

Eine klassische Frage, die Entwickler an ihren DBA oder Geschäftsinhaber – an einen PostgreSQL-Berater – stellen, lautet fast immer gleich: „Warum dauern die Abfragen auf der Datenbank so lange?“
Eine traditionelle Reihe von Gründen:
- ineffizienter Algorithmus
wenn Sie beschlossen haben, mehrere CTEs mit mehreren Zehntausend Datensätzen zu verknüpfen - veraltete Statistiken.
wenn die tatsächliche Verteilung der Daten in der Tabelle bereits stark von der zuletzt durchgeführten ANALYSE abweicht - "Engpass" bei den Ressourcen
und es an den zugewiesenen CPU-Ressourcen mangelt, Gigabytes an Speicher ständig voll ausgelastet sind oder die Festplatte den vielen „Wünschen“ der DB nicht gerecht wird - Sperrung wegen konkurrierender Prozesse
Und wenn Sperren schwer zu erfassen und zu analysieren sind, dann genügt uns für alles andere der Abfrageplan, den man mit Hilfe von (am besten direkt EXPLAIN (ANALYZE, BUFFERS) ...) oder .
Aber, wie in der betreffenden Dokumentation erwähnt,
„Das Verständnis des Plans ist eine Kunst, und um diese zu meistern, benötigt man eine gewisse Erfahrung ...“
Aber man kann auch ohne diese auskommen, wenn man ein geeignetes Werkzeug verwendet!
Wie sieht ein Anfrageplan normalerweise aus? So etwa:
Index Scannen über pg_class_relname_nsp_index auf pg_class (tatsächliche Zeit=0.049..0.050 Zeilen=1 Schleifen=1)
Index Bedingung: (relname = $1)
Filter: (oid = $0)
Puffer: gemeinsamer Treffer=4
InitPlan 1 (gibt $0,$1 zurück)
-> Limit (tatsächliche Zeit=0.019..0.020 Zeilen=1 Schleifen=1)
Puffer: gemeinsamer Treffer=1
-> Seq Scannen auf pg_class pg_class_1 (tatsächliche Zeit=0.015..0.015 Zeilen=1 Schleifen=1)
Filter: (relkind = 'r'::"char")
Entfernte Zeilen durch Filter: 5
Puffer: gemeinsamer Treffer=1oder so:
"Append (Kosten=868.60..878.95 Zeilen=2 Breite=233) (tatsächliche Zeit=0.024..0.144 Zeilen=2 Schleifen=1)"
" Puffer: gemeinsamer Treffer=3"
" CTE cl"
" -> Seq Scannen auf pg_class (Kosten=0.00..868.60 Zeilen=9972 Breite=537) (tatsächliche Zeit=0.016..0.042 Zeilen=101 Schleifen=1)"
" Puffer: gemeinsamer Treffer=3"
" -> Limit (Kosten=0.00..0.10 Zeilen=1 Breite=233) (tatsächliche Zeit=0.023..0.024 Zeilen=1 Schleifen=1)"
" Puffer: gemeinsamer Treffer=1"
" -> CTE Scannen auf cl (Kosten=0.00..997.20 Zeilen=9972 Breite=233) (tatsächliche Zeit=0.021..0.021 Zeilen=1 Schleifen=1)"
" Puffer: gemeinsamer Treffer=1"
" -> Limit (Kosten=10.00..10.10 Zeilen=1 Breite=233) (tatsächliche Zeit=0.117..0.118 Zeilen=1 Schleifen=1)"
" Puffer: gemeinsamer Treffer=2"
" -> CTE Scannen auf cl cl_1 (Kosten=0.00..997.20 Zeilen=9972 Breite=233) (tatsächliche Zeit=0.001..0.104 Zeilen=101 Schleifen=1)"
" Puffer: gemeinsamer Treffer=2"
"Planungszeit: 0.634 ms"
"Ausführungszeit: 0.248 ms"Aber den Plan als Text »von der Liste« zu lesen, ist sehr schwierig und unübersichtlich:
- im Knoten wird ausgegeben die Summe der Ressourcen des Teilbaums
Das bedeutet, um zu verstehen, wie viel Zeit für die Ausführung eines bestimmten Knotens aufgewendet wurde oder wie genau dieses Lesen der Daten aus der Tabelle von der Festplatte abgerufen wurde – muss man irgendwie das Eine vom Anderen abziehen. - Die Knotenzeit ist erforderlich. Multiplizieren mit loops.
Ja, Subtraktion ist noch nicht die komplizierteste Operation, die man „im Kopf“ durchführen muss – schließlich wird die Ausführungszeit als Durchschnitt für einen einzelnen Knoten angegeben, und es können Hunderte von ihnen vorhanden sein. - Nun, all das zusammen erschwert die Antwort auf die Hauptfrage – also, wer ist das „schwächste Glied“??
Als wir versuchten, all dies mehreren Hundert unserer Entwickler zu erklären, stellten wir fest, dass das von außen etwa so aussieht:

Ah, das heißt, wir brauchen…
Ein Tool
In diesem haben wir versucht, alle Schlüsselmechaniken zu sammeln, die helfen, anhand des Plans und der Anfrage zu verstehen, „wer schuld ist und was zu tun ist“. Und außerdem wollten wir einen Teil unseres Wissens mit der Gemeinschaft teilen.
Treffen Sie und nutzen Sie –
Anschaulichkeit der Pläne
Ist es leicht, den Plan zu verstehen, wenn er so aussieht?
Seq Scan on pg_class (tatsächliche Zeit=0.009..1.304 Zeilen=6609 Schleifen=1)
Buffer: shared hit=263
Planungszeit: 0,108 ms
Ausführungszeit: 1,800 ms
Nicht wirklich.
Aber so, in verkürzter Form, wenn die Schlüsselindikatoren getrennt sind – ist es bereits viel klarer:
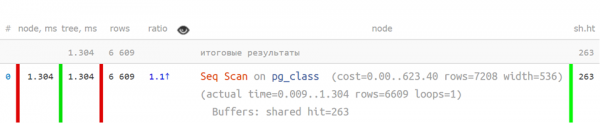
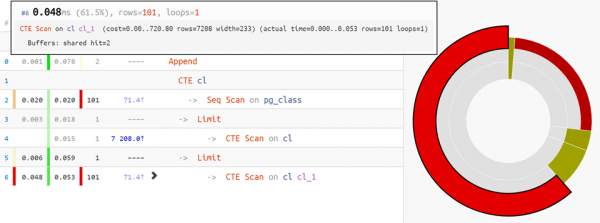
Aber wenn der Plan komplexer ist, kommt Hilfe von Kreisdiagramm der Zeitverteilung nach Knoten:
Für die kompliziertesten Varianten steht uns auch die Ausführungsdiagramm:
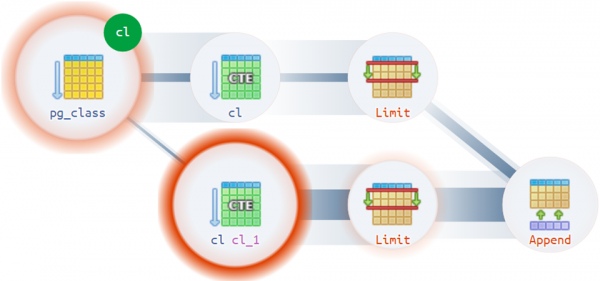
Es gibt tatsächlich Nicht-Trivial-Fälle, in denen ein Plan mehr als eine tatsächliche Wurzel haben kann:
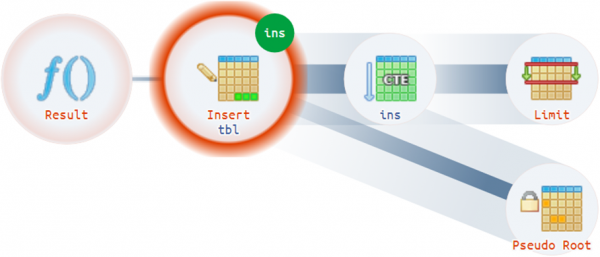
Strukturelle Hinweise
Wenn die gesamte Struktur des Plans und dessen Schwachstellen bereits aufgegliedert und sichtbar sind, warum dann nicht dem Entwickler markieren und «in verständlicher Sprache» erklären?
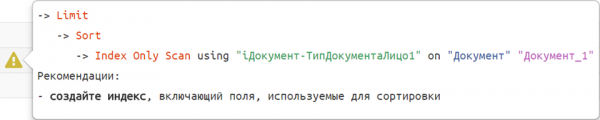 Solcher Empfehlungsvorlagen haben wir bereits einige Dutzend gesammelt.
Solcher Empfehlungsvorlagen haben wir bereits einige Dutzend gesammelt.
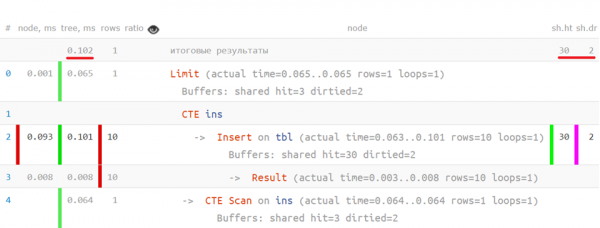
Zeilenprofilierer der Anfrage
Wenn wir nun den analysierten Plan mit der ursprünglichen Anfrage kombinieren, können wir sehen, wie viel Zeit jeder einzelne Operator in Anspruch genommen hat — etwa so:
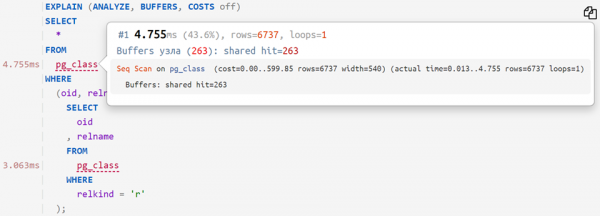
… oder sogar so:

Parameterersetzung in der Anfrage
Wenn Sie nicht nur die Anfrage, sondern auch deren Parameter aus der DETAIL-Zeile des Logs an den Plan angehängt haben, können Sie ihn in einer der Varianten zusätzlich kopieren:
- mit den Werten in der Anfrage ersetzt
zum unmittelbaren Ausführen auf Ihrer Datenbank und zur weiteren ProfilierungSELECT 'const', 'param'::text; - mit den Werten über PREPARE/EXECUTE ersetzt
für die Simulation der Arbeitsweise des Planers, wenn der parametrische Teil ignoriert werden kann – zum Beispiel bei der Arbeit mit partitionierten TabellenDEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Planarchive
Fügen Sie hinzu, analysieren Sie, teilen Sie mit Kollegen! Die Pläne bleiben im Archiv, und Sie können später darauf zurückgreifen:
Wenn Sie jedoch nicht möchten, dass Ihr Plan von anderen gesehen wird, vergessen Sie nicht, das Kästchen "nicht im Archiv veröffentlichen" anzukreuzen.
In den kommenden Artikeln werde ich über die Herausforderungen und Lösungen sprechen, die bei der Analyse von Plänen auftreten.
Quelle: habr.com
