche Festplatten, herzlichen Glückwunsch, der Gewinn dürfte noch deutlicher ausfallen.
Lassen Sie uns nun darüber sprechen, wie wir dieses Glück wiederherstellen können. Dazu müssen Sie den Wiederherstellungsbefehl ändern und alle Geräte auflisten:
RESTORE DATABASE [bt]
FROM
DISK = 'D:SQLServerbackupbt1.bak',
DISK = 'D:SQLServerbackupbt2.bak',
DISK = 'D:SQLServerbackupbt3.bak',
DISK = 'D:SQLServerbackupbt4.bak'
WITH REPLACE, RECOVERY;RESTORE DATABASE hat 1070074 Seiten erfolgreich in 38.027 Sekunden (219.842 MB/s) verarbeitet.
Etwas schneller, aber irgendwo in der Nähe, nicht signifikant. Im Allgemeinen wird das Backup schneller entfernt und auf die gleiche Weise wiederhergestellt – Erfolg? Für mich ist es ein ziemlicher Erfolg. Das wichtig, also wiederhole ich - wenn du Wenn Sie mindestens eine dieser Dateien verlieren, geht auch das gesamte Backup verloren.
Wenn Sie sich im Protokoll die mit den Trace Flags 3213 und 3605 angezeigten Backup-Informationen ansehen, werden Sie feststellen, dass sich bei der Sicherung auf mehreren Geräten zumindest die Anzahl der BUFFERCOUNT erhöht. Wahrscheinlich können Sie versuchen, optimalere Parameter für BUFFERCOUNT, BLOCKSIZE, MAXTRANSFERSIZE auszuwählen, aber das ist mir nicht auf Anhieb gelungen und ich war zu faul, einen solchen Test noch einmal durchzuführen, allerdings für eine andere Anzahl von Dateien. Und schade um die Räder. Wenn Sie solche Tests zu Hause organisieren möchten, ist es nicht schwierig, das Skript neu zu erstellen.
Lassen Sie uns abschließend über den Preis sprechen. Wenn das Backup parallel zur Arbeit der Benutzer entfernt wird, müssen Sie beim Testen sehr verantwortungsbewusst vorgehen, denn wenn das Backup schneller entfernt wird, werden die Festplatten stärker belastet, die Belastung des Prozessors steigt (Sie müssen immer noch komprimieren). es im laufenden Betrieb), und dementsprechend nimmt die allgemeine Reaktionsfähigkeit des Systems ab.
Nur ein Scherz, aber ich verstehe vollkommen, dass ich keine Enthüllungen gemacht habe. Was oben geschrieben wurde, ist lediglich eine Demonstration, wie Sie die optimalen Parameter für die Erstellung von Backups auswählen können.
Denken Sie daran, dass alles, was Sie tun, auf eigene Gefahr und Gefahr geschieht. Überprüfen Sie Ihre Backups und vergessen Sie nicht DBCC CHECKDB.
Source: habr.com
