

Hallo, Habr! Mein Name ist Maxim Vasiliev, ich arbeite als Analyst und Projektmanager bei FINCH. Heute möchte ich erzählen, wie wir es mit Hilfe von ElasticSearch geschafft haben, 15 Millionen Anfragen in 6 Minuten zu verarbeiten und die täglichen Lasten auf der Website eines unserer Kunden zu optimieren. Leider müssen wir ohne Namen auskommen, da wir eine NDA haben. Wir hoffen, dass der Inhalt des Artikels darunter nicht leidet. Lass uns beginnen.
Wie das Projekt aufgebaut ist
In unserem Backend erstellen wir Dienste, die die Funktionsfähigkeit der Websites und der mobilen Anwendungen unseres Kunden gewährleisten. Die allgemeine Struktur ist in der folgenden Grafik zu sehen:
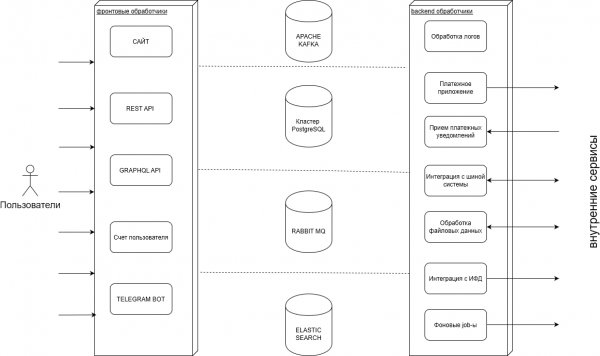
Im Verlauf unserer Arbeit verarbeiten wir eine große Anzahl von Transaktionen: Käufen, Auszahlungen, Operationen mit Benutzerkonten, zu denen wir viele Protokolle speichern, sowie Daten in externe Systeme importieren und exportieren.
Es gibt auch umgekehrte Prozesse, bei denen wir Daten vom Kunden erhalten und an die Benutzer übermitteln. Darüber hinaus gibt es Prozesse, die sich mit Zahlungen und Bonusprogrammen befassen.
Kurze Vorgeschichte
Ursprünglich nutzten wir PostgreSQL als primäres Datenspeicher. Die Standardvorteile von DBMS: Transaktionen, eine ausgefeilte Abfragesprache und ein umfangreiches Integrationswerkzeug; in Verbindung mit einer soliden Leistung erfüllten sie unsere Anforderungen über einen längeren Zeitraum zufriedenstellend.
Wir speicherten in Postgres alle Daten: von Transaktionen bis hin zu Nachrichten. Doch die Anzahl der Benutzer stieg, und damit auch die Menge der Anfragen.
Zum Verständnis: die jährliche Anzahl der Sitzungen im Jahr 2017 nur auf der Desktop-Website betrug 131 Millionen. Im Jahr 2018 waren es 125 Millionen. 2019 erneut 130 Millionen. Fügen Sie noch 100-200 Millionen von der mobilen Version der Website und der mobilen App hinzu, und Sie erhalten eine enorme Anzahl von Anfragen.
Mit dem Wachstum des Projekts konnte Postgres die Last nicht mehr bewältigen, wir kamen nicht hinterher — es gab eine große Vielfalt an Anfragen, für die wir nicht genügend Indizes erstellen konnten.
Wir haben erkannt, dass es notwendig ist, andere Datenspeicher zu haben, die unseren Anforderungen entsprechen und die Belastung von PostgreSQL reduzieren. Als mögliche Optionen haben wir Elasticsearch und MongoDB in Betracht gezogen. Letzteres fiel in den folgenden Punkten zurück:
- Langsame Indizierungsgeschwindigkeit mit zunehmendem Volumen der Indizes. Bei Elastic hängt die Geschwindigkeit nicht vom Datenvolumen ab.
- Kein Volltextsuche.
So haben wir uns für Elastic entschieden und die Vorbereitungen für den Wechsel getroffen.
Wechsel zu Elastic
1. Wir haben den Wechsel mit dem Suchdienst für Verkaufsstellen begonnen. Unser Kunde hat insgesamt etwa 70.000 Verkaufsstellen, und es werden mehrere Suchtypen auf der Website und in der App benötigt:
- Textsuche nach dem Namen des Ortes.
- Geosuche in einem bestimmten Radius von einem Punkt. Zum Beispiel, wenn der Benutzer sehen möchte, welche Verkaufsstellen am nächsten zu seinem Wohnort sind.
- Suche in einem bestimmten Quadrat – der Benutzer umreißt ein Quadrat auf der Karte, und ihm werden alle Verkaufsstellen in diesem Radius angezeigt.
- Suche nach zusätzlichen Filtern. Die Verkaufsstellen unterscheiden sich in ihrem Sortiment.
Wenn es um die Organisation geht, haben wir in Postgres Datenquellen sowohl für Karten als auch für Nachrichten, während in Elastic Schnappschüsse der Originaldaten erstellt werden. Zu Beginn konnte Postgres nicht alle Suchkriterien bewältigen. Abgesehen von der Vielzahl an Indizes konnten sie auch überlappen, weshalb der Planner in Postgres verwirrt war und nicht wusste, welchen Index er verwenden sollte.
2. Der nächste Schritt war der Nachrichtenbereich. Auf der Webseite erscheinen täglich Veröffentlichungen, sodass Benutzer im Informationsfluss nicht verloren gehen. Die Daten müssen vor der Ausgabe sortiert werden. Dafür ist die Suche erforderlich: Auf der Webseite kann nach Textübereinstimmungen gesucht werden, und zusätzlich können weitere Filter aktiviert werden, da diese ebenfalls über Elastic implementiert sind.
3. Dann haben wir die Verarbeitung von Transaktionen verlagert. Benutzer können bestimmte Produkte auf der Webseite kaufen und an Verlosungen teilnehmen. Nach solchen Käufen verarbeiten wir eine große Menge an Daten, insbesondere an Wochenenden und Feiertagen. Zum Vergleich: An normalen Tagen beträgt die Anzahl der Käufe etwa 1,5-2 Millionen, während sie an Feiertagen bis zu 53 Millionen erreichen kann.
Dabei müssen die Daten in minimaler Zeit verarbeitet werden – die Nutzer mögen es nicht, mehrere Tage auf Ergebnisse zu warten. Das lässt sich mit Postgres nicht erreichen – wir haben oft Blockierungen erlebt, und während wir alle Anfragen bearbeitet haben, konnten die Nutzer nicht überprüfen, ob sie Preise erhalten haben oder nicht. Das ist für das Geschäft nicht sehr angenehm, weshalb wir die Verarbeitung nach Elasticsearch verlagert haben.
Häufigkeit
Derzeit sind die Updates ereignisgesteuert und basieren auf folgenden Bedingungen:
- Verkaufspunkte. Sobald wir Daten aus einer externen Quelle erhalten, starten wir umgehend das Update.
- Nachrichten. Sobald eine Nachricht auf der Website bearbeitet wird, wird sie automatisch an Elastic gesendet.
Hier sollte nochmals auf die Vorteile von Elastic hingewiesen werden. Bei Postgres muss man beim Senden einer Anfrage warten, bis alle Datensätze ordnungsgemäß verarbeitet sind. Bei Elastic kann man 10.000 Datensätze senden und sofort mit der Arbeit beginnen, ohne auf die Verteilung der Daten auf alle Shards zu warten. Sicherlich könnte ein Shard oder eine Replica die Daten nicht sofort sehen, aber sehr bald ist alles verfügbar.
Integrationsmethoden
Es gibt 2 Integrationsmethoden mit Elastic:
- Über den nativen TCP-Client. Der native Treiber stirbt allmählich aus: er wird nicht mehr unterstützt und hat eine sehr unhandliche Syntax. Daher verwenden wir ihn praktisch nicht und versuchen, vollständig darauf zu verzichten.
- Über die HTTP-Schnittstelle, die sowohl JSON-Anfragen als auch die Lucene-Syntax verwenden kann. Letzteres ist ein Text-Engine, das von Elastic verwendet wird. In dieser Variante haben wir die Möglichkeit, Batch-Anfragen über JSON über HTTP zu stellen. Genau diese Variante versuchen wir zu nutzen.
Dank der HTTP-Schnittstelle können wir Bibliotheken verwenden, die eine asynchrone Implementierung des HTTP-Clients bieten. Wir können die Vorteile von Batch und der asynchronen API nutzen, was letztendlich eine hohe Leistung ermöglicht, die uns an Tagen großer Aktionen sehr geholfen hat (darüber später mehr).
Ein paar Zahlen zum Vergleich:
- Speicherung von Nutzern, die Preise in Postgres erhalten haben, mit 20 Threads ohne Gruppierung: 460713 Datensätze in 42 Sekunden.
- Elastic + reaktiver Client mit 10 Threads + Batch mit 1000 Elementen: 596749 Datensätze in 11 Sekunden.
- Elastic + reaktiver Client mit 10 Threads + Batch mit 1000 Elementen: 23801684 Datensätze in 4 Minuten.
Jetzt haben wir einen HTTP-Anforderungsmanager geschrieben, der JSON generiert, sowohl im Batch- als auch im Non-Batch-Modus, und über jeden HTTP-Client, unabhängig von der Bibliothek, sendet. Es kann auch ausgewählt werden, ob die Anfragen synchron oder asynchron gesendet werden.
In einigen Integrationen verwenden wir immer noch den offiziellen Transport-Client, aber das ist nur eine Frage der nächsten Refactoring-Phase. Für die Verarbeitung wird jedoch ein eigener Client verwendet, der auf Spring WebClient basiert.
Große Aktion
Einmal im Jahr findet im Projekt eine große Aktion für die Benutzer statt — das ist das Highload-Event, da wir zu dieser Zeit mit zig Millionen Benutzern gleichzeitig arbeiten.
Normalerweise treten Lastspitzen an Feiertagen auf, aber diese Aktion ist völlig anders. Vor zwei Jahren haben wir am Tag der Aktion 27.580.890 Produkte verkauft. Die Datenverarbeitung dauerte über eine halbe Stunde, was bei den Benutzern zu Unannehmlichkeiten führte. Die Benutzer erhielten Preise für ihre Teilnahme, aber es wurde klar, dass der Prozess schneller gestaltet werden muss.
Anfang 2019 entschieden wir, dass wir ElasticSearch benötigen. Ein ganzes Jahr lang organisierten wir die Verarbeitung der erhaltenen Daten in Elastic und deren Bereitstellung über die API für die mobile Anwendung und die Website. Letztendlich haben wir im folgenden Jahr während einer Aktion 15 131 783 Datensätze in 6 Minuten verarbeitet.
Da viele an unserem Produkt und an der Teilnahme an Gewinnspielen interessiert sind, ist dies eine vorübergehende Maßnahme. Derzeit senden wir aktuelle Informationen an Elastic, planen jedoch, die archivierten Informationen der vergangenen Monate in Postgres zu übertragen, um einen permanenten Speicher zu schaffen. So vermeiden wir es, den Elastic-Index zu verunreinigen, der ebenfalls seine eigenen Einschränkungen hat.
Fazit/Schlussfolgerungen
Bis jetzt haben wir alle gewünschten Services in Elastic übertragen und haben vorerst eine Pause eingelegt. Derzeit bauen wir einen Index in Elastic, der auf dem Hauptspeicher in Postgres basiert und die Benutzerlast übernimmt.
Zukünftig planen wir, Services zu migrieren, wenn wir erkennen, dass die Datenanfragen zu vielfältig werden und über eine unbegrenzte Anzahl von Spalten gesucht wird. Das ist dann eine Aufgabe, die nicht mehr für Postgres geeignet ist.
Wenn wir eine Volltextsuche in der Funktionalität benötigen oder wenn wir viele verschiedene Suchkriterien haben, wissen wir bereits, dass dies in Elastic übersetzt werden muss.
⌘⌘⌘
Danke, dass Sie gelesen haben. Wenn in Ihrem Unternehmen auch ElasticSearch verwendet wird und Sie eigene Implementierungsfälle haben, erzählen Sie uns davon. Es wäre interessant zu erfahren, wie es bei anderen aussieht 🙂
Quelle: habr.com
