

Jedes größere Projekt begann mit ein paar Servern. Zunächst gab es einen DB-Server, dann kamen Slave-Server hinzu, um das Lesevolumen zu skalieren. Und dann kommt der Stopp! Nur ein Master und viele Slaves; wenn einer der Slaves ausfällt, ist das in Ordnung, aber wenn der Master ausfällt — dann ist es schlecht: Ausfallzeit, Admins heben den Server aus der Todeszone. Was tun? Den Master reservieren. Mein Kollege Pavel hat bereits darüber geschrieben , ich werde dies nicht wiederholen. Stattdessen erkläre ich, warum Sie unbedingt einen Orchestrator für MySQL benötigen!
Lassen Sie uns mit der wichtigsten Frage beginnen: „Wie schalten wir den Code auf die neue Maschine um, wenn der Master ausfällt?“
- Das Schema mit VIP (Virtual IP) gefällt mir am besten, darüber werden wir auch gleich sprechen. Es ist das einfachste und offensichtlichste, hat aber eine klare Einschränkung: Der Master, den wir reservieren werden, muss sich im L2-Segment mit der neuen Maschine befinden, das heißt, das zweite Rechenzentrum können wir vergessen. Und ehrlich gesagt sollte man, wenn man der Regel folgt, dass ein großes L2 schlecht ist, weil es nur auf einem Rack existiert, und zwischen den Racks L3 ist, berücksichtigen, dass ein solches Schema noch mehr Einschränkungen hat.
- Sie können den DNS-Namen im Code definieren und über /etc/hosts auflösen. In Wirklichkeit wird jedoch keine Auflösung stattfinden. Der Vorteil dieses Ansatzes liegt darin, dass es keine Einschränkungen wie beim ersten Weg gibt, wodurch auch eine cross-Datacenter-Organisation möglich ist. Natürlich stellt sich dann die offensichtliche Frage, wie schnell wir Änderungen über Puppet-Ansible in /etc/hosts bereitstellen können.
- Eine kleine Modifikation des zweiten Ansatzes könnte sein: Auf allen Webservern einen caching DNS-Server zu installieren, über den der Code auf die Master-Datenbank zugreift. Man kann für diesen DNS-Eintrag eine TTL von 60 setzen. Bei richtiger Implementierung scheint dieser Ansatz vielversprechend zu sein.
- Ein Schema zur Dienstentdeckung, das die Verwendung von Consul und etcd vorsieht.
- Eine interessante Variante mit . Der gesamte MySQL-Verkehr sollte über ProxySQL geleitet werden, da ProxySQL in der Lage ist, den aktuellen Master automatisch zu erkennen. Eine der Einsatzmöglichkeiten dieses Produkts kann in meinem Artikel nachgelesen werden. .
Der Autor Orchestrator hat bei seiner Arbeit in Github zunächst das erste Schema mit VIP umgesetzt und dann auf das Schema mit Consul umgestellt.
Typisches Infrastruktur-Schema:
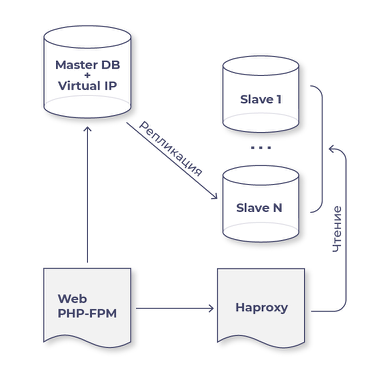
Ich werde sofort die offensichtlichen Situationen beschreiben, die man berücksichtigen sollte:
- Die VIP-Adresse darf in der Konfiguration keines der Server eingetragen sein. Stellen Sie sich folgendes Szenario vor: Der Master wird neu gestartet, während der Orchestrator in den Failover-Modus wechselt und einen der Slaves zum neuen Master erhebt; dann startet der alte Master wieder, und jetzt gibt es die VIP-Adresse auf zwei Maschinen. Das ist problematisch.
- Für den Orchestrator muss ein Skript zur Kommunikation mit dem alten und dem neuen Master geschrieben werden. Auf dem alten Master sollte ifdown ausgeführt werden, während auf dem neuen Master ifup vip ausgeführt wird. Es wäre außerdem gut, in dieses Skript aufzunehmen, dass im Fall eines Failovers der Port am Switch des alten Masters einfach abgeschaltet wird, um jeglichen Split-Brain zu vermeiden.
- Nachdem der Orchestrator Ihr Skript aufgerufen hat, um zunächst die VIP abzuschalten und/oder den Port am Switch abzuschalten, und dann auf dem neuen Master das Skript zum Aktivieren der VIP aufgerufen hat, vergessen Sie nicht, mit dem Befehl arping allen mitzuteilen, dass die neue VIP jetzt hier ist.
- Auf allen Slaves sollte read_only=1 gesetzt sein, und sobald Sie einen Slave zum Master befördern, muss sich der Wert auf read_only=0 ändern.
- Denken Sie daran, dass jeder Slave, den wir dafür ausgewählt haben, zum Master werden kann (Orchestrator hat einen Mechanismus, um die Präferenzen zu bestimmen, welcher Slave zunächst als potenzieller Master in Betracht gezogen wird, welcher als zweites und welcher Slave unter keinen Umständen als Master ausgewählt werden sollte). Wenn ein Slave zum Master wird, behält er die Last des Slaves und erhält zusätzlich die Last des Masters, was berücksichtigt werden muss.
Warum benötigen Sie Orchestrator unbedingt, wenn Sie ihn noch nicht haben?
- Orchestrator bietet eine sehr benutzerfreundliche grafische Oberfläche, die die gesamte Topologie anzeigt (siehe Screenshot unten).
- Orchestrator kann überwachen, welche Slaves hinterherhinken und wo die Replikation sogar ganz gescheitert ist (wir haben Skripte an Orchestrator angeschlossen, die SMS senden).
- Orchestrator informiert Sie über die Slaves, auf denen ein GTID-Fehler vorliegt.
Benutzeroberfläche von Orchestrator:
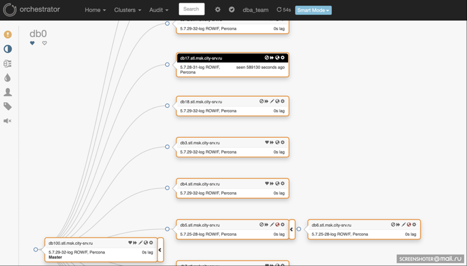
Was ist also ein GTID-Fehler?
Es gibt zwei grundlegende Voraussetzungen für den Betrieb von Orchestrator:
- Auf allen Maschinen des MySQL-Clusters muss pseudo GTID aktiviert sein, wir haben GTID aktiviert.
- Es ist wichtig, dass überall der gleiche Typ von Binärprotokollen verwendet wird, vorzugsweise den Statement-Typ. Wir hatten eine Konfiguration, bei der auf dem Master und den meisten Slaves der Row-Modus aktiviert war, während bei zwei historisch der Mixed-Modus erhalten blieb. Infolgedessen wollte der Orchestrator diese Slaves einfach nicht mit dem neuen Master verbinden.
Denken Sie daran, dass das Wichtigste bei einem Produktions-Slave seine Konsistenz mit dem Master ist! Wenn sowohl auf dem Master als auch auf dem Slave die Global Transaction ID (GTID) aktiviert ist, können Sie über die Funktion gtid_subset überprüfen, ob auf diesen Maschinen tatsächlich die gleichen Änderungsanfragen ausgeführt wurden. Weitere Informationen dazu finden Sie hier. .
So zeigt Ihnen der Orchestrator durch den GTID-Fehler an, dass es auf dem Slave Transaktionen gibt, die auf dem Master nicht vorhanden sind. Warum passiert das?
- Auf dem Slave ist read_only=1 nicht aktiviert, jemand hat sich verbunden und eine Anfrage zur Datenänderung ausgeführt.
- Auf dem Slave ist super_read_only=1 nicht aktiviert, sodass ein Administrator, der den Server verwechselt hat, sich dort angemeldet und eine Anfrage ausgeführt hat.
- Wenn Sie die beiden vorherigen Punkte berücksichtigt haben, gibt es noch einen weiteren Trick: In MySQL wird auch der Flush-Befehl für die Binärprotokolle in das Binärprotokoll aufgenommen. Daher wird beim ersten Flush auf dem Master und auf allen Slaves ein GTID-Fehler angezeigt. Wie kann man das vermeiden? In perona-5.7.25-28 gibt es die Einstellung binlog_skip_flush_commands=1, die das Schreiben von Flush-Befehlen in die Binärprotokolle verbietet. Weitere Informationen finden Sie auf mysql.com. .
Zusammenfassend lässt sich sagen: Wenn Sie Orchestrator derzeit nicht im Failover-Modus verwenden möchten, setzen Sie ihn in den Überwachungsmodus. So haben Sie immer eine Übersicht über die Interaktion der MySQL-Maschinen und die direkte Information darüber, welcher Replikationstyp auf jeder Maschine läuft, ob die Slaves hinterherhinken und vor allem, wie konsistent sie mit dem Master sind!
Offensichtliche Frage: „Wie sollte der Orchestrator funktionieren?“. Er sollte einen neuen Master aus den aktuellen Slaves auswählen und dann alle Slaves zu ihm umschalten (gerade dafür ist GTID notwendig; wenn man die alte Methode mit binlog_name und binlog_pos verwendet, ist ein Wechsel des Slaves vom aktuellen Master auf den neuen einfach unmöglich!). Bevor wir den Orchestrator hatten, musste ich einmal alles manuell durchführen. Der alte Master hing wegen eines fehlerhaften Adaptec-Controllers, und ich hatte etwa 10 Slaves. Ich musste die VIP von dem Master auf einen der Slaves umschalten und alle anderen Slaves daran anschließen. Wie viele Konsolen musste ich öffnen, wie viele gleichzeitige Befehle eingeben… Ich musste bis um 3 Uhr morgens warten, die Last von allen Slaves, außer zwei, nehmen, die erste Maschine aus zwei zum Master machen, sofort die zweite Maschine anschließen und alle anderen Slaves wieder mit dem neuen Master verbinden und die Last zurückgeben. Kurz gesagt, schrecklich…
Wie funktioniert der Orchestrator, wenn er in den Failover-Modus wechselt? Am besten lässt sich das anhand einer Situation erklären, in der wir eine leistungsstärkere, moderne Maschine zum Master machen wollen, als die, die wir derzeit haben.
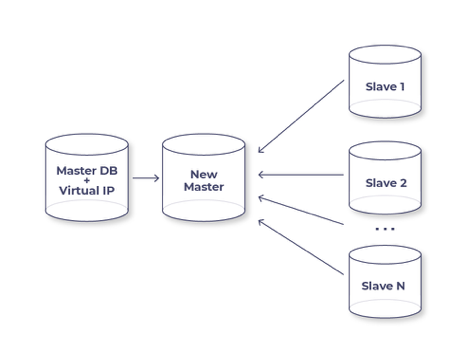
Das Bild zeigt die Mitte des Prozesses. Was wurde bis zu diesem Punkt bereits gemacht? Wir haben gesagt, dass wir einen bestimmten Slave zum neuen Master machen möchten, der Orchestrator begann einfach, alle anderen Slaves an ihn wieder anzuschließen, während der neue Master die Rolle einer Übergangsmaschine einnimmt. Bei diesem Setup treten keine Fehler auf, alle Slaves arbeiten ordnungsgemäß, der Orchestrator entfernt die VIP vom alten Master, überträgt sie auf den neuen, stellt read_only=0 ein und vergisst den alten Master. Das wars! Die Ausfallzeit unseres Dienstes beträgt die Zeit für die Übertragung der VIP, etwa 2-3 Sekunden.
Das ist es für heute, vielen Dank. Bald wird der zweite Artikel über den Orchestrator veröffentlicht. In einem bekannten sowjetischen Film "Die Garage" sagte ein Charakter: "Ich würde nicht mit ihm in die Aufklärung gehen!" Also, Orchestrator, ich würde mit dir in die Aufklärung gehen!
Quelle: habr.com
