


Einleitung
Hallo!
In diesem Artikel teile ich meine Erfahrungen beim Aufbau einer Mikroservice-Architektur für ein Projekt, das neuronale Netze verwendet.
Wir sprechen über die Anforderungen an die Architektur, betrachten verschiedene Strukturdiagramme, analysieren jeden der Komponenten der fertigen Architektur und bewerten die technischen Metriken der Lösung.
Viel Spaß beim Lesen!
Ein paar Worte zur Aufgabe und ihrer Lösung
Die Grundidee besteht darin, die Attraktivität einer Person anhand eines Fotos auf einer Skala von eins bis zehn zu bewerten.
In diesem Artikel werden wir von der Beschreibung sowohl der verwendeten neuronalen Netze als auch des Prozesses der Datenaufbereitung und des Trainings absehen. In einer der nächsten Veröffentlichungen werden wir jedoch auf die detaillierte Analyse des Bewertungs-Pipelines zurückkommen.
Im Moment werden wir die Bewertungs-Pipeline auf einer hohen Ebene durchgehen und uns auf die Interaktion der Mikroservices im Kontext der Gesamtarchitektur des Projekts konzentrieren.
Bei der Arbeit an der Bewertung der Attraktivität wurde die Aufgabe in die folgenden Bestandteile unterteilt:
- Gesichtserkennung auf dem Foto
- Bewertung jedes der Gesichter
- Ergebnis-Rendering
Das erste wird durch ein vortrainiertes Modell gelöst . Für das zweite wurde ein neuronales Netzwerk mit Convolutional Neural Networks auf PyTorch trainiert, wobei ResNet34 als Backbone verwendet wurde. – aus dem Ziel „Qualität / Geschwindigkeit der Inferenz auf CPU“

Funktionsdiagramm des Bewertungs-Pipeline
Analyse der Anforderungen an die Projektarchitektur
Im Lebenszyklus des Projekts sind die Phasen der Arbeit an der Architektur und der Automatisierung der Modellbereitstellung oft eine der zeit- und ressourcenintensivsten.
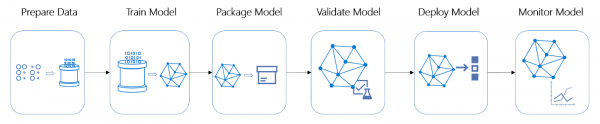
Lebenszyklus eines ML-Projekts
Dieses Projekt ist keine Ausnahme – es wurde entschieden, die Bewertungspipeline in einen Online-Service zu integrieren, was ein tiefes Eintauchen in die Architektur erforderte. Folgende grundlegende Anforderungen wurden festgelegt:
- Zentrales Log-Repository – alle Dienste sollten ihre Logs an einem Ort schreiben, um eine bequeme Analyse zu ermöglichen.
- Möglichkeit zur horizontalen Skalierung des Bewertungsdienstes – als wahrscheinlichster Engpass.
- Jedes Bild sollte mit der gleichen Menge an Rechenressourcen bewertet werden – um Ausreißer in der Verteilung der Inferenzzeit zu vermeiden.
- Schnelles (Neu-)Bereitstellen sowohl einzelner Dienste als auch des gesamten Stacks.
- Die Möglichkeit, bei Bedarf in verschiedenen Diensten gemeinsame Objekte zu verwenden.
Architektur von
Nach der Analyse der Anforderungen wurde deutlich, dass die mikroservicebasierte Architektur fast perfekt passt.
Um überflüssige Kopfschmerzen zu vermeiden, wurde das Telegram API als Frontend gewählt.
Zuerst betrachten wir das strukturelle Diagramm der fertigen Architektur, anschließend gehen wir auf die Beschreibung jeder Komponente ein und formalisierten den Prozess der erfolgreichen Bildverarbeitung.
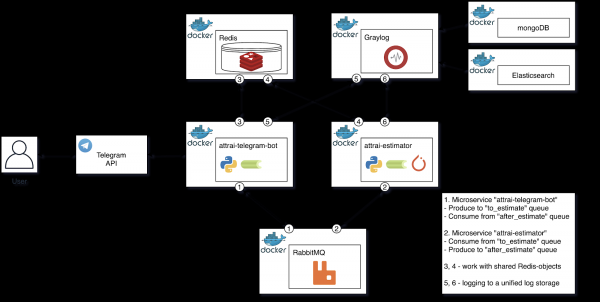
Das strukturelle Diagramm der fertigen Architektur.
Lassen Sie uns näher auf jede Komponente des Diagramms eingehen und ihre Single Responsibility im Prozess der Bildbewertung kennzeichnen.
Mikroservice «attrai-telegram-bot»
Dieser Mikroservice kapselt alle Interaktionen mit dem Telegram API ein. Es lassen sich zwei Hauptszenarien unterscheiden – die Bearbeitung des Benutzerbildes und die Arbeit mit dem Ergebnis des Bewertungs-Pipelines. Beide Szenarien werden wir allgemein untersuchen.
Beim Empfang einer Benutzernachricht mit einem Bild:
- Es erfolgt eine Filterung, die aus den folgenden Prüfungen besteht:
- Vorhandensein der optimalen Bildgröße.
- Anzahl der Bilder des Benutzers, die sich bereits in der Warteschlange befinden.
- Bei der ersten Filterung wird das Bild in einem Docker-Volume gespeichert.
- In die Warteschlange „to_estimate“ wird eine Aufgabe eingereiht, die unter anderem den Pfad zum Bild enthält, das in unserem Volume liegt.
- Wenn die oben genannten Schritte erfolgreich abgeschlossen sind, erhält der Benutzer eine Nachricht mit der geschätzten Bearbeitungszeit des Bildes, die auf der Anzahl der Aufgaben in der Warteschlange basiert. Im Falle eines Fehlers wird der Benutzer ausdrücklich darüber informiert – durch eine Nachricht mit Informationen dazu, was schiefgelaufen sein könnte.
Dieser Mikrodienst fungiert als Celery-Worker und hört auf die Warteschlange „after_estimate“, die für Aufgaben vorgesehen ist, die den Bewertungspipeline durchlaufen haben.
Beim Erhalt einer neuen Aufgabe aus „after_estimate“:
- Wenn das Bild erfolgreich verarbeitet wurde, senden wir das Ergebnis an den Benutzer, andernfalls informieren wir über einen Fehler.
- Wir löschen das Bild, das das Ergebnis der Bewertungspipeline ist.
Mikrodienst zur Bewertung „attrai-estimator“
Dieser Mikrodienst ist ein Celery-Worker und umfasst alles, was mit der Bewertung des Bildes zu tun hat. Der Algorithmus ist einfach – lassen Sie uns diesen durchgehen.
Beim Erhalt einer neuen Aufgabe aus „to_estimate“:
- Wir führen das Bild durch die Evaluierungs-Pipeline:
- Laden das Bild in den Speicher
- Passen das Bild auf die benötigte Größe an
- Erkennen alle Gesichter (MTCNN)
- Bewerten alle Gesichter (packen die im vorherigen Schritt gefundenen Gesichter in ein Batch und führen Inferenzen mit ResNet34 durch)
- Rendern das endgültige Bild
- Zeichnen die Begrenzungsrahmen
- Zeichnen die Bewertungen
- Löschen das Benutzerbild (ursprüngliches Bild)
- Speichern den Output der Evaluierungs-Pipeline
- Legen die Aufgabe in die Warteschlange "after_estimate", die vom oben genannten Microservice "attrai-telegram-bot" überwacht wird
Graylog (+ mongoDB + Elasticsearch)
ist eine Lösung für das zentrale Log-Management. In diesem Projekt wurde es für seinen vorgesehenen Zweck verwendet.
Die Wahl fiel genau auf dieses System und nicht auf das allgemein bekannte Stack, aufgrund der Bequemlichkeit der Arbeit mit ihm aus Python heraus. Alles, was man für das Logging in Graylog tun muss, ist, GELFTCPHandler aus dem Paket zu den anderen Root-Logger-Handlern unseres Python-Microservices hinzuzufügen.
Als jemand, der zuvor nur mit dem ELK-Stack gearbeitet hat, habe ich insgesamt positive Erfahrungen mit Graylog gemacht. Einziges Manko ist die Überlegenheit der Features von Kibana gegenüber der Web-Oberfläche von Graylog.
RabbitMQ
— ist ein Nachrichtenbroker, der auf dem AMQP-Protokoll basiert.
In diesem Projekt wurde er verwendet als Broker für Celery und arbeitete im durable Modus.
Redis
— ist eine NoSQL-Datenbank, die mit Datenstrukturen vom Typ „Schlüssel-Wert“ arbeitet.
Manchmal ist es notwendig, in verschiedenen Python-Mikrodiensten gemeinsame Objekte zu verwenden, die bestimmte Datenstrukturen implementieren.
Zum Beispiel speichert Redis eine Hashmap in der Form „telegram_user_id => Anzahl aktiver Aufgaben in der Warteschlange“, was es ermöglicht, die Anzahl der Anfragen eines Benutzers auf einen bestimmten Wert zu begrenzen und so DoS-Angriffe zu verhindern.
Formalisiert den Prozess der erfolgreichen Bildverarbeitung.
- Der Benutzer sendet ein Bild an den Telegram-Bot
- „attrai-telegram-bot“ empfängt die Nachricht von der Telegram API und analysiert sie.
- Die Aufgabe mit dem Bild wird in die asynchrone Warteschlange „to_estimate“ eingefügt.
- Der Benutzer erhält eine Nachricht mit der geschätzten Bewertungszeit.
- „attrai-estimator“ holt die Aufgabe aus der Warteschlange „to_estimate“, verarbeitet sie durch die Bewertungspipeline und produziert die Aufgabe in die Warteschlange „after_estimate“.
- „attrai-telegram-bot“, der die Warteschlange „after_estimate“ überwacht, sendet das Ergebnis an den Benutzer.
DevOps
Nach der Überprüfung der Architektur können wir nun zu einem nicht weniger interessanten Teil übergehen – DevOps.
Docker Swarm

— ein Clusterierungssystem, dessen Funktionalität innerhalb der Docker Engine umgesetzt ist und standardmäßig verfügbar ist.
Mit Hilfe eines „Clusters“ können alle Knoten unseres Clusters in zwei Typen unterteilt werden – Worker und Manager. Auf den Maschinen des ersten Typs werden Gruppen von Containern (Stacks) bereitgestellt, während die Maschinen des zweiten Typs für das Skalieren, die Lastverteilung und Manager sind standardmäßig auch Worker.
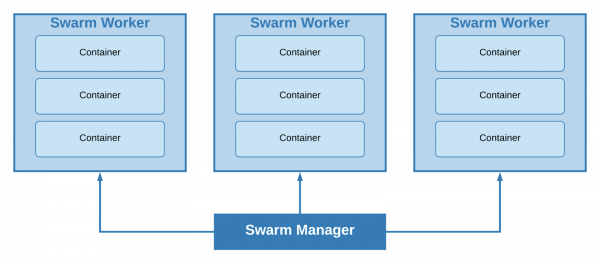
Cluster mit einem Leader-Manager und drei Workern.
Die minimal mögliche Clustergröße beträgt 1 Knoten; die einzige Maschine fungiert gleichzeitig als Leader-Manager und Worker. Je nach Projektgröße und minimale Anforderungen an die Fehlertoleranz wurde beschlossen, diesen Ansatz zu verwenden.
Um vorzugreifen, kann ich sagen, dass seit der ersten Produktionsbereitstellung, die Mitte Juni stattfand, keine Probleme in Verbindung mit dieser Clusterorganisation aufgetreten sind (das bedeutet jedoch nicht, dass eine solche Organisation in irgendeiner Weise in mittelgroßen Projekten ohne Anforderungen an die Fehlertoleranz akzeptabel ist).
Docker Stack
Im Modus „Swarm“ ist docker stack für die Bereitstellung von Stacks (Docker-Dienste) verantwortlich.
Es unterstützt docker-compose Konfigurationen und erlaubt die Verwendung zusätzlicher Bereitstellungsparameter.
Zum Beispiel wurden mit diesen Parametern die Ressourcen für jede Instanz des Evaluierungs-Mikrodienstes begrenzt (wir weisen N Kerne für N Instanzen zu, und im Mikrodienst beschränken wir die Anzahl der von PyTorch verwendeten Kerne auf einen).
attrai_estimator:
image: 'erqups/attrai_estimator:1.2'
deploy:
replicas: 4
resources:
limits:
cpus: '4'
restart_policy:
condition: on-failure
…Es ist wichtig zu beachten, dass Redis, RabbitMQ und Graylog Stateful-Services sind und sie nicht so einfach skalierbar sind wie „attrai-estimator“.
Antizipierend die Frage — warum nicht Kubernetes?
Es scheint, dass die Nutzung von Kubernetes in kleinen und mittleren Projekten ein Overhead ist; die gesamte benötigte Funktionalität kann von Docker Swarm bereitgestellt werden, das recht benutzerfreundlich für einen Containerorchestrator ist und einen niedrigen Einstieg bietet.
Infrastruktur
Das Ganze wurde auf einem VDS mit folgenden Eigenschaften bereitgestellt:
- CPU: 4 Kerne Intel® Xeon® Gold 5120 CPU @ 2.20GHz
- RAM: 8 GB
- SSD: 160 GB
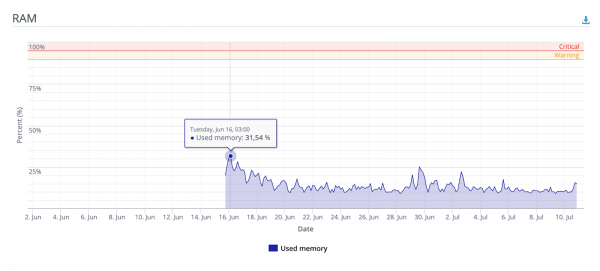
Nach den lokalen Lasttests schien es, dass dieses System bei einem starken Anstieg der Benutzer gerade ausreicht.
Aber direkt nach dem Deployment teilte ich einen Link zu einem der beliebtesten Imageboards im GUS-Raum (ja, genau das), woraufhin die Leute interessiert waren und der Service innerhalb weniger Stunden erfolgreich zehntausende Bilder verarbeitete. Dabei wurden in den Spitzenzeiten die Ressourcen von CPU und RAM nicht einmal zur Hälfte genutzt.
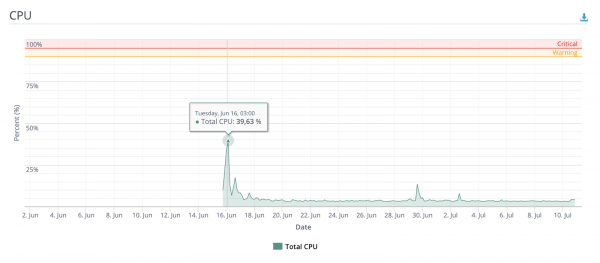
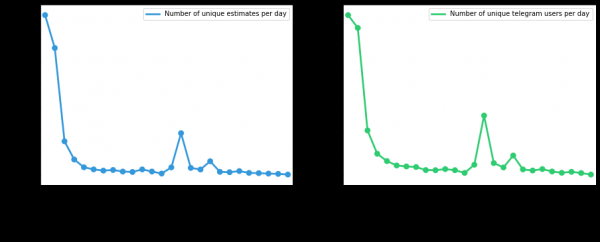
Noch ein paar Grafiken
Anzahl der einzigartigen Benutzer und Bewertungsanfragen seit dem Deployment, je nach Tag
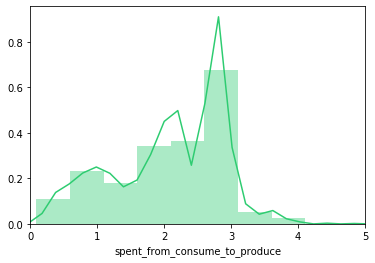
Verteilung der Inferenzzeit der Bewertungs-Pipeline
Fazit
Zusammenfassend kann ich sagen, dass die Architektur und der Ansatz zur Orchestrierung der Container sich voll und ganz bewährt haben — selbst in Spitzenzeiten gab es keine Ausfälle oder Verzögerungen bei der Verarbeitung.
Ich denke, kleine und mittelgroße Projekte, die in ihrem Prozess Echtzeit-Inferenz von neuronalen Netzen auf CPU verwenden, können die in diesem Artikel beschriebenen Praktiken erfolgreich übernehmen.
Ich möchte hinzufügen, dass der Artikel ursprünglich länger war, aber um keinen Longread zu posten, habe ich beschlossen, einige Punkte in diesem Artikel auszulassen – wir werden in zukünftigen Veröffentlichungen darauf zurückkommen.
Den Bot kann man auf Telegram anstoßen – @AttraiBot, er wird mindestens bis zum Ende des Herbstes 2020 funktionieren. Ich erinnere daran – es werden keine Benutzerdaten gespeichert – weder die ursprünglichen Bilder noch die Ergebnisse des Bewertungs-Pipelines – alles wird nach der Verarbeitung gelöscht.
Quelle: habr.com
