


Die Präsentation befasst sich mit praktischen Aspekten der Entwicklung von Operatoren in Kubernetes, der Architekturplanung und den grundlegenden Funktionsprinzipien.
Im ersten Teil der Präsentation werden wir folgende Themen behandeln:
- Was ist ein Operator in Kubernetes und wofür wird er benötigt;
- Wie der Operator das Management komplexer Systeme vereinfacht;
- Was der Operator kann und was nicht.
Anschließend werden wir das interne Design des Operators besprechen. Wir betrachten die Architektur und das Funktionieren des Operators Schritt für Schritt. Detaillierte Betrachtung von:
- der Interaktion zwischen dem Operator und Kubernetes;
- welche Funktionen der Operator übernimmt und was er an Kubernetes delegiert.
Wir betrachten das Management von Shards und Datenbank-Replikaten in Kubernetes.
Dann diskutieren wir Fragen der Datenspeicherung:
- Wie man mit Persistent Storage aus der Perspektive des Operators arbeitet;
- Die Fallstricke der Nutzung von Local Storage.
Im abschließenden Teil der Präsentation werden wir praktische Anwendungsbeispiele betrachten mit Amazon oder Google Cloud Service. Die Präsentation basiert auf der Entwicklung und den Betriebserfahrungen eines Operators für ClickHouse.
Video:

Mein Name ist Vladislav Klimenko. Heute möchte ich über unsere Erfahrungen mit der Entwicklung und dem Betrieb eines Operators sprechen, speziell über einen Operator zur Verwaltung von Datenbankclustern. Am Beispiel für die Verwaltung des ClickHouse-Clusters.

Warum sind wir in der Lage, über den Operator und ClickHouse zu berichten?
- Wir unterstützen und entwickeln ClickHouse weiter.
- Derzeit bemühen wir uns, schrittweise unseren Beitrag zur Entwicklung von ClickHouse zu leisten. Wir sind die zweitgrößte Entität nach Yandex, was die Anzahl der durchgeführten Änderungen in ClickHouse betrifft.
- Wir planen zusätzliche Projekte für das Ökosystem von ClickHouse.
Über eines dieser Projekte möchte ich sprechen. Es geht um den ClickHouse-Operator für Kubernetes.
In meinem Vortrag möchte ich zwei Themen ansprechen:
- Das erste Thema ist, wie unser Operator zur Verwaltung von ClickHouse-Datenbanken in Kubernetes funktioniert.
- Das zweite Thema betrifft, wie jeder Operator funktioniert, d.h. wie er mit Kubernetes interagiert.
Diese beiden Fragen werden sich während meines gesamten Vortrags überschneiden.

Wer könnte daran interessiert sein, zuzuhören, was ich zu sagen versuche?
- Am meisten interessiert sein werden diejenigen, die Operatoren betreiben.
- Oder an diejenigen, die ihren eigenen erstellen möchten, um zu verstehen, wie es intern funktioniert, wie der Betreiber mit Kubernetes interagiert und welche Fallstricke auftreten können.

Um das, was wir heute besprechen werden, besser zu verstehen, wäre es hilfreich zu wissen, wie Kubernetes funktioniert und über grundlegendes Wissen in Cloud-Technologien zu verfügen.
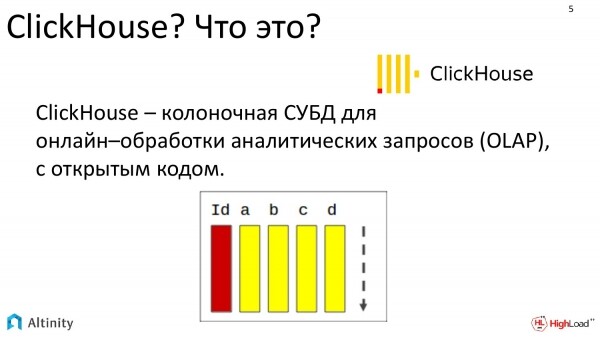
Was ist ClickHouse? Es ist eine spaltenorientierte Datenbank, die sich auf die Online-Verarbeitung analytischer Anfragen spezialisiert hat. Und sie ist vollständig Open Source.
Dabei ist es wichtig, nur zwei Dinge zu wissen. Erstens, es handelt sich um eine Datenbank, weshalb das, was ich erzählen werde, praktisch auf jede Datenbank anwendbar ist. Und zweitens, dass die Datenbank ClickHouse sehr gut skalierbar ist und praktisch lineare Skalierbarkeit bietet. Der Zustand des Clusters ist daher für ClickHouse natürlich. Und es interessiert uns am meisten, zu besprechen, wie man einen ClickHouse-Cluster in Kubernetes verwaltet.

Warum ist er dort notwendig? Warum können wir ihn nicht weiterhin eigenständig betreiben? Die Antworten sind teilweise technischer Natur und teilweise organisatorischer Art.
- In der Praxis begegnen wir immer häufiger der Situation, dass in großen Unternehmen bereits fast alle Komponenten in Kubernetes integriert sind. Die Datenbanken sind jedoch noch außen vor.
- Immer häufiger stellt sich die Frage: 'Kann man das auch intern integrieren?'. Daher bemühen sich große Unternehmen um eine maximale Vereinheitlichung des Managements, um ihre Datenspeicher schnell verwalten zu können.
- Dies ist besonders hilfreich, wenn die maximale Wiederholbarkeit an einem neuen Standort erforderlich ist, d. h. maximale Portabilität.

Wie einfach oder kompliziert ist das? Natürlich kann man es manuell durchführen. Allerdings ist es nicht so einfach, da sich die Komplexität des Kubernetes-Managements mit den speziellen Anforderungen von ClickHouse überschneidet. Dadurch entsteht eine gewisse Aggregation.
Insgesamt ergibt sich daraus ein recht umfangreicher Technologie-Stack, dessen Verwaltung zunehmend komplex wird, da Kubernetes tägliche Betriebsfragen mit sich bringt und ClickHouse ebenso spezifische Anforderungen an den täglichen Betrieb stellt. Besonders, wenn wir mehrere ClickHouse-Instanzen betreiben und ständig mit ihnen arbeiten müssen.

Bei ClickHouse gibt es bei der dynamischen Konfiguration eine Vielzahl von Fragen, die eine ständige Belastung für die DevOps-Teams darstellen.
- Wenn wir etwas in ClickHouse ändern möchten, etwa eine Replik oder einen Shard hinzufügen, müssen wir das Konfigurationsmanagement durchführen.
- Anschließend muss das Datenmodell angepasst werden, da ClickHouse eine spezielle Art des Shardings verwendet. Hierbei ist es notwendig, das Datenmodell und die Konfigurationen aufzuteilen.
- Es muss ein Monitoring eingerichtet werden.
- Das Sammeln von Logs für neue Shards und neue Replikate ist erforderlich.
- Man muss sich um die Wiederherstellung kümmern.
- Und um den Neustart.
Das sind alltägliche Aufgaben, deren Durchführung in der Verwaltung gern erleichtert werden würde.

Kubernetes unterstützt dabei gut, aber vor allem in grundlegenden Systemaufgaben.
Kubernetes erleichtert und automatisiert solche Vorgänge wie:
- Wiederherstellung.
- Neustart.
- Management des Speichersystems.
Das ist positiv und in die richtige Richtung, jedoch hat es keine umfassende Vorstellung davon, wie ein Datenbankcluster betrieben wird.
Wir wünschen uns mehr, wir möchten, dass unsere gesamte Datenbank in Kubernetes läuft.

Man wünscht sich etwas wie einen großen, magischen roten Knopf, auf den man drückt, und sofort wird ein Cluster eingerichtet und über den gesamten Lebenszyklus hinweg betreut, um die täglichen Herausforderungen zu bewältigen. ClickHouse-Cluster in Kubernetes.
Wir haben versucht, eine Lösung zu schaffen, die die Arbeit erleichtert. Dies ist der ClickHouse-Operator für Kubernetes von Altinity.

Ein Operator ist ein Programm, dessen Hauptaufgabe es ist, andere Programme zu verwalten, also fungiert es als Manager.
Es enthält Verhaltensmuster, die man als kodifiziertes Wissen über das Fachgebiet bezeichnen kann.
Sein Hauptzweck besteht darin, das Leben von DevOps zu erleichtern und Mikromanagement zu reduzieren, damit DevOps in höheren Begriffen denken kann, anstatt sich mit der manuellen Anpassung aller Details zu beschäftigen.
Der Operator ist also ein hilfreicher Roboter, der sich mit Mikroaufgaben auseinandersetzt und DevOps unterstützt.

Warum ist ein Operator notwendig? Besonders gut bewährt er sich in zwei Bereichen:
- Wenn ein Spezialist für ClickHouse nicht genügend Erfahrung hat, aber ClickHouse dennoch einsetzen muss, erleichtert der Operator die Nutzung und ermöglicht den Betrieb eines komplex konfigurierten ClickHouse-Clusters, ohne sich intensiv mit den internen Abläufen auseinanderzusetzen. Man gibt ihm einfach hochrangige Aufgaben, und es funktioniert.
- Die zweite Aufgabe, in der er sich besonders gut zeigt, ist die Automatisierung einer großen Anzahl typischer Aufgaben. Er entlastet die Systemadministratoren von Kleinstaufgaben.

Das braucht man besonders entweder für Einsteiger oder für diejenigen, die viel Automatisierung durchführen müssen.

Was unterscheidet also den auf Operatoren basierenden Ansatz von anderen Systemen? Es gibt ja Helm. Das hilft ebenfalls beim Aufsetzen von ClickHouse, man kann Helm-Charts zeichnen, die sogar einen ganzen ClickHouse-Cluster einrichten. Wo liegt also der Unterschied zwischen dem Operator und z.B. Helm?
Der grundlegende Unterschied besteht darin, dass Helm ein Paketmanagement-System ist, während der Operator darüber hinausgeht. Er umfasst den gesamten Lebenszyklus des Systems. Es geht nicht nur um die Installation, sondern um tägliche Aufgaben wie Skalierung, Sharding und alles, was im Lebenszyklus erledigt werden muss (einschließlich der Deinstallation, falls erforderlich) – all dies wird durch den Operator gesteuert. Sein Ziel ist es, den gesamten Lebenszyklus der Software zu automatisieren und zu verwalten. Das ist das fundamentale Unterscheidungsmerkmal zu anderen Lösungen, die zur Verfügung stehen.
Das war der einführende Teil, lassen Sie uns fortfahren.
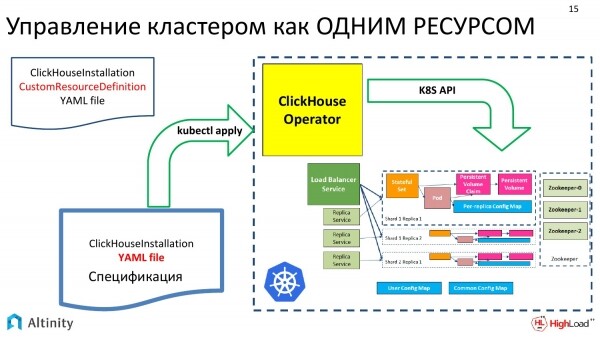
Wie bauen wir unseren Operator? Wir versuchen, den Cluster von ClickHouse als eine einzige Ressource zu verwalten.
Auf der linken Seite sehen wir die Eingaben. Dies ist YAML mit der Spezifikation des Clusters, die klassisch über kubectl an Kubernetes übergeben wird. Dort erfasst der Operator dies, vollbringt seine Magie. Und am Ende erhalten wir ein solches Schema. Das ist die Implementierung von ClickHouse in Kubernetes.
Wir werden uns weiterhin langsam anschauen, wie der Operator funktioniert und welche typischen Aufgaben gelöst werden können. Wir konzentrieren uns auf typische Aufgaben, da wir nur begrenzte Zeit haben. Es wird nicht alles behandelt, was der Operator leisten kann.

Lassen Sie uns von der Praxis ausgehen. Unser Projekt ist vollständig Open Source, daher können Sie auf GitHub sehen, wie es funktioniert. Wenn Sie einfach starten möchten, können Sie mit dem Quick Start Guide beginnen.
Wenn Sie detailliert einsteigen möchten, bemühen wir uns, die Dokumentation in einem angemessenen Zustand zu halten.

Lassen Sie uns mit einer praktischen Aufgabe beginnen. Die erste Aufgabe, mit der wir beginnen möchten, besteht darin, das erste Beispiel irgendwie auszuführen. Wie können wir mit Hilfe des Operators ClickHouse starten, selbst wenn wir nicht genau wissen, wie er funktioniert? Wir schreiben ein Manifest, da die gesamte Kommunikation mit k8s über Manifeste erfolgt.

Hier ist ein solches komplexes Manifest. Was rot hervorgehoben ist, sind die Punkte, auf die Sie achten sollten. Wir bitten den Operator, ein Cluster mit dem Namen demo zu erstellen.
Das sind vorläufig die grundlegenden Beispiele. Storage wird noch nicht beschrieben, aber wir werden später darauf zurückkommen. Im Moment beobachten wir die Entwicklung des Clusters.
Wir haben dieses Manifest erstellt. Wir füttern es unserem Operator. Er hat gearbeitet, hat seine Magie wirken lassen.

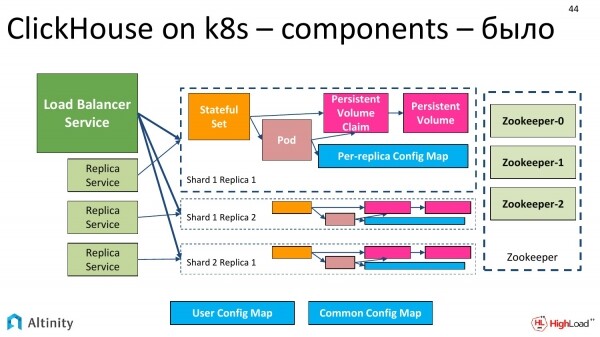
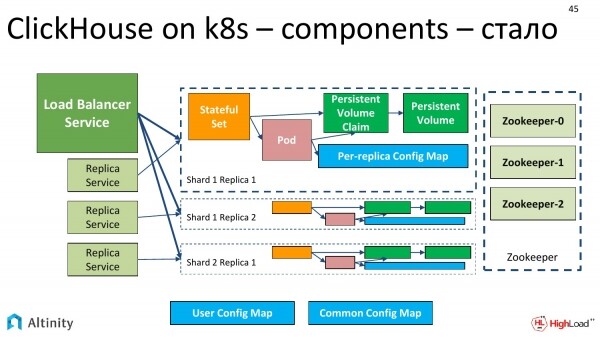
Schauen wir in die Konsole. Drei Komponenten wecken unser Interesse – das sind der Pod, zwei Services und der StatefulSet.
Der Operator hat gearbeitet, und wir können sehen, was genau er erstellt hat.
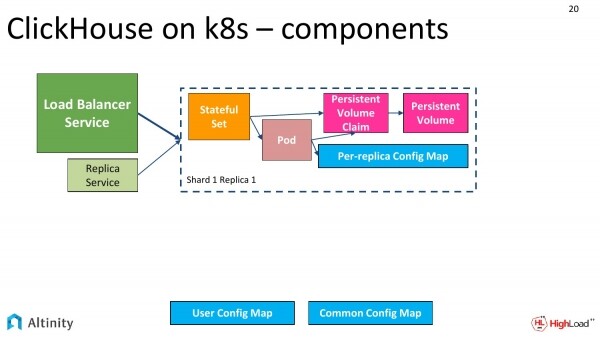
Er erstellt ungefähr ein solches Schema. Wir haben ein StatefulSet, einen Pod, einen ConfigMap für jede Replica und einen ConfigMap für das gesamte Cluster. Unbedingt benötigt werden die Services als Eingabepunkte in das Cluster.
Die Services sind der zentrale Load Balancer Service und ggf. kann man auch für jede Replica, für jedes Shard einen weiteren hinzufügen.
So sieht unser Basis-Cluster ungefähr aus. Es besteht aus einer einzigen Node.

Lass uns weitermachen, wir werden es komplizierter gestalten. Das Cluster muss ge-shardet werden.
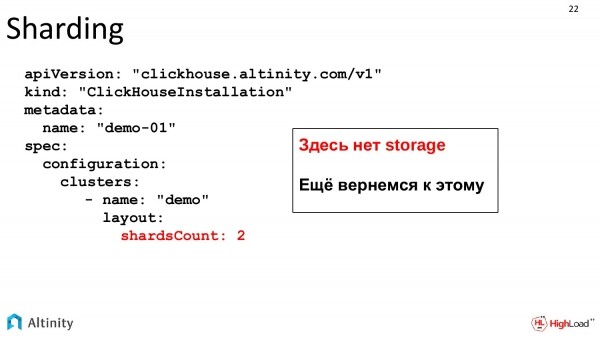
Unsere Aufgaben wachsen, die Dynamik beginnt. Wir möchten ein Shard hinzufügen. Wir verfolgen die Entwicklung. Wir ändern unsere Spezifikation und geben an, dass wir zwei Shards wollen.
Das ist dieselbe Datei, die sich dynamisch mit dem Wachstum des Systems weiterentwickelt. Storage ist noch nicht vorhanden, das wird später behandelt; das ist ein separates Thema.
Wir füttern den YAML-Operator und sehen, was dabei herauskommt.

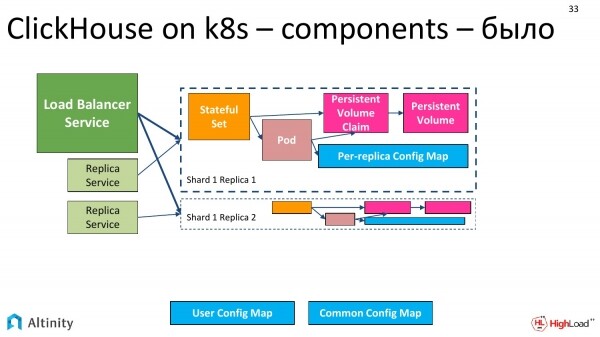
Der Betreiber hat nachgedacht und die folgenden Entitäten erstellt. Wir haben bereits zwei Pods, drei Services und plötzlich zwei StatefulSets. Warum zwei StatefulSets?
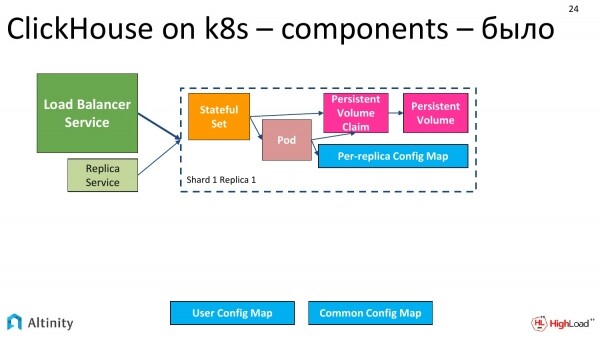
So sah das Diagramm aus – das war unser ursprünglicher Zustand, als wir nur einen Pod hatten.
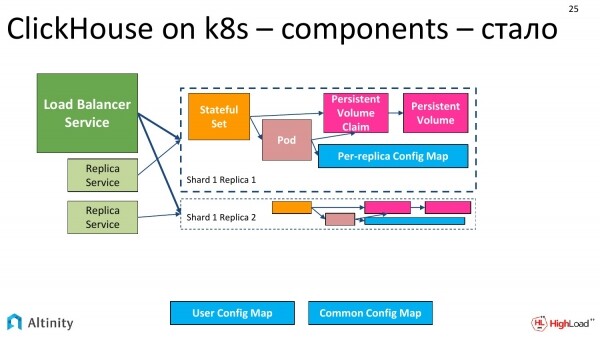
Nun sieht es so aus. Bisher ist alles einfach, es hat sich einfach verdoppelt.
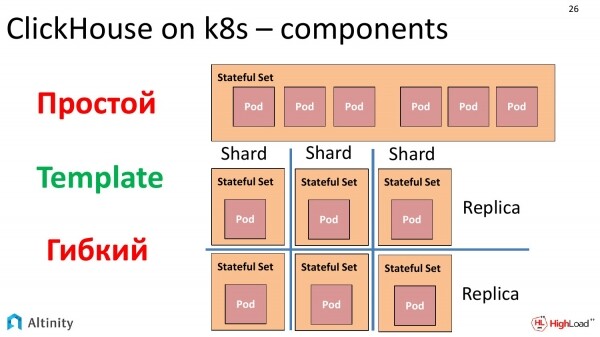
Und warum gibt es jetzt zwei StatefulSets? Hier müssen wir einen Moment innehalten und besprechen, wie in Kubernetes die Pods verwaltet werden.
Es gibt ein Objekt namens StatefulSet, das es ermöglicht, eine Gruppe von Pods aus einer Vorlage zu erstellen. Der entscheidende Faktor hier ist das Template. In einem einzigen StatefulSet können mehrere Pods aus derselben Vorlage gestartet werden. Der zentrale Satz hier ist 'viele Pods aus einer Vorlage'.
Es gab einen großen Anreiz, den gesamten Cluster in einem einzigen StatefulSet zu verpacken. Das wird funktionieren, da gibt es keine Probleme. Aber es gibt einen Haken. Wenn wir einen heterogenen Cluster aufbauen wollen, d.h. aus mehreren Versionen von ClickHouse, beginnen die Probleme. Ja, ein StatefulSet kann ein Rolling Update durchführen, ja, dort können neue Versionen implementiert werden, und es muss erklärt werden, dass nicht mehr als eine bestimmte Anzahl von Nodes gleichzeitig aktualisiert werden sollte.
Wenn wir die Aufgabe extrapolieren und sagen, dass wir einen vollständig heterogenen Cluster erstellen möchten, und dabei nicht von einer alten Version auf eine neue mittels eines Rolling Updates wechseln wollen, sondern einfach einen heterogenen Cluster mit verschiedenen ClickHouse-Versionen und unterschiedlichen Speicherarten aufbauen möchten, können wir beispielsweise einige Replikate auf separaten, langsameren Disks erstellen. Wir wollen einen komplett heterogenen Cluster aufbauen. Da StatefulSet jedoch eine standardisierte Lösung aus einer Vorlage erstellt, haben wir keinen Spielraum für diese Konstruktion.
Nach einigem Überlegen haben wir beschlossen, es auf diese Weise zu tun. Jedes unserer Replikate hat sein eigenes StatefulSet. Dieses Vorgehen hat einige Nachteile, aber in der Praxis kapselt es alles vollständig durch den Operator. Darüber hinaus gibt es zahlreiche Vorteile. Wir können den Cluster genau so gestalten, wie wir ihn möchten, zum Beispiel völlig heterogen. Daher werden wir in dem Cluster, der zwei Shards mit jeweils einer Replikat hat, zwei StatefulSets und zwei Pods haben, und zwar aus den zuvor genannten Gründen, um einen heterogenen Cluster zu ermöglichen.

Kommen wir zu praktischen Aufgaben. In unserem Cluster müssen wir die Benutzer einrichten, d.h. wir müssen einige Konfigurationen für ClickHouse in Kubernetes vornehmen. Der Operator bietet dafür alle Möglichkeiten.

Wir können direkt im YAML schreiben, was wir möchten. Alle Konfigurationsoptionen werden direkt aus diesem YAML in die ClickHouse-Konfigurationen abgebildet, die dann im gesamten Cluster verteilt werden.
Man kann auch so schreiben. Das ist nur ein Beispiel. Das Passwort kann verschlüsselt werden. Es werden alle Konfigurationsoptionen von ClickHouse unterstützt. Hier ist nur ein Beispiel.
Die Clusterkonfiguration wird als ConfigMap verteilt. In der Praxis erfolgt das Update der ConfigMap nicht sofort, daher dauert der Prozess der Konfigurationseinführung bei großen Clustern eine gewisse Zeit. Aber es ist sehr praktisch in der Anwendung.

Wir machen die Aufgabe komplexer. Der Cluster entwickelt sich weiter. Wir möchten Daten replizieren. D.h. wir haben bereits zwei Shards mit je einem Replica, die Benutzer sind eingerichtet. Wir wachsen und möchten uns mit der Replikation beschäftigen.

Was benötigen wir für die Replikation?
Wir benötigen ZooKeeper. In ClickHouse wird die Replikation unter Verwendung von ZooKeeper aufgebaut. ZooKeeper ist erforderlich, damit verschiedene ClickHouse-Replikate einen Konsens darüber haben, welche Datenblöcke in welchem ClickHouse vorhanden sind.
Es kann jeder ZooKeeper verwendet werden. Wenn das Unternehmen einen externen ZooKeeper hat, kann dieser genutzt werden. Ansonsten kann einer aus unserem Repository installiert werden. Es gibt einen Installer, der alles vereinfacht.
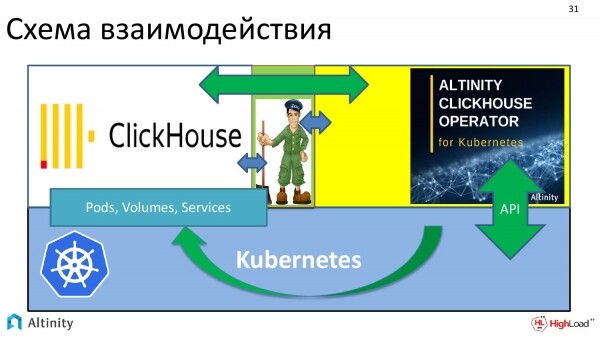
Das Systeminteraktionsschema sieht folgendermaßen aus. Wir haben Kubernetes als Plattform. Darauf läuft der ClickHouse-Operator. ZooKeeper habe ich hier skizziert. Der Operator interagiert sowohl mit ClickHouse als auch mit ZooKeeper. Das bedeutet, es findet eine Interaktion statt.
All dies ist notwendig, damit ClickHouse erfolgreich Daten in k8s repliziert.

Schauen wir uns jetzt die eigentliche Aufgabe an, wie das Manifest für die Replikation aussehen wird.
Wir fügen unserem Manifest zwei Abschnitte hinzu. Der erste ist, wo wir ZooKeeper beziehen, der sowohl innerhalb von Kubernetes als auch extern sein kann. Das ist einfach eine Beschreibung. Und wir bestellen Replikate. Das heißt, wir möchten zwei Replikate. In der Summe sollten wir 4 Pods erhalten. An den Speicher erinnern wir uns, er wird etwas später zurückkommen. Speicher - das ist eine eigene Geschichte.
Es war so.
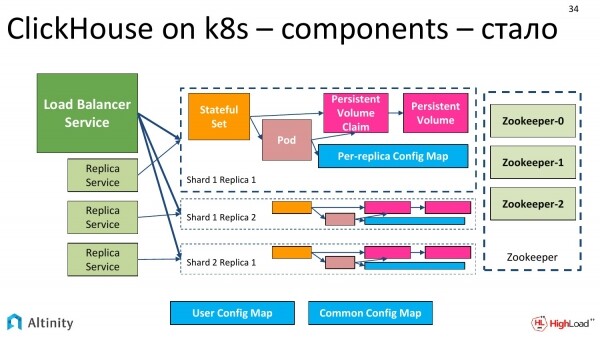
Es wird so. Replica werden hinzugefügt. Die vierte passte nicht rein, aber wir glauben, dass es dort viele geben könnte. Und daneben wird ZooKeeper hinzugefügt. Die Diagramme werden komplexer.

Jetzt ist es an der Zeit, die nächste Aufgabe hinzuzufügen. Wir werden Persistent Storage hinzufügen.
 Für den Persistent Storage haben wir verschiedene Ausführungsvarianten.
Für den Persistent Storage haben wir verschiedene Ausführungsvarianten.
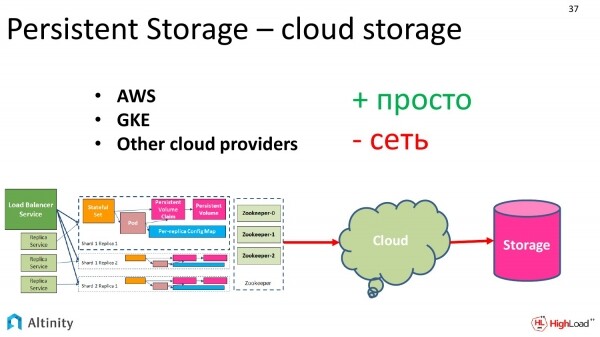
Wenn wir in einem Cloud-Anbieter ausgeführt werden, beispielsweise mit Amazon oder Google, gibt es eine große Versuchung, Cloud-Speicher zu nutzen. Das ist sehr praktisch und gut.
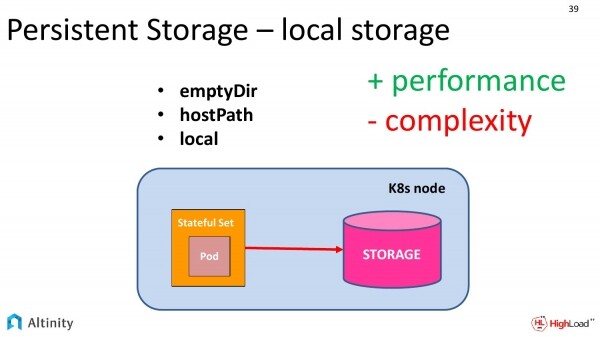
Es gibt eine zweite Option. Das ist für den lokalen Speicher, wenn wir lokale Festplatten in jedem Node haben. Diese Option ist viel komplizierter umzusetzen, bietet aber dafür eine höhere Leistung.
Lassen Sie uns ansehen, was wir in Bezug auf Cloud-Speicher haben.
Es gibt Vorteile. Es ist sehr einfach zu konfigurieren. Wir bestellen einfach bei dem Cloud-Anbieter, geben ihm die Bitte, uns Speicher mit bestimmter Kapazität und Klasse zur Verfügung zu stellen. Die Klassen werden von den Anbietern selbst festgelegt.
Es gibt jedoch auch einen Nachteil. Für manche ist das kein kritischer Nachteil. Natürlich können dort einige Leistungseinbußen auftreten. Es ist sehr bequem im Betrieb, zuverlässig, aber es gibt potenzielle Leistungseinbußen.

Da ClickHouse besonders auf Leistung ausgelegt ist, könnte man sogar sagen, dass es alles herausholt, was möglich ist. Daher versuchen viele Kunden, die maximal mögliche Leistung herauszuholen.
Um das Maximum herauszuholen, benötigen wir lokalen Speicher.
Kubernetes bietet drei Abstraktionen für die Verwendung von lokalem Speicher in Kubernetes. Diese sind:
- EmptyDir
- HostPath.
- Lokal
Schauen wir uns an, wie sie sich unterscheiden und was sie gemeinsam haben.
Zunächst einmal haben wir in allen drei Ansätzen Speicher – das sind lokale Festplatten, die sich auf demselben physikalischen K8s-Knoten befinden. Aber es gibt einige Unterschiede.
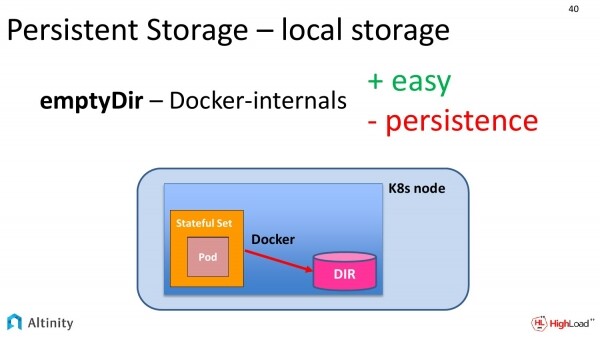
Beginnen wir mit dem einfachsten, d.h. mit emptyDir. Was ist das praktisch? Hierbei bitten wir in unserer Spezifikation das Containerisierungssystem (meistens Docker), uns Zugriff auf einen Ordner auf der lokalen Festplatte zu gewähren.
In der Praxis erstellt Docker irgendwo intern einen temporären Ordner, nennt ihn mit einem langen Hash und gewährt Zugriff auf ihn.
Wie wird das hinsichtlich der Leistung funktionieren? Es wird mit der Geschwindigkeit der lokalen Festplatte arbeiten, d.h. es gibt vollen Zugriff auf die eigene Festplatte.
Allerdings hat diese Lösung einen Nachteil. Persistent ist in diesem Fall ziemlich fragwürdig. Bei der ersten Bewegung von Docker mit Containern geht Persistent verloren. Wenn Kubernetes aus irgendeinem Grund dieses Pod auf eine andere Festplatte verschieben möchte, gehen die Daten verloren.
Dieser Ansatz eignet sich gut für Tests, da er bereits eine akzeptable Geschwindigkeit zeigt, jedoch ist diese Option für etwas Ernsthaftes nicht geeignet.
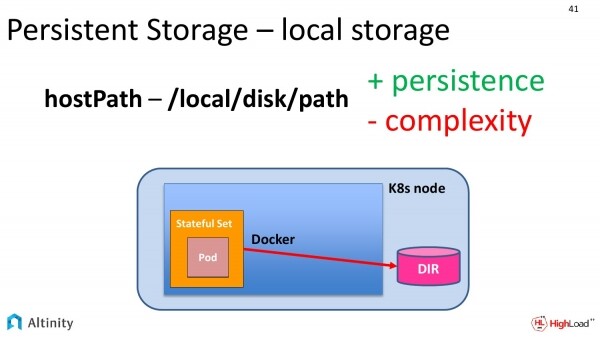
Daher gibt es einen zweiten Ansatz: hostPath. Wenn wir die vorherige Folie und diese betrachten, sehen wir nur einen Unterschied. Der Ordner ist direkt von Docker auf den Kubernetes-Knoten verschoben. Hier ist es etwas einfacher. Wir geben direkt den Pfad im lokalen Dateisystem an, wo wir unsere Daten speichern möchten.
Dieser Ansatz hat seine Vorteile. Es handelt sich bereits um ein echtes Persistent, und zwar das klassische. Unsere Daten werden an einer bestimmten Adresse auf der Festplatte gespeichert.
Es gibt auch Nachteile. Dazu gehört die Komplexität der Verwaltung. Unser Kubernetes könnte Pods auf einen anderen physischen Knoten verschieben wollen. Hier kommt DevOps ins Spiel. Er muss dem gesamten System klar machen, dass diese Pods nur auf Knoten verschoben werden können, auf denen du über diese Pfade etwas montiert hast, und nicht mehr als einen Knoten auf einmal. Das ist ziemlich kompliziert.
Speziell für diese Zwecke haben wir in unserem Unternehmen Vorlagen erstellt, um diese Komplexität zu verbergen. So könnte man einfach sagen: "Ich möchte, dass auf jedem physischen Knoten ein ClickHouse-Instanz und auf diesem bestimmten Pfad besteht."
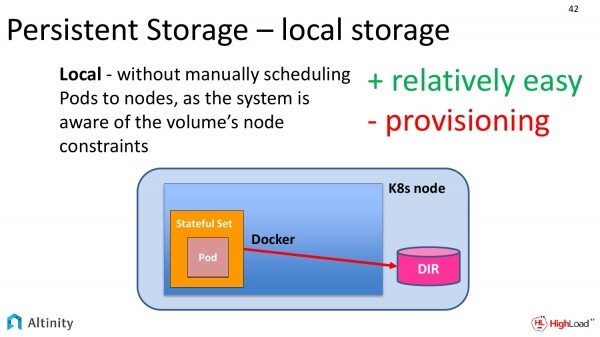
Aber dieses Bedürfnis haben nicht nur wir, daher verstehen die Herren von Kubernetes auch, dass die Menschen Zugriff auf physische Datenträger wünschen, weshalb sie eine dritte Ebene bieten.
Es wird lokal genannt. Der Unterschied zum vorherigen Slide ist praktisch keiner. Eher musste man früher manuell eingreifen, da wir diese Pods nicht von Knoten zu Knoten verschieben konnten, weil sie auf einem bestimmten Pfad mit der lokalen physikalischen Festplatte verbunden sein mussten. Jetzt sind all dieses Wissen im Kubernetes selbst inkapsuliert. So wird die Konfiguration viel einfacher.

Wenden wir uns nun unserer praktischen Aufgabe zu. Wir kehren zum YAML-Template zurück. Hier haben wir echten Storage. Wir sind zu diesem Thema zurückgekehrt. Wir definieren das klassische VolumeClaim-Template wie in k8s und beschreiben, welchen Storage wir benötigen.
Nach diesem Schritt wird k8s Storage anfordern und es uns im StatefulSet zuweisen. Am Ende steht es ClickHouse zur Verfügung.
Wir hatten so ein Schema. Unser Persistent Storage war rot, was andeutete, dass wir es verbessern sollten.
Und er wird grün. Jetzt ist das Schema des ClickHouse-Clusters auf k8s vollständig finalisiert. Wir haben Shards, Replikate, ZooKeeper und es gibt echten Persistent Storage, der auf die eine oder andere Weise implementiert ist. Das Schema ist bereits vollständig funktionsfähig.

Wir leben weiter. Unser Cluster entwickelt sich. Und Alexey gibt sich Mühe und bringt eine neue Version von ClickHouse heraus.
Wir stehen vor einer praktischen Herausforderung: Die neue Version von ClickHouse auf unserem Cluster zu testen. Natürlich möchten wir nicht das gesamte Cluster darauf aktualisieren, sondern irgendwo in einer Ecke eine einzelne Replik mit der neuen Version versehen, und vielleicht sogar mit zwei neuen Versionen gleichzeitig, da diese recht häufig veröffentlicht werden.
Was können wir dazu sagen?

Hier haben wir genau diese Möglichkeit. Es handelt sich um Pod-Vorlagen. Unser Operator ermöglicht es uns, einen heterogenen Cluster aufzubauen. Das heißt, wir können konfigurieren, angefangen bei einer Gruppe aller Replikate bis hin zu jeder einzelnen Replik, welche Version von ClickHouse und welche Storage-Version wir möchten. Wir können den Cluster nach unseren Bedürfnissen vollständig konfigurieren.

Ein wenig werden wir jetzt tiefer einsteigen. Zuvor haben wir darüber gesprochen, wie der ClickHouse-Operator im Kontext von ClickHouse funktioniert.
Jetzt möchte ich ein paar Worte dazu sagen, wie generell jeder Operator funktioniert und wie er mit K8s interagiert.
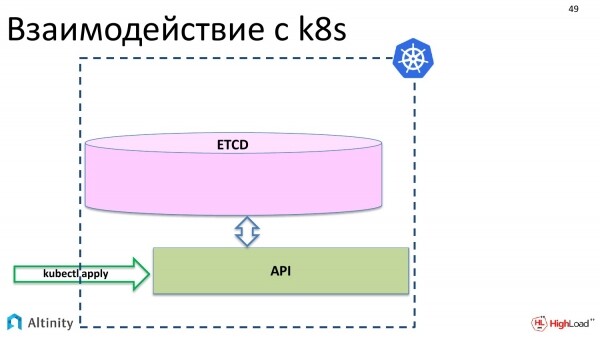
Lassen Sie uns zunächst die Interaktion mit K8s betrachten. Was passiert, wenn wir kubectl apply ausführen? Unsere Objekte erscheinen über die API in etcd.
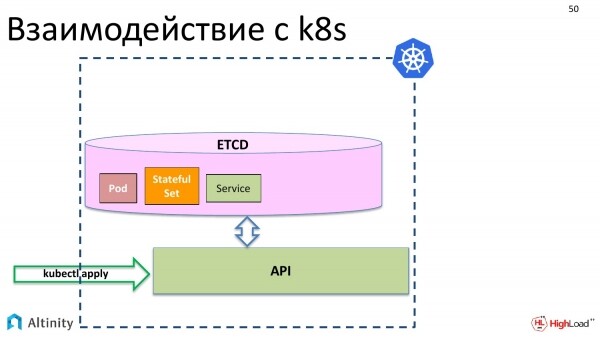
Beispielsweise die grundlegenden Objekte von Kubernetes: Pod, StatefulSet, Service und so weiter.
Zunächst passiert jedoch nichts Physisches. Diese Objekte müssen im Cluster materialisiert werden.
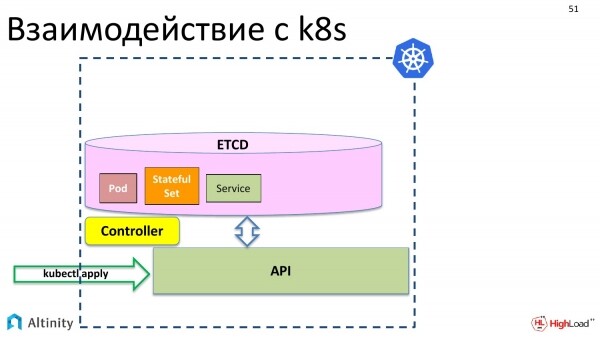
Dafür kommt der Controller ins Spiel. Der Controller ist eine spezielle Komponente von k8s, die diese Beschreibungen materialisieren kann. Er weiß, was physisch getan werden muss. Er weiß, wie Container gestartet werden und was konfiguriert werden muss, damit der Server läuft.
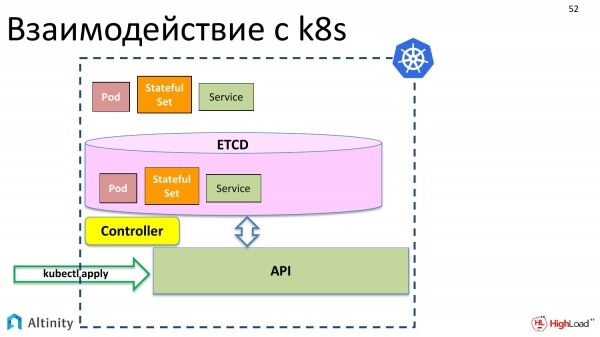
Und er materialisiert unsere Objekte in K8s.
Aber wir möchten nicht nur mit Pods und StatefulSets arbeiten, wir wollen eine ClickHouseInstallation erstellen, d. h. ein Objekt vom Typ ClickHouse, um es als Einheit zu verwalten. Momentan gibt es dafür jedoch keine Möglichkeit.
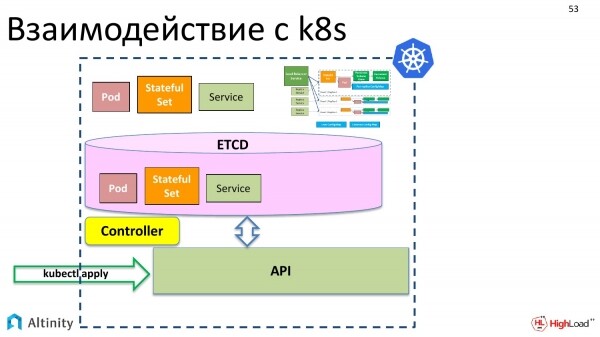
Aber k8s hat noch eine weitere nützliche Funktion. Wir möchten, dass wir irgendwo eine komplexe Entität haben, die aus Pods und StatefulSets unseren Cluster zusammenstellt.
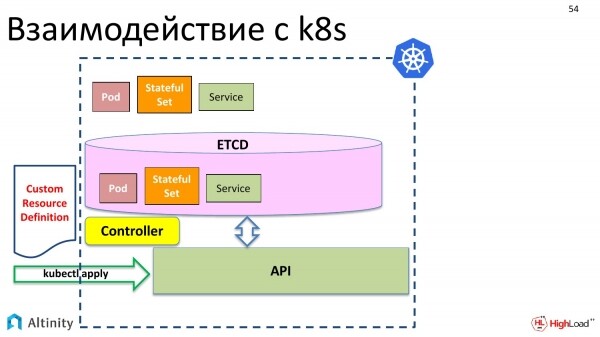
Was müssen wir dafür tun? Zunächst tritt die Custom Resource Definition auf den Plan. Was ist das? Es ist eine Beschreibung für k8s, dass es einen weiteren Datentyp geben wird, dass wir zu Pods und StatefulSets ein benutzerdefiniertes Ressourcen hinzufügen möchten, das komplexe Informationen enthält. Das ist die Beschreibung der Datenstruktur.
Wir senden ihn ebenfalls über kubectl apply dorthin. Kubernetes hat ihn begeistert übernommen.
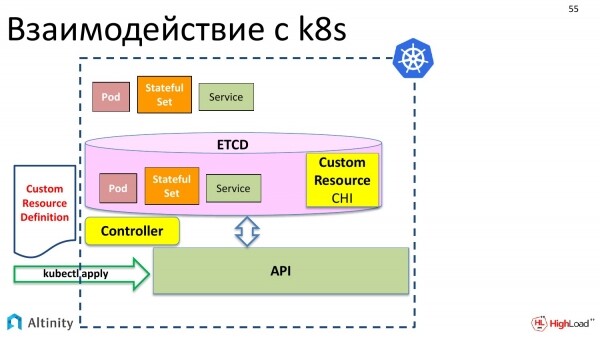
Jetzt haben wir im Speicher die Möglichkeit, ein benutzerdefiniertes Objekt mit dem Namen ClickHouseInstallation in etcd zu hinterlegen.
Aber bis jetzt wird nichts weiter geschehen. Das heißt, wenn wir jetzt eine YAML-Datei erstellen, die wir mit der Beschreibung von Shards, Replikaten usw. betrachtet haben, und sagen „kubectl apply“, dann wird Kubernetes sie akzeptieren, in etcd ablegen und sagen: „Gut, aber ich weiß nicht, was ich damit machen soll. Ich weiß nicht, wie ich ClickHouseInstallation verwalten soll.“
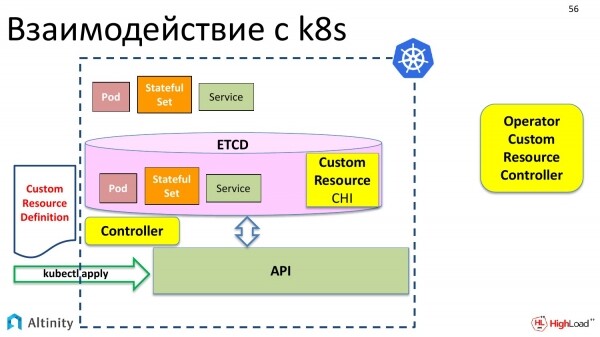
Deshalb brauchen wir jemanden, der Kubernetes hilft, diesen neuen Datentyp zu verwalten. Links haben wir den integrierten Kubernetes-Controller, der mit den Standard-Datentypen arbeitet. Rechts sollte ein benutzerdefinierter Controller erscheinen, der mit benutzerdefinierten Datentypen arbeiten kann.
Und anders genannt wird er Operator. Ich habe ihn hier absichtlich außerhalb von Kubernetes dargestellt, weil er auch außerhalb von K8s betrieben werden kann. In der Regel werden die meisten Operatoren natürlich innerhalb von Kubernetes ausgeführt, aber nichts hindert ihn daran, draußen zu stehen, weshalb er hier speziell nach außen gerückt ist.
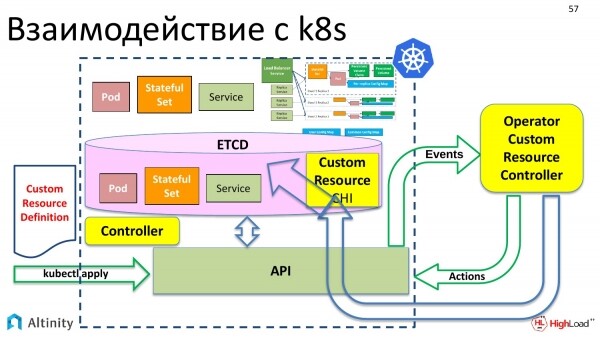
Der benutzerdefinierte Controller, auch Operator genannt, interagiert über die API mit Kubernetes. Er kann bereits mit der API kommunizieren und weiß, wie er aus einer benutzerdefinierten Ressource ein komplexes Schema erstellen kann, das wir anstreben. Genau das ist die Aufgabe des Operators.
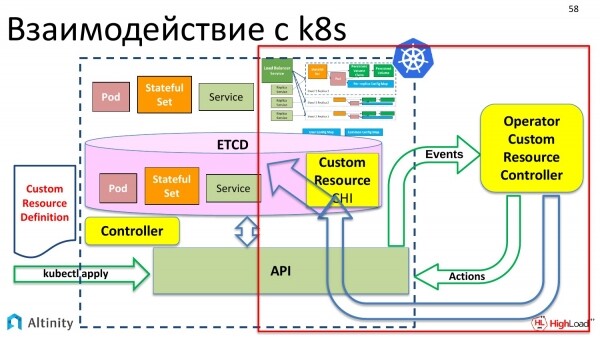
Wie funktioniert der Operator? Werfen wir einen Blick auf die rechte Seite, um zu erfahren, wie er das macht. Lassen Sie uns entdecken, wie der Operator alles materialisiert und wie die Interaktion mit K8s anschließend verläuft.
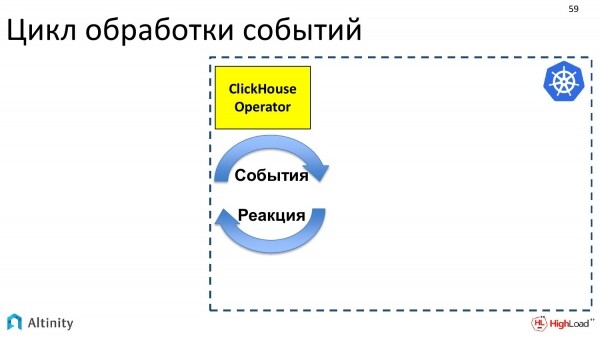
Der Operator ist ein Programm, das ereignisorientiert arbeitet. Mithilfe der Kubernetes API abonniert der Operator Ereignisse. In der Kubernetes API gibt es Einstiegspunkte, an denen man sich auf Ereignisse abonnieren kann. Wenn sich etwas in K8s ändert, sendet Kubernetes Ereignisse an alle Abonnenten, d.h. jeder, der auf diesen API-Punkt abonniert ist, erhält Benachrichtigungen.
Der Operator abonniert Ereignisse und muss darauf reagieren. Seine Aufgabe besteht darin, auf die auftretenden Ereignisse zu reagieren.
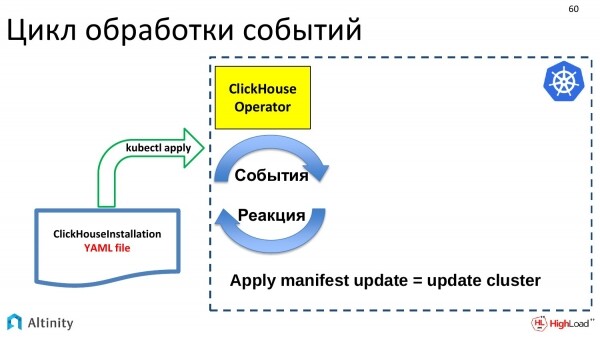
Ereignisse werden durch bestimmte Updates generiert. Unser YAML-Dokument mit der Beschreibung ClickHouseInstallation wird über kubectl apply in etcd übertragen. Dort wird ein Ereignis ausgelöst, das schließlich beim ClickHouse-Operator ankommt. Der Operator erhält diese Beschreibung und muss entsprechend handeln. Wenn ein Update für das Objekt ClickHouseInstallation kommt, ist es seine Aufgabe, das Cluster zu aktualisieren.
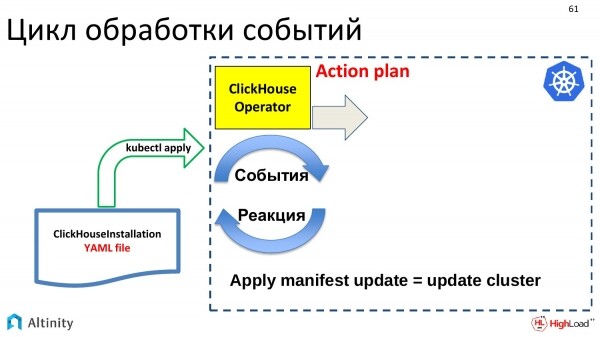
Was macht er? Zunächst einmal muss ein Aktionsplan erstellt werden, was wir mit diesem Update tun werden. Updates können sehr klein sein, d.h. in YAML geringfügig, aber sie können erhebliche Änderungen im Cluster nach sich ziehen. Daher erstellt der Operator einen Plan und hält sich dann daran.
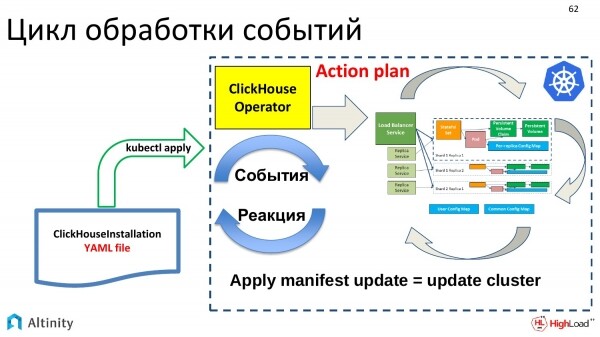
Er beginnt gemäß diesem Plan, die Struktur intern zu entwickeln, um Pods und Dienste zu materialisieren, d.h. das zu tun, was seine Hauptaufgabe ist. Es ist wie der Aufbau eines ClickHouse-Clusters in Kubernetes.
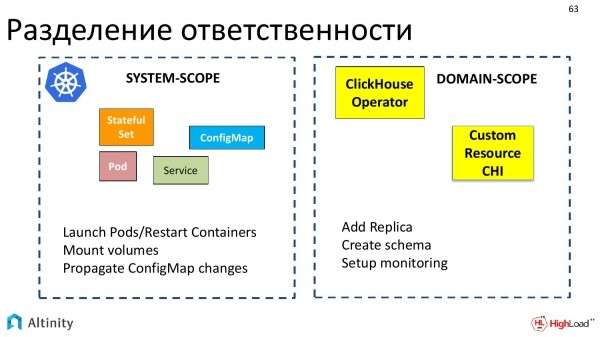
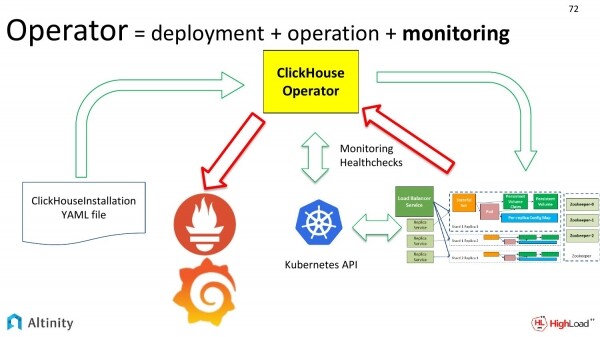
Nun lassen Sie uns auf eine interessante Sache eingehen. Es handelt sich um die Aufteilung der Verantwortung zwischen Kubernetes und dem Operator, d.h. was Kubernetes tut, was der Operator tut und wie sie miteinander interagieren.
Kubernetes kümmert sich um systemrelevante Aufgaben, also um den grundlegenden Satz von Objekten, die als systemisch interpretiert werden können. Kubernetes weiß, wie man Pods startet, Container neustartet, Volumes einbindet und mit ConfigMaps umgeht – alles, was man als systemisch bezeichnen kann.
Operatoren agieren in spezifischen Anwendungsbereichen. Jeder Operator wird für seinen spezifischen Anwendungsbereich erstellt. Wir haben einen für ClickHouse entwickelt.
Der Operator interagiert genau in den Begriffen des Anwendungsbereichs, wie zum Beispiel eine Replik hinzufügen, ein Schema erstellen oder Monitoring einrichten. So entsteht eine klare Trennung.

Betrachten wir ein praktisches Beispiel, wie diese Trennung von Verantwortlichkeiten stattfindet, wenn wir die Aktion „Replik hinzufügen“ ausführen.
Der Operator erhält die Aufgabe – eine Replik hinzuzufügen. Was macht der Operator? Der Operator berechnet, dass ein neues StatefulSet erstellt werden muss, in dem bestimmte Vorlagen und Volume-Claims beschrieben sind.

Er bereitet alles vor und leitet es an K8s weiter. Er erklärt, dass er eine ConfigMap, ein StatefulSet und ein Volume benötigt. Kubernetes führt dann die erforderlichen Schritte aus. Es materialisiert die grundlegenden Einheiten, mit denen es arbeitet.
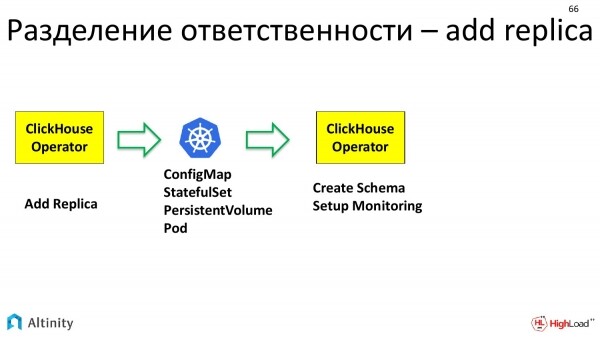
Und hier kommt erneut der ClickHouse-Operator ins Spiel. Er verfügt bereits über ein physisches Pod, auf dem etwas durchgeführt werden kann. Der ClickHouse-Operator arbeitet erneut in Fachbegriffen. Das heißt, um eine Replik in den Cluster einzufügen, muss zunächst das Datenschema, das in diesem Cluster vorhanden ist, konfiguriert werden. Zweitens muss diese Replik in die Überwachung aufgenommen werden, damit sie gut nachvollziehbar ist. Das richtet bereits der Operator ein.
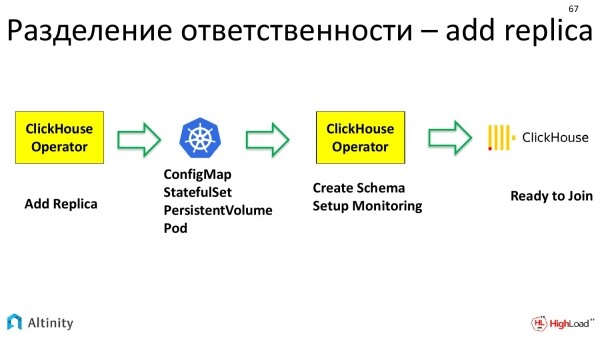
Erst danach kommt der ClickHouse selbst ins Spiel, also eine weitere hochrangige Entität. Das ist die Datenbank. Sie hat ihre eigene Instanz und eine konfigurierte Replik, die bereit ist, in den Cluster aufgenommen zu werden.
Das ergibt eine lange Kette von Ausführungen und eine Verantwortungsteilung bei der Hinzufügung einer Replik.

Wir setzen unsere praktischen Aufgaben fort. Wenn der Cluster bereits besteht, kann die Konfiguration migriert werden.

Wir haben es so eingerichtet, dass bestehende XML, das ClickHouse versteht, nahtlos durchgereicht werden kann.

Es ist möglich, ClickHouse fein abzustimmen. Wie gerade gesagt, ist zoned deployment genau das, worüber ich bei der Erklärung von hostPath und Local Storage gesprochen habe. Es geht darum, zoned deployment richtig umzusetzen.

Die nächste praktische Aufgabe ist das Monitoring.
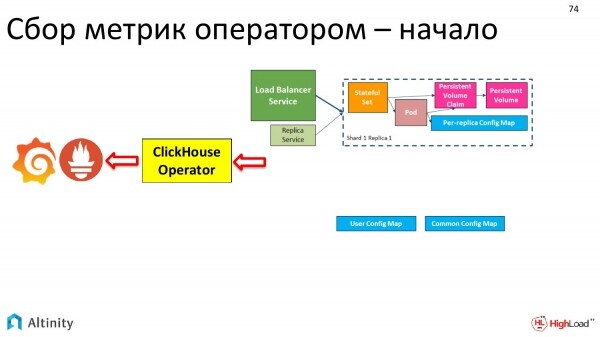
Wenn sich unser Cluster ändert, muss das Monitoring regelmäßig angepasst werden.
Lassen Sie uns das Schema betrachten. Die grünen Pfeile haben wir bereits besprochen. Nun sehen wir uns die roten Pfeile an. So möchten wir unser Cluster überwachen. Wie die Metriken aus dem ClickHouse-Cluster in Prometheus und dann in Grafana gelangen.

Was ist die Herausforderung beim Monitoring? Warum wird es als eine Art Errungenschaft bezeichnet? Die Schwierigkeit liegt in der Dynamik. Wenn wir einen statischen Cluster haben, kann das Monitoring einmalig eingerichtet werden und man muss sich nicht weiter darum kümmern.
Aber wenn wir viele Cluster haben oder sich ständig etwas ändert, ist der Prozess dynamisch. Sich ständig um die Neuanpassung des Monitorings zu kümmern, verbraucht Ressourcen und Zeit – einfach gesagt, es ist sogar mühsam. Das muss automatisiert werden. Die Komplexität liegt also in der Dynamik des Prozesses. Und der Operator automatisiert das sehr gut.
Wie hat sich unser Cluster entwickelt? Zu Beginn sah es so aus.
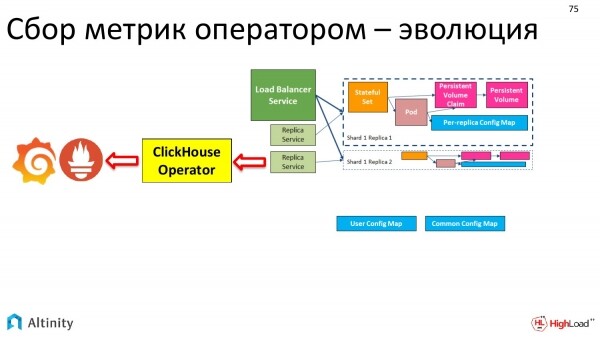
Dann sah es so aus.
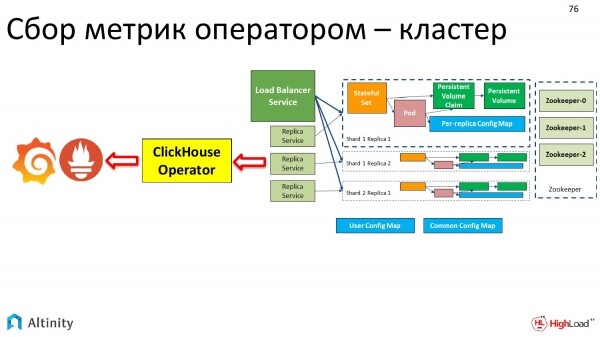
Am Ende hat es sich zu diesem entwickelt.
Das Monitoring wird automatisch vom Operator durchgeführt. Eine zentrale Anlaufstelle.
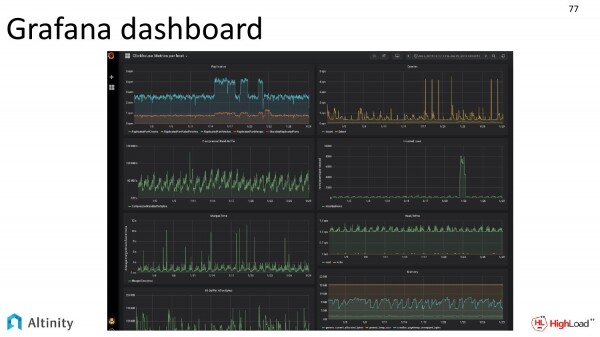
Wir werfen nur einen Blick auf das Grafana-Dashboard, um zu sehen, wie lebhaft das Innenleben unseres Clusters ist.
Übrigens wird das Grafana-Dashboard ebenfalls mit unserem Operator in den Quellcodes bereitgestellt. Man kann es einfach anschließen und nutzen. Dieses Screenshot haben unsere DevOps zur Verfügung gestellt.

Wohin möchten wir als Nächstes gehen? Das ist:
- Die Automatisierung der Testverfahren vorantreiben. Die Hauptaufgabe besteht in der automatisierten Prüfung neuer Versionen.
- Außerdem möchten wir die Integration mit ZooKeeper automatisieren. Geplant ist, sich mit dem ZooKeeper-Operator zu integrieren. Das bedeutet, dass ein Operator für ZooKeeper geschrieben wurde, und es wäre nur logisch, dass zwei Operatoren zur Schaffung einer benutzerfreundlicheren Lösung zusammenarbeiten.
- Wir möchten komplexere Lebenszeichenprüfungen implementieren.
- Ich habe in Grün hervorgehoben, dass wir beim Erben von Templates auf dem richtigen Weg sind – FERTIG, d. h. mit der nächsten Veröffentlichung des Operators wird das Template-Erben verfügbar sein. Dies ist ein leistungsstarkes Werkzeug, das es ermöglicht, komplexe Konfigurationen aus verschiedenen Teilen zusammenzustellen.
- Und wir streben die Automatisierung komplexer Aufgaben an. Eine der Hauptaufgaben ist das Re-Sharding.

Lassen Sie uns eine Zwischenbilanz ziehen.

Was erhalten wir am Ende? Und ist es sinnvoll oder nicht? Sollte man überhaupt versuchen, eine Datenbank in Kubernetes zu integrieren und den Operator insgesamt sowie den Alitnity-Operator im Besonderen anzuwenden?
Am Ende erhalten wir:
- Eine signifikante Vereinfachung und Automatisierung der Konfiguration, Bereitstellung und Wartung.
- Sofort integriertes Monitoring.
- Und sofort einsatzbereite, kodifizierte Vorlagen für komplexe Situationen. Aktionen wie das Hinzufügen einer Replik sind nicht mehr manuell erforderlich. Das übernimmt der Operator.

Bleibt nur noch die letzte Frage. Wir haben bereits eine Datenbank in Kubernetes, Virtualisierung. Wie steht es um die Leistung dieser Lösung, insbesondere in Anbetracht der Tatsache, dass ClickHouse auf Leistung optimiert ist?
Die Antwort – alles in Ordnung! Ich werde nicht ins Detail gehen, das ist ein Thema für einen separaten Vortrag.

Aber es gibt ein Projekt namens TSBS. Was ist sein Hauptziel? Es ist ein Test für Datenbanken auf Leistung. Es versucht, Äpfel mit Äpfeln und Birnen mit Birnen zu vergleichen.
Wie funktioniert es? Es wird ein Datensatz generiert. Dieser Datensatz wird dann mit dem gleichen Test-Set auf verschiedenen Datenbanken durchlaufen. Jede Datenbank löst eine Aufgabe auf ihre eigene Weise. Anschließend können die Ergebnisse verglichen werden.
Es unterstützt bereits eine Vielzahl von Datenbanken. Ich habe drei Hauptdatenbanken hervorgehoben. Diese sind:
- TimescaleDB.
- InfluxDB.
- ClickHouse.
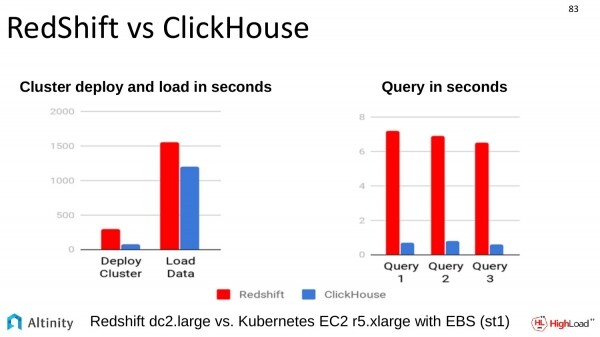
Es wurde auch ein Vergleich mit einer ähnlichen Lösung durchgeführt, und zwar mit RedShift. Der Vergleich fand bei Amazon statt. ClickHouse übertrifft auch in dieser Hinsicht alle anderen.

Welche Schlussfolgerungen kann ich aus dem, was ich erzählt habe, ziehen?
- DB in Kubernetes ist möglich. Wahrscheinlich kann man jede Datenbank verwenden, aber insgesamt sieht es so aus, als wäre es machbar. ClickHouse kann definitiv im Kubernetes-Umfeld unseres Operators betrieben werden.
- Der Operator hilft dabei, Prozesse zu automatisieren und vereinfacht das Leben erheblich.
- Die Leistung ist angemessen.
- Und wir glauben, dass es sinnvoll ist, dies zu verwenden.
Open Source – schließen Sie sich uns an!
Wie bereits erwähnt, ist der Operator ein vollständig Open-Source-Produkt, daher wäre es großartig, wenn möglichst viele Menschen ihn nutzen würden. Schließen Sie sich uns an! Wir freuen uns auf Sie alle!
Vielen Dank an alle!
Fragen

Vielen Dank für den Vortrag! Ich heiße Anton und komme von SEMrush. Mich interessiert das Thema Logging. Über Monitoring hört man viel, aber über Logging, wenn man den gesamten Cluster betrachtet, nicht so viel. Bei uns zum Beispiel haben wir einen Cluster auf Hardware hochgezogen. Wir nutzen zentrales Logging und sammeln die Daten mit Standardmitteln in einem gemeinsamen Repository. Von dort aus extrahieren wir die für uns interessanten Daten.
Eine gute Frage, das heißt, Logging steht auf der To-Do-Liste. Unser Operator automatisiert das derzeit noch nicht. Das Projekt entwickelt sich noch, es ist noch recht jung. Wir erkennen die Notwendigkeit des Loggings. Dies ist ebenfalls ein sehr wichtiges Thema, das wahrscheinlich nicht weniger wichtig ist als Monitoring. Aber zuallererst stand Monitoring auf der Implementierungsliste. Logging wird kommen. Wir versuchen natürlich, alle Aspekte der Betriebsführung des Clusters zu automatisieren. Daher ist die Antwort: Leider kann der Operator dies aktuell nicht, aber es steht auf unserer Liste, wir werden das umsetzen. Wenn Sie Interesse haben, sich anzuschließen, dann senden Sie bitte einen Pull Request.
Hallo! Vielen Dank für den Bericht! Ich habe eine Standardfrage zu den Persistent Volumes. Wie bestimmt der Operator, auf welchem Knoten ein bestimmtes Laufwerk oder ein Verzeichnis gemountet ist, wenn wir mit diesem Operator eine Konfiguration erstellen? Müssen wir ihm im Voraus erklären, dass unser ClickHouse bitte auf den Knoten platziert werden soll, auf denen sich das Laufwerk befindet?
Soweit ich das verstehe, ist diese Frage eine Fortsetzung des lokalen Speichers, insbesondere des Teils über hostPath. Es geht darum, dem gesamten System zu erklären, dass der Pod genau auf diesem Knoten ausgeführt werden soll, auf dem wir ein physisch verbundenes Laufwerk haben, das an einem bestimmten Pfad gemountet ist. Das ist ein ganzes Thema, das ich nur sehr oberflächlich angeschnitten habe, da die Antwort recht umfangreich ist.
Kurz gesagt, das sieht so aus: Wir müssen natürlich die Bereitstellung dieser Volumes vornehmen. Momentan gibt es im lokalen Speicher keine dynamische Bereitstellung, daher müssen die DevOps die Festplatten, also diese Volumes, manuell partitionieren. Sie müssen Kubernetes erklären, dass es Persistent Volumes einer bestimmten Klasse geben wird, die sich auf bestimmten Knoten befinden. Anschließend muss Kubernetes erklärt werden, dass Pods, die eine bestimmte Klasse von lokalem Speicher benötigen, nur auf solchen Knoten geplant werden sollen. Für diese Zwecke ermöglicht der Operator, einen bestimmten Label und eine Instanz pro Host zuzuweisen. Dadurch werden die Pods von Kubernetes nur auf Knoten gestartet, die den Anforderungen der Labels entsprechen, einfach gesagt. Die Administratoren weisen Labels zu und führen die Bereitstellung der Festplatten manuell durch. So wird die Skalierung ermöglicht.
Der dritte Ansatz mit lokalem Speicher erleichtert dies ein wenig. Wie ich bereits betont habe, ist es eine mühsame Aufgabe, die jedoch letztendlich dazu beiträgt, die maximale Leistung zu erzielen.
Ich habe eine zweite Frage dazu. Kubernetes wurde so konzipiert, dass es uns egal ist, ob wir einen Knoten verlieren oder nicht. Was sollten wir in diesem Fall tun, wenn wir den Knoten verloren haben, auf dem unser Shard läuft?
Ja, Kubernetes wurde ursprünglich so positioniert, dass unsere Pods wie Vieh behandelt werden, aber hier wird jede Festplatte wie ein Haustier betrachtet. Es gibt das Problem, dass wir diese nicht einfach wegwerfen können. Die Entwicklung von Kubernetes geht dahin, dass wir nicht vollständig philosophisch damit umgehen können, als wären es Ressourcen, die wir jederzeit entsorgen können.
Nun zur praktischen Frage. Was tun, wenn ein Knoten verloren geht, auf dem die Festplatte war? Hier wird die Aufgabe auf einer höheren Ebene gelöst. Bei ClickHouse haben wir Replikate, die auf einer höheren Ebene arbeiten, also auf der Ebene von ClickHouse.
Wie sieht dieDisposition aus? DevOps ist dafür verantwortlich, dass keine Daten verloren gehen. Er muss die Replikation richtig einstellen und darauf achten, dass die Replikation erfolgt. In der Replikation auf der Ebene von ClickHouse sollten die Daten dupliziert sein. Das ist nicht die Aufgabe des Betreibers. Und nicht die Aufgabe, die Kubernetes selbst löst. Das geschieht auf der Ebene von ClickHouse.
Was tun, wenn Ihr Hardware-Knoten ausfällt? In diesem Fall müssen Sie einen zweiten Knoten aufbauen, richtig die Festplatte provisionieren und Labels anbringen. Danach erfüllt dieser Knoten die Anforderungen, sodass Kubernetes ein Pod-Instance darauf starten kann. Kubernetes wird ihn starten. Ihnen fehlen ja Pod-Kapazitäten, um die definierte Anzahl zu erreichen. Der Knoten wird den Zyklus durchlaufen, den ich gezeigt habe. Auf der obersten Ebene wird ClickHouse erkennen, dass ein Replikat hinzugefügt wurde, das noch leer ist, und die Daten beginnen müssen, darauf übertragen zu werden. Dieser Prozess ist noch unzureichend automatisiert.
Danke für den Vortrag! Wenn inkonsistente Ereignisse eintreten, der Operator abstürzt und neu gestartet wird, während in diesem Moment Ereignisse eintreffen, wie gehen Sie damit um?
Was passiert, wenn der Operator abgestürzt ist und neu gestartet wurde?
Ja. Und in diesem Moment sind Ereignisse eingetroffen.
Die Aufgabe, was in diesem Fall zu tun ist, wird teilweise zwischen dem Operator und Kubernetes aufgeteilt. Kubernetes hat die Fähigkeit, das aufgetretene Ereignis erneut abzuspielen. Es spielt es erneut ab. Die Aufgabe des Operators besteht jedoch darin, sicherzustellen, dass, wenn das Ereignisprotokoll wiederholt wird, diese Ereignisse idempotent sind. Und dass ein erneutes Eintreten des gleichen Ereignisses unser System nicht stört. Und unser Operator bewältigt diese Aufgabe.
Guten Tag! Vielen Dank für den Vortrag! Dmitry Zavyalov, Unternehmen Smedenova. Ist eine Anpassung des Operators mit haproxy geplant? Gibt es Interesse an einem anderen Load Balancer neben dem Standard, der intelligent ist und erkennt, dass dort tatsächlich ClickHouse läuft.
Sprechen Sie von Ingress?
Ja, Ingress durch haproxy ersetzen. In haproxy kann die Cluster-Topologie angegeben werden, wo sich die Replikate befinden.
Bisher haben wir darüber noch nicht nachgedacht. Wenn Sie es benötigen und erklären können, warum es notwendig ist, könnten wir es umsetzen, insbesondere wenn Sie teilnehmen möchten. Wir würden das gerne in Betracht ziehen. Kurz gesagt – nein, derzeit haben wir diese Funktionalität nicht. Vielen Dank für den Hinweis, wir werden uns damit beschäftigen. Und wenn Sie auch den Anwendungsfall erklären und z.B. Issues auf GitHub erstellen, wäre das großartig.
Ist bereits vorhanden.
Gut. Wir sind offen für alle Vorschläge. Und haproxy wird auf die To-Do-Liste gesetzt. Die To-Do-Liste wächst im Moment, statt sich zu verringern. Aber das ist gut, das zeigt, dass das Produkt nachgefragt wird.
Quelle: habr.com
