

OpenShift-Virtualisierung (Upstream-Projekt – Kubernetes: KubeVirt, siehe. и Kubernetes Virtualization (ehemals Container-native Virtualization) wurde als Funktion der OpenShift-Plattform eingeführt, um virtuelle Maschinen (VMs) als Kernelemente von Kubernetes bereitzustellen und zu verwalten. Diese Aufgabe ist aufgrund grundlegender technologischer Unterschiede technisch anspruchsvoll. Um dieses Ziel zu erreichen, wurden bewährte Technologien auf Basis von Red Hat Enterprise eingesetzt. Linux und KVM, die uns seit vielen Jahren begleiten und ihre Effektivität unter Beweis gestellt haben.

In diesem Artikel befassen wir uns mit den technischen Aspekten der OpenShift-Virtualisierung, die es ermöglichen, dass VMs und Container auf einer einzigen Plattform koexistieren, die sie als eine Einheit verwaltet.
Rechenaufgaben
Container nutzen Mechanismen LinuxKernfunktionen wie Namensräume und Cgroups dienen der Prozessisolation und Ressourcenverwaltung. Prozesse werden üblicherweise als Python- oder Java-Anwendungen oder ausführbare Dateien verstanden, können aber in Wirklichkeit beliebige Prozesse sein, beispielsweise Bash, Emacs oder Vim.
Was ist eine virtuelle Maschine? Aus Sicht des Hypervisors ist dies ebenfalls ein Prozess. Aber nicht der Anwendungsprozess, sondern der KVM-Prozess, der für die Ausführung einer bestimmten VM verantwortlich ist.
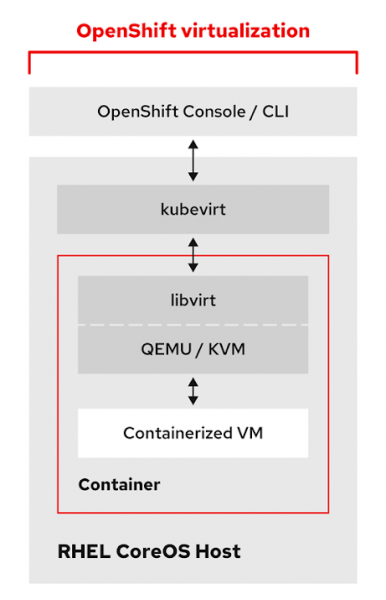
Das Container-Image enthält alle Tools, Bibliotheken und Dateien, die für die virtuelle KVM-Maschine benötigt werden. Wenn wir den Pod einer laufenden VM untersuchen, werden wir dort Helfer und qemu-kvm-Prozesse sehen. Darüber hinaus haben wir Zugriff auf KVM-Tools zur Verwaltung virtueller Maschinen wie qemu-img, qemu-nbd und virsh.

Da eine virtuelle Maschine ein Pod ist, erbt sie automatisch alle Funktionen eines Pods in Kubernetes. VM-Pods unterliegen, genau wie normale Pods, Zeitplanungsschemata und Kriterien wie Taints, Toleranzen, Affinität und Anti-Affinität. Sie profitieren außerdem von den Vorteilen einer hohen Verfügbarkeit usw. Allerdings gibt es einen wichtigen Unterschied: Normale Pods wandern nicht im üblichen Sinne von Host zu Host. Wenn ein Knoten offline geht, wird der darauf befindliche Pod beendet und einem anderen Knoten im Cluster neu zugewiesen. Und im Falle einer virtuellen Maschine erwarten wir eine Live-Migration.
Um diese Lücke zu schließen, wurde eine benutzerdefinierte Ressourcendefinition (CDR) erstellt, um den Live-Migrationsmechanismus zu beschreiben, der für die Initialisierung, Überwachung und Verwaltung von Live-Migrationen von VMs zwischen Worker-Knoten verantwortlich ist.
apiVersion: kubevirt.io/v1alpha3
kind: VirtualMachineInstanceMigration
metadata:
name: migration-job
spec:
vmiName: fedora
Wenn ein Knoten deaktiviert wird, werden automatisch Migrationsaufgaben für die virtuellen Maschinen erstellt, für die Live Migration als Räumungsstrategie festgelegt ist. Auf diese Weise können Sie das Verhalten virtueller Maschinen beim Wechsel zwischen Clusterknoten steuern. Sie können sowohl die Live-Migration konfigurieren als auch die VM verwalten, wie alle anderen Pods auch.
Netzwerk
Jedes Kubernetes-System ermöglicht die Kommunikation zwischen Knoten und Pods mithilfe von Software-SDN-Netzwerken. OpenShift bildet da keine Ausnahme und nutzt hierfür ab Version 3 standardmäßig OpenShiftSDN. Darüber hinaus verfügt OpenShift 4 über eine weitere neue Funktion namens Multus, mit der Sie mehrere Netzwerke verfügbar machen und Pods gleichzeitig mit ihnen verbinden können.
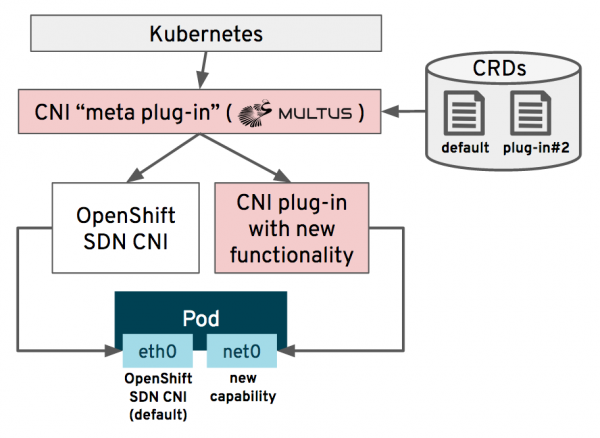
Mithilfe von Multus kann der Administrator zusätzliche CNI-Netzwerke definieren, die anschließend mithilfe eines dedizierten Cluster-Netzwerkoperators im Cluster bereitgestellt und konfiguriert werden. Pods werden dann mit einem oder mehreren dieser Netzwerke verbunden, typischerweise mit dem Standard-OpenShiftSDN und einer zusätzlichen Schnittstelle. SR-IOV-Geräte, Standard Linux Bridge-, MACVLAN- und IPVLAN-Geräte können bei Bedarf von Ihrer VM verwendet werden. Die folgende Abbildung zeigt, wie Sie Multus CNI für das Bridge-Netzwerk auf der eth1-Schnittstelle konfigurieren:
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
additionalNetworks:
- name: multus1
rawCNIConfig: '{ "cniVersion": "0.3.1", "type": "bridge", "master": "eth1", "ipam":
{ "type": "static", "addresses": [ { "address": "191.168.1.1/24" } ] } }'
type: Raw
Bezogen auf die OpenShift-Virtualisierung bedeutet dies, dass eine VM direkt und unter Umgehung von SDN mit einem externen Netzwerk verbunden werden kann. Dies ist wichtig für virtuelle Maschinen, die von Red Hat Virtualization oder VMware vSphere auf OpenShift migriert wurden, da sich die Netzwerkeinstellungen nicht ändern, wenn Sie Zugriff auf die zweite OSI-Schicht haben. Dies bedeutet auch, dass die VM möglicherweise eine Netzwerkadresse hat, die SDN umgeht. So können wir spezielle Netzwerkadapter effektiv nutzen oder über das Netzwerk direkt eine Verbindung zum Speichersystem herstellen ...
Erfahren Sie mehr darüber, wie Sie virtuelle OpenShift-Virtualisierungsmaschinen erstellen und mit dem Netzwerk verbinden . Zusätzlich , das als Teil der OpenShift-Virtualisierung bereitgestellt wird, bietet eine weitere bekannte Möglichkeit, Netzwerkkonfigurationen auf physischen Knoten zu erstellen und zu verwalten, die unter Hypervisoren verwendet werden.
Lagerung
Das Verbinden und Verwalten von Festplatten virtueller Maschinen innerhalb der OpenShift-Virtualisierung erfolgt mithilfe von Kubernetes-Konzepten wie StorageClasses, PersistentVolumeClaims (PVC) und PersistentVolume (PV) sowie Speicherprotokollen, die standardmäßig für die Kubernetes-Umgebung gelten. Dies bietet Kubernetes-Administratoren und Anwendungsteams eine gemeinsame, vertraute Möglichkeit, sowohl Container als auch virtuelle Maschinen zu verwalten. Und vielen Administratoren von Virtualisierungsumgebungen kommt dieses Konzept vielleicht bekannt vor, da es das gleiche Prinzip der Trennung von VM-Konfigurationsdateien und -Festplatten verwendet, das in OpenStack und vielen anderen Cloud-Plattformen verwendet wird.
Wir können jedoch nicht jedes Mal einfach eine neue Festplatte für die VM erstellen, da wir bei der Migration vom Hypervisor zu OpenShift die Daten speichern müssen. Ja, selbst wenn wir eine neue VM bereitstellen, ist es immer schneller, dies anhand einer Vorlage zu tun, als sie von Grund auf neu zu erstellen. Daher benötigen wir eine Funktionalität zum Importieren vorhandener Datenträger.
Um diese Aufgabe zu vereinfachen, stellt die OpenShift-Virtualisierung das Containerized Data Importer (CDI)-Projekt bereit, das den Import von Disk-Images von Festplatten aus mehreren Quellen auf die Erstellung eines PVC-Eintrags reduziert.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: "fedora-disk0"
labels:
app: containerized-data-importer
annotations:
cdi.kubevirt.io/storage.import.endpoint: "http://10.0.0.1/images/Fedora-Cloud-Base-31-1.9.x86_64.qcow2"
spec:
storageClassName: ocs-gold
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
Dieser Eintrag aktiviert CDI und löst die in der folgenden Abbildung dargestellte Aktionsfolge aus:
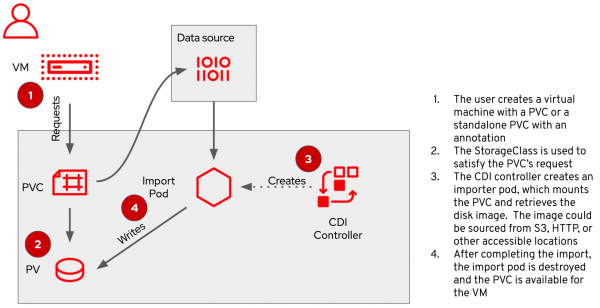
Nach Abschluss des CDI enthält das PVC die Festplatte der virtuellen Maschine, die zur Verwendung bereit und in das Standard-OpenShift-Format konvertiert ist ...
Bei der Arbeit mit OpenShift-Virtualisierung ist auch OpenShift Container Storage (OCS) nützlich, eine auf dem Ceph-Dateisystem basierende Red Hat-Lösung, die persistente Speicherfunktionen für Container implementiert. Zusätzlich zu den Standard-PVC-Zugriffsmethoden RWO (Block) und RWX (Datei) stellt OCS RWX für Raw-Block-Geräte bereit, was für die gemeinsame Nutzung des Blockzugriffs für Anwendungen mit hohen Leistungsanforderungen sehr nützlich ist. Darüber hinaus unterstützt OCS den neuen Object Bucket Claim-Standard, der es Anwendungen ermöglicht, Objektdatenspeicher direkt zu nutzen.
Virtuelle Maschinen in Containern
Wenn Sie wissen möchten, wie es funktioniert, wissen Sie, dass die OpenShift-Virtualisierung bereits in der Tech Preview-Version als Teil von OpenShift 3.11 und höher verfügbar ist. Besitzer eines bestehenden OpenShift-Abonnements können die OpenShift-Virtualisierung völlig kostenlos und ohne zusätzliche Schritte nutzen. Zum Zeitpunkt dieses Beitrags sind OpenShift 4.4 und OpenShift Virtualization 2.3 aktuell; wenn Sie frühere Versionen verwenden, sollten Sie ein Upgrade durchführen, um die neuesten Funktionen zu erhalten. Eine vollständig unterstützte Version der OpenShift-Virtualisierung soll in der zweiten Hälfte des Jahres 2020 veröffentlicht werden.
Für mehr Informationen, kontaktieren sie bitte für Installationsanweisungen, einschließlich , das Informationen zum Einrichten externer Netzwerke enthält.
Source: habr.com
