

Dieser Artikel ist eine Übersetzung meines Artikels auf Medium — , der sich als ziemlich beliebt herausgestellt hat, wahrscheinlich wegen seiner Einfachheit. Daher habe ich beschlossen, ihn auf Deutsch zu schreiben und ein wenig zu ergänzen, damit es auch einer Person, die kein Datenexperte ist, klar wird, was ein Data Warehouse (DW) und was ein Data Lake ist, und wie sie zusammen funktionieren.
Warum wollte ich über den Data Lake schreiben? Ich arbeite seit mehr als 10 Jahren mit Daten und Analytik, und im Moment arbeite ich definitiv mit großen Daten bei Amazon Alexa AI in Cambridge, das in Boston liegt, obwohl ich selbst in Victoria auf Vancouver Island wohne und oft sowohl in Boston als auch in Seattle und Vancouver bin, und manchmal sogar in Moskau auf Konferenzen spreche. Auch schreibe ich von Zeit zu Zeit, hauptsächlich auf Englisch, und habe bereits , außerdem habe ich das Bedürfnis, Trends der Analytik aus Nordamerika zu teilen, und ich schreibe manchmal in .
Ich habe immer mit Datenspeichern gearbeitet und seit 2015 intensiv mit Amazon Web Services, also allgemein mit Cloud-Analytik (AWS, Azure, GCP). Ich habe die Entwicklung von Analyse-Lösungen seit 2007 beobachtet und habe sogar bei dem Datenspeicher-Anbieter Teradata gearbeitet, wo ich dessen Lösung bei Sberbank implementiert habe. In dieser Zeit entstand Big Data mit Hadoop. Alle begannen zu sagen, dass die Ära der Datenspeicher vorbei sei und jetzt alles Hadoop sei, und bald sprach man über Data Lakes, erneut mit der Behauptung, dass es für Datenspeicher nun endgültig vorbei sei. Aber zum Glück (vielleicht für einige unglücklich, die viel Geld mit der Einrichtung von Hadoop verdient haben) ist das Datenschließfach nicht verschwunden.
In diesem Artikel werden wir uns mit dem Thema Data Lake beschäftigen. Der Artikel richtet sich an Personen, die wenig oder gar keine Erfahrung mit Datenspeichern haben.

Auf dem Bild ist der Bleder See zu sehen, eines meiner Lieblingsseen, auch wenn ich nur einmal dort war, aber ich habe ihn mein Leben lang in Erinnerung behalten. Aber wir sprechen über einen anderen Typ von See — das Data Lake. Vielleicht haben viele von Ihnen diesen Begriff schon oft gehört, aber eine weitere Definition kann nie schaden.
Zunächst sind hier die bekanntesten Definitionen eines Data Lakes:
„Ein Dateispeicher für alle Arten von Rohdaten, die von jedem in der Organisation analysiert werden können“ — Martin Fowler.
„Wenn Sie denken, dass ein Data Warehouse eine Flasche Wasser ist — gereinigt, verpackt und für den bequemen Gebrauch abgefüllt, dann ist ein Data Lake ein riesiger Reservoir mit Wasser in seiner natürlichen Form. Benutzer können sich Wasser schöpfen, tauchen und erforschen“ — James Dixon.
Jetzt wissen wir ganz genau, dass ein Data Lake sich um Analytik dreht, er ermöglicht es uns, große Datenmengen in ihrer ursprünglichen Form zu speichern, und wir haben den nötigen und bequemen Zugriff auf die Daten.
Ich liebe es oft, Dinge zu vereinfachen. Wenn ich einen komplexen Begriff in einfachen Worten erklären kann, habe ich für mich selbst verstanden, wie es funktioniert und wofür es gebraucht wird. So war ich einmal mit meinem iPhone in der Fotogalerie beschäftigt, und es kam mir in den Sinn, dass das tatsächlich ein Data Lake ist; ich habe sogar eine Folie für Konferenzen erstellt:
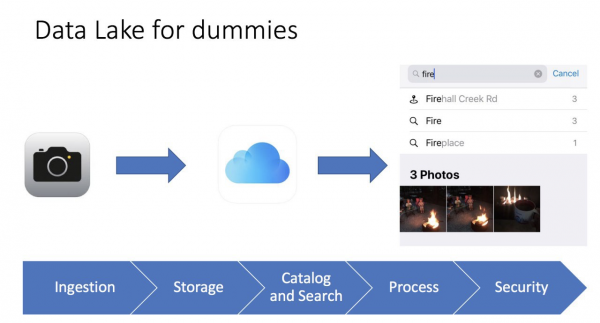
Es ist ganz einfach. Wir machen ein Foto mit dem Handy, das Foto wird auf dem Handy gespeichert und kann in iCloud (Cloud-Speicher) gespeichert werden. Außerdem sammelt das Handy Metadaten des Fotos: was darauf abgebildet ist, Geotags, Zeit. Das Ergebnis ist, dass wir die benutzerfreundliche iPhone-Oberfläche nutzen können, um unser Foto zu finden, und dabei sehen wir sogar Auswertungen. Wenn ich zum Beispiel nach Bildern mit dem Wort Feuer suche, finde ich drei Fotos mit dem Bild eines Lagerfeuers. Für mich ist das wie ein Business-Intelligence-Tool, das sehr schnell und präzise arbeitet.
Und natürlich dürfen wir die Sicherheit (Autorisierung und Authentifizierung) nicht vergessen, sonst können unsere Daten leicht in die falschen Hände geraten. Es gibt viele Nachrichten über große Unternehmen und Startups, deren Daten wegen Nachlässigkeit der Entwickler und der Missachtung einfacher Regeln in den offenen Zugang gelangt sind.
Selbst so ein einfaches Bild hilft uns zu verstehen, was ein Datenlake ist, wie er sich von einem traditionellen Datenspeicher unterscheidet und welche Hauptelemente er hat:
- Daten hochladen (Ingestion) — ein zentraler Bestandteil des Data Lakes. Daten können auf zwei Arten in das Datenspeicher gelangen: durch Batch-Verarbeitung (Übertragung in Intervallen) und Streaming (Datenstrom).
- Dateispeicher (Storage) — die Hauptkomponente des Data Lakes. Es ist wichtig, dass der Speicher skalierbar, äußerst zuverlässig und kosteneffizient ist. Zum Beispiel ist das S3 in AWS.
- Katalog und Suche (Catalog and Search) — um das Data Swamp zu vermeiden (was passiert, wenn wir alle Daten in einem Haufen ablegen und dann nicht mehr damit arbeiten können), müssen wir eine Metadatenebene schaffen, um die Daten zu klassifizieren, damit Benutzer die Daten, die sie für ihre Analysen benötigen, leicht finden können. Zusätzlich können weitere Suchlösungen wie ElasticSearch eingesetzt werden. Die Suche hilft dem Benutzer, die benötigten Daten über eine benutzerfreundliche Schnittstelle zu finden.
- Verarbeitung (Process) — dieser Schritt ist für die Verarbeitung und Transformation der Daten verantwortlich. Wir können Daten transformieren, ihre Strukturen ändern, sie bereinigen und vieles mehr.
- Sicherheit (Sicherheit) — es ist wichtig, Zeit für das Design der Sicherheitslösung aufzuwenden. Zum Beispiel die Verschlüsselung von Daten während der Speicherung, Verarbeitung und Übertragung. Authentifizierungs- und Autorisierungsmethoden sollten verwendet werden. Abschließend wird ein Audit-Tool benötigt.
Aus praktischer Sicht können wir einen Datensee durch drei Attribute charakterisieren:
- Sammeln und speichern Sie alles, was Sie möchten — ein Datensee enthält alle Daten, sowohl rohe, unverarbeitete Daten über einen beliebigen Zeitraum als auch verarbeitete/bereinigte Daten.
- Tiefenanalyse — ein Datensee ermöglicht es Benutzern, Daten zu erkunden und zu analysieren.
- Flexibler Zugang — ein Datensee bietet flexiblen Zugang zu verschiedenen Daten und Szenarien.
Nun können wir über den Unterschied zwischen einem Data Warehouse und einem Datensee sprechen. Normalerweise fragen die Leute:
- Und was ist mit dem Data Warehouse?
- Ersetzen wir das Data Warehouse durch einen Datensee oder erweitern wir es?
- Kann man tatsächlich auf einen Datensee verzichten?
Kurz gesagt, es gibt keine klare Antwort. Es hängt von der konkreten Situation, den Fähigkeiten im Team und dem Budget ab. Zum Beispiel die Migration eines Datenlagers auf Oracle in AWS und die Schaffung eines Data Lakes durch die Tochtergesellschaft von Amazon – Woot – .
Auf der anderen Seite behauptet der Anbieter Snowflake, dass Sie nicht mehr über Data Lakes nachdenken müssen, da ihre Datenplattform (bis 2020 war es ein Data Warehouse) es Ihnen ermöglicht, Data Lakes und Data Warehouses zu kombinieren. Ich habe ein wenig mit Snowflake gearbeitet, und es ist wirklich ein einzigartiges Produkt, das dies leisten kann. Die Frage der Kosten ist ein anderes Thema.
Abschließend denke ich, dass wir weiterhin ein Data Warehouse als primäre Datenquelle für unsere Berichterstattung benötigen. Alles, was nicht hineinpasst, speichern wir im Data Lake. Die gesamte Rolle der Analytik besteht darin, dem Unternehmen einen einfachen Zugang zur Entscheidungsfindung zu ermöglichen. Geschäftsanwender arbeiten effizienter mit einem Data Warehouse als mit einem Data Lake. Zum Beispiel gibt es bei Amazon Redshift (das analytische Data Warehouse) und Redshift Spectrum/Athena (SQL-Schnittstelle für den Data Lake in S3 basierend auf Hive/Presto). Das gilt auch für andere moderne analytische Data Warehouses.
Betrachten wir die typische Architektur eines Data Warehouses:
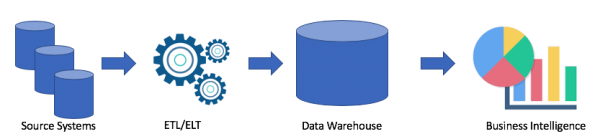
Dies ist eine klassische Lösung. Wir haben Quellsysteme, und mithilfe von ETL/ELT kopieren wir die Daten in das analytische Data Warehouse und verbinden es mit einer Business Intelligence-Lösung (mein Favorit ist Tableau, und Ihrer?).
Eine solche Lösung hat folgende Nachteile:
- ETL/ELT-Operationen benötigen Zeit und Ressourcen.
- In der Regel sind die Speicherkosten für Daten in analytischen Data Warehouses nicht günstig (z. B. Redshift, BigQuery, Teradata), da wir einen ganzen Cluster kaufen müssen.
- Business-Nutzer haben Zugang zu bereinigten und häufig aggregierten Daten und haben keine Möglichkeit, Rohdaten zu erhalten.
Natürlich hängt alles von Ihrem Anwendungsfall ab. Wenn Sie keine Probleme mit Ihrem Datenspeicher haben, benötigen Sie überhaupt kein Data Lake. Aber wenn Probleme mit dem Platz, der Leistung oder den Kosten auftreten, könnte ein Data Lake in Betracht gezogen werden. Genau deshalb ist das Data Lake so beliebt. Hier ist ein Beispiel für die Architektur eines Data Lake:
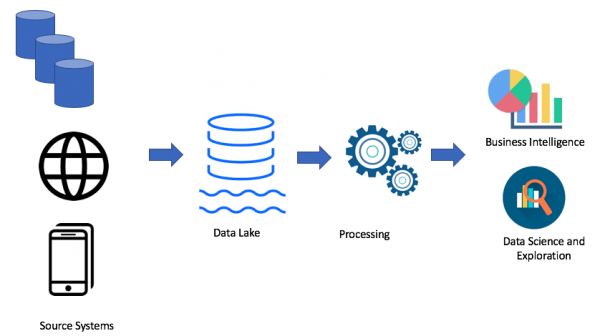
Bei der Verwendung des Data-Lake-Ansatzes laden wir Rohdaten in unseren Data Lake (batch oder streaming) und verarbeiten die Daten bei Bedarf. Ein Data Lake ermöglicht es Business-Nutzern, ihre eigenen Datenumwandlungen (ETL/ELT) zu erstellen oder Daten in Business-Intelligence-Lösungen zu analysieren (sofern der erforderliche Treiber vorhanden ist).
Ziel jeder Analyselösung ist es, den Business-Nutzern zu dienen. Deshalb müssen wir immer von den Anforderungen des Unternehmens ausgehen. (Bei Amazon ist dies eines der Prinzipien — 'working backwards').
Durch die Arbeit sowohl mit dem Datenspeicher als auch mit dem Data Lake können wir beide Lösungen vergleichen:
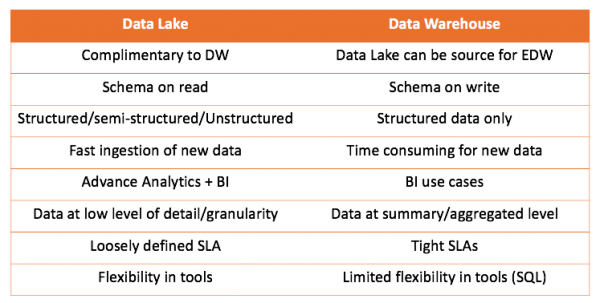
Die wichtigste Erkenntnis ist, dass ein Datenspeicher nicht mit einem Data Lake konkurriert, sondern ihn eher ergänzt. Letztlich liegt es an Ihnen zu entscheiden, was für Ihren Fall geeignet ist. Es ist immer interessant, es selbst auszuprobieren und die richtigen Schlüsse zu ziehen.
Ich möchte auch einen der Fälle vorstellen, in dem ich den Data-Lake-Ansatz verwendet habe. Es war alles recht banal, ich habe versucht, ein ELT-Tool (wir hatten Matillion ETL) und Amazon Redshift zu verwenden. Meine Lösung funktionierte, entsprach aber nicht den Anforderungen.
Ich musste Web-Logs erfassen, transformieren und aggregieren, um Daten für zwei Fälle bereitzustellen:
- Das Marketing-Team wollte die Aktivität von Bots für SEO analysieren.
- Die IT wollte die Metriken zur Leistung der Websites überwachen.
Ganz einfache, sehr einfache Logs. Hier ist ein Beispiel:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188
192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57
"GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2
arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067
"Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012"
1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"Eine Datei wog 1-4 Megabyte.
Es gab jedoch ein Problem. Wir hatten 7 Domains weltweit, und an einem Tag wurden 7000 Dateien erstellt. Das ist nicht besonders viel, insgesamt 50 Gigabyte. Aber auch die Größe unseres Redshift-Clusters war klein (4 Knoten). Das herkömmliche Hochladen einer Datei dauerte etwa eine Minute. Das bedeutete, dass die Herausforderung nicht direkt lösbar war. Daher entschied ich mich für den Ansatz des Data Lakes. Die Lösung sah ungefähr so aus:
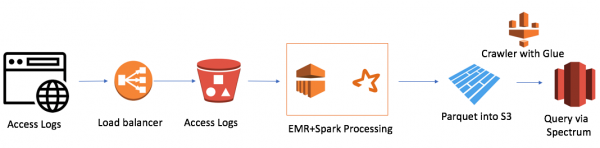
Sie ist ziemlich einfach (ich möchte darauf hinweisen, dass der Vorteil der Arbeit in der Cloud die Einfachheit ist). Ich habe genutzt:
- AWS Elastic Map Reduce (Hadoop) als Rechenleistung
- AWS S3 als Dateispeicher mit Datenverschlüsselung und Zugriffskontrolle
- Spark als In-Memory Rechenleistung und PySpark für Logik und Datenumwandlung
- Parquet als Ergebnis der Spark-Arbeit
- AWS Glue Crawler als Metadatensammler für neue Daten und Partitionen
- Redshift Spectrum als SQL-Schnittstelle zum Data Lake für bestehende Redshift-Nutzer
Der kleinste EMR+Spark-Cluster verarbeitete alle Dateigruppen in 30 Minuten. Es gibt auch andere Anwendungsfälle für AWS, insbesondere zahlreiche mit Alexa, wo es sehr viele Daten gibt.
Vor kurzem habe ich einen der Nachteile eines Data Lakes entdeckt – die DSGVO. Das Problem ist, dass wir, wenn ein Kunde verlangt, dass seine Daten gelöscht werden, die Data Manipulation Language und die DELETE-Operation nicht wie in einer Datenbank verwenden können, da die Daten in einer Datei gespeichert sind.
Ich hoffe, der Artikel hat den Unterschied zwischen einem Data Warehouse und einem Data Lake klargestellt. Wenn es Ihnen gefallen hat, kann ich gerne weitere Artikel von mir oder von professionellen Autoren, die ich lese, übersetzen. Ich kann auch über die Lösungen sprechen, mit denen ich arbeite, und deren Architektur.
Quelle: habr.com
