


Wenn man ein Produkt betrachtet, das seit über einem Jahrzehnt entwickelt wird, ist es nicht überraschend, veraltete Technologien darin zu finden. Aber was, wenn Sie in sechs Monaten eine zehnmal höhere Last halten müssen, während die Kosten für Ausfälle in die Hunderte steigen? In diesem Fall benötigen Sie einen erfahrenen Highload Engineer. Doch da es keinen gibt, wurde die Problemlösung mir anvertraut. Im ersten Teil des Artikels erkläre ich, wie wir von Redis auf Redis-Cluster umgestiegen sind, und im zweiten Teil gebe ich Tipps, wie man einen Cluster sinnvoll nutzt und worauf man bei Betrieb und Wartung achten sollte.
Technologieauswahl
Ist ein separates Redis (standalone redis) in einer Konfiguration mit 1 Master und N Slave-Instanzen wirklich so schlecht? Warum bezeichne ich es als veraltete Technologie?
Nein, Redis ist nicht so schlecht... Allerdings gibt es einige Mängel, die man nicht ignorieren sollte.
Erstens unterstützt Redis keine Mechanismen zur Notfallwiederherstellung nach dem Ausfall des Masters. Um dieses Problem zu lösen, haben wir eine Konfiguration mit automatischem VIP-Umschalten auf den neuen Master verwendet, indem wir die Rolle eines der Slaves gewechselt und die anderen umgeschaltet haben. Dieser Mechanismus funktionierte, konnte aber nicht als zuverlässige Lösung bezeichnet werden. Erstens gab es Fehlalarme, und zweitens war es eine einmalige Lösung, nach der man manuelle Schritte zur Rückstellung durchführen musste.
Zweitens führte die Existenz nur eines Masters zu einem Sharding-Problem. Man musste mehrere unabhängige Cluster mit „1 Master und N Slaves“ erstellen, dann die Datenbanken manuell auf diese Maschinen verteilen und hoffen, dass morgen eine der Datenbanken nicht so anwächst, dass sie auf eine separate Instanz ausgelagert werden muss.
Welche Optionen gibt es?
- Die teuerste und umfassendste Lösung ist Redis-Enterprise. Dies ist eine Boxlösung mit vollem technischem Support. Obwohl sie aus technischer Sicht perfekt aussieht, ist sie aus ideologischen Gründen für uns nicht geeignet.
- Redis-Cluster. Aus der Box gibt es Unterstützung für das Failover von Master und Sharding. Die Benutzeroberfläche unterscheidet sich kaum von der normalen Version. Sieht vielversprechend aus, auf die Fallstricke kommen wir später zu sprechen.
- Tarantool, Memcache, Aerospike und andere. All diese Tools erfüllen ungefähr die gleiche Funktion. Aber jedes hat seine eigenen Nachteile. Wir haben beschlossen, nicht alle Eier in einen Korb zu legen. Memcache und Tarantool nutzen wir für andere Aufgaben, und um vorzugreifen, kann ich sagen, dass wir in der Praxis mehr Probleme mit ihnen hatten.
Spezifik der Nutzung
Schauen wir uns an, welche Aufgaben wir historisch mit Redis gelöst haben und welche Funktionalitäten wir genutzt haben:
- Cache vor Anfragen an externe Dienste wie 2GIS | Golang
GET SET MGET MSET "SELECT DB"
- Cache vor MYSQL | PHP
GET SET MGET MSET SCAN "KEY BY PATTERN" "SELECT DB"
- Hauptspeicher für den Dienst zur Verwaltung von Sitzungen und Standorten von Fahrern | Golang
GET SET MGET MSET "SELECT DB" "ADD GEO KEY" "GET GEO KEY" SCAN
Wie Sie sehen, ist keine höhere Mathematik notwendig. Was ist also die Schwierigkeit? Lassen Sie uns jeden Ansatz einzeln betrachten.
Methode
Beschreibung
Besonderheiten von Redis-Cluster
Lösung
GET SET
Schreiben/Lesen eines Schlüssels
MGET MSET
Schreiben/Lesen mehrerer Schlüssel
Die Schlüssel werden auf verschiedenen Knoten liegen. Fertige Bibliotheken können Multi-Operationen nur innerhalb eines Knotens durchführen.
MGET durch eine Pipeline aus N GET-Operationen ersetzen.
Datenbank auswählen.
Wählen Sie die Datenbank aus, mit der wir arbeiten werden.
Unterstützt keine mehreren Datenbanken.
Alles in einer Datenbank speichern. Präfixe zu den Schlüsseln hinzufügen.
SCAN
Alle Schlüssel in der Datenbank durchgehen.
Da wir eine Datenbank haben, ist es zu kostspielig, alle Schlüssel im Cluster zu durchlaufen.
Ein Invarianz innerhalb eines Schlüssels unterstützen und HSCAN über diesen Schlüssel durchführen. Oder ganz darauf verzichten.
GEO.
Operationen mit geografischen Schlüsseln.
Geoschlüssel werden nicht sharded.
KEY BY PATTERN.
Schlüssel nach Muster suchen.
Da wir eine Datenbank haben, werden wir in allen Schlüsseln im Cluster suchen. Zu kostspielig.
Aufgeben oder Invarianz unterstützen, wie im Fall von SCAN.
Redis vs Redis-Cluster.
Was verlieren wir und was gewinnen wir bei der Umstellung auf einen Cluster?
- Nachteile: Verlust der Funktionalität mehrerer Datenbanken.
- Wenn wir logisch nicht zusammenhängende Daten in einem Cluster speichern möchten, müssen wir mit Präfixen arbeiten.
- Wir verlieren alle Operationen „pro Datenbank“, wie SCAN, DBSIZE, CLEAR DB usw.
- Multi-Operationen sind erheblich komplexer in der Umsetzung geworden, da möglicherweise mehrere Knoten angesprochen werden müssen.
- Vorteile:
- Ausfallsicherheit in Form von Master-Failover.
- Sharding auf der Redis-Seite.
- Datenübertragung zwischen Knoten atomar und ohne Ausfallzeiten.
- Hinzufügen und Umverteilung von Kapazitäten und Lasten ohne Ausfallzeiten.
Ich würde schlussfolgern, dass der Umzug zu einem Cluster nicht notwendig ist, wenn Sie kein hohes Maß an Ausfallsicherheit gewährleisten müssen, da dies eine komplexe Aufgabe sein kann. Aber wenn man von Anfang an zwischen einer Einzelversion und einer Cluster-Version wählen muss, sollte man das Cluster wählen, da es nicht schlechter ist und zudem einen Teil des Kopfzerbrechens von Ihnen abnimmt.
Vorbereitung auf den Umzug
Lassen Sie uns mit den Anforderungen für den Umzug beginnen:
- Er muss nahtlos sein. Eine vollständige Dienstunterbrechung von 5 Minuten ist für uns nicht akzeptabel.
- Er sollte so sicher und schrittweise wie möglich sein. Wir möchten eine gewisse Kontrolle über die Situation haben. Wir wollen nicht alles auf einmal umschalten und auf einen Rückroll-Knopf beten.
- Minimale Datenverluste beim Umzug. Wir verstehen, dass ein atomarer Umzug sehr schwierig sein wird, daher erlauben wir eine gewisse Desynchronisation zwischen den Daten in Redis und im Cluster.
Clusterwartung
Vor dem Umzug sollten wir uns fragen, ob wir das Cluster unterstützen können:
- Diagramme. Wir verwenden Prometheus und Grafana für Diagramme zur CPU-Auslastung, genutzten Speicher, Anzahl der Clients, Anzahl der GET-, SET-, AUTH-Operationen usw.
- Expertise. Stellen Sie sich vor, morgen sind Sie verantwortlich für ein riesiges Cluster. Wenn es ausfällt, kann es niemand außer Ihnen reparieren. Wenn es anfängt, zu haken, laufen alle zu Ihnen. Wenn Ressourcen hinzugefügt oder die Last umverteilt werden muss, kommen sie wieder zu Ihnen. Um in den entscheidenden Momenten nicht nervös zu werden, ist es ratsam, solche Szenarien im Voraus zu bedenken und zu testen, wie sich die Technologie bei bestimmten Maßnahmen verhält. Lassen Sie uns in dem Abschnitt 'Expertise' näher darauf eingehen.
- Überwachungen und Benachrichtigungen. Wenn der Cluster ausfällt, möchte man als Erster Bescheid wissen. Hier haben wir uns darauf beschränkt, Benachrichtigungen zu senden, wenn alle Knoten die gleichen Informationen über den Zustand des Clusters zurückgeben (ja, es kann auch anders sein). Andere Probleme lassen sich schneller anhand der Benachrichtigungen der Redis-Clientdienste erkennen.
Umzug
Wie wir umziehen werden:
- Zunächst muss die Bibliothek zur Arbeit mit dem Cluster vorbereitet werden. Als Grundlage für die Version in Go haben wir go-redis genommen und etwas angepasst. Multi-Methoden wurden über Pipelines realisiert, und auch die Regeln zur Wiederholung von Anfragen haben wir leicht überarbeitet. Bei der Version für PHP gab es mehr Probleme, aber schließlich haben wir uns für php-redis entschieden. Kürzlich wurde die Clusterunterstützung integriert, und wir finden, sie sieht gut aus.
- Als nächstes muss der Cluster selbst eingerichtet werden. Dies geschieht wörtlich mit zwei Befehlen auf Basis einer Konfigurationsdatei. Details zur Konfiguration besprechen wir weiter unten.
- Für einen schrittweisen Umstieg verwenden wir den Dry-Mode. Da wir zwei Versionen der Bibliothek mit identischem Interface haben (eine für die Standardversion, die andere für den Cluster), ist es nicht schwer, eine Wrapper-Funktion zu erstellen, die mit der einzelnen Version arbeitet und gleichzeitig alle Anfragen an den Cluster dupliziert, die Antworten vergleicht und Abweichungen in die Logs (in unserem Fall nach NewRelic) schreibt. So wird selbst, wenn die Cluster-Version während des Rollouts ausfällt, unsere Produktion nicht betroffen sein.
- Bei der Bereitstellung des Clusters im Dry-Mode können wir ruhig auf das Diagramm der Antwortabweichungen schauen. Wenn der Fehleranteil langsam, aber sicher zu einer kleinen Konstante tendiert, ist alles in Ordnung. Warum gibt es dennoch Abweichungen? Weil der Eintrag in der einzelnen Version etwas früher erfolgt als im Cluster, und durch die Mikrolaten können die Daten voneinander abweichen. Wir müssen nur noch die Logs der Abweichungen überprüfen, und wenn alle erklärbar sind durch die Nicht-Atomarität des Eintrags, können wir weitermachen.
- Jetzt kann der Dry-Mode umgekehrt werden. Wir werden aus dem Cluster schreiben und lesen und in eine separate Version duplizieren. Warum? In der kommenden Woche möchten wir die Leistung des Clusters beobachten. Falls sich herausstellt, dass es bei hoher Last Probleme gibt oder wir etwas übersehen haben, haben wir immer einen Notfall-Rollback auf den alten Code und aktuelle Daten dank des Dry-Modes.
- Es bleibt nur noch, den Dry-Mode auszuschalten und die separate Version abzubauen.
Expertise
Zunächst eine kurze Einführung in die Struktur des Clusters.
Redis ist in erster Linie ein Key-Value-Speicher. Beliebige Strings werden als Schlüssel verwendet. Als Werte können Zahlen, Strings und ganze Strukturen verwendet werden. Letztere sind zahlreich, aber für das allgemeine Verständnis ist das nicht wichtig.
Die nächste Abstraktionsebene nach den Schlüsseln sind die Slots (SLOTS). Jeder Schlüssel gehört zu einem der 16.383 Slots. Innerhalb jedes Slots können beliebig viele Schlüssel vorhanden sein. So entstehen 16.383 nicht überlappende Mengen von Schlüsseln.
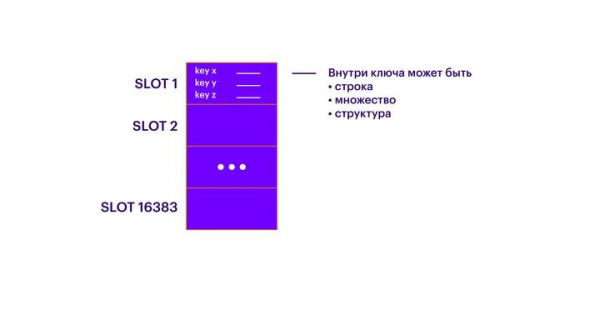
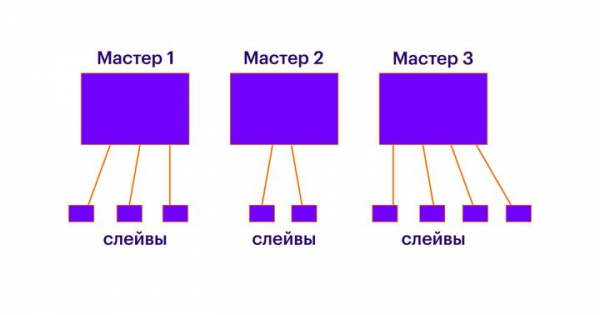
Im Cluster müssen N Master-Knoten vorhanden sein. Jeden Knoten kann man als eine separate Redis-Instanz betrachten, die alles über die anderen Knoten im Cluster weiß. Jeder Master-Knoten enthält eine bestimmte Anzahl von Slots. Jeder Slot gehört nur zu einem Master-Knoten. Alle Slots müssen auf die Knoten verteilt werden. Wenn einige Slots nicht zugeteilt sind, sind die darin gespeicherten Schlüssel nicht verfügbar. Es ist sinnvoll, jeden Master-Knoten auf einer separaten logischen oder physischen Maschine zu betreiben. Zudem ist zu beachten, dass jeder Knoten nur auf einem Kern arbeitet. Wenn Sie mehrere Redis-Instanzen auf einer logischen Maschine ausführen möchten, stellen Sie sicher, dass sie auf unterschiedlichen Kernen laufen (wir haben das nicht getestet, aber theoretisch sollte alles funktionieren). Im Wesentlichen bieten Master-Knoten ein normales Sharding, und eine größere Anzahl von Master-Knoten ermöglicht die Skalierung von Lese- und Schreibanfragen.
Nachdem alle Schlüssel auf die Slots verteilt und die Slots auf die Master-Nodes verteilt sind, kann jeder Master-Node eine beliebige Anzahl von Slave-Nodes hinzugefügt werden. Innerhalb jeder solchen „Master-Slave“-Verbindung wird die normale Replikation arbeiten. Slaves sind für das Skalieren von Leseanfragen und für das Failover im Falle eines Ausfalls des Masters erforderlich.
Jetzt sprechen wir über die Operationen, die wir besser beherrschen sollten.
Wir werden über Redis-CLI auf das System zugreifen. Da Redis keinen einheitlichen Einstiegspunkt hat, können die folgenden Operationen auf jeder der Nodes ausgeführt werden. In jedem Punkt weise ich speziell auf die Möglichkeit hin, die Operation unter Last auszuführen.
- Das Erste und Hauptsächliche, was wir benötigen: die Operation cluster nodes. Sie gibt den Zustand des Clusters zurück, zeigt die Liste der Nodes, ihre Rollen, die Verteilung der Slots usw. Weitere Informationen können über cluster info und cluster slots abgerufen werden.
- Es wäre gut, Nodes hinzufügen und entfernen zu können. Dafür gibt es die Operationen cluster meet und cluster forget. Beachten Sie, dass cluster forget auf JEDER Node, sowohl auf Master- als auch auf Replica-Nodes, angewandt werden muss. Während für cluster meet nur ein Aufruf auf einer Node erforderlich ist. Diese Unterscheidung kann verwirrend sein, deshalb ist es besser, diese Informationen zu kennen, bevor Sie den Cluster in Betrieb nehmen. Das Hinzufügen einer Node erfolgt sicher im Betrieb und hat keinen Einfluss auf die Funktionsweise des Clusters (was logisch ist). Wenn Sie jedoch eine Node aus dem Cluster entfernen möchten, sollten Sie sicherstellen, dass auf ihr keine Slots mehr vorhanden sind (ansonsten riskieren Sie den Verlust des Zugriffs auf alle Schlüssel auf dieser Node). Entfernen Sie außerdem nicht den Master, der Slave-Nodes hat, da sonst eine unnötige Wahl für einen neuen Master stattfinden würde. Wenn auf den Nodes bereits keine Slots mehr vorhanden sind, ist das kein großes Problem, aber warum sollten wir unnötige Entscheidungen treffen, wenn wir zuerst die Slaves entfernen können?
- Wenn Sie Master und Slave zwangsweise umschalten müssen, verwenden Sie den Befehl cluster failover. Bei der Ausführung sollten Sie beachten, dass der Master während der Operation nicht verfügbar ist. Normalerweise erfolgt der Wechsel in weniger als einer Sekunde, aber nicht atomar. Sie können davon ausgehen, dass während dieser Zeit einige Anfragen an den Master mit einem Fehler enden.
- Bevor Sie eine Node aus dem Cluster entfernen, dürfen keine Slots mehr vorhanden sein. Es ist besser, sie mit dem Befehl cluster reshard neu zu verteilen. Die Slots werden von einem Master auf einen anderen verschoben. Der gesamte Vorgang kann einige Minuten in Anspruch nehmen, abhängig vom Umfang der zu übertragenden Daten; der Transferprozess ist jedoch sicher und beeinträchtigt die Funktionalität des Clusters nicht. So können alle Daten unter Last von einer Node auf eine andere übertragen werden, ohne sich um ihre Verfügbarkeit sorgen zu müssen. Es gibt jedoch einige Feinheiten. Erstens ist der Datentransfer mit einer gewissen Belastung für die empfangende und sendende Node verbunden. Wenn die empfangende Node bereits stark ausgelastet ist, sollten Sie sie nicht zusätzlich mit neuen Daten belasten. Zweitens, sobald auf dem sendenden Master kein Slot mehr vorhanden ist, gehen alle seine Slaves sofort zu dem Master, auf den diese Slots übertragen wurden. Das Problem ist, dass all diese Slaves gleichzeitig versuchen werden, die Daten zu synchronisieren. Glücklicherweise wird es sich dabei möglicherweise um eine partielle und nicht um eine vollständige Synchronisation handeln. Berücksichtigen Sie dies und kombinieren Sie die Operationen der Slotübertragung und der Deaktivierung/Verschiebung von Slaves. Oder hoffen Sie, dass Sie über genügend Spielraum verfügen.
- Was tun, wenn Sie beim Transfer feststellen, dass einige Slots verloren gegangen sind? Ich hoffe, dieses Problem wird Ihnen nicht begegnen, aber falls doch, gibt es den Cluster-Fix. Dieser verteilt die Slots mehr oder weniger zufällig auf die Nodes. Ich empfehle, seine Funktion zu überprüfen, nachdem Sie die Node mit den verteilten Slots aus dem Cluster entfernt haben. Da die Daten in den nicht verteilten Slots ohnehin nicht verfügbar sind, ist es zu spät, sich um die Verfügbarkeit dieser Slots Sorgen zu machen. Die Operation wird sich hingegen nicht auf die verteilten Slots auswirken.
- Eine weitere nützliche Operation ist monitor. Sie ermöglicht es, in Echtzeit die gesamte Liste der Anfragen zu sehen, die an die Node gesendet werden. Darüber hinaus können Sie mit ihr einen Grep-Befehl ausführen und herausfinden, ob der benötigte Traffic vorhanden ist.
Es ist auch erwähnenswert, dass es einen Failover-Prozess für den Master gibt. Kurz gesagt, er existiert und meiner Meinung nach funktioniert er hervorragend. Man sollte jedoch nicht denken, dass Redis sofort umschaltet und die Clients den Verlust nicht bemerken, wenn man den Stecker aus der Steckdose zieht. Aus meiner Erfahrung dauert der Umschaltprozess einige Sekunden. Während dieser Zeit sind Teile der Daten nicht verfügbar: der Master wird als nicht erreichbar erkannt, die Noden stimmen über einen neuen ab, die Slaves schalten um, die Daten werden synchronisiert. Der beste Weg, um sicherzustellen, dass das System funktioniert, ist, lokale Übungen durchzuführen. Starten Sie einen Cluster auf Ihrem Laptop, geben Sie eine minimale Last, simulieren Sie einen Ausfall (zum Beispiel durch Blockieren der Ports), bewerten Sie die Umschaltgeschwindigkeit. Meiner Meinung nach kann man nur durch ein- bis zweitägiges Ausprobieren sicher sein, dass die Technologie funktioniert — oder man hofft einfach, dass die Software, die die Hälfte des Internets nutzt, auf jeden Fall zuverlässig ist.
Konfiguration
Oft ist die Konfiguration das Erste, was man braucht, um mit dem Tool zu beginnen. Und wenn alles funktioniert, möchte man die Konfiguration nicht mehr anfassen. Es erfordert bestimmte Anstrengungen, um sich dazu zu bringen, zu den Einstellungen zurückzukehren und sie gründlich zu durchforsten. In meiner Erinnerung hatten wir mindestens zwei schwere Fehler wegen mangelnder Aufmerksamkeit für die Konfiguration. Achten Sie besonders auf die folgenden Punkte:
- timeout 0
Die Zeit, nach der inaktive Verbindungen geschlossen werden (in Sekunden). 0 — keine Schließung.
Nicht jede unserer Bibliotheken konnte Verbindungen korrekt schließen. Wenn diese Einstellung deaktiviert ist, riskieren wir, die maximale Anzahl an Clients zu erreichen. Andererseits, falls es ein solches Problem gibt, könnte der automatische Abbruch verlorener Verbindungen es maskieren, sodass wir es möglicherweise nicht bemerken. Außerdem sollte diese Einstellung bei Verwendung von persistierenden Verbindungen nicht aktiviert werden. - Save x y & appendonly yes
Speicherung des RDB-Snapshots.
Die Probleme mit RDB/AOF werden wir gleich ausführlich besprechen. - stop-writes-on-bgsave-error no & slave-serve-stale-data yes
Wenn aktiviert, wird der Master bei einem RDB-Snapshot-Fehler keine Änderungsanfragen mehr annehmen. Wenn die Verbindung zum Master unterbrochen wird, kann der Slave weiterhin Anfragen beantworten (ja). Oder er wird aufhören zu antworten (nein).
Wir möchten nicht, dass Redis zum Kürbis wird. - repl-ping-slave-period 5
Nach diesem Zeitraum beginnen wir uns Sorgen zu machen, dass der Master ausgefallen ist und es Zeit für einen Failover ist.
Wir müssen manuell das Gleichgewicht zwischen Fehlalarmen und dem Start von Failover finden. Aus unserer Erfahrung sind das 5 Sekunden. - repl-backlog-size 1024mb & epl-backlog-ttl 0
So viele Daten können wir im Puffer für einen ausgefallenen Slave speichern. Wenn der Puffer voll ist, muss eine vollständige Synchronisation erfolgen.
Die Praxis zeigt, dass es besser ist, einen höheren Wert zu wählen. Es gibt viele Gründe, warum ein Slave hinterherhinken kann. Wenn er hinterherhinkt, hat Ihr Master wahrscheinlich schon Mühe, und eine vollständige Synchronisation wird der letzte Tropfen sein. - maxclients 10000
Maximale Anzahl gleichzeitiger Clients.
Nach unseren Erfahrungen ist es besser, einen höheren Wert festzulegen. Redis bewältigt problemlos 10.000 Verbindungen. Stellen Sie nur sicher, dass im System genügend Sockets verfügbar sind. - maxmemory-policy volatile-ttl
Regel, nach der Schlüssel beim Erreichen des verfügbaren Speicherkapazitätslimits gelöscht werden.
Hier ist nicht so wichtig, welche Regel gilt, sondern das Verständnis, wie dies geschehen wird. Redis verdient Lob dafür, dass es auch bei Erreichen des Speicherkapazitätslimits zuverlässig arbeitet.
Probleme mit RDB und AOF
Obwohl Redis alle Informationen im Arbeitsspeicher speichert, gibt es auch einen Mechanismus zur Datenspeicherung auf der Festplatte. Genauer gesagt, drei Mechanismen:
- RDB-Snapshot — eine vollständige Kopie aller Daten. Wird mit der Konfiguration SAVE X Y festgelegt und liest sich als 'Speichern Sie alle Daten alle X Sekunden, wenn mindestens Y Schlüssel geändert wurden.'
- Append-Only-File — eine Liste von Operationen in der Reihenfolge ihrer Ausführung. Fügt neue eingehende Operationen alle X Sekunden oder alle Y Operationen in die Datei ein.
- RDB und AOF — die Kombination der beiden vorhergehenden Methoden.
Alle Methoden haben ihre eigenen Vor- und Nachteile; ich werde nicht alle aufzählen, sondern lediglich auf einige, meiner Meinung nach, weniger offensichtliche Punkte hinweisen.
Zunächst erfordert das Erstellen eines RDB-Snapshots den Aufruf von FORK. Wenn viele Daten vorhanden sind, kann dies Redis für einen Zeitraum von mehreren Millisekunden bis zu einer Sekunde blockieren. Außerdem benötigt das System Arbeitsspeicher für einen solchen Snapshot, was bedeutet, dass die logische Maschine einen doppelt so hohen Arbeitsspeicherbedarf haben muss: Wenn Redis mit 8 GB konfiguriert ist, sollten auf der virtuellen Maschine 16 GB verfügbar sein.
Zweitens gibt es Probleme mit der teilweisen Synchronisierung. Im AOF-Modus kann bei der Wiederverbindung eines Slaves anstelle der partiellen Synchronisierung eine vollständige Synchronisierung durchgeführt werden. Warum das passiert, konnte ich nicht herausfinden. Aber man sollte daran denken.
Diese beiden Punkte lassen bereits darüber nachdenken, ob wir diese Daten auf der Festplatte überhaupt benötigen, wenn sie ohnehin von den Slaves dupliziert werden. Daten können nur dann verloren gehen, wenn alle Slaves ausfallen, und das ist ein Problem der Kategorie "Brand im Rechenzentrum". Als Kompromiss könnte man vorschlagen, die Daten nur auf den Slaves zu speichern, aber in diesem Fall muss sichergestellt werden, dass diese Slaves niemals zum Master werden, wenn eine Notfallwiederherstellung erforderlich ist (hierfür gibt es die Einstellung der Priorität der Slaves in ihrer Konfiguration). Wir denken in jedem konkreten Fall darüber nach, ob es notwendig ist, Daten auf der Festplatte zu speichern, und antworten meistens mit "nein".
Fazit
Abschließend hoffe ich, dass ich einen allgemeinen Überblick über die Funktionsweise von redis-cluster geben konnte für diejenigen, die noch nie davon gehört haben, sowie auf einige nicht sofort offensichtliche Aspekte aufmerksam gemacht habe für diejenigen, die es schon lange nutzen.
Vielen Dank für Ihre Zeit, und wie immer sind Kommentare zum Thema willkommen.
Quelle: habr.com
