

Die Entwicklung eines Data Warehouses ist eine langwierige und ernsthafte Angelegenheit.
Vieles im Leben eines Projekts hängt davon ab, wie gut das objektorientierte Modell und die Datenbankstruktur von Anfang an durchdacht sind.
Eine gängige Methode sind verschiedene Kombinationen aus Sternschema und dritter Normalform. In der Regel gilt: Quelldaten – 3NF, Data Marts – Sternschema. Dieser, durch die Jahre bewährte Ansatz, gestützt durch zahlreiche Studien, ist das Erste (und manchmal auch das Einzige), was einem erfahrenen DWH-Spezialisten in den Sinn kommt, wenn er darüber nachdenkt, wie ein analytisches Data Warehouse aussehen sollte.
Andererseits ist es für Unternehmen im Allgemeinen und für die Anforderungen des Kunden im Besonderen typisch, sich schnell zu verändern, während Daten sowohl „vertikal“ als auch „horizontal“ wachsen. Hier zeigt sich der Hauptnachteil des Sternschemas – die Begrenztheit. Flexibilität.
Und wenn in Ihrem ruhigen und gemütlichen Leben eines DWH-Entwicklers plötzlich:
- die Aufgabe auftaucht, „schnell irgendetwas zu machen und dann sehen wir weiter“;
- ein schnell wachsendes Projekt mit der Anbindung neuer Datenquellen und einer Umgestaltung des Geschäftsmodells mindestens einmal pro Woche entsteht;
- Ein Kunde ist aufgetaucht, der sich nicht vorstellen kann, wie das System aussehen und welche Funktionen es letztendlich erfüllen soll, aber bereit ist, zu experimentieren und das gewünschte Ergebnis schrittweise zu verfeinern, während er sich schrittweise diesem Ziel nähert.
- Der Projektmanager kam mit einer frohen Botschaft: „Und jetzt haben wir Agile!“
Oder wenn Sie einfach nur neugierig sind, wie man Speicher bauen kann – willkommen unter dem Cut!
Was bedeutet "Flexibilität"?
Lassen Sie uns zunächst festlegen, welche Eigenschaften das System haben sollte, damit es als "flexibel" bezeichnet werden kann.
Es ist wichtig zu betonen, dass die beschriebenen Eigenschaften sich speziell auf das Systemund nicht auf den Prozess seiner Entwicklung beziehen. Wenn Sie also über Agile als Entwicklungsmethodologie lesen möchten, sollten Sie sich besser mit anderen Artikeln vertrautmachen. Zum Beispiel gibt es hier auf Habr eine Fülle interessanter Materialien (wie und , als auch ).
Das bedeutet nicht, dass der Entwicklungsprozess und die Struktur eines Data Warehouses überhaupt nicht miteinander verbunden sind. Im Allgemeinen sollte die Entwicklung eines flexiblen Architekturspeichers nach Agile wesentlich einfacher sein. In der Praxis finden sich jedoch häufig auch Varianten, bei denen klassisches DWH-Design nach Kimball und Data Vault — nach dem Wasserfallprinzip — öfter vorkommen als glückliche Fälle der Flexibilität in beiden Formen in einem Projekt.
Also, welche Eigenschaften sollte ein flexibles Data Warehouse besitzen? Hier lassen sich drei Punkte hervorheben:
- Frühe Lieferung und schnelle Anpassungen — das bedeutet, dass im Idealfall das erste Geschäftsergebnis (zum Beispiel die ersten funktionierenden Berichte) so früh wie möglich erzielt werden sollte, also noch bevor das gesamte System vollständig entworfen und implementiert ist. Dabei sollte auch jede nachfolgende Anpassung möglichst wenig Zeit in Anspruch nehmen.
- Iterative Anpassungen — das bedeutet, dass jede folgende Anpassung idealerweise nicht die bereits funktionierenden Funktionalitäten beeinträchtigen sollte. Genau dieser Aspekt wird oft zum größten Albtraum bei großen Projekten – früher oder später wachsen einzelne Objekte mit so vielen Verbindungen, dass es einfacher wird, die Logik in einer Kopie daneben vollständig zu replizieren, als ein Feld in die bestehende Tabelle hinzuzufügen. Und wenn es Sie überrascht, dass die Analyse der Auswirkungen einer Anpassung auf bestehende Objekte mehr Zeit in Anspruch nehmen kann als die Anpassung selbst – dann haben Sie wahrscheinlich noch nicht mit großen HD im Bankwesen oder Telekommunikation gearbeitet.
- Ständige Anpassung an sich ändernde Geschäftsanforderungen — die gesamte Objekthierarchie sollte nicht nur unter Berücksichtigung möglicher Erweiterungen entworfen werden, sondern mit dem Kalkül, dass die Richtung dieser nächsten Erweiterung Ihnen zu Entwurfszeitpunkten niemals hätte in den Sinn kommen können.
Und ja, die Einhaltung all dieser Anforderungen in einem System ist möglich (natürlich unter bestimmten Umständen und mit einigen Vorbehalten).
Im Folgenden bespreche ich die zwei beliebtesten agilen Designmethoden für HD – Anchor-Modell und Data Vault. Dabei gibt es so wunderbare Ansätze wie EAV, 6NF (in reinster Form) und alles, was mit NoSQL-Lösungen zu tun hat – nicht weil diese schlechter sind, und auch nicht, weil der Artikel sonst den Umfang einer typischen Dissertation annehmen würde. Einfach weil alles dies zu Lösungen einer etwas anderen Klasse gehört – entweder zu Ansätzen, die Sie in spezifischen Fällen anwenden können, unabhängig von der Gesamtarchitektur Ihres Projekts (wie EAV), oder zu global anderen Paradigmen der Informationsspeicherung (wie zum Beispiel Graph-Datenbanken und andere NoSQL-Varianten).
Probleme des „klassischen“ Ansatzes und deren Lösungen in flexiblen Methoden
Mit dem „klassischen“ Ansatz meine ich den guten alten Stern (unabhängig von der konkreten Umsetzung der zugrunde liegenden Schichten, mögen mir die Anhänger von Kimball, Inmon und CDM vergeben).
1. Strikte Kardinalität der Verbindungen
Diese Modellierung basiert auf einer klaren Trennung der Daten in Dimensionen (Dimension) und Fakten (Fact). Und das macht verdammt viel Sinn — denn die Datenanalyse reduziert sich in überwiegendem Maße auf die Analyse bestimmter numerischer Kennzahlen (Fakten) in bestimmten Anschnitten (Dimensionen).
Dabei werden die Beziehungen zwischen Objekten in Form von Verbindungen zwischen Tabellen über einen Fremdschlüssel gelegt. Das erscheint völlig natürlich, führt aber sofort zu der ersten Einschränkung der Flexibilität — der strengen Definition der Kardinalität von Beziehungen..
Das bedeutet, dass Sie in der Entwurfsphase der Tabellen genau festlegen müssen, ob jede Paarung verbundener Objekte viele-zu-viele oder nur eins-zu-viele sein kann und „in welche Richtung“. Davon hängt direkt ab, in welcher der Tabellen der Primärschlüssel und in welcher der Fremdschlüssel platziert wird. Eine Änderung dieser Beziehung bei neuen Anforderungen wird mit großer Wahrscheinlichkeit zu einer Überarbeitung der Datenbank führen.
Wenn Sie zum Beispiel das Objekt „Kassenbon“ entwerfen, haben Sie, gestützt auf die eidesstattlichen Erklärungen der Verkaufsabteilung, die Möglichkeit vorgesehen, eine Promotion auf mehrere Positionen im Bon anzuwenden (aber nicht umgekehrt):
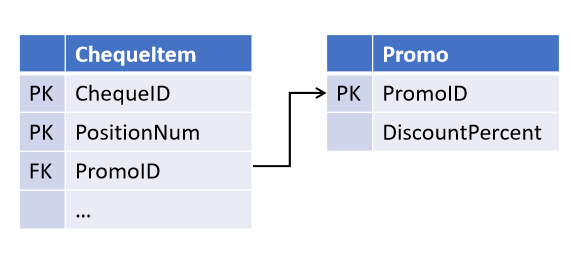
Nach einiger Zeit führten die Kollegen eine neue Marketingstrategie ein, bei der mehrere Aktionen gleichzeitig für eine gleiche Position wirken können. Und jetzt müssen Sie die Tabellen überarbeiten und die Beziehungen in einem separaten Objekt hervorheben.(Alle abgeleiteten Objekte, in denen das Join-Check auf die Promotion stattfindet, müssen jetzt ebenfalls überarbeitet werden.)
Beziehungen im Data Vault und im Anchor Model
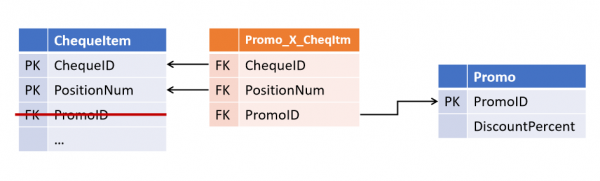
Es stellte sich als recht einfach heraus, eine solche Situation zu vermeiden: Man muss der Verkaufsabteilung nicht vertrauen; es reicht aus,
alle Beziehungen ursprünglich in separaten Tabellen zu speichern und als viele-zu-viele zu verarbeiten. Dieser Ansatz wurde
von Dan Linstedt als Teil der Paradigmen und wurde vollständig unterstützt Data Vault von Lars Rönnbäck. Anchor Model in Somit erhalten wir das erste Unterscheidungsmerkmal flexibler Methoden:.
Die Beziehungen zwischen Objekten werden nicht in den Attributen der übergeordneten Entitäten gespeichert, sondern stellen einen eigenen Objekttyp dar.
Solche Verbindungstabellen werden genannt
In Data Vault Anchor Model Link, sondern in Verbindung — Verbinde. Auf den ersten Blick scheinen sie sehr ähnlich, obwohl ihre Unterschiede nicht auf die Namen beschränkt sind (darüber wird im Folgenden gesprochen). In beiden Architekturen können Verknüpfungstabellen beliebig viele Entitäten verbinden jede Anzahl von Entitäten (nicht unbedingt 2).
Diese auf den ersten Blick redundante Struktur bietet wesentliche Flexibilität bei Ergänzungen. Solch eine Struktur wird nicht nur tolerant gegenüber Änderungen der Kardinalitäten bestehender Beziehungen, sondern auch gegenüber dem Hinzufügen neuer — wenn nun eine Verknüpfung zur kassatführenden Person für den Beleg hinzugefügt wird, wird das Auftreten dieser Verknüpfung einfach eine Erweiterung der bestehenden Tabellen sein, ohne Einfluss auf vorhandene Objekte und Prozesse.
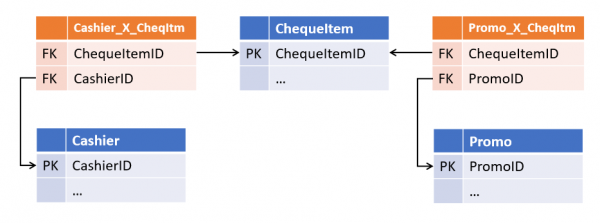
2. Datenredundanz
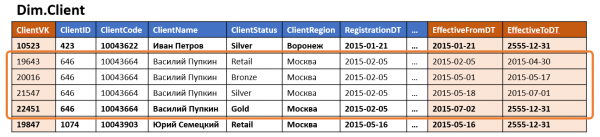
Das zweite Problem, das durch flexible Architekturen gelöst wird, ist weniger offensichtlich und charakteristisch vor allem für SCD2-Typ-Messungen (langsam sich ändernde Dimensionen zweiten Typs), obwohl nicht nur für diese.
In einem klassischen Data Warehouse stellt eine Dimension normalerweise eine Tabelle dar, die einen Surrogatschlüssel (als PK) sowie eine Reihe von Geschäftsschlüsseln und Attributen in einzelnen Spalten enthält.

Wenn das Maß eine Versionierung unterstützt, werden dem Standardsatz von Feldern die Zeitgrenzen der Versionsgültigkeit hinzugefügt, und es erscheinen mehrere Versionen in der Quelle (eine für jede Änderung der versionierten Attribute).
Enthält das Maß mindestens ein häufig verändertes versioniertes Attribut, wird die Anzahl der Versionen dieses Maßes erheblich sein (auch wenn die anderen Attribute nicht versioniert sind oder sich nie ändern), und wenn mehrere solcher Attribute vorhanden sind, kann die Anzahl der Versionen exponentiell mit ihrer Anzahl wachsen. Solch ein Maß kann erheblichen Speicherplatz beanspruchen, obwohl der Großteil der darin gespeicherten Daten einfach Duplikate von Werten unveränderlicher Attribute aus anderen Zeilen sind.
Dabei wird häufig auch Denormalisierung verwendet — Teile von Attributen werden absichtlich als Werte und nicht als Verweise auf ein Verzeichnis oder ein anderes Maß gespeichert. Dieser Ansatz beschleunigt den Datenzugriff und reduziert die Anzahl der Joins beim Zugriff auf das Maß.
In der Regel führt dies dazu, dass Die gleichen Informationen werden gleichzeitig an mehreren Orten gespeichert.Zum Beispiel können Informationen über den Wohnort und die Zugehörigkeit zur Kundenkategorie gleichzeitig in den Dimensionen 'Kunde' und den Fakten 'Kauf', 'Lieferung' sowie 'Anfragen beim Callcenter' gespeichert werden, ebenso wie in der Verknüpfungstabelle 'Kunde — Kundenmanager'.
Insgesamt gilt das oben Beschriebene auch für gewöhnliche (nicht versionierte) Dimensionen, aber in versionierten Dimensionen können andere Maßstäbe gelten: Das Erscheinen einer neuen Version eines Objekts (insbesondere rückblickend) führt nicht nur zu einem Update aller verbundenen Tabellen, sondern zu einem kaskadierenden Erscheinen neuer Versionen der verknüpften Objekte — wenn Tabelle 1 beim Aufbau von Tabelle 2 verwendet wird und Tabelle 2 beim Aufbau von Tabelle 3 usw. Selbst wenn kein Attribut von Tabelle 1 an der Erstellung von Tabelle 3 beteiligt ist (sondern andere Attribute von Tabelle 2, die aus anderen Quellen stammen), wird ein versioniertes Update dieser Konstruktion mindestens zu zusätzlichen Overheadkosten führen und im schlimmsten Fall zu überflüssigen Versionen in Tabelle 3, die hier überhaupt 'nicht zutrifft' und so weiter in der Kette.
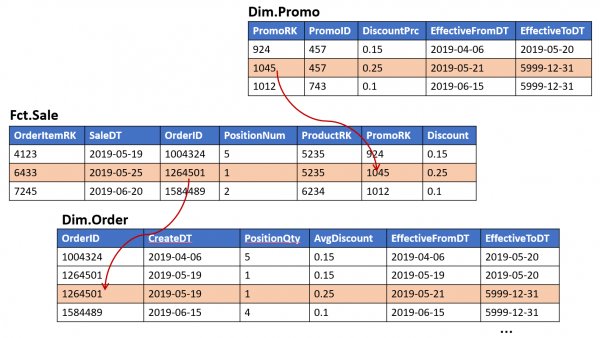
3. Nichtlineare Komplexität der Nachbearbeitung
Jede neue Sicht, die auf einer anderen basiert, erhöht die Anzahl der Stellen, an denen sich die Daten bei Änderungen im ETL „auseinanderentwickeln“ können. Dies führt wiederum zu einer höheren Komplexität (und Dauer) jeder nachfolgenden Anpassung.
Wenn das oben Beschriebene für Systeme mit selten angepassten ETL-Prozessen gilt, kann man in einer solchen Paradigme leben – es genügt, darauf zu achten, dass neue Anpassungen korrekt in alle verbundenen Objekte übernommen werden. Treten jedoch häufig Anpassungen auf, steigt die Wahrscheinlichkeit, versehentlich mehrere Verbindungen „zu übersehen“, erheblich.
Wenn man zudem bedenkt, dass „versioniertes“ ETL wesentlich komplexer ist als „nicht-versioniertes“, wird es ziemlich schwierig, Fehler bei häufigen Anpassungen dieser gesamten Struktur zu vermeiden.
Speicherung von Objekten und Attributen im Data Vault und Anchor Model
Der von den Autoren flexibler Architekturen vorgeschlagene Ansatz lässt sich wie folgt formulieren:
Es ist notwendig, das Veränderliche von dem Unveränderlichen zu trennen. Das heißt, Schlüssel separat von Attributen zu speichern.
Dabei sollte man nicht verwechseln nicht-versioniert das Attribut mit unverändert: Der erste speichert keine Änderungsverlauf, kann sich jedoch ändern (zum Beispiel bei der Korrektur eines Eingabefehlers oder beim Empfang neuer Daten); der zweite ändert sich niemals.
Über die Definition dessen, was in einem Data Vault und einem Anchor-Modell unveränderlich ist, gibt es unterschiedliche Ansichten.
Aus architektonischer Sicht Data Vault, kann man als unveränderlich betrachten das gesamte Satz an Schlüsseln — natürliche (z. B. die Steuer-Identifikationsnummer der Organisation, die Artikelnummer im Quellsystem usw.) und surrogate. Dabei können die anderen Attribute nach Quelle und/oder Änderungsfrequenz in Gruppen unterteilt werden und für jede Gruppe sollte eine separate Tabelle geführt werden mit einem unabhängigen Satz von Versionen.
Im Konzept des Anchor Model wird als unveränderlich betrachtet nur der surrogate Schlüssel der Entität. Alles andere (einschließlich der natürlichen Schlüssel) ist einfach ein Spezialfall seiner Attribute. Dabei sind alle Attribute standardmäßig unabhängig voneinander, daher sollte für jedes Attribut eine separate Tabelle erstellt werden..
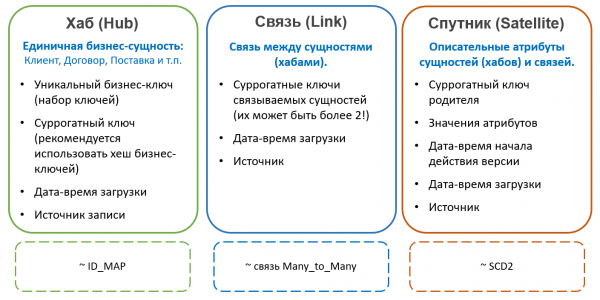
In Data Vault Die Tabellen, die Entitätsschlüssel enthalten, werden als Hubs (Hub). Hubs enthalten immer eine feste Anzahl von Feldern:
- Natürliche Entitätsschlüssel
- Surrogatschlüssel
- Referenz auf die Quelle
- Zeitpunkt der Hinzufügung des Datensatzes
Datensätze in den Hubs werden niemals geändert und haben keine Versionen. Äußerlich ähneln Hubs sehr den ID-Map-Tabellen, die in einigen Systemen zur Generierung von Surrogaten verwendet werden; jedoch wird im Data Vault empfohlen, als Surrogate keinen ganzzahligen Sequenzwert, sondern einen Hash aus einer Menge von Geschäftsschlüsseln zu verwenden. Dieser Ansatz vereinfacht das Laden von Beziehungen und Attributen aus Quellen (es ist nicht notwendig, sich mit dem Hub zu verbinden, um das Surrogat zu erhalten; es reicht aus, einfach den Hash des natürlichen Schlüssels zu berechnen), kann jedoch andere Probleme verursachen (wie Kollisionen, Groß-/Kleinschreibung und nicht druckbare Zeichen in Zeichenfolgen-Schlüsseln usw.), weshalb er nicht allgemein anerkannt ist.
Alle anderen Attribute der Entitäten werden in speziellen Tabellen gespeichert, die Satelliten (Satellit). Ein Hub kann mehrere Satelliten haben, die unterschiedliche Attributsätze speichern.
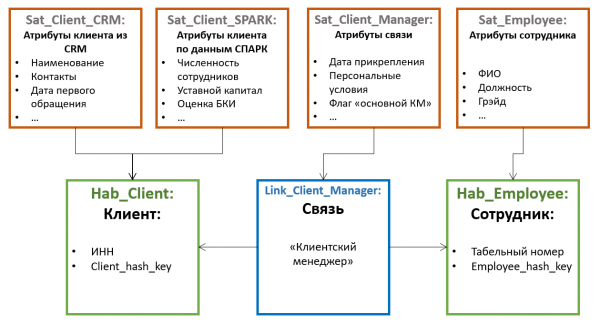
Die Verteilung der Attribute auf die Satelliten erfolgt nach dem Prinzip der gemeinsamen Änderung — In einem Satelliten können nicht-versionierte Attribute (zum Beispiel Geburtsdatum und SNILS für natürliche Personen) gespeichert werden, in einem anderen selten sich ändernde versionierte (zum Beispiel Nachname und Reisepassnummer), in einem dritten häufig sich ändernde (zum Beispiel Lieferadresse, Kategorie, Datum der letzten Bestellung usw.). Die Versionierung erfolgt dabei auf der Ebene der einzelnen Satelliten und nicht der Entität insgesamt, weshalb die Verteilung der Attribute so erfolgen sollte, dass die Überschneidung der Versionen innerhalb eines Satelliten minimal ist (was die Gesamtanzahl der gespeicherten Versionen reduziert).
Um den Datenladeprozess zu optimieren, werden in separate Satelliten häufig Attribute ausgelagert, die aus verschiedenen Quellen stammen.
Die Satelliten sind mit dem Hub verbunden über einen Fremdschlüssel (was der Kardinalität 1 zu vielen entspricht). Das bedeutet, dass mehrere Werte von Attributen (zum Beispiel mehrere Telefonnummern eines Kunden) durch solch eine Architektur „standardmäßig“ unterstützt werden.
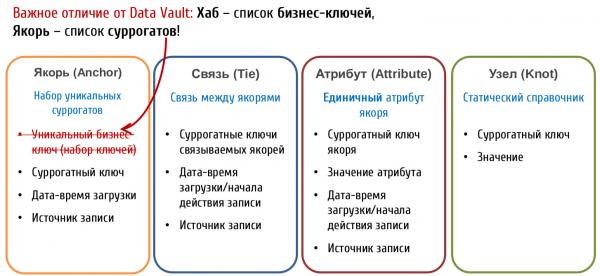
In Anker-Modell (Anchor Model) Tabellen, die Schlüssel speichern, werden genannt Anker (Anchor). Und sie speichern:
- Nur surrogate Schlüssel
- Referenz auf die Quelle
- Zeitpunkt der Hinzufügung des Datensatzes
Natürliche Schlüssel aus der Sicht des Anker-Modells gelten als gewöhnliche Attribute. Diese Variante mag komplexer erscheinen, bietet jedoch wesentlich mehr Spielraum zur Identifizierung des Objekts.
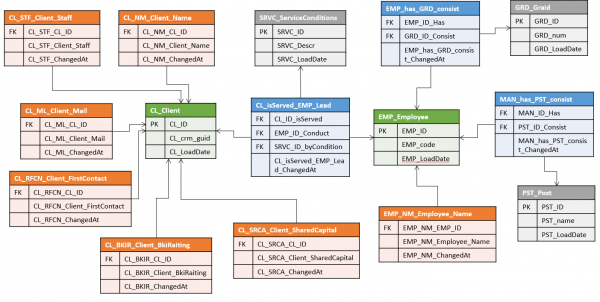
Wenn beispielsweise Daten über dieselbe Entität aus verschiedenen Systemen stammen, in denen jeweils ein anderer natürlicher Schlüssel verwendet wird. Im Data Vault kann dies zu ziemlich umfangreichen Konstruktionen aus mehreren Hubs führen (einen pro Quelle + eine vereinigende Master-Version), während im Anker-Modell der natürliche Schlüssel jeder Quelle in sein eigenes Attribut gelangt und unabhängig von allen anderen beim Laden verwendet werden kann.
Doch hier verbirgt sich ein tückischer Moment: Wenn in einer Entität Attribute aus verschiedenen Systemen zusammengeführt werden, gibt es wahrscheinlich bestimmte Regeln zur „Verklebung“, nach denen das System verstehen muss, dass Datensätze aus unterschiedlichen Quellen zu einem einzigen Exemplar der Entität gehören.
In Data Vault Diese Regeln werden wahrscheinlich die Bildung eines „surrogativen Hubs“ der Master-Entität bestimmen und keinen Einfluss auf die Hubs ausüben, die die nativen Schlüssel der Quellen und ihre ursprünglichen Attribute speichern. Wenn sich zu einem bestimmten Zeitpunkt die Kleberegeln ändern (oder ein Update der Attribute kommt, nach denen es erfolgt), reicht es aus, die Surrogat-Hubs neu zu bilden.
In Anker-Modell so wird eine solche Entität wahrscheinlich in einem einzigen Anker. Das bedeutet, dass alle Attribute, unabhängig von der Quelle, aus der sie stammen, an dasselbe Surrogat gebunden sind. Fehlerhaft zusammengeführte Datensätze zu trennen und die Aktualität der Zusammenführung in einem solchen System zu überwachen, kann sich als erheblich schwieriger erweisen, insbesondere wenn die Regeln recht komplex sind und sich häufig ändern, und das gleiche Attribut aus verschiedenen Quellen stammen kann (obwohl dies genau möglich ist, da jede Version des Attributs einen Verweis auf ihre Quelle speichert).
In jedem Fall, wenn in Ihrem System die Implementierung von Funktionen Deduplizierung, Zusammenführung von Datensätzen und anderen MDM-Elementen vorgesehen ist., es ist besonders wichtig, die Aspekte der Speicherung natürlicher Schlüssel in flexiblen Methodologien genau zu prüfen. Wahrscheinlich erweist sich die umfangreichere Data Vault-Konstruktion plötzlich als sicherer in Bezug auf Merge-Fehler.
Das Anker-Modell sieht auch einen zusätzlichen Objekttyp vor, der als Knoten (Knot) definiert ist, es handelt sich im Wesentlichen um eine spezielledegenerierte Variante des Ankers , die nur ein Attribut enthalten kann. Knoten sollen zur Speicherung flacher Nachschlagewerke verwendet werden (z. B. Geschlecht, Familienstand, Kundenkategorie usw.). Im Gegensatz zum Anker hat der Knotenkeine verknüpften Attribut-Tabellen
, und sein einziges Attribut (der Name) wird immer in einer Tabelle mit dem Schlüssel gespeichert. Knoten werden mit Ankern durch Verknüpfungstabellen (Tie) verbunden, ähnlich wie Anker untereinander. Nikolaï Golov immer , der die Anwendung des Anker-Modells in Russland aktiv fördert, ist der Ansicht (nicht ohne Grund), dass man für kein Nachschlagewerk mit Sicherheit behaupten kann, dass es
Ein weiteres wichtiges Unterscheidungsmerkmal zwischen Data Vault und dem Anker-Modell ist das Vorhandensein von Attributen bei den Verbindungen.:
In Data Vault Verbindungen sind ebenso eigenständige Objekte wie Hubs und können eigene Attribute haben.In Anker-Modell Verbindungen werden ausschließlich verwendet, um Anker zu verbinden und können keine eigenen Attribute haben.. Diese Unterscheidung führt zu grundlegend unterschiedlichen Ansätzen in der Modellierung von Fakten., worüber wir im Folgenden sprechen werden.
Die Speicherung von Fakten.
Zuvor haben wir hauptsächlich über die Modellierung von Dimensionen gesprochen. Bei Fakten gestaltet sich die Sache etwas weniger eindeutig.
In Data Vault Ein typisches Objekt zur Speicherung von Fakten ist eine Verbindung (Link),in deren Satelliten sich die tatsächlichen Kennzahlen ansammeln.
Dieser Ansatz erscheint intuitiv verständlich. Er ermöglicht einfachen Zugriff auf die analysierten Kennzahlen und ähnelt insgesamt einer traditionellen Faktentabelle (nur dass die Kennzahlen nicht in der Tabelle selbst gespeichert werden, sondern in einer "benachbarten"). Aber es gibt auch Fallstricke: Eine der typischen Anpassungen des Modells — die Erweiterung des Faktenschlüssels — erfordert die Hinzufügung eines neuen Fremdschlüssels in den Link.. Dies „bricht“ wiederum die Modularität und kann potenziell die Notwendigkeit von Anpassungen anderer Objekte zur Folge haben.
In Anker-Modell Eine Beziehung kann keine eigenen Attribute haben, daher funktioniert dieser Ansatz nicht — alle Attribute und Kennzahlen müssen an einen bestimmten Anker gebunden sein. Die Schlussfolgerung ist einfach — für jede Tatsache wird auch ein eigener Anker benötigt.. Bei einigen der Dinge, die wir als Fakten betrachten, mag dies natürlich erscheinen — zum Beispiel wird der Kauf als Objekt „Bestellung“ oder „Beleg“ interpretiert, der Besuch einer Website — als Sitzung usw. Doch gibt es auch Fakten, für die es nicht so einfach ist, ein solches natürliches „Trägersubjekt“ zu finden — etwa der Warenbestand in den Lagern zu Beginn eines jeden Tages.
Daher gibt es bei der Erweiterung des Schlüssels für Fakten im Anker-Modell keine Probleme mit der Modularität (es reicht aus, eine neue Beziehung zum entsprechenden Anker hinzuzufügen), aber das Design des Modells zur Darstellung von Fakten ist weniger eindeutig, und es können „künstliche“ Anker entstehen, die das Geschäftsobjektmodell nicht offensichtlich darstellen.
Wie wird Flexibilität erreicht?
Die entstandene Struktur enthält in beiden Fällen deutlich mehr Tabellen, als die traditionelle Messung. Sie kann jedoch deutlich weniger Speicherplatz beanspruchen bei denselben Versionierungsattributen wie die traditionelle Messung. Natürlich gibt es hier keine Magie – alles hängt von der Normalisierung ab. Indem wir die Attribute auf Satelliten (im Data Vault) oder separate Tabellen (Anchor Model) verteilen, reduzieren wir (oder schließen ganz aus) die Duplizierung von Werten einiger Attribute bei der Änderung anderer..
Für Data Vault Der Gewinn hängt von der Verteilung der Attribute auf die Satelliten ab, und für Anker-Modell ist er praktisch direkt proportional zur durchschnittlichen Anzahl der Versionen eines Messobjekts.
Der Gewinn an Speicherplatz ist jedoch ein wichtiges, aber nicht das Hauptvorteil separater Attributspeicherung. Zusammen mit der separaten Speicherung von Beziehungen macht dieser Ansatz das Data Warehouse modular aufgebaut.Das bedeutet, dass die Hinzufügung sowohl einzelner Attribute als auch ganzer neuer Fachgebiete in ein solches Modell wie eine Erweiterung des bestehenden Satzes von Objekten aussieht, ohne deren Änderungen. Und genau das macht die beschriebenen Methoden flexibel.
Es erinnert auch an den Übergang von Einzel- zu Massenerzeugung — während im traditionellen Ansatz jede Modelltabelle einzigartig ist und besondere Aufmerksamkeit erfordert, handelt es sich bei flexiblen Methoden bereits um eine Reihe von standardisierten "Details". Einerseits gibt es mehr Tabellen, die Datenlade- und -abfrageprozesse erscheinen komplexer. Andererseits werden sie standardisiert. Das bedeutet, sie können automatisiert und durch Metadaten gesteuert werden. Die Frage „Wie werden wir das umsetzen?” — auf die vorher ein erheblicher Teil der Entwurfsarbeit entfiel — stellt sich jetzt einfach nicht mehr (genauso wenig wie die Frage nach den Auswirkungen einer Modelländerung auf die bestehenden Prozesse).
Das bedeutet nicht, dass Analysten in einem solchen System völlig überflüssig sind — irgendjemand muss immer noch ein Set von Objekten mit Attributen bearbeiten und sich darüber klar werden, wo und wie man all dies lädt. Aber das Arbeitsvolumen sowie die Wahrscheinlichkeit und die Kosten eines Fehlers sinken erheblich. Sowohl in der Analysephase als auch bei der ETL-Entwicklung, die in erheblichem Maße auf die Bearbeitung von Metadaten reduziert werden kann.
Die dunkle Seite
Alles, was oben beschrieben wurde, macht beide Ansätze wirklich flexibel, technologisch fortschrittlich und geeignet für iterative Verbesserungen. Natürlich gibt es auch ‚den Wermutstropfen‘, dessen Sie sich, wie ich denke, bereits bewusst sind.
Die Dekompensation von Daten, die der Modularität flexibler Architekturen zugrunde liegt, führt zu einer zunehmenden Anzahl von Tabellen und damit auch zu overhead costs für Joins während der Abfrage. Um einfach alle Attributmessungen zu erhalten, reicht in einem klassischen Lager ein einziges Select aus, während eine flexible Architektur eine ganze Reihe von Joins erfordert. Während diese Joins für Berichte im Voraus geschrieben werden können, wird es Analysten, die es gewohnt sind, SQL von Hand zu schreiben, doppelt schwerfallen.
Es gibt einige Faktoren, die diese Situation erleichtern:
Beim Arbeiten mit großen Dimensionen werden fast nie alle Attribute gleichzeitig genutzt. Das bedeutet, dass die Verbindungen weniger sein können, als es auf den ersten Blick bei dem Modell scheint. Im Data Vault kann auch die angenommene gemeinsame Nutzungshäufigkeit bei der Verteilung von Attributen auf Satelliten berücksichtigt werden. Dabei dienen die Hubs oder Anker in erster Linie zur Generierung und Zuordnung von Surrogaten während des Ladevorgangs und werden selten in Abfragen verwendet (insbesondere gilt dies für die Anker).
Alle Joins erfolgen über Schlüssel. Darüber hinaus verringert eine „kompaktere“ Methode zur Speicherung von Daten die Kosten für das Scannen von Tabellen, wo es notwendig ist (zum Beispiel beim Filtern nach Attributwerten). Dies kann dazu führen, dass eine Abfrage aus einer normalisierten Datenbank mit vielen Joins sogar schneller ist als das Scannen einer einzigen großen Dimension mit vielen Versionen pro Zeile.
Zum Beispiel gibt es in diesem Artikel einen detaillierten Leistungsvergleichstest des Anker-Modells mit einer Abfrage aus einer Tabelle.
Vieles hängt vom Engine ab. Viele moderne Plattformen verfügen über interne Mechanismen zur Optimierung von Joins. Beispielsweise sind MS SQL und Oracle in der Lage, Joins auf Tabellen zu "überspringen", wenn deren Daten nirgendwo anders verwendet werden, außer in anderen Joins, und keinen Einfluss auf die endgültige Auswahl haben (Table/Join Eliminierung). MPP Vertica hat sich in. , als hervorragende Engine für das Anchormodell erwiesen, wenn auch mit gewisser manueller Optimierung des Abfrageplans. Andererseits scheint es keine besonders gute Idee zu sein, das Anchormodell beispielsweise in Click House zu speichern, das eine begrenzte Unterstützung für Joins hat.
Darüber hinaus gibt es spezielle Techniken , die den Zugriff auf Daten erleichtern (sowohl aus Sicht der Abfrageleistung als auch für die Endbenutzer). Zum BeispielPoint-In-Time-Tabellen im Data Vault oder spezielle Tabellenfunktionen im Anchormodell. Der Hauptgedanke der betrachteten flexiblen Architekturen liegt in der Modularität ihrer "Konstruktion".
Gesamt
Genau diese Eigenschaft ermöglicht es:
Nach einer gewissen anfänglichen Vorbereitung, die mit der Bereitstellung von Metadaten und dem Schreiben grundlegender ETL-Algorithmen verbunden ist,
- schnell dem Kunden das erste Ergebnis zu liefern. schnell dem Kunden das erste Ergebnis liefern in Form von ein paar Berichten, die Daten von nur wenigen Quellobjekten enthalten. Es ist nicht notwendig, das gesamte Objektmodell vollständig zu durchdenken (auch nicht auf oberster Ebene).
- Das Datenmodell kann mit nur 2-3 Objekten beginnen und dennoch Nutzen bringen, und dann allmählich anwachsen. (in Bezug auf das Anker-Modell hat Nikolai Die meisten Erweiterungen, einschließlich der Erweiterung des Fachbereichs und der Hinzufügung neuer Quellen,
- beeinflussen nicht die bestehende Funktionalität und gefährden nicht, etwas, das bereits funktioniert, zu beschädigen. Durch die Zerlegung in Standardelemente erscheinen ETL-Prozesse in solchen Systemen einheitlich, ihre Erstellung kann algorithmisiert und letztendlich.
- automatisiert werden. Der Preis dieser Flexibilität ist.
. Das bedeutet nicht, dass es unmöglich ist, akzeptable Leistung mit solchen Modellen zu erreichen. Häufig müssen Sie einfach mehr Aufwand und Aufmerksamkeit auf Details verwenden, um die gewünschten Kennzahlen zu erreichen. LeistungEntitätstypen
Anwendungen
Mehr über Data Vault: Data Vault
Die Website von Dan Linstedt
Mehr über das Anker-Modell: Anchor Model
Mehr über das Anchor Model:
Übersichtstabelle mit allgemeinen Merkmalen und Unterschieden der betrachteten Ansätze:

Quelle: habr.com
