

Hinweis.: Die Anpassung von Kubernetes in GitLab wird als einer der beiden Hauptfaktoren angesehen, die zum Wachstum des Unternehmens beigetragen haben. Bis vor kurzem war die Infrastruktur des Online-Dienstes GitLab.com jedoch auf virtuellen Maschinen aufgebaut, und erst vor etwa einem Jahr begann die Migration zu K8s, die noch nicht abgeschlossen ist. Wir freuen uns, die Übersetzung eines aktuellen Artikels eines SRE-Ingenieurs von GitLab darüber zu präsentieren, wie dieser Prozess verläuft und welche Erkenntnisse die Ingenieure, die an dem Projekt beteiligt sind, sammeln.
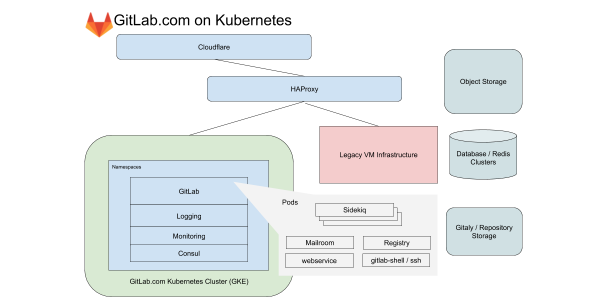
Seit fast einem Jahr arbeitet unsere Infrastrukturabteilung an der Migration aller Dienste von GitLab.com zu Kubernetes. Während dieser Zeit sind wir auf Herausforderungen gestoßen, die nicht nur mit der Überführung von Diensten in Kubernetes zusammenhingen, sondern auch mit dem Management von hybriden Deployments während des Übergangs. In diesem Artikel berichten wir über die wertvollen Lektionen, die wir dabei gelernt haben.
Von Anfang an betrieb GitLab.com seine Server in der Cloud auf virtuellen Maschinen. Diese virtuellen Maschinen werden mit Chef verwaltet, und ihre Installation erfolgt über unser . Falls ein Update der Anwendung erforderlich ist, erfolgt dies durch ein einfaches, koordiniertes sequenzielles Update des Serverparks mittels eines CI-Pipelines. Diese Methode – zwar langsam und etwas – gewährleistet, dass GitLab.com die gleichen Installationstechniken und Konfigurationen anwendet wie die Nutzer von (self-managed) Installationen von GitLab, die hierfür unsere Linux-Pakete verwenden.
Wir setzen diese Methode ein, da es von entscheidender Bedeutung ist, die Sorgen und Freuden der Community-Mitglieder zu erleben, während sie ihre eigenen Kopien von GitLab installieren und konfigurieren. Dieser Ansatz hat eine Zeit lang gut funktioniert, jedoch haben wir, als die Anzahl der Projekte auf GitLab die 10 Millionen-Grenze überschritt, erkannt, dass er unseren Anforderungen an Skalierung und Bereitstellung nicht mehr gerecht wird.
Die ersten Schritte zu Kubernetes und cloud-native GitLab
Im Jahr 2017 wurde das Projekt zur Vorbereitung von GitLab für die Bereitstellung in der Cloud und um den Benutzern die Installation von GitLab in Kubernetes-Clustern zu ermöglichen. Zu diesem Zeitpunkt wussten wir, dass die Migration von GitLab zu Kubernetes die Skalierbarkeit der SaaS-Plattform verbessern, die Bereitstellungen vereinfachen und die Effizienz der Nutzung von Compute-Ressourcen steigern würde. Gleichzeitig war jedoch viele Funktionen unserer Anwendung von angebundenen NFS-Volumes abhängig, was den Übergang von virtuellen Maschinen verlangsamt hat.
Das Streben nach Cloud-Native und Kubernetes hat es unseren Ingenieuren ermöglicht, einen schrittweisen Übergang zu planen, bei dem wir einige Abhängigkeiten der Anwendung von Netzwerkspeichern aufgegeben haben, während wir weiterhin neue Funktionen entwickelt haben. Seit wir im Sommer 2019 mit der Planung der Migration begonnen haben, wurden viele dieser Einschränkungen beseitigt, und der Prozess der Überführung von GitLab.com nach Kubernetes schreitet nun in vollem Umfang voran!
Besonderheiten des Betriebs von GitLab.com in Kubernetes
Für GitLab.com verwenden wir einen einheitlichen regionalen GKE-Cluster, der den gesamten Anwendungsverkehr verarbeitet. Um die bereits komplexe Migration zu minimieren, konzentrieren wir uns auf Dienste, die nicht von lokalem Speicher oder NFS abhängen. GitLab.com verwendet hauptsächlich einen monolithischen Code auf Rails, und wir leiten den Verkehr je nach Merkmalen der Arbeitslast zu verschiedenen Endpunkten weiter, die in eigenen Knotengruppen isoliert sind.
Im Frontend werden diese Typen in Anfragen an Web, API, Git SSH/HTTPS und Registry unterteilt. Im Backend teilen wir Jobs in den Warteschlangen nach verschiedenen Merkmalen auf, je nach , die es uns ermöglichen, Zielservicelevel (Service-Level Objectives, SLOs) für unterschiedliche Lasten festzulegen.
Alle diese GitLab.com-Dienste sind mit Hilfe des unveränderten Helm-Charts von GitLab konfiguriert. Die Konfiguration erfolgt in Subcharts, die nach und nach aktiviert werden können, während wir die Dienste schrittweise in das Cluster migrieren. Auch wenn entschieden wurde, bestimmte unserer zustandsbehafteten Dienste wie Redis, Postgres, GitLab Pages und Gitaly nicht in die Migration einzubeziehen, ermöglicht Kubernetes eine drastische Reduzierung der Anzahl der VMs, die derzeit von Chef verwaltet werden.
Transparenz und Konfigurationsmanagement von Kubernetes
Alle Einstellungen werden von GitLab selbst verwaltet. Dazu verwenden wir drei Konfigurationsprojekte basierend auf Terraform und Helm. Wo immer möglich, versuchen wir, GitLab selbst für den Betrieb von GitLab zu nutzen, aber für betriebliche Aufgaben haben wir eine separate Instanz von GitLab in Betrieb. Diese ist notwendig, um nicht von der Verfügbarkeit von GitLab.com bei Bereitstellungen und Updates von GitLab.com abhängig zu sein.
Obwohl unsere Pipelines für das Kubernetes-Cluster auf einer separaten Instanz von GitLab arbeiten, gibt es von den Code-Repositories Mirror, die öffentlich unter folgenden Adressen verfügbar sind:
- — Konfigurationsanpassung von GitLab.com für das Helm-Chart von GitLab;
- — enthält Konfigurationen für Dienste, die nicht direkt mit der GitLab-Anwendung verbunden sind. Dazu gehören Konfigurationen für das Logging und Monitoring des Clusters sowie für integrierte Tools wie PlantUML;
- — Terraform-Konfiguration für Kubernetes und die alte (Legacy) VM-Infrastruktur. Hier werden alle Ressourcen konfiguriert, die für den Betrieb des Clusters erforderlich sind, einschließlich des Clusters selbst, der Node-Pools, der Dienstkonten und der IP-Adressreservierung.

Bei Änderungen wird eine öffentlich zugängliche mit einem Link zu einem detaillierten Diff angezeigt, das die SRE vor der Durchführung von Änderungen am Cluster analysiert.
Für SRE führt der Link zu einem detaillierten Diff in der GitLab-Installation, die für den Betrieb verwendet wird und dessen Zugang eingeschränkt ist. Dies ermöglicht Mitarbeitern und der Community, die keinen Zugang zum Betriebsprojekt haben (das nur für SRE offen ist), die vorgeschlagenen Änderungen in der Konfiguration einzusehen. Durch die Kombination eines öffentlichen GitLab-Exemplars für den Code mit einem geschlossenen Exemplar für CI-Pipelines gewährleisten wir einen einheitlichen Arbeitsablauf und gleichzeitig die Unabhängigkeit von GitLab.com bei Konfigurationsupdates.
Was wir während der Migration herausgefunden haben
Im Zuge des Umzugs haben wir Erfahrungen gesammelt, die wir bei neuen Migrationen und Deployments in Kubernetes anwenden.
1. Steigende Kosten durch den Datenverkehr zwischen Verfügbarkeitszonen

Tägliche Egress-Statistiken (Bytes pro Tag) für den Git-Speicherpool auf GitLab.com
Google unterteilt sein Netzwerk in Regionen, die wiederum in Verfügbarkeitszonen (AZ) gegliedert sind. Da Git-Hosting mit großen Datenmengen verbunden ist, ist es für uns wichtig, den Netzwerk-Egress zu kontrollieren. Bei internem Traffic ist der Egress nur dann kostenlos, wenn er innerhalb einer einzigen Verfügbarkeitszone bleibt. Zum Zeitpunkt der Erstellung dieses Artikels geben wir an einem normalen Arbeitstag etwa 100 TB Daten aus (und das gilt nur für Git-Repositories). Dienste, die in unserer alten VM-basierten Topologie auf denselben virtuellen Maschinen liefen, arbeiten jetzt in verschiedenen Kubernetes-Pods. Das bedeutet, dass ein Teil des Traffics, der früher lokal für die VM war, potenziell die Grenzen der Verfügbarkeitszonen überschreiten kann.
Regionale GKE-Cluster ermöglichen es, mehrere Verfügbarkeitszonen für die Redundanz abzudecken. Wir ziehen in Betracht, für Dienste, die große Datenmengen erzeugen. Dies wird helfen, die Egress-Kosten zu senken und gleichzeitig die Cluster-Redundanz beizubehalten.
2. Limits, Ressourcenzuteilungen und Skalierung

Die Anzahl der Replikate, die den Produktionsverkehr auf registry.gitlab.com verarbeiten. Der Verkehr erreicht seinen Höhepunkt um ca. 15:00 UTC.
Unsere Geschichte mit der Migration begann im August 2019, als wir den ersten Dienst – das GitLab Container Registry – in Kubernetes umgezogen haben. Dieser kritische Hochverkehrs-Dienst eignete sich gut für die erste Migration, da es sich um eine zustandslose Anwendung mit wenigen externen Abhängigkeiten handelt. Das erste Problem, mit dem wir konfrontiert waren, war die große Anzahl an verdrängten Pods aufgrund von Speichermangel auf den Knoten. Deshalb mussten wir die Requests und Limits anpassen.
Es wurde festgestellt, dass bei Anwendungen, deren Speicherverbrauch im Laufe der Zeit ansteigt, niedrige Werte für die Requests (die Speicher für jeden Pod reservieren) in Kombination mit einem 'großzügigen' festen Limit für die Nutzung zu einer Sättigung führten. (saturation) der Knoten und einem hohen Niveau an Verdrängungen. Um dieses Problem zu lösen, wurde . Dies reduzierte den Druck auf die Knoten und gewährleistete einen Lebenszyklus der Pods, der nicht zu viel Druck auf den Knoten ausübte. Jetzt beginnen wir mit Migrationen unter großzügigen (und fast identischen) Werten für Requests und Limits, die wir nach Bedarf anpassen.
3. Metriken und Protokolle

Die Infrastrukturabteilung konzentriert sich auf Latenzen, Fehlerquoten und die Saturation gemäß den festgelegten (SLO), die an .
gebunden sind. Im vergangenen Jahr waren eine der Schlüsselentwicklungen in der Infrastrukturabteilung Verbesserungen im Monitoring und im Umgang mit SLO. SLO ermöglichten es uns, Ziele für einzelne Dienste zu setzen, die wir während der Migration sorgfältig verfolgt haben. Aber selbst bei dieser verbesserten Sichtbarkeit ist es nicht immer möglich, Probleme sofort zu erkennen, wenn man Metriken und Alarme verwendet. Zum Beispiel, indem wir uns auf Latenzen und Fehlerquoten konzentrieren, erfassen wir nicht alle Nutzungsszenarien des Dienstes, der migriert wird.
Dieses Problem wurde nahezu sofort nach der Verlagerung eines Teils der Arbeitslasten in den Cluster festgestellt. Besonders deutlich trat es zutage, als wir Funktionen überprüfen mussten, bei denen die Anzahl der Anfragen zwar gering ist, jedoch sehr spezifische Konfigurationsabhängigkeiten bestehen. Eine der wichtigsten Lektionen aus der Migration war, dass wir bei der Überwachung nicht nur Metriken, sondern auch Protokolle und den "langen Schwanz" berücksichtigen müssen. (es handelt sich um im Diagramm - Anm. des Übersetzers) Fehler. Jetzt führen wir für jede Migration eine detaillierte Liste der Protokollanfragen ein (log queries) und planen klare Rollback-Verfahren, die im Falle von Problemen von einem Schichtwechsel zur nächsten übergeben werden können.
Die parallele Verarbeitung derselben Anfragen in der alten VM-Infrastruktur und in der neuen, die auf Kubernetes basiert, stellte eine einzigartige Herausforderung dar. Im Gegensatz zu einer Lift-and-Shift-Migration (schnelle Übertragung von Anwendungen "wie sie sind" in die neue Infrastruktur; mehr dazu kann man zum Beispiel lesen, — Anmerkung des Übersetzers)., der parallele Betrieb auf "alten" VMs und Kubernetes erfordert, dass die Überwachungstools mit beiden Umgebungen kompatibel sind und Metriken in einer einheitlichen Ansicht aggregieren können. Wichtig ist, dass wir dieselben Dashboards und Log-Abfragen verwenden, um während der Übergangszeit eine konsistente Beobachtbarkeit zu gewährleisten.
4. Umleitung des Traffics auf den neuen Cluster
Für GitLab.com wird ein Teil der Server für die reserviert. Der Canary-Park bedient unsere internen Projekte und kann . Zunächst dient er jedoch zur Überprüfung von Änderungen, die an der Infrastruktur und der Anwendung vorgenommen werden. Der erste migrierte Dienst begann mit der Annahme eines begrenzten Volumens an internem Traffic, und wir verwenden weiterhin diese Methode, um die Einhaltung der SLO sicherzustellen, bevor wir den gesamten Traffic in den Cluster leiten.
Bei der Migration bedeutet dies, dass zunächst in Kubernetes Anfragen an interne Projekte gesendet werden, während wir allmählich den restlichen Datenverkehr über HAProxy umleiten, indem wir das Gewicht für das Backend ändern. Im Prozess des Wechsels von VMs zu Kubernetes wurde deutlich, dass es sehr vorteilhaft ist, eine einfache Methode zur Umleitung von Datenverkehr zwischen der alten und der neuen Infrastruktur bereit zu haben und die alte Infrastruktur für die ersten Tage nach der Migration bereitzuhalten.
5. Backup-Kapazitäten der Pods und deren Nutzung
Fast sofort trat das folgende Problem auf: Die Pods für den Registry-Service starteten schnell, jedoch dauerte der Start der Pods für Sidekiq bis zu . Der lange Start der Pods für Sidekiq wurde problematisch, als wir mit der Migration der Arbeitslasten für die Worker in Kubernetes begannen, die Jobs schnell bearbeiten und schnell skalieren müssen.
In diesem Fall lag die Lektion darin, dass der Horizontal Pod Autoscaler (HPA) in Kubernetes zwar gut mit steigendem Traffic umgehen kann, es jedoch wichtig ist, die Eigenschaften der Arbeitslasten zu berücksichtigen und Reserven für Pods bereitzustellen (insbesondere bei ungleichmäßiger Nachfragedistribution). In unserem Fall gab es einen plötzlichen Anstieg von Jobs, der eine rasante Skalierung zur Folge hatte, wodurch die CPU-Ressourcen vor der eigentlichen Skalierung des Node-Pools ausgelastet wurden.
Es besteht immer die Versuchung, so viel wie möglich aus dem Cluster herauszuholen, doch nachdem wir anfangs mit Performance-Problemen konfrontiert waren, starten wir jetzt mit einem großzügigen Pod-Budget und verringern es anschließend, während wir die SLOs genau im Auge behalten. Der Start der Pods für den Sidekiq-Service hat sich deutlich beschleunigt und dauert nun im Durchschnitt etwa 40 Sekunden. haben sowohl GitLab.com als auch unsere Nutzer, die mit der offiziellen GitLab-Helm-Chart arbeiten und selbstverwaltete Installationen betreiben, profitiert.
Fazit
Nach der Migration jedes Dienstes haben wir die Vorteile von Kubernetes in der Produktion genossen: schnellere und sicherere Bereitstellung von Anwendungen, Skalierung und effizientere Ressourcennutzung. Darüber hinaus gehen die Vorteile der Migration über den Dienst GitLab.com hinaus. Jeder Nutzer profitiert von den Verbesserungen des offiziellen Helm-Charts.
Ich hoffe, Ihnen hat die Geschichte über unsere Abenteuer mit der Migration zu Kubernetes gefallen. Wir setzen die Migration weiterer Dienste in den Cluster fort. Weitere Informationen finden Sie in den folgenden Veröffentlichungen:
- «»;
- «»;
- .
P.S. vom Übersetzer
Lesen Sie auch in unserem Blog:
- «»;
- «»;
- «»;
- «».
Quelle: habr.com
