

Die Zeiten, in denen man sich keine Gedanken über die Optimierung der Datenbankleistung machen musste, sind vorbei. Die Zeit bleibt nicht stehen. Jeder neue Unternehmer im Technologiebereich möchte das nächste Facebook schaffen und dabei alle Daten sammeln, die ihm zugänglich sind. Diese Daten sind für Unternehmen erforderlich, um qualitativ hochwertige Modelle zu trainieren, die helfen, Gewinne zu generieren. Unter diesen Bedingungen müssen Programmierer APIs erstellen, die es ermöglichen, schnell und zuverlässig mit großen Datenmengen zu arbeiten.
Wenn Sie bereits seit einiger Zeit an der Gestaltung von Server-Komponenten oder Datenbanken arbeiten, haben Sie wahrscheinlich Code geschrieben, um paginierte Anfragen auszuführen. Zum Beispiel solchen:
SELECT * FROM table_name LIMIT 10 OFFSET 40
Stimmt das?
Aber wenn Sie die Paginierung genau so durchgeführt haben, muss ich leider sagen, dass Sie das bei weitem nicht am effizientesten gemacht haben.
Möchten Sie mir widersprechen? . , und verwenden bereits Techniken, über die ich heute sprechen möchte.
Nennen Sie mindestens einen Backend-Entwickler, der niemals genutzt hat OFFSET und LIMIT um Anfragen mit Seitenaufteilung durchzuführen. In MVPs (Minimum Viable Product) und in Projekten mit kleinen Datenmengen ist dieser Ansatz durchaus praktikabel. Er funktioniert einfach.
Wenn jedoch zuverlässige und effiziente Systeme von Grund auf erstellt werden müssen, sollte im Voraus auf die Effizienz der Datenbankabfragen geachtet werden, die in solchen Systemen verwendet werden.
Heute sprechen wir über die Probleme, die mit den weit verbreiteten (leider) Implementierungen von Anfragen mit Seitenaufteilung verbunden sind, und darüber, wie man eine hohe Leistung bei der Ausführung solcher Anfragen erreichen kann.
Was ist falsch mit OFFSET und LIMIT?
Wie bereits erwähnt, OFFSET und LIMIT zeigen sich in Projekten, in denen keine großen Datenmengen verarbeitet werden müssen, hervorragend.
Das Problem tritt auf, wenn die Datenbank so groß wird, dass sie nicht mehr in den RAM des Servers passt. Aber während der Arbeit mit dieser Datenbank müssen trotzdem Anfragen mit Seitenaufteilung verwendet werden.
Damit dieses Problem auftritt, muss eine Situation entstehen, in der das DBMS bei der Ausführung jeder Anfrage mit Paging eine ineffiziente vollständige Tabellenscan-Operation (Full Table Scan) durchführt (während gleichzeitig Daten eingefügt oder gelöscht werden können, und veraltete Daten sind dabei nicht erforderlich!).
Was ist ein „vollständiger Tabellenscan“ (oder „sequentieller Tabellenscan“, Sequential Scan)? Dies ist eine Operation, bei der das DBMS jede Zeile der Tabelle sequentiell liest, das heißt, die darin enthaltenen Daten überprüft und mit einer bestimmten Bedingung vergleicht. Es ist bekannt, dass dieser Typ des Tabellenscans der langsamste ist. Das liegt daran, dass bei seiner Ausführung viele Ein-/Ausgabeoperationen beteiligt sind, die das Speichersystem des Servers beanspruchen. Die Situation wird durch die Verzögerungen, die mit der Arbeit mit auf der Festplatte gespeicherten Daten verbunden sind, und die Tatsache, dass der Datentransfer von der Festplatte in den Speicher eine ressourcenintensive Operation ist, verschärft.
Zum Beispiel haben Sie Aufzeichnungen über 100000000 Benutzer, und Sie führen eine Anfrage mit der Konstruktion aus OFFSET 50000000. Das bedeutet, dass das DBMS all diese Datensätze laden muss (obwohl wir sie eigentlich nicht benötigen!), sie im Speicher ablegen und dann beispielsweise 20 Ergebnisse abrufen muss, die in LIMIT.
So könnte es aussehen: „Wählen Sie die Zeilen von 50000 bis 50020 aus 100000“. Das heißt, das System muss zuerst 50000 Zeilen laden, um die Anfrage auszuführen. Sehen Sie, wie viel unnötige Arbeit es leisten muss?
Wenn Sie es nicht glauben, werfen Sie einen Blick auf das Beispiel, das ich unter Verwendung der Möglichkeiten erstellt habe. .
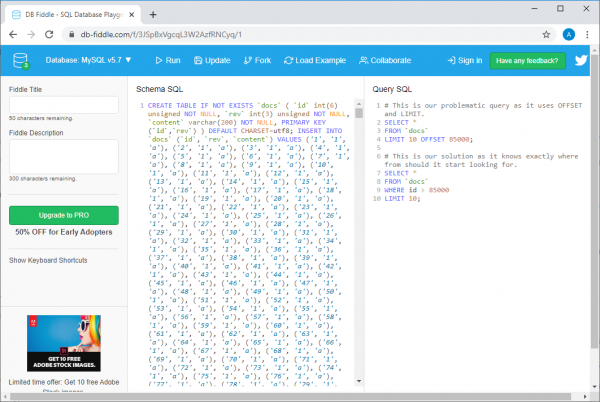
Beispiel auf db-fiddle.com
Dort, links im Feld Schema SQL, befindet sich der Code, der das Einfügen von 100000 Zeilen in die Datenbank ausführt, während rechts im Feld Query SQL, zwei Anfragen dargestellt sind. Die erste, langsame, sieht so aus:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
Und die zweite, die eine effiziente Lösung für dasselbe Problem darstellt, so:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Um diese Abfragen auszuführen, genügt ein Klick auf die Schaltfläche Ausführen oben auf der Seite. Wenn Sie dies tun, können wir die Informationen über die Abfragezeit vergleichen. Es stellt sich heraus, dass bei der Ausführung einer ineffizienten Anfrage mindestens 30-mal mehr Zeit benötigt wird als für die Ausführung der zweiten (von Durchlauf zu Durchlauf kann sich diese Zeit unterscheiden; beispielsweise kann das System melden, dass die Ausführung der ersten Anfrage 37 ms und die der zweiten 1 ms dauerte).
Und wenn die Datenmenge größer wird, sieht es noch schlechter aus (um dies zu überprüfen, werfen Sie einen Blick auf meine mit 10 Millionen Zeilen).
Was wir gerade besprochen haben, sollte Ihnen ein gewisses Verständnis dafür vermitteln, wie Anfragen an Datenbanken tatsächlich verarbeitet werden.
Bedenken Sie, dass je höher der Wert ist, OFFSET desto länger die Anfrage dauert.
Was sollte stattdessen anstelle der Kombination OFFSET und LIMIT verwendet werden?
Anstelle der Kombination OFFSET und LIMIT sollte die folgende Konstruktion verwendet werden:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Dies ist die Ausführung der Abfrage mit paginierten Ergebnissen, basierend auf dem Cursor (cursorbasierte Paginierung).
Anstatt den aktuellen OFFSET und LIMIT und sie bei jeder Anfrage zu übermitteln, ist es notwendig, den zuletzt erhaltenen Primärschlüssel zu speichern (normalerweise ist das ID) und LIMIT, wodurch Anfragen entstehen, die den oben genannten ähneln.
Warum? Der Grund ist, dass Sie durch die explizite Angabe der ID der zuletzt gelesenen Zeile Ihrer DBMS mitteilen, wo sie mit der Suche nach den benötigten Daten beginnen soll. Dank der Verwendung des Schlüssels erfolgt die Suche effizient, da das System nicht abgelenkt wird von Zeilen, die außerhalb des angegebenen Bereichs liegen.
Lassen Sie uns einen Blick auf den folgenden Vergleich der Performance verschiedener Abfragen werfen. Hier ist eine ineffiziente Abfrage.
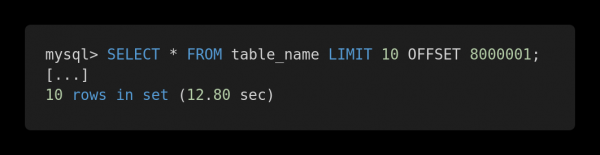
Langsame Anfrage
Und hier ist die optimierte Version dieser Abfrage.
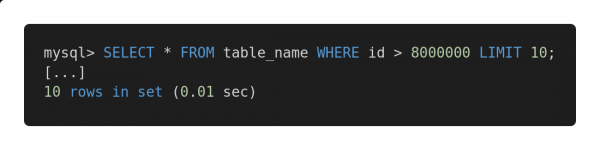
Schnelle Abfrage
Beide Abfragen geben genau denselben Datenumfang zurück. Doch die Ausführung der ersten dauert 12,80 Sekunden, während die zweite nur 0,01 Sekunde benötigt. Fühlen Sie den Unterschied?
Mögliche Probleme
Für die effektive Ausführung der vorgeschlagenen Abfragemethode ist es notwendig, dass die Tabelle eine oder mehrere Spalten mit einzigartigen, aufeinanderfolgenden Indizes wie einer Ganzzahl-ID enthält. In einigen speziellen Fällen kann dies den Erfolg der Anwendung solcher Abfragen zur Beschleunigung der Datenbankoperationen bestimmen.
Natürlich müssen beim Konstruieren von Abfragen die Besonderheiten der Tabellenarchitektur berücksichtigt werden, und es sollte die Mechanismen ausgewählt werden, die sich am besten in den gegebenen Tabellen bewähren. Zum Beispiel, wenn Sie bei Abfragen mit großen Mengen verwandter Daten arbeiten müssen, könnte für Sie interessant sein, Artikel.
Wenn wir mit dem Problem eines fehlenden Primärschlüssels konfrontiert sind, zum Beispiel wenn eine Tabelle mit einer "viele-zu-viele"-Beziehung vorliegt, dann erfordert der traditionelle Ansatz die Anwendung OFFSET und LIMIT, es ist garantiert geeignet. Allerdings kann die Anwendung zu potenziell langsamen Abfragen führen. In solchen Fällen würde ich empfehlen, einen Primärschlüssel mit automatischer Inkrementierung zu verwenden, auch wenn dieser nur zur Organisation der paginierten Abfragen benötigt wird.
Wenn Sie an diesem Thema interessiert sind — , und — hier sind einige nützliche Materialien.
Ergebnisse
Die Hauptschlussfolgerung, die wir ziehen können, ist, dass unabhängig von der Größe der Datenbanken immer die Geschwindigkeit der Abfragen analysiert werden muss. In der heutigen Zeit ist die Skalierbarkeit der Lösungen von entscheidender Bedeutung, und wenn man von Anfang an ein System richtig plant, kann man in der Zukunft dem Entwickler viele Probleme ersparen.
Wie analysieren und optimieren Sie die Abfragen in Datenbanken?
Quelle: habr.com
