

LINQ ist als neue leistungsstarke Sprache zur Datenmanipulation in .NET eingeführt worden. LINQ to SQL ermöglicht es, bequem mit Datenbanken zu kommunizieren, beispielsweise über das Entity Framework. Häufig vergessen Entwickler jedoch, zu überprüfen, welcher SQL-Befehl vom queryable provider generiert wird – in Ihrem Fall dem Entity Framework.
Lassen Sie uns zwei wesentliche Punkte am Beispiel durchgehen.
Zuerst erstellen wir in SQL Server die Datenbank Test und fügen mit dem folgenden Befehl zwei Tabellen hinzu:
Tabellen erstellen
VERWENDEN [TEST]
GEHEN
SET ANSI_NULLS EIN
GEHEN
SET QUOTED_IDENTIFIER EIN
GEHEN
ERSTELLEN TABELLE [dbo].[Ref](
[ID] [int] NICHT NULL,
[ID2] [int] NICHT NULL,
[Name] [nvarchar](255) NICHT NULL,
[InsertUTCDate] [datetime] NICHT NULL,
EINSCHRÄNKUNG [PK_Ref] PRIMARY KEY CLUSTERED
(
[ID] ASC
)MIT (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) AUF [PRIMARY]
) AUF [PRIMARY]
GEHEN
ÄNDERN TABELLE [dbo].[Ref] HINZUFÜGEN EINSCHRÄNKUNG [DF_Ref_InsertUTCDate] STANDARD (getutcdate()) FÜR [InsertUTCDate]
GEHEN
VERWENDEN [TEST]
GEHEN
SET ANSI_NULLS EIN
GEHEN
SET QUOTED_IDENTIFIER EIN
GEHEN
ERSTELLEN TABELLE [dbo].[Customer](
[ID] [int] NICHT NULL,
[Name] [nvarchar](255) NICHT NULL,
[Ref_ID] [int] NICHT NULL,
[InsertUTCDate] [datetime] NICHT NULL,
[Ref_ID2] [int] NICHT NULL,
EINSCHRÄNKUNG [PK_Customer] PRIMARY KEY CLUSTERED
(
[ID] ASC
)MIT (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) AUF [PRIMARY]
) AUF [PRIMARY]
GEHEN
ÄNDERN TABELLE [dbo].[Customer] HINZUFÜGEN EINSCHRÄNKUNG [DF_Customer_Ref_ID] STANDARD ((0)) FÜR [Ref_ID]
GEHEN
ÄNDERN TABELLE [dbo].[Customer] HINZUFÜGEN EINSCHRÄNKUNG [DF_Customer_InsertUTCDate] STANDARD (getutcdate()) FÜR [InsertUTCDate]
GEHEN
Jetzt füllen wir die Tabelle Ref mit dem folgenden Skript aus:
Ausfüllen der Tabelle Ref
VERWENDEN [TEST]
GEHEN
ERKLÄREN @ind INT=1;
WHILE(@ind<1200000)
BEGIN
EINFÜGEN IN [dbo].[Ref]
([ID]
,[ID2]
,[Name])
SELECT
@ind
,@ind
,CAST(@ind AS NVARCHAR(255));
SET @ind=@ind+1;
END
GEHEN
Analog füllen wir die Tabelle Customer mit dem folgenden Skript aus:
Ausfüllen der Tabelle Customer
VERWENDEN [TEST]
GO
DECLARE @ind INT=1;
DECLARE @ind_ref INT=1;
WHILE(@ind<=12000000)
BEGIN
IF(@ind%3=0) SET @ind_ref=1;
ELSE IF (@ind%5=0) SET @ind_ref=2;
ELSE IF (@ind%7=0) SET @ind_ref=3;
ELSE IF (@ind=0) SET @ind_ref=4;
ELSE IF (@ind=0) SET @ind_ref=5;
ELSE IF (@ind=0) SET @ind_ref=6;
ELSE IF (@ind=0) SET @ind_ref=7;
ELSE IF (@ind=0) SET @ind_ref=8;
ELSE IF (@ind=0) SET @ind_ref=9;
ELSE IF (@ind=0) SET @ind_ref=10;
ELSE IF (@ind=0) SET @ind_ref=11;
ELSE SET @ind_ref=@ind90000;
INSERT INTO [dbo].[Customer]
([ID]
,[Name]
,[Ref_ID]
,[Ref_ID2])
SELECT
@ind,
CAST(@ind AS NVARCHAR(255)),
@ind_ref,
@ind_ref;
SET @ind=@ind+1;
END
GO
So haben wir zwei Tabellen erhalten, von denen eine über 1 Million Datensätze und die andere über 10 Millionen Datensätze enthält.
Jetzt müssen wir in Visual Studio ein Testprojekt vom Typ Visual C# Console App (.NET Framework) erstellen:
Als nächstes fügen wir eine Bibliothek für die Interaktion mit der Datenbank über Entity Framework hinzu.
Um dies zu tun, klicken wir mit der rechten Maustaste auf das Projekt und wählen im Kontextmenü NuGet-Pakete verwalten:
Im daraufhin angezeigten Fenster zur Verwaltung von NuGet-Paketen geben wir im Suchfeld "Entity Framework" ein, wählen das Paket Entity Framework aus und installieren es:

Fügen Sie anschließend im App.config nach dem schließenden Element configSections den folgenden Block hinzu:
In der connectionString muss die Verbindungszeichenfolge eingetragen werden.
Jetzt erstellen wir in separaten Dateien 3 Schnittstellen:
- Implementierung der Schnittstelle IBaseEntityID
namespace TestLINQ { public interface IBaseEntityID { int ID { get; set; } } } - Implementierung der Schnittstelle IBaseEntityName
namespace TestLINQ { public interface IBaseEntityName { string Name { get; set; } } } - Implementierung der Schnittstelle IBaseNameInsertUTCDate
namespace TestLINQ { public interface IBaseNameInsertUTCDate { DateTime InsertUTCDate { get; set; } } }
Und in einer separaten Datei erstellen wir die Basisklasse BaseEntity für unsere beiden Entitäten, die gemeinsame Felder enthalten wird:
Implementierung der Basisklasse BaseEntity
namespace TestLINQ
{
public class BaseEntity : IBaseEntityID, IBaseEntityName, IBaseNameInsertUTCDate
{
public int ID { get; set; }
public string Name { get; set; }
public DateTime InsertUTCDate { get; set; }
}
}
Als Nächstes erstellen wir in separaten Dateien unsere beiden Entitäten:
- Implementierung der Klasse Ref
using System.ComponentModel.DataAnnotations.Schema; namespace TestLINQ { [Table("Ref")] public class Ref : BaseEntity { public int ID2 { get; set; } } } - Implementierung der Klasse Customer
using System.ComponentModel.DataAnnotations.Schema; namespace TestLINQ { [Table("Customer")] public class Customer: BaseEntity { public int Ref_ID { get; set; } public int Ref_ID2 { get; set; } } }
Lassen Sie uns jetzt in einer separaten Datei den Kontext UserContext erstellen:
Implementierung der Klasse UserContext
using System.Data.Entity;
namespace TestLINQ
{
public class UserContext : DbContext
{
public UserContext()
: base("DbConnection")
{
Database.SetInitializer(null);
}
public DbSet Customer { get; set; }
public DbSet Ref { get; set; }
}
}
Wir haben eine betriebsbereite Lösung zur Durchführung von Tests zur Optimierung mit LINQ to SQL über EF für MS SQL Server erhalten:
Jetzt fügen wir im Datei Program.cs den folgenden Code ein:
Datei Program.cs
using System;
using System.Collections.Generic;
using System.Linq;
namespace TestLINQ
{
class Program
{
static void Main(string[] args)
{
using (UserContext db = new UserContext())
{
var dblog = new List();
db.Database.Log = dblog.Add;
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
&& (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
var result = query.Take(1000).ToList();
Console.WriteLine(dblog[1]);
Console.ReadKey();
}
}
}
}
Lassen Sie uns jetzt unser Projekt starten.
Am Ende der Ausführung wird Folgendes in die Konsole ausgegeben:
Generierte SQL-Abfrage
WÄHLEN SIE TOP (1000)
[Extent1].[Ref_ID] ALS [Ref_ID],
[Extent1].[Name] ALS [Name],
[Extent2].[Name] ALS [Name1]
VON [dbo].[Customer] ALS [Extent1]
INNER JOIN [dbo].[Ref] ALS [Extent2] ON ([Extent1].[Ref_ID] = [Extent2].[ID]) UND ([Extent1].[Ref_ID2] = [Extent2].[ID2])
Das heißt, insgesamt hat LINQ einen SQL-Abfrage an die MS SQL Server-Datenbank recht gut generiert.
Jetzt ändern wir die Bedingung von UND zu ODER in der LINQ-Abfrage:
LINQ-Abfrage
var query = von e1 in db.Customer
von e2 in db.Ref
wo (e1.Ref_ID == e2.ID)
|| (e1.Ref_ID2 == e2.ID2)
auswählt neues { Data1 = e1.Name, Data2 = e2.Name };
Und lassen Sie unsere Anwendung erneut laufen.
Die Ausführung wird mit einem Fehler abbrechen, der mit dem Überschreiten der Ausführungszeit von 30 Sekunden zusammenhängt:
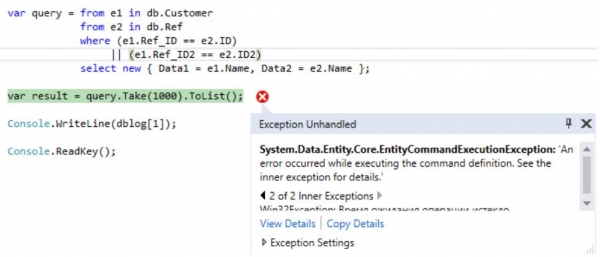
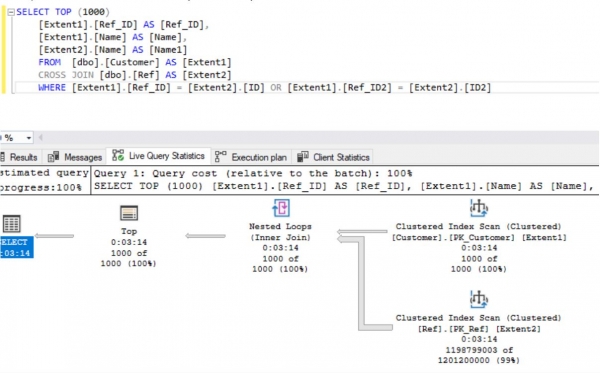
Wenn wir uns anschauen, welche Abfrage dabei generiert wurde:
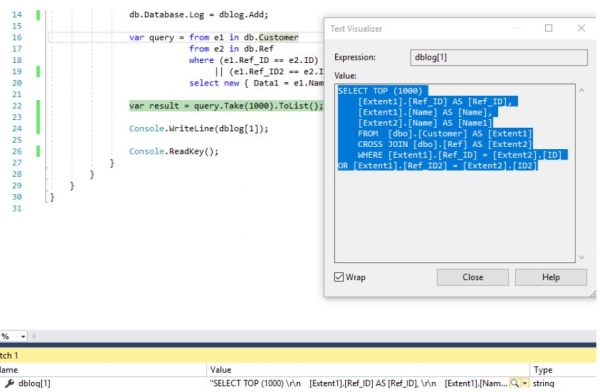
, kann man bestätigen, dass die Auswahl über das kartesische Produkt zweier Mengen (Tabellen) erfolgt:
Generierte SQL-Abfrage
WÄHLEN SIE TOP (1000)
[Extent1].[Ref_ID] ALS [Ref_ID],
[Extent1].[Name] ALS [Name],
[Extent2].[Name] ALS [Name1]
VON [dbo].[Customer] ALS [Extent1]
CROSS JOIN [dbo].[Ref] ALS [Extent2]
WO [Extent1].[Ref_ID] = [Extent2].[ID] ODER [Extent1].[Ref_ID2] = [Extent2].[ID2]
Lassen Sie uns die LINQ-Abfrage wie folgt umschreiben:
Optimierte LINQ-Abfrage
var query = (from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID equals e2.ID
select new { Data1 = e1.Name, Data2 = e2.Name }).Union(
from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID2 equals e2.ID2
select new { Data1 = e1.Name, Data2 = e2.Name });
Dann erhalten wir die folgende SQL-Abfrage:
SQL-Abfrage
SELECT
[Limit1].[C1] AS [C1],
[Limit1].[C2] AS [C2],
[Limit1].[C3] AS [C3]
FROM ( SELECT DISTINCT TOP (1000)
[UnionAll1].[C1] AS [C1],
[UnionAll1].[Name] AS [C2],
[UnionAll1].[Name1] AS [C3]
FROM (SELECT
1 AS [C1],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON [Extent1].[Ref_ID] = [Extent2].[ID]
UNION ALL
SELECT
1 AS [C1],
[Extent3].[Name] AS [Name],
[Extent4].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent3]
INNER JOIN [dbo].[Ref] AS [Extent4] ON [Extent3].[Ref_ID2] = [Extent4].[ID2]) AS [UnionAll1]
) AS [Limit1]
Leider kann in LINQ-Abfragen die Join-Bedingung nur einmal definiert werden, weshalb hier ein äquivalenter Abfrageansatz mittels zwei separaten Abfragen für jede Bedingung möglich ist, gefolgt von einem Union, um Duplikate aus den Zeilen zu entfernen.
Ja, die Anfragen werden in der Regel nicht äquivalent sein, da vollständige Duplikate von Zeilen zurückgegeben werden können. In der Praxis sind vollständige Duplikate jedoch nicht erforderlich, und man versucht, sie zu vermeiden.
Lassen Sie uns nun die Ausführungspläne dieser beiden Anfragen vergleichen:
- Für den CROSS JOIN beträgt die durchschnittliche Ausführungszeit 195 Sekunden:

- Für den INNER JOIN-UNION liegt die durchschnittliche Ausführungszeit bei weniger als 24 Sekunden:

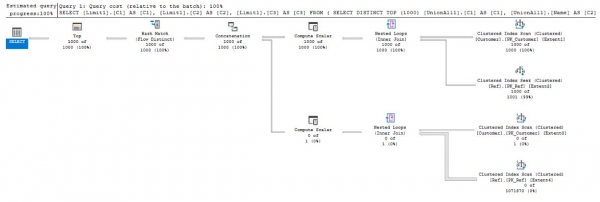
Wie aus den Ergebnissen ersichtlich ist, funktioniert die optimierte LINQ-Anfrage bei zwei Tabellen mit Millionen von Einträgen um ein Vielfaches schneller als die nicht optimierte.
Für den Fall mit AND in den Bedingungen einer LINQ-Anfrage, wie in folgendem Beispiel:
LINQ-Abfrage
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
&& (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
wird fast immer eine korrekte SQL-Anfrage generiert, die im Durchschnitt etwa 1 Sekunde benötigt:
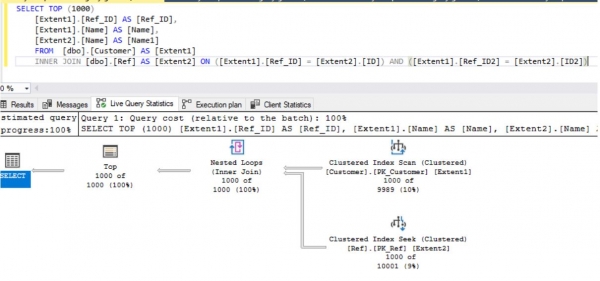
Für LINQ to Objects Manipulationen anstelle der Anfrage wie folgt:
LINQ-Anfrage (1. Variante)
var query = from e1 in seq1
from e2 in seq2
where (e1.Key1 == e2.Key1)
&& (e1.Key2 == e2.Key2)
select new { Data1 = e1.Data, Data2 = e2.Data };
kann eine Anfrage wie folgt verwendet werden:
LINQ-Anfrage (2. Variante)
var query = from e1 in seq1
join e2 in seq2
on new { e1.Key1, e1.Key2 } equals new { e2.Key1, e2.Key2 }
select new { Data1 = e1.Data, Data2 = e2.Data };
wo:
Definition von zwei Arrays
Para[] seq1 = new[] { new Para { Key1 = 1, Key2 = 2, Data = "777" }, new Para { Key1 = 2, Key2 = 3, Data = "888" }, new Para { Key1 = 3, Key2 = 4, Data = "999" } };
Para[] seq2 = new[] { new Para { Key1 = 1, Key2 = 2, Data = "777" }, new Para { Key1 = 2, Key2 = 3, Data = "888" }, new Para { Key1 = 3, Key2 = 5, Data = "999" } };
, und der Typ Para wird wie folgt definiert:
Definition des Typs Para
class Para
{
public int Key1, Key2;
public string Data;
}
Somit haben wir einige Aspekte der Optimierung von LINQ-Abfragen für MS SQL Server betrachtet.
Leider vergessen selbst erfahrene und führende .NET-Entwickler, dass es wichtig ist zu verstehen, was hinter den Kulissen mit den Anweisungen geschieht, die sie verwenden. Andernfalls werden sie zu Konfiguratoren und können wie bei der Skalierung von Softwarelösungen sowie bei kleinen Änderungen der Umgebungsbedingungen eine Zeitbombe im Hintergrund platzieren.
Es wurde auch eine kleine Übersicht durchgeführt und .
Die Quellcodes für den Test — das Projekt selbst, die Erstellung der Tabellen in der Datenbank TEST sowie das Befüllen dieser Tabellen sind vorhanden. .
In diesem Repository finden Sie im Ordner 'Plans' Pläne zur Ausführung von Abfragen mit ODER-Bedingungen.
Quelle: habr.com
