

Einige Unternehmen, darunter auch unser Kunde, entwickeln das Produkt über ein Partnernetzwerk. Beispielsweise sind große Online-Shops in den Lieferservice integriert – Sie bestellen ein Produkt und erhalten bald eine Sendungsverfolgungsnummer für das Paket. Ein weiteres Beispiel ist der Kauf einer Versicherung oder eines Aeroexpress-Tickets zusammen mit Ihrem Flugticket.
Hierzu wird eine API verwendet, die über das API Gateway an Partner ausgegeben werden muss. Wir haben dieses Problem gelöst. In diesem Artikel verraten wir Ihnen die Details.
Gegeben: ein Ökosystem und ein API-Portal mit einer Schnittstelle, über die Benutzer registriert werden, Informationen erhalten usw. Wir müssen ein praktisches und zuverlässiges API-Gateway erstellen. Dabei mussten wir etwas bereitstellen
- Anmeldung,
- API-Verbindungssteuerung,
- Überwachung, wie Benutzer das Endsystem nutzen,
- Bilanzierung von Geschäftsindikatoren.
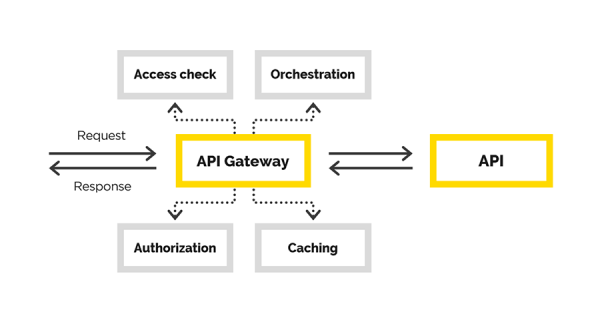
In dem Artikel werden wir über unsere Erfahrungen bei der Erstellung von API Gateway sprechen, bei denen wir die folgenden Aufgaben gelöst haben:
- Benutzerauthentifizierung,
- Benutzerberechtigung,
- Änderung des ursprünglichen Antrags,
- Anforderungs-Proxying,
- Antwortnachbearbeitung.
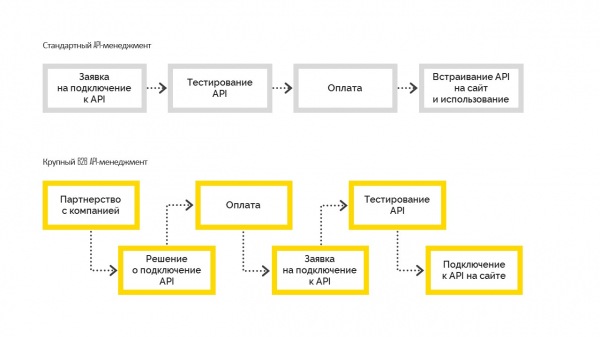
Es gibt zwei Arten der API-Verwaltung:
1. Standard, der wie folgt funktioniert. Bevor der Benutzer eine Verbindung herstellt, testet er die Funktionen, zahlt dann und bettet sie auf seiner Website ein. Am häufigsten werden sie in kleinen und mittleren Unternehmen eingesetzt.
2. Großes B2B-API-Management: Wenn das Unternehmen zum ersten Mal eine geschäftliche Entscheidung zur Verbindung trifft, wird es Partner des Unternehmens mit einer vertraglichen Verpflichtung und stellt dann eine Verbindung zur API her. Und nachdem alle Formalitäten geklärt sind, erhält das Unternehmen einen Testzugang, besteht die Tests und geht in die Produktion. Dies ist jedoch ohne eine Entscheidung des Managements zur Anbindung nicht möglich.
Unsere Lösung
In diesem Teil werden wir über die Erstellung eines API-Gateways sprechen.
Die Endnutzer des erstellten API-Gateways sind Partner unseres Kunden. Für jeden von ihnen liegen uns bereits die notwendigen Verträge vor. Wir müssen die Funktionalität lediglich erweitern, indem wir den gewährten Zugriff auf das Gateway markieren. Dementsprechend ist ein kontrollierter Verbindungs- und Managementprozess erforderlich.
Natürlich wäre es möglich, eine vorgefertigte Lösung zur Lösung des Problems des API-Managements und insbesondere der Erstellung eines API-Gateways zu verwenden. Dies könnte zum Beispiel sein. Es passte nicht zu uns, da wir in unserem Fall bereits über ein API-Portal und ein riesiges Ökosystem verfügten, das darauf aufgebaut war. Alle Benutzer sind bereits registriert und haben bereits verstanden, wo und wie sie die erforderlichen Informationen erhalten können. Die notwendigen Schnittstellen waren im API-Portal bereits vorhanden, wir benötigten lediglich das API Gateway. Eigentlich beschäftigen wir uns mit seiner Entwicklung.
Was wir API Gateway nennen, ist eine Art Proxy. Auch hier hatten wir die Wahl: Sie können Ihren eigenen Proxy schreiben oder etwas Vorgefertigtes auswählen. In diesem Fall sind wir den zweiten Weg gegangen und haben uns für das Nginx + Lua-Bundle entschieden. Warum? Wir brauchten zuverlässige, getestete Software, die die Skalierung unterstützt. Nach der Implementierung wollten wir nicht sowohl die Korrektheit der Geschäftslogik als auch die Korrektheit des Proxys überprüfen.
Jeder Webserver verfügt über eine Pipeline zur Anforderungsverarbeitung. Im Fall von Nginx sieht das so aus:
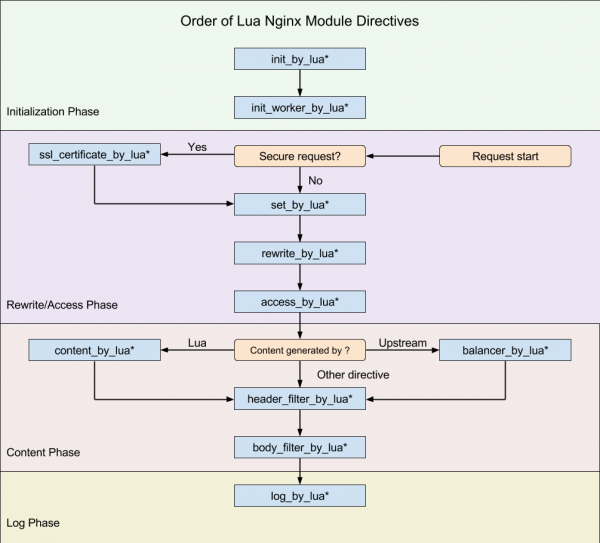
(Diagramm aus )
Unser Ziel war es, an einem Punkt in diese Pipeline zu passen, an dem wir die ursprüngliche Anfrage ändern können.
Wir möchten einen transparenten Proxy erstellen, damit die Anfrage funktional dieselbe bleibt, wie sie gekommen ist. Wir kontrollieren nur den Zugriff auf die endgültige API und helfen der Anfrage, dorthin zu gelangen. Falls die Anfrage falsch war, sollte die endgültige API den Fehler anzeigen, nicht jedoch wir. Der einzige Grund, warum wir eine Anfrage ablehnen können, besteht darin, dass der Kunde keinen Zugriff hat.
Existiert bereits für Nginx auf . Lua ist eine Skriptsprache, sie ist sehr leichtgewichtig und leicht zu erlernen. Daher haben wir die notwendige Logik mithilfe von Lua implementiert.
Die Nginx-Konfiguration (eine Analogie zur Route der Anwendung), in der die ganze Arbeit erledigt wird, ist durchaus verständlich. Bemerkenswert ist hier die letzte Direktive – post_action.
location /middleware {
more_clear_input_headers Accept-Encoding;
lua_need_request_body on;
rewrite_by_lua_file 'middleware/rewrite.lua';
access_by_lua_file 'middleware/access.lua';
proxy_pass https://someurl.com;
body_filter_by_lua_file 'middleware/body_filter.lua';
post_action /process_session;
}
Überlegen Sie, was in dieser Konfiguration passiert:
more_clear_input_headers – löscht den Wert der nach der Direktive angegebenen Header.
lua_need_request_body – steuert, ob der ursprüngliche Anfragetext vor der Ausführung der rewrite/access/access_by_lua-Anweisungen gelesen werden soll oder nicht. Standardmäßig liest Nginx den Hauptteil einer Client-Anfrage nicht. Wenn Sie darauf zugreifen müssen, sollte diese Anweisung aktiviert sein.
rewrite_by_lua_file – der Pfad zum Skript, das die Logik zum Ändern der Anfrage beschreibt
access_by_lua_file – der Pfad zum Skript, der die Logik beschreibt, die den Zugriff auf die Ressource prüft.
Proxy_pass – URL, an die die Anfrage weitergeleitet wird.
body_filter_by_lua_file – der Pfad zum Skript, das die Logik zum Filtern der Anfrage vor der Rückgabe an den Client beschreibt.
Und endlich, post_aktion - eine offiziell nicht dokumentierte Anweisung, mit der Sie einige andere Aktionen ausführen können, nachdem die Antwort an den Kunden übermittelt wurde.
Als nächstes werden wir der Reihe nach beschreiben, wie wir unsere Probleme gelöst haben.
Autorisierung/Authentifizierung und Anforderungsänderung
Genehmigung
Wir haben Autorisierung und Authentifizierung mithilfe des Zertifikatzugriffs erstellt. Es gibt ein Root-Zertifikat. Jeder Neukunde des Kunden erhält sein persönliches Zertifikat, mit dem er auf die API zugreifen kann. Dieses Zertifikat wird im Serverabschnitt der Nginx-Einstellungen konfiguriert.
ssl on;
ssl_certificate /usr/local/openresty/nginx/ssl/cert.pem;
ssl_certificate_key /usr/local/openresty/nginx/ssl/cert.pem;
ssl_client_certificate /usr/local/openresty/nginx/ssl/ca.crt;
ssl_verify_client on;Änderung
Es stellt sich möglicherweise die berechtigte Frage: Was tun mit einem zertifizierten Client, wenn wir ihn plötzlich vom System trennen möchten? Stellen Sie Zertifikate für alle anderen Clients nicht erneut aus.
So gingen wir reibungslos an die nächste Aufgabe heran – die Änderung der ursprünglichen Anfrage. Die ursprüngliche Anfrage des Kunden gilt im Allgemeinen nicht für das endgültige System. Eine der Aufgaben besteht darin, der Anfrage die fehlenden Teile hinzuzufügen, um sie gültig zu machen. Der Punkt ist, dass die fehlenden Daten für jeden Kunden unterschiedlich sind. Wir wissen, dass ein Kunde mit einem Zertifikat zu uns kommt, von dem wir einen Fingerabdruck nehmen und die notwendigen Kundendaten aus der Datenbank extrahieren können.
Wenn Sie den Kunden irgendwann von unserem Dienst trennen müssen, verschwinden seine Daten aus der Datenbank und er kann nichts mehr tun.
Arbeiten mit Kundendaten
Wir mussten die Lösung hochverfügbar machen, insbesondere wie wir Kundendaten erhalten. Die Schwierigkeit besteht darin, dass die primäre Quelle dieser Daten ein Drittanbieterdienst ist, der keine unterbrechungsfreie und ausreichend hohe Geschwindigkeit garantiert.
Daher mussten wir eine hohe Verfügbarkeit der Kundendaten sicherstellen. Als Werkzeug haben wir uns entschieden was uns Folgendes bietet:
- schneller Zugriff auf Daten
- die Fähigkeit, einen Cluster aus mehreren Knoten zu organisieren, wobei die Daten auf verschiedenen Knoten repliziert werden.
Wir haben uns für die einfachste Strategie zur Übermittlung von Daten an den Cache entschieden:
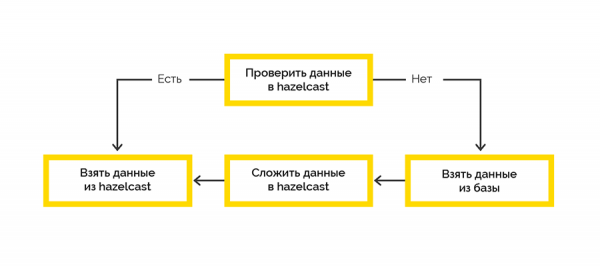
Die Arbeit mit dem Endsystem erfolgt innerhalb von Sitzungen und die maximale Anzahl ist begrenzt. Wenn der Kunde die Sitzung nicht geschlossen hat, müssen wir dies tun.
Die offenen Sitzungsdaten stammen vom Endsystem und werden zunächst auf Lua-Seite verarbeitet. Wir haben uns entschieden, Hazelcast zu verwenden, um diese Daten mit einem .NET-Job zu speichern. Dann überprüfen wir in bestimmten Abständen die Lebensberechtigung offener Sitzungen und schließen die faulen.
Zugriff auf Hazelcast sowohl über Lua als auch über .NET
Es gibt keine Lua-Clients, die mit Hazelcast arbeiten, aber Hazelcast verfügt über eine REST-API, für deren Verwendung wir uns entschieden haben. Für .NET gibt es , über die wir auf der .NET-Seite auf Hazelcast-Daten zugreifen wollten. Aber es war nicht da.
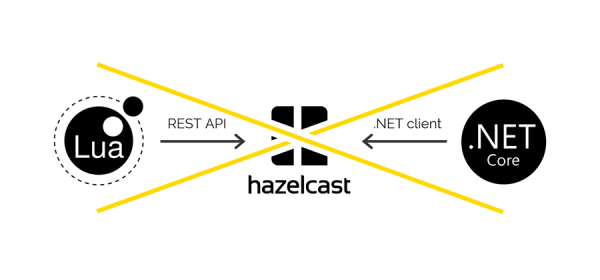
Beim Speichern von Daten über REST und beim Abrufen von Daten über einen .NET-Client werden unterschiedliche Serialisierer und Deserialisierer verwendet. Daher ist es unmöglich, Daten über REST zu übertragen, sie aber über den .NET-Client abzurufen und umgekehrt.
Bei Interesse werden wir Ihnen in einem separaten Artikel mehr über dieses Problem erzählen. Spoiler - zum Schaltplan.
Protokollierung und Überwachung
Unser Unternehmensstandard für die Protokollierung über .NET ist Serilog. Alle Protokolle landen in Elasticsearch und wir analysieren sie über Kibana. Ich würde in diesem Fall gerne etwas Ähnliches tun. Der Einzige Es wurde festgestellt, dass die Arbeit mit Elastic an Lua beim ersten Anfordern scheiterte. Und wir haben Fluentd verwendet.
- Open-Source-Lösung zur Bereitstellung einer einzigen Ebene der Anwendungsprotokollierung. Ermöglicht das Sammeln von Protokollen aus verschiedenen Ebenen der Anwendung und deren Übertragung an eine einzige Quelle.
API Gateway funktioniert in K8S, daher haben wir uns entschieden, einen Container mit fluentd im selben Pody hinzuzufügen, um Protokolle in den vorhandenen offenen TCP-Port fluentd zu schreiben.
Wir haben auch untersucht, wie fluentd sich verhalten würde, wenn es keine Verbindung zu Elasticsearch hätte. Zwei Tage lang wurden ununterbrochen Anfragen an das Gateway gesendet, Protokolle wurden an fluentd gesendet, aber fluentd wurde von IP Elastic gesperrt. Nachdem die Verbindung wiederhergestellt war, überholte Fluentd absolut alle Protokolle in Elastic.
Fazit
Der gewählte Implementierungsansatz ermöglichte es uns, in nur 2.5 Monaten ein wirklich funktionierendes Produkt in die Kampfumgebung zu liefern.
Wenn Sie eines Tages solche Dinge tun, empfehlen wir Ihnen, zunächst einmal klar zu verstehen, welches Problem Sie lösen und über welche Ressourcen Sie bereits verfügen. Seien Sie sich der Komplexität der Integration in bestehende API-Managementsysteme bewusst.
Verstehen Sie selbst, was genau Sie entwickeln werden – nur die Geschäftslogik zur Verarbeitung von Anfragen oder, wie es in unserem Fall sein könnte, den gesamten Proxy. Vergessen Sie nicht, dass alles, was Sie selbst tun, anschließend gründlich getestet werden muss.
Source: habr.com
