

Vorwort
Häufig stoßen Benutzer, Entwickler und Administratoren von MS SQL Server-Datenbankmanagementsystemen auf Leistungsprobleme der Datenbank oder des gesamten Systems, weshalb die Überwachung von MS SQL Server von großer Bedeutung ist.
Dieser Artikel ist eine Ergänzung zu dem Artikel und behandelt einige Aspekte der Überwachung von MS SQL Server, insbesondere: wie man schnell feststellt, welche Ressourcen fehlen, sowie Empfehlungen zur Konfiguration von Trace-Flags.
Um die folgenden Skripte nutzen zu können, muss das Schema inf in der benötigten Datenbank wie folgt erstellt werden:
Erstellung des Schemas inf
use ;
go
create schema inf;
Methode zur Erkennung von unzureichendem Arbeitsspeicher
Ein erster Hinweis auf einen Mangel an Arbeitsspeicher ist der Fall, wenn das MS SQL Server-Exemplar den gesamten ihm zugewiesenen RAM beansprucht.
Dafür erstellen wir die folgende Ansicht inf.vRAM:
Erstellung der Ansicht inf.vRAM
ERSTELLEN Sie die Ansicht [inf].[vRAM] als
SELECT a.[TotalAvailOSRam_Mb] -- wie viel RAM auf dem Server in MB verfügbar ist
, a.[RAM_Avail_Percent] -- prozentualer Anteil des freien RAMs auf dem Server
, a.[Server_physical_memory_Mb] -- wie viel RAM insgesamt auf dem Server in MB vorhanden ist
, a.[SQL_server_committed_target_Mb] -- wie viel RAM insgesamt für MS SQL Server in MB zugewiesen ist
, a.[SQL_server_physical_memory_in_use_Mb] -- wie viel RAM MS SQL Server derzeit in MB verwendet
, a.[SQL_RAM_Avail_Percent] -- prozentualer Anteil des freien RAMs für MS SQL Server im Verhältnis zum gesamten zugewiesenen RAM für MS SQL Server
, a.[StateMemorySQL] -- ausreichend RAM für MS SQL Server
, a.[SQL_RAM_Reserve_Percent] -- prozentualer Anteil des zugewiesenen RAMs für MS SQL Server im Verhältnis zum gesamten RAM des Servers
-- ist genügend RAM für den Server vorhanden
, (CASE WHEN a.[RAM_Avail_Percent]5 AND a.[TotalAvailOSRam_Mb]<8192 THEN 'Warnung' WHEN a.[RAM_Avail_Percent]<=5 AND a.[TotalAvailOSRam_Mb]<2048 THEN 'Gefahr' ELSE 'Normal' END) AS [StateMemoryServer]
FROM
(
SELECT CAST(a0.available_physical_memory_kb/1024.0 AS INT) AS TotalAvailOSRam_Mb
, CAST((a0.available_physical_memory_kb/CAST(a0.total_physical_memory_kb AS FLOAT))*100 AS NUMERIC(5,2)) AS [RAM_Avail_Percent]
, a0.system_low_memory_signal_state
, CEILING(b.physical_memory_kb/1024.0) AS [Server_physical_memory_Mb]
, CEILING(b.committed_target_kb/1024.0) AS [SQL_server_committed_target_Mb]
, CEILING(a.physical_memory_in_use_kb/1024.0) AS [SQL_server_physical_memory_in_use_Mb]
, CAST(((b.committed_target_kb-a.physical_memory_in_use_kb)/CAST(b.committed_target_kb AS FLOAT))*100 AS NUMERIC(5,2)) AS [SQL_RAM_Avail_Percent]
, CAST((b.committed_target_kb/CAST(a0.total_physical_memory_kb AS FLOAT))*100 AS NUMERIC(5,2)) AS [SQL_RAM_Reserve_Percent]
, (CASE WHEN (CEILING(b.committed_target_kb/1024.0)-1024)<CEILING(a.physical_memory_in_use_kb/1024.0) THEN 'Warnung' ELSE 'Normal' END) AS [StateMemorySQL]
FROM sys.dm_os_sys_memory AS a0
CROSS JOIN sys.dm_os_process_memory AS a
CROSS JOIN sys.dm_os_sys_info AS b
CROSS JOIN sys.dm_os_sys_memory AS v
) AS a;
Um zu bestimmen, dass das MS SQL Server-Exemplar den ihm zugewiesenen Speicher vollständig nutzt, kann folgender Befehl verwendet werden:
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb
from [inf].[vRAM];
Wenn der Wert für SQL_server_physical_memory_in_use_Mb konstant nicht unter SQL_server_committed_target_Mb liegt, sollte die Wartestatistik überprüft werden.
Um den Mangel an Arbeitsspeicher anhand der Wartestatistik zu bestimmen, erstellen wir die Ansicht inf.vWaits:
Erstellen der Ansicht inf.vWaits
ERSTELLEN Sie die Ansicht [inf].[vWaits] als
MIT [Waits] AS
(SELECT
[wait_type], -- Name des Warte-Typs
[wait_time_ms] / 1000.0 AS [WaitS], -- Gesamte Wartezeit dieses Typs in Millisekunden. Diese Zeit umfasst signal_wait_time_ms
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS], -- Gesamte Wartezeit dieses Typs in Millisekunden ohne signal_wait_time_ms
[signal_wait_time_ms] / 1000.0 AS [SignalS], -- Differenz zwischen der Signalzeit des wartenden Threads und dem Zeitpunkt seines Starts
[waiting_tasks_count] AS [WaitCount], -- Anzahl der Wartezeiten dieses Typs. Dieser Zähler wird bei jedem Warten erhöht
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [waiting_tasks_count] > 0
AND [wait_type] NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT')
)
, ress AS (
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S], -- Gesamte Wartezeit dieses Typs in Millisekunden. Diese Zeit umfasst signal_wait_time_ms
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S], -- Gesamte Wartezeit dieses Typs in Millisekunden ohne signal_wait_time_ms
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S], -- Differenz zwischen der Signalzeit des wartenden Threads und dem Zeitpunkt seines Starts
[W1].[WaitCount] AS [WaitCount], -- Anzahl der Wartezeiten dieses Typs. Dieser Zähler wird bei jedem Warten erhöht
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95 -- Prozentgrenze
)
SELECT [WaitType]
,MAX([Wait_S]) AS [Wait_S]
,MAX([Resource_S]) AS [Resource_S]
,MAX([Signal_S]) AS [Signal_S]
,MAX([WaitCount]) AS [WaitCount]
,MAX([Percentage]) AS [Percentage]
,MAX([AvgWait_S]) AS [AvgWait_S]
,MAX([AvgRes_S]) AS [AvgRes_S]
,MAX([AvgSig_S]) AS [AvgSig_S]
FROM ress
GROUP BY [WaitType];
In diesem Fall kann der Mangel an RAM mit der folgenden Abfrage bestimmt werden:
SELECT [Percentage]
,[AvgWait_S]
FROM [inf].[vWaits]
where [WaitType] in (
'PAGEIOLATCH_XX',
'RESOURCE_SEMAPHORE',
'RESOURCE_SEMAPHORE_QUERY_COMPILE'
);
Hier sollten Sie besonders auf die Werte Percentage und AvgWait_S achten. Wenn sie in ihrer Gesamtheit erheblich sind, ist die Wahrscheinlichkeit hoch, dass dem MS SQL Server nicht genügend RAM zur Verfügung steht. Wesentliche Werte sind individuell für jedes System festzulegen. Sie können jedoch mit folgenden Werten beginnen: Percentage >= 1 und AvgWait_S >= 0.005.
Um die Kennzahlen in ein Monitoringsystem (zum Beispiel Zabbix) auszugeben, können Sie die folgenden zwei Abfragen erstellen:
- wie viel Prozent die Arten von Wartezeiten für den RAM ausmachen (Summe über alle solchen Wartearten):
select coalesce(sum([Percentage]), 0.00) as [Percentage] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' ); - wie viel in Millisekunden die Arten von Wartezeiten für den RAM ausmachen (maximaler Wert aus allen Durchschnittsverzögerungen für alle solchen Wartearten):
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Basierend auf der Dynamik der erhaltenen Werte dieser beiden Indikatoren kann geschlossen werden, ob genügend RAM für die MS SQL Server-Instanz vorhanden ist.
Methode zur Identifizierung von übermäßiger CPU-Auslastung
Zur Erkennung eines Mangels an CPU-Zeit genügt es, die Systemansicht sys.dm_os_schedulers zu nutzen. Hier gilt: Wenn der Wert von runnable_tasks_count konstant größer als 1 ist, besteht eine hohe Wahrscheinlichkeit, dass die Anzahl der Kerne für die MS SQL Server-Instanz nicht ausreicht.
Um den Indikator in ein Monitoring-System (z.B. Zabbix) zu überführen, kann die folgende Abfrage erstellt werden:
select max([runnable_tasks_count]) as [runnable_tasks_count]
from sys.dm_os_schedulers
where scheduler_id<255;
Basierend auf der Dynamik der erhaltenen Werte dieses Indikators kann geschlossen werden, ob ausreichend CPU-Zeit (Anzahl der CPU-Kerne) für die MS SQL Server-Instanz vorhanden ist.
Es ist jedoch wichtig, sich daran zu erinnern, dass die Anfragen mehrere Threads gleichzeitig anfordern können. Manchmal kann der Optimierer die Komplexität der Anfrage nicht richtig einschätzen. In diesem Fall könnten zu viele Threads zugewiesen werden, die zu einem bestimmten Zeitpunkt nicht gleichzeitig verarbeitet werden können. Dies führt ebenfalls zu einer Art von Wartezeit, die mit einem Mangel an CPU-Zeit verbunden ist, und es entsteht eine Warteschlange für Scheduler, die bestimmte CPU-Kerne nutzen. Daher wird der Wert von runnable_tasks_count unter diesen Bedingungen steigen.
In diesem Fall sollte, bevor die Anzahl der CPU-Kerne erhöht wird, die Parallelitätseigenschaften des MS SQL Server-Instances korrekt konfiguriert werden, und ab Version 2016 sollten die Parallelitätseigenschaften der relevanten Datenbanken richtig eingestellt werden:
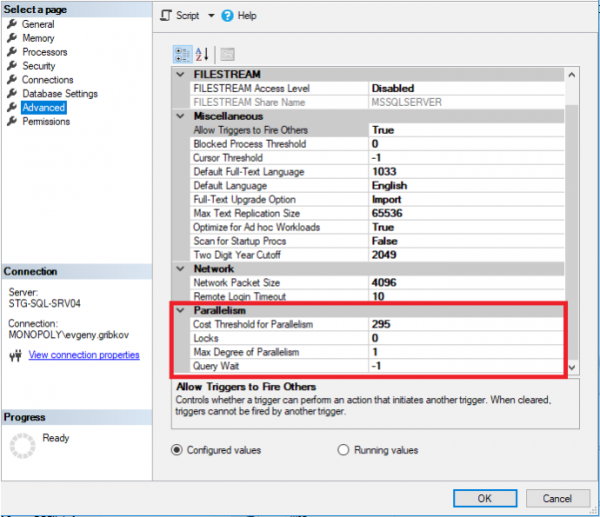
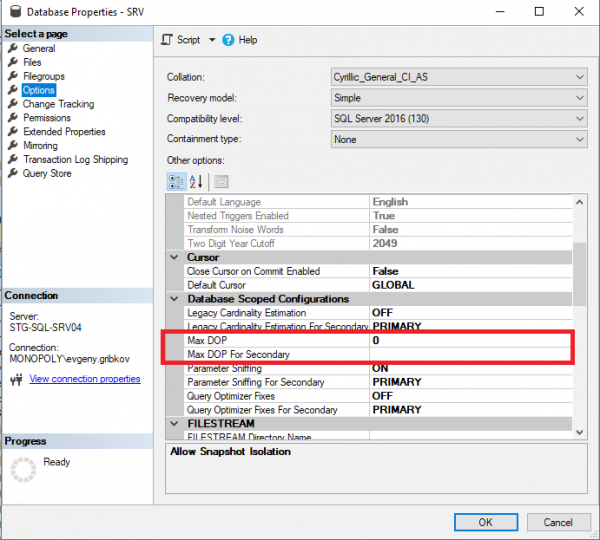
Hierbei sollten folgende Parameter beachtet werden:
- Max Degree of Parallelism - legt die maximale Anzahl an Threads fest, die jeder Anfrage zugewiesen werden können (standardmäßig auf 0, was nur durch das Betriebssystem und die Edition des MS SQL Servers begrenzt wird)
- Cost Threshold for Parallelism - die geschätzte Kosten für Parallelität (standardmäßig auf 5 eingestellt)
- Max DOP legt die maximale Anzahl an Threads fest, die jeder Anfrage auf Datenbankebene zugewiesen werden können (jedoch nicht mehr als den Wert der Eigenschaft „Max Degree of Parallelism“). Standardmäßig ist dies auf 0 eingestellt – eine Beschränkung, die nur durch das Betriebssystem und die Edition von MS SQL Server sowie durch die Eigenschaft „Max Degree of Parallelism“ für die gesamte Instanz von MS SQL Server bestimmt wird.
Hier kann kein allgemein gültiges Rezept für alle Fälle gegeben werden. Es ist notwendig, anspruchsvolle Abfragen zu analysieren.
Aus eigener Erfahrung empfehle ich den folgenden Handlungsalgorithmus für OLTP-Systeme zur Einstellung der Parallelitätseigenschaften:
- Zuerst Parallelität verbieten, indem man den Max Degree of Parallelism für die gesamte Instanz auf 1 setzt.
- Die schwersten Abfragen analysieren und die optimale Anzahl an Threads dafür bestimmen.
- Den Max Degree of Parallelism auf die ermittelte optimale Anzahl an Threads aus Punkt 2 setzen und für spezifische Datenbanken den Max DOP-Wert, der aus Punkt 2 gewonnen wurde, für jede Datenbank festlegen.
- Die schwersten Abfragen analysieren und die negativen Auswirkungen von Multithreading feststellen. Falls vorhanden, den Cost Threshold for Parallelism erhöhen.
Für Systeme wie 1C, Microsoft CRM und Microsoft NAV ist in den meisten Fällen eine Deaktivierung der Multithread-Funktionalität sinnvoll.
Falls die Standard-Edition verwendet wird, eignet sich ebenfalls in der Regel die Beschränkung der Multithreading-Funktion, da diese Edition in der Anzahl der CPU-Kerne limitiert ist.
Der oben beschriebene Algorithmus ist für OLAP-Systeme nicht geeignet.
Aus eigener Erfahrung empfehle ich den folgenden Aktionsablauf zur Einstellung der Parallelitätseigenschaften für OLAP-Systeme:
- Die schwersten Abfragen analysieren und die optimale Anzahl an Threads dafür bestimmen.
- Setzen Sie den Max Degree of Parallelism auf die optimal ermittelte Anzahl an Threads aus Punkt 1 und definieren Sie für jede spezifische Datenbank den Max DOP-Wert, der aus Punkt 1 abgeleitet wurde.
- Analysieren Sie die ressourcenintensivsten Abfragen und identifizieren Sie negative Effekte durch die Beschränkung der Parallelität. Falls vorhanden, reduzieren Sie entweder den Wert für Cost Threshold for Parallelism oder wiederholen Sie die Schritte 1-2 dieses Algorithmus.
Das heißt, für OLTP-Systeme gehen wir von der Ein- zur Mehrprozessverarbeitung, während wir bei OLAP-Systemen umgekehrt von der Mehrprozessverarbeitung zur Einprozessverarbeitung übergehen. So können die optimalen Parallelitätseinstellungen sowohl für spezifische Datenbanken als auch für die gesamte MS SQL Server-Instanz ausgewählt werden.
Es ist auch wichtig zu verstehen, dass die Einstellungen für die Parallelität im Laufe der Zeit angepasst werden müssen, basierend auf den Ergebnissen der Leistungsmessung von MS SQL Server.
Empfehlungen zur Konfiguration von Trace-Flags
Aus eigener Erfahrung und der Erfahrung meiner Kollegen empfehle ich, für eine optimale Leistung bei den Versionen 2008-2016 der MS SQL Server folgende Trace-Flags beim Start des MS SQL Server-Dienstes zu aktivieren:
- 610 — Reduzierung der Protokollierung von Einfügungen in indizierte Tabellen. Kann bei Einfügungen in Tabellen mit einer großen Anzahl von Datensätzen und vielen Transaktionen hilfreich sein, insbesondere bei häufigen langen Wartezeiten auf WRITELOG aufgrund von Änderungen an den Indizes.
- 1117 — Wenn eine Datei in der Dateigruppe die Anforderungen für die automatische Vergrößerung erfüllt, werden alle Dateien in der Dateigruppe vergrößert.
- 1118 — Erzwingt, dass alle Objekte in unterschiedlichen Extents angeordnet werden (Verbot von gemischten Extents), was die Notwendigkeit verringert, die SGAM-Seite zu scannen, die zur Nachverfolgung gemischter Extents verwendet wird.
- 1224 — Deaktiviert die Aggregation von Sperren basierend auf der Anzahl der Sperren. Jedoch kann eine zu starke Speichernutzung die Aggregation von Sperren aktivieren.
- 2371 — Ändert den Schwellenwert für das feste automatische Aktualisieren der Statistiken hin zu einem dynamischen automatischen Aktualisieren der Statistiken. Dies ist wichtig für das Aktualisieren von Abfrageplänen bei großen Tabellen, wo eine falsche Bestimmung der Anzahl der Einträge zu fehlerhaften Ausführungsplänen führt.
- 3226 — Unterdrückt erfolgreiche Backup-Meldungen im Fehlerprotokoll.
- 4199 — Aktiviert Änderungen im Abfrageoptimierer, die in kumulativen Updates und SQL Server-Updates veröffentlicht wurden.
- 6532-6534 — Verbessert die Leistung von Abfrageoperationen mit räumlichen Datentypen.
- 8048 — Transformiert NUMA-segmentierte Speicherobjekte in CPU-segmentierte.
- 8780 — Aktiviert zusätzliche Zeitzuweisung zur Planerstellung von Abfragen. Einige Abfragen ohne dieses Flag können abgelehnt werden, da sie keinen Abfrageplan haben (sehr seltener Fehler).
- 8780 — 9389 — Inkludiert einen zusätzlichen dynamischen, temporär bereitgestellten Speicherpuffers für Batch-Operatoren, was es dem Batch-Operator ermöglicht, zusätzlichen Speicher anzufordern und einen Transfer von Daten in die tempdb zu vermeiden, sofern zusätzlicher Speicher verfügbar ist.
Es ist auch vor der Version 2016 nützlich, das Trace-Flag 2301 zu aktivieren, welches die Optimierung der erweiterten Entscheidungsunterstützung beinhaltet und dadurch hilft, besser geeignete Ausführungspläne auszuwählen. Ab Version 2016 hat es jedoch häufig negative Auswirkungen auf die Gesamtlaufzeit der Abfragen.
Für Systeme, die viele Indizes haben (z. B. für 1C-Datenbanken), empfehle ich auch, das Trace-Flag 2330 zu aktivieren, welches die Erfassung der Indexnutzung deaktiviert, was sich insgesamt positiv auf das System auswirkt.
Weitere Informationen zu Trace-Flags finden Sie
Es ist wichtig, die Versionen und Builds von MS SQL Server zu berücksichtigen, die unter dem obigen Link angegeben sind, da in neueren Versionen einige Trace-Flags standardmäßig aktiviert sind oder keinen Effekt haben.
Sie können das Tracing-Flag mit den Befehlen DBCC TRACEON und DBCC TRACEOFF aktivieren und deaktivieren. Weitere Informationen finden Sie
Um den Status der Tracing-Flags zu überprüfen, verwenden Sie den Befehl DBCC TRACESTATUS:
Damit die Tracing-Flags beim Autostart des MS SQL Server-Dienstes aktiviert werden, müssen Sie den SQL Server Configuration Manager aufrufen und die Flags über -T in den Diensteigenschaften hinzufügen.
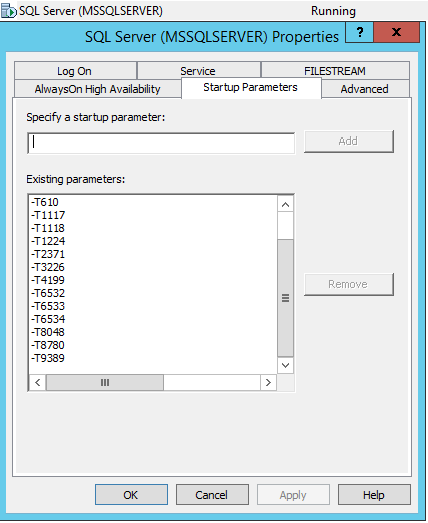
Ergebnisse
In diesem Artikel wurden einige Aspekte der Überwachung des MS SQL Servers behandelt, mit denen Sie schnell einen Mangel an RAM und CPU-Zeit sowie eine Reihe anderer weniger offensichtlicher Probleme erkennen können. Die am häufigsten verwendeten Tracing-Flags wurden besprochen.
Quellen:
»
»
»
»
»
»
»
Quelle: habr.com
