

Ich lade Sie ein, die Transkription des Vortrags von Alexey Lesovskiy von Data Egret "Grundlagen der PostgreSQL-Überwachung" zu lesen.
In diesem Vortrag wird Alexey Lesovskiy die Schlüsselpunkte der PostgreSQL-Statistiken erläutern, was sie bedeuten und warum sie in der Überwachung vorhanden sein sollten; welche Grafiken in der Überwachung notwendig sind, wie man sie hinzufügt und wie man sie interpretiert. Der Vortrag wird für Datenbankadministratoren, Systemadministratoren und Entwickler von Interesse sein, die an der Problemlösung von Postgres interessiert sind.


Mein Name ist Alexey Lesovskiy und ich vertrete das Unternehmen Data Egret.
Ein paar Worte über mich. Ich habe einst vor vielen Jahren als Systemadministrator angefangen.
Ich habe verschiedene Linux-Systeme administriert, mich mit verschiedenen Linux-bezogenen Themen, wie Virtualisierung und Überwachung, beschäftigt und mit Proxys gearbeitet. Aber irgendwann habe ich mich mehr mit Datenbanken beschäftigt, insbesondere mit PostgreSQL. Es hat mir sehr gefallen. Schließlich habe ich den Großteil meiner Arbeitszeit mit PostgreSQL verbracht und bin so allmählich PostgreSQL DBA geworden.
In meiner gesamten Karriere haben mich immer die Themen Statistik, Monitoring und Telemetriedaten interessiert. Während meiner Zeit als Systemadministrator habe ich mich intensiv mit Zabbix beschäftigt und ein kleines Set an Skripten geschrieben, das . Es erlangte zu seiner Zeit recht große Beliebtheit. Damit konnte man eine Vielzahl von wichtigen Aspekten überwachen, nicht nur Linux, sondern auch verschiedene andere Komponenten.
Zurzeit arbeite ich mit PostgreSQL. Ich entwickle ein anderes Tool, das die Arbeit mit PostgreSQL-Statistiken ermöglicht. Es heißt (Artikel auf Habr — ).

Eine kurze Einführung. Welche Situationen treten bei unseren Kunden auf? Es kommt zu einem Vorfall mit der Datenbank. Nachdem die Datenbank wiederhergestellt wurde, kommt der Abteilungsleiter oder der Entwicklungsleiter und sagt: „Freunde, wir sollten die Datenbank überwachen, denn es ist etwas Schlimmes passiert und wir müssen verhindern, dass so etwas in Zukunft nochmals passiert.“ Hier beginnt der spannende Prozess, ein Überwachungssystem auszuwählen oder ein bestehendes System anzupassen, um die eigene Datenbank – sei es PostgreSQL, MySQL oder eine andere – zu überwachen. Die Kollegen fangen an, Vorschläge zu machen: „Ich habe gehört, dass es diese oder jene Datenbank gibt. Lasst uns die nutzen.“ Die Kollegen fangen an, untereinander zu streiten. Am Ende wählen wir eine Datenbank aus, aber die Überwachung von PostgreSQL ist darin ziemlich schwach ausgeprägt, sodass ständig Anpassungen notwendig sind. Man muss bestimmte Repositories von GitHub herunterladen, sie klonen, Skripte anpassen und wie auch immer nachjustieren. Letztlich führt dies zu einer Menge manueller Arbeit.

In diesem Bericht werde ich Ihnen vermitteln, wie Sie Monitoring-Lösungen nicht nur für PostgreSQL, sondern auch für andere Datenbanken auswählen können. Ziel ist es, Ihr Monitoring so zu optimieren, dass Sie daraus echten Nutzen ziehen können, um Ihre Datenbank effektiv zu überwachen und rechtzeitig auf bevorstehende Probleme oder Ausfälle reagieren zu können.
Die Ideen in diesem Bericht lassen sich direkt auf jede Datenbank anwenden, sei es eine relationale Datenbank oder NoSQL. Daher werden nicht nur Aspekte von PostgreSQL behandelt; Sie finden auch viele Ansätze, wie Sie Monitoring in PostgreSQL umsetzen können. Es werden Abfragebeispiele und Entitäten gezeigt, die in PostgreSQL für das Monitoring zur Verfügung stehen. Wenn Ihre Datenbank ähnliche Funktionen bietet, die Sie in Ihr Monitoring integrieren können, können Sie diese ebenfalls adaptieren und umsetzen.
 In dem Bericht werde ich nicht
In dem Bericht werde ich nicht
darlegen, wie Metriken erfasst und gespeichert werden. Ich werde nichts über die Datenverarbeitung und deren Bereitstellung für den Benutzer sagen und auch nichts über das Alerting erwähnen.
Im Verlauf des Berichts werde ich verschiedene Screenshots bestehender Monitoring-Tools zeigen und diese kritisieren. Dennoch werde ich versuchen, keine Marken zu nennen, um keine Werbung oder gegen diese Produkte gerichtete Werbung zu machen. Daher sind alle Übereinstimmungen zufällig und dem Leser überlassen.

Lassen Sie uns zunächst klären, was Monitoring bedeutet. Monitoring ist ein äußerst wichtiges Element, das jeder haben sollte. Das ist allgemein bekannt. Aber gleichzeitig zählt Monitoring nicht als direktes Geschäftsprodukt und hat keinen unmittelbaren Einfluss auf den Gewinn eines Unternehmens. Daher wird Monitoring oft nur nachrangig behandelt. Wenn wir Zeit haben, kümmern wir uns um das Monitoring; wenn nicht, dann bleibt es einfach im Backlog und wird irgendwann später angegangen.
In unserer Erfahrung, wenn wir zu Kunden kommen, ist das Monitoring häufig unvollständig und weist keine interessanten Funktionen auf, die uns bei der Arbeit mit der Datenbank helfen könnten. Daher muss das Monitoring immer weiter verbessert werden.
Datenbanken sind komplexe Systeme, die ebenfalls überwacht werden müssen, da sie als Informationsspeicher fungieren. Informationen sind für ein Unternehmen von großer Bedeutung und dürfen nicht verloren gehen. Gleichzeitig sind Datenbanken jedoch sehr komplexe Softwarekomponenten, die aus zahlreichen Elementen bestehen, von denen viele überwacht werden müssen.
 Betrachten wir konkret PostgreSQL, so lässt es sich als ein Schema darstellen, das aus vielen Komponenten besteht. Diese Komponenten interagieren miteinander. Zudem gibt es in PostgreSQL das sogenannte Stats Collector-System, das es ermöglicht, Statistiken über die Leistung dieser Subsysteme zu sammeln und dem Administrator oder Benutzer eine Schnittstelle zu bieten, um diese Statistiken einzusehen.
Betrachten wir konkret PostgreSQL, so lässt es sich als ein Schema darstellen, das aus vielen Komponenten besteht. Diese Komponenten interagieren miteinander. Zudem gibt es in PostgreSQL das sogenannte Stats Collector-System, das es ermöglicht, Statistiken über die Leistung dieser Subsysteme zu sammeln und dem Administrator oder Benutzer eine Schnittstelle zu bieten, um diese Statistiken einzusehen.
Diese Statistiken werden in Form eines Satzes von Funktionen und Views präsentiert, die auch als Tabellen bezeichnet werden können. Mit einem herkömmlichen psql-Client können Sie sich mit der Datenbank verbinden, diese Funktionen und Views abfragen und konkrete Zahlen zur Leistung der PostgreSQL-Subsysteme erhalten.
Sie können diese Zahlen in Ihr bevorzugtes Überwachungssystem einfügen, Grafiken erstellen, Funktionen hinzufügen und langfristige Analysen erhalten.
In diesem Bericht möchte ich jedoch nicht alle diese Funktionen umfassend behandeln, da dies einen ganzen Tag in Anspruch nehmen könnte. Stattdessen werde ich mich auf nur zwei bis vier Punkte konzentrieren und erläutern, wie sie die Überwachung verbessern.

Wenn es um die Überwachung der Datenbank geht, welche Aspekte sollten wir im Auge behalten? Zuerst einmal die Verfügbarkeit, denn die Datenbank ist ein Dienst, der den Zugang zu Daten für unsere Kunden bereitstellt, und wir müssen die Verfügbarkeit überwachen, sowie einige qualitative und quantitative Merkmale, die damit verbunden sind.

Außerdem sollten wir die Kunden überwachen, die sich mit unserer Datenbank verbinden. Diese können sowohl normale Kunden als auch schädliche Nutzer sein, die der Datenbank schaden könnten. Auch deren Aktivitäten müssen überwacht werden.

Wenn Kunden auf die Datenbank zugreifen, arbeiten sie offensichtlich mit unseren Daten. Daher müssen wir auch überwachen, wie die Kunden mit den Daten interagieren: mit welchen Tabellen und in geringerem Maße mit welchen Indizes. Das heißt, wir müssen die Arbeitslast (workload) bewerten, die durch unsere Kunden entsteht.

Die Arbeitslast setzt sich natürlich aus Anfragen zusammen. Anwendungen verbinden sich mit der Datenbank und greifen über Anfragen auf die Daten zu. Deshalb ist es wichtig, die Anfragen in unserer Datenbank zu bewerten, ihre Angemessenheit zu überwachen und sicherzustellen, dass sie nicht fehlerhaft geschrieben sind. Einige Optionen müssen möglicherweise überarbeitet werden, damit sie schneller und mit besserer Leistung arbeiten.

Wenn wir über Datenbanken sprechen, sind Datenbanken immer mit Hintergrundprozessen verbunden. Diese Prozesse sorgen dafür, dass die Leistung der Datenbank auf einem hohen Niveau bleibt, weshalb sie eine gewisse Menge an Ressourcen benötigen. Gleichzeitig können sie mit den Ressourcen der Clientanfragen in Konflikt geraten, und ein übermäßiger Ressourcenverbrauch dieser Hintergrundprozesse kann die Leistung der Clientanfragen direkt beeinflussen. Daher ist es wichtig, auch diese Prozesse zu überwachen und sicherzustellen, dass es keine Ungleichgewichte gibt.

In Bezug auf das Monitoring von Datenbanken bleiben alle diese Aspekte innerhalb der Systemmetriken. Da jedoch die meisten unserer Infrastrukturen in die Cloud verlagert werden, rücken die Systemmetriken eines einzelnen Hosts häufig in den Hintergrund. In Datenbanken sind sie jedoch weiterhin relevant, und es ist natürlich auch notwendig, die Systemmetriken zu überwachen.

Mit den Systemmetriken ist im Großen und Ganzen alles in Ordnung; alle modernen Monitoring-Systeme unterstützen bereits diese Metriken. Dennoch fehlen insgesamt einige Komponenten, und es müssen gewisse Dinge hinzugefügt werden. Auch darauf werde ich eingehen; es wird mehrere Folien zu diesem Thema geben.

Der erste Punkt des Plans ist die Verfügbarkeit. Was bedeutet Verfügbarkeit? Meiner Meinung nach ist Verfügbarkeit die Fähigkeit der Datenbank, Verbindungen zu bedienen, d. h. die Datenbank ist aktiv und nimmt Verbindungen von Klienten entgegen. Diese Verfügbarkeit kann anhand einiger Merkmale bewertet werden. Diese Merkmale lassen sich sehr gut auf Dashboards darstellen.

Alle wissen, was Dashboards sind. Es ist, wenn du einen kurzen Blick auf einen Bildschirm wirfst, auf dem die erforderlichen Informationen zusammengefasst sind. Und du kannst sofort feststellen, ob es ein Problem mit der Datenbank gibt oder nicht.
Daher ist es wichtig, die Verfügbarkeit der Datenbank und andere Schlüsselmerkmale immer auf Dashboards darzustellen, damit diese Informationen zur Hand sind und stets verfügbar sind. Zusätzliche Details, die bei der Untersuchung von Vorfällen oder Notfallsituationen helfen, sollten auf sekundäre Dashboards ausgegliedert oder in Drilldown-Links verborgen werden, die auf externe Monitoring-Systeme verweisen.
Ein Beispiel für ein bekanntes Überwachungssystem. Es handelt sich um ein sehr fortschrittliches Überwachungssystem. Es sammelt eine große Menge an Daten, aber aus meiner Sicht hat es ein merkwürdiges Verständnis von Dashboards. Es gibt einen Link „Dashboard erstellen“. Wenn Sie jedoch ein Dashboard erstellen, erstellen Sie eine Art Liste, die aus zwei Spalten besteht, eine Liste von Diagrammen. Und wenn Sie etwas ansehen möchten, klicken Sie mit der Maus, scrollen und suchen nach dem gewünschten Diagramm. Das kostet Zeit, das heißt, echte Dashboards gibt es nicht. Es gibt nur Listen von Diagrammen.

Was sollte man auf diese Dashboards hinzufügen? Man kann mit einer Kennzahl wie der Reaktionszeit beginnen. In PostgreSQL gibt es die Ansicht pg_stat_statements. Sie ist standardmäßig deaktiviert, aber es ist eine der wichtigen systemeigenen Ansichten, die immer aktiviert und verwendet werden sollte. Sie enthält Informationen über alle ausgeführten Abfragen, die in der Datenbank durchgeführt wurden.
Dementsprechend können wir von der Gesamtzeit der ausgeführten Anfragen ausgehen und sie durch die Anzahl der Anfragen dividieren, basierend auf den oben genannten Feldern. Aber das ist eine allgemeine Angabe. Wir können auch andere Felder heranziehen – die minimale, maximale und mediane Laufzeit der Anfragen. Zudem können wir Perzentile berechnen; in PostgreSQL gibt es dafür entsprechende Funktionen. Dadurch erhalten wir Werte, die die Antwortzeit unserer Datenbank bei bereits ausgeführten Anfragen charakterisieren. Das heißt, wir führen nicht einfach eine fiktive Abfrage wie 'select 1' durch und messen die Antwortzeit, sondern analysieren die Antwortzeiten vorhandener Anfragen und stellen diese als Einzelwert dar oder erstellen ein Diagramm auf dieser Grundlage.
Es ist auch wichtig, die Anzahl der derzeit von der System generierten Fehler zu überwachen. Dazu kann die Ansicht pg_stat_database verwendet werden. Wir konzentrieren uns auf das Feld xact_rollback. Dieses Feld zeigt nicht nur die Anzahl der Rollbacks, die in der Datenbank stattfinden, sondern berücksichtigt auch die Anzahl der Fehler. Wir können diese Zahl theoretisch in unser Dashboard integrieren und beobachten, wie viele Fehler wir derzeit haben. Wenn es viele Fehler gibt, ist das ein guter Anlass, die Logs zu überprüfen und herauszufinden, um welche Fehler es sich handelt und warum sie auftreten, um dann entsprechende Untersuchungen anzustellen und Lösungen zu finden.

Es ist möglich, etwas wie einen Tacho hinzuzufügen. Dies zeigt die Anzahl der Transaktionen pro Sekunde und die Anzahl der Anfragen pro Sekunde an. Vereinfacht gesagt, können Sie diese Zahlen als aktuelle Leistung Ihrer Datenbank verwenden und beobachten, ob es hier zu Anfrage- oder Transaktionsspitzen kommt oder ob die Datenbank unterlastet ist, weil ein Backend ausgefallen ist. Diese Kennzahl sollte stets im Auge behalten werden. Für unser Projekt ist diese Leistung normal, während Werte darüber oder darunter problematisch und unklar sind. Das bedeutet, dass wir überprüfen müssen, warum solche Zahlen auftreten.
Um die Anzahl der Transaktionen zu bewerten, können wir erneut auf die Ansicht pg_stat_database zugreifen. Wir können die Anzahl der Commits und der Rollbacks addieren und die Anzahl der Transaktionen pro Sekunde ermitteln.
Jeder versteht, dass in eine Transaktion mehrere Anfragen passen können? Daher sind TPS und QPS etwas unterschiedlich.
Die Anzahl der Anfragen pro Sekunde kann über pg_stat_statements ermittelt werden, indem man einfach die Summe aller ausgeführten Anfragen berechnet. Es ist klar, dass wir den aktuellen Wert mit dem vorherigen vergleichen, die Differenz berechnen und die Anzahl erhalten.

Es können auf Wunsch zusätzliche Metriken hinzugefügt werden, die ebenfalls helfen, die Verfügbarkeit unserer Datenbank zu bewerten und zu verfolgen, ob es irgendwelche Ausfallzeiten gab.
Eine dieser Metriken ist die Uptime. Aber Uptime in PostgreSQL ist ein etwas kompliziertes Thema. Lassen Sie mich erklären, warum. Sobald PostgreSQL gestartet ist, beginnt die Uptime zu zählen. Wenn jedoch zu einem bestimmten Zeitpunkt, zum Beispiel nachts, eine Aufgabe ausgeführt wurde und der OOM-Killer einen untergeordneten Prozess von PostgreSQL zwangsweise beendet, beendet PostgreSQL in diesem Fall die Verbindung zu allen Clients, setzt den Bereich des shardierten Speichers zurück und beginnt die Wiederherstellung von dem letzten Prüfpunkte. Während dieser Wiederherstellung nimmt die Datenbank keine Verbindungen an, was als Ausfallzeit betrachtet werden kann. Gleichzeitig wird der Uptime-Zähler jedoch nicht zurückgesetzt, da er die Zeit seit dem ersten Start des Postmasters zählt. Daher können solche Situationen übersehen werden.
Es ist auch wichtig, die Anzahl der Autovacuum-Arbeiter zu überwachen. Wissen Sie, was Autovacuum in PostgreSQL ist? Es handelt sich um ein faszinierendes System innerhalb von PostgreSQL. Darüber wurden zahlreiche Artikel verfasst und viele Vorträge gehalten. Es gibt viele Diskussionen über das Vacuum und darüber, wie es funktionieren sollte. Viele betrachten es als ein notwendiges Übel. Und das ist es tatsächlich. Es ähnelt einem Garbage Collector, der veraltete Zeilenversionen bereinigt, die von keiner Transaktion benötigt werden, und Platz in Tabellen und Indizes für neue Zeilen schafft.
Warum ist es notwendig, das zu überwachen? Weil das Vacuum manchmal großen Schaden anrichten kann. Es beansprucht eine erhebliche Menge an Ressourcen, was dazu führt, dass die Client-Anfragen darunter leiden.
Die Überwachung sollte über die Ansicht pg_stat_activity erfolgen, über die ich im nächsten Abschnitt sprechen werde. Diese Ansicht zeigt die aktuelle Aktivität in der Datenbank an. Anhand dieser Aktivität können wir die Anzahl der aktuell laufenden Vacuum-Prozesse verfolgen. Wir können die Vacuums beobachten und feststellen, dass, wenn wir das Limit überschreiten, dies ein Grund ist, die PostgreSQL-Einstellungen zu überprüfen und die Vacuum-Arbeiten zu optimieren.
Eine weitere Eigenschaft von PostgreSQL ist, dass es unter langen Transaktionen leidet. Besonders unter Transaktionen, die lange verweilen und keine Aktivitäten durchführen. Diese werden als stat idle-in-transaction bezeichnet. Eine solche Transaktion hält Sperren und behindert die Arbeit des Vacuum-Prozesses. Infolgedessen wachsen die Tabellen und nehmen an Größe zu. Anfragen, die mit diesen Tabellen arbeiten, beginnen langsamer zu werden, weil alte Versionen der Zeilen aus dem Speicher auf die Festplatte und zurück geschaufelt werden müssen. Daher ist es wichtig, die Dauer der längsten Transaktionen sowie die längsten Anfragen des Vacuum-Prozesses zu überwachen. Wenn wir Prozesse sehen, die bereits sehr lange laufen, also länger als 10-20-30 Minuten bei OLTP-Last, dann sollten wir darauf achten und sie entweder zwangläufig beenden oder die Anwendung optimieren, damit sie nicht so lange aufgerufen werden und hängen bleiben. Bei analytischer Last sind 10-20-30 Minuten normal; manchmal gibt es sogar noch längere.

Als Nächstes haben wir die Option mit verbundenen Kunden. Sobald wir das Dashboard erstellt und die wichtigen Verfügbarkeitsmetriken angezeigt haben, können wir auch zusätzliche Informationen über die verbundenen Kunden hinzufügen.
Informationen über die verbundenen Kunden sind wichtig, denn aus der Perspektive von PostgreSQL gibt es verschiedene Arten von Kunden. Es gibt gute Kunden und es gibt schlechte Kunden.
Ein einfaches Beispiel: Mit Kunden meine ich Anwendungen. Eine Anwendung stellt eine Verbindung zur Datenbank her und beginnt sofort, ihre Anfragen zu senden. Die Datenbank verarbeitet diese Anfragen, führt sie aus und gibt die Ergebnisse an den Kunden zurück. Das sind gute und richtige Kunden.
Es gibt Situationen, in denen sich ein Kunde verbindet und die Verbindung aufrechterhält, aber dabei nichts tut. Er befindet sich im Zustand idle.
Es gibt jedoch auch problematische Kunden. Ein Beispiel wäre ein Kunde, der sich anmeldet, eine Transaktion öffnet, etwas in der Datenbank macht und dann zur Code-Ebene wechselt, um auf eine externe Quelle zuzugreifen oder um dort die erhaltenen Daten zu verarbeiten. Dabei schließt er jedoch die Transaktion nicht. Dadurch bleibt die Transaktion in der Datenbank offen und blockiert eine Zeile. Das ist ein ungünstiger Zustand. Wenn die Anwendung dann zufällig aufgrund eines Exceptions irgendwo im Inneren abstürzt, kann die Transaktion über einen sehr langen Zeitraum offen bleiben. Dies hat direkte Auswirkungen auf die Leistung von PostgreSQL. PostgreSQL wird langsamer arbeiten. Daher ist es wichtig, solche Kunden rechtzeitig zu überwachen und ihre Arbeit gegebenenfalls zwangsweise zu beenden. Zudem muss die Anwendung optimiert werden, um solche Situationen zu vermeiden.
Andere problematische Kunden sind wartende Kunden. Sie werden jedoch aus Umständen problematisch. Ein einfaches Beispiel sind wartende Transaktionen: Eine Transaktion kann eine Sperre auf bestimmte Zeilen setzen, dann kann sie irgendwo im Code fehlschlagen und es bleibt eine hängende Transaktion. Ein anderer Kunde könnte die gleichen Daten anfordern, aber er wird auf eine Sperre stoßen, weil die hängende Transaktion bereits Sperren auf bestimmte benötigte Zeilen hält. Die zweite Transaktion wird somit im Warten hängen bleiben, bis die erste Transaktion abgeschlossen ist oder ihr Administrator sie zwangsweise schließt. Wartende Transaktionen können sich ansammeln und das Verbindungslimit zur Datenbank überschreiten. Wenn das Limit überschritten ist, kann die Anwendung nicht mehr mit der Datenbank arbeiten. Dies stellt eine Notfallsituation für das Projekt dar. Daher ist es wichtig, problematische Kunden zu überwachen und zeitnah zu reagieren.
Ein weiteres Beispiel für das Monitoring. Hier sehen wir ein ansprechendes Dashboard. Oben finden Sie Informationen zu den Verbindungen. Insgesamt 8 DB-Verbindungen. Das ist alles. Wir haben keine Informationen darüber, welche Kunden aktiv sind, welche nur im Leerlauf sind und nichts tun. Es fehlen Informationen zu hängenden Transaktionen und zu wartenden Verbindungen. Es handelt sich nur um eine Zahl, die die Anzahl der Verbindungen anzeigt, und das war's. Weiter müssen Sie selbst raten.

Um diese Informationen im Monitoring zu integrieren, müssen Sie die Systemansicht pg_stat_activity nutzen. Wenn Sie viel Zeit mit PostgreSQL verbringen, wird diese Ansicht zu Ihrem besten Freund, da sie die aktuelle Aktivität in PostgreSQL anzeigt, also was dort gerade passiert. Jeder Prozess hat eine eigene Zeile, die Informationen zu diesem Prozess darstellt: von welchem Host die Verbindung hergestellt wurde, unter welchem Benutzer, unter welchem Namen, wann die Transaktion gestartet wurde, welcher aktuelle Befehl ausgeführt wird und welcher Befehl zuletzt ausgeführt wurde. Das Zustand des Clients kann anhand des Feldes stat bewertet werden. Wir können dies gruppieren und die aktuellen Stats in der Datenbank sowie die Anzahl der Verbindungen mit diesem stat in der Datenbank ermitteln. Diese Zahlen können wir dann in unser Monitoring einspeisen und Diagramme dafür erstellen.
Es ist auch wichtig, die Dauer der Transaktionen zu bewerten. Ich habe bereits gesagt, dass die Dauer der Vakuumprozesse wichtig ist, aber die Transaktionen werden auf die gleiche Weise bewertet. Es gibt die Felder xact_start und query_start. Diese zeigen, sozusagen, den Startzeitpunkt der Transaktion und den Startzeitpunkt der Anfrage an. Wir verwenden die Funktion now(), die den aktuellen Zeitstempel anzeigt, und subtrahieren den Timestamp der Transaktion und der Anfrage. So erhalten wir die Dauer der Transaktion und die Dauer der Anfrage.
Wenn wir lange Transaktionen sehen, sollten wir diese bereits abschließen. Für OLTP-Lasten gelten Transaktionen von mehr als 1-2-3 Minuten als lang.. Für OLAP-Lasten sind lange Transaktionen normal, aber wenn sie länger als zwei Stunden dauern, ist das ebenfalls ein Zeichen dafür, dass es irgendwo ein Ungleichgewicht gibt.

Wenn die Kunden mit der Datenbank verbunden sind, beginnen sie mit unseren Daten zu arbeiten. Sie greifen auf Tabellen zu, sie greifen auf Indizes zu, um Daten aus der Tabelle abzurufen. Es ist wichtig zu bewerten, wie die Kunden mit diesen Daten arbeiten.
Dies dient dazu, unsere Arbeitslast zu bewerten und ein ungefähres Verständnis dafür zu bekommen, welche Tabellen bei uns am "heißesten" sind. Beispielsweise ist dies nötig, wenn wir "heiße" Tabellen auf einen schnellen SSD-Speicher legen möchten. Archivierte Tabellen, die wir seit langem nicht mehr verwenden, können wir auf ein "kaltes" Archiv, auf SATA-Festplatten, verschieben, wo sie verbleiben können, und der Zugriff erfolgt nach Bedarf.
Es ist auch nützlich, um Anomalien nach verschiedenen Releases und Deployments zu erkennen. Angenommen, das Projekt hat eine neue Funktion eingeführt. Beispielsweise wurde eine neue Funktionalität für die Arbeit mit der Datenbank hinzugefügt. Wenn wir Grafiken zur Nutzung der Tabellen erstellen, können wir diese Anomalien leicht auf diesen Grafiken erkennen. Beispielsweise plötzliche Anstiege bei Updates oder Deletes. Das wird sehr gut sichtbar sein.
Auch Anomalien einer "verzerrten" Statistik können festgestellt werden. Was bedeutet das? PostgreSQL verfügt über einen sehr leistungsstarken und hochwertigen Abfrageplaner. Die Entwickler widmen viel Zeit dessen Optimierung. Wie funktioniert er? Um gute Pläne zu erstellen, sammelt PostgreSQL in regelmäßigen Abständen Statistiken über die Verteilung der Daten in den Tabellen. Dazu gehören häufige Werte wie die Anzahl der einzigartigen Werte, Informationen über NULL in der Tabelle und eine große Menge an weiteren Informationen.
Basierend auf diesen Statistiken erstellt der Planer mehrere Abfragen, wählt die optimalste aus und verwendet diesen Abfrageplan zur Ausführung der Abfrage und zur Rückgabe der Daten.
Es kommt vor, dass die Statistiken "schwanken". Die Daten bezüglich Qualität und Menge haben sich in der Tabelle verändert, aber die Statistiken wurden nicht aktualisiert. Daher können die erstellten Pläne suboptimal sein. Wenn unsere Pläne anhand des gesammelten Monitorings und der Tabellen als suboptimal erweisen, können wir diese Anomalien identifizieren. Beispielsweise, wenn sich die Daten qualitativ verändert haben und der Index zusammen mit dem sequentiellen Durchlauf durch die Tabelle genutzt wird. Das bedeutet, wenn der Abfrage nur 100 Zeilen zurückgegeben werden sollen (mit einer Begrenzung von limit 100), wird eine vollständige Durchsuchung durchgeführt. Das wirkt sich immer negativ auf die Leistung aus.
Wir werden dies im Monitoring erkennen können. Wir können bereits diese Abfrage anschauen, ein Explain dafür durchführen, Statistiken sammeln und einen neuen zusätzlichen Index erstellen. So können wir auf dieses Problem reagieren. Daher ist das wichtig.
Ein weiteres Beispiel für Monitoring. Ich denke, viele werden es erkannt haben, weil es sehr populär ist. Wer es in seinen Projekten verwendet, ? А кто использует этот продукт совместно с Prometheus? Дело в том, что в стандартном репозитории этого мониторинга есть дашборд для работы с PostgreSQL – Prometheus. Aber hier gibt es einen Nachteil.
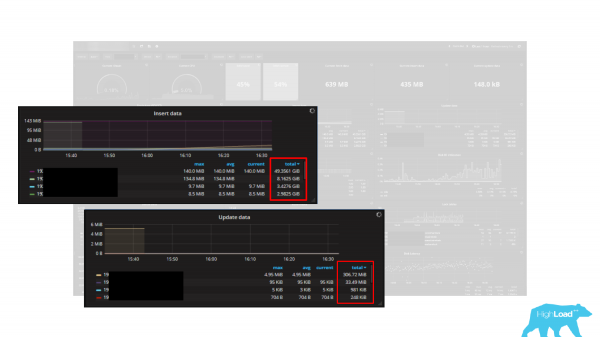
Es gibt mehrere Diagramme, in denen als Einheit Bytes angegeben sind, d.h. insgesamt fünf Diagramme: Insert-Daten, Update-Daten, Delete-Daten, Fetch-Daten und Return-Daten. Als Maßeinheit sind Bytes angegeben. Das Problem ist jedoch, dass die Statistik in PostgreSQL Daten in Tuples (Zeilen) zurückliefert. Entsprechend sind diese Diagramme eine ausgezeichnete Möglichkeit, Ihre Arbeitslast um ein Vielfaches zu senken, denn ein Tuple entspricht nicht einem Byte; ein Tuple ist eine Zeile, die viele Bytes umfasst und immer variable Länge hat. Es ist also eine äußerst komplizierte oder sogar unmögliche Aufgabe, die Arbeitslast in Bytes anhand von Tuples zu berechnen. Daher ist es wichtig, bei der Verwendung eines Dashboards oder einer integrierten Überwachung stets zu verstehen, dass diese korrekt funktioniert und Ihnen angemessen bewertete Daten liefert.

Wie erhält man Statistiken für diese Tabellen? PostgreSQL bietet dafür eine bestimmte Reihe von Views. Die wichtigste View ist . User_tables bedeutet, dass die Tabellen im Namen des Benutzers erstellt wurden. Im Gegensatz dazu gibt es System-Views, die von PostgreSQL selbst verwendet werden. Und es gibt eine aggregierte Tabelle Alltables, die sowohl System- als auch Benutzertabellen umfasst. Sie können je nach Vorliebe auf einer der beiden basieren.
Über die oben genannten Felder kann man die Anzahl von Insert, Update und Delete bewerten. Das Dashboard-Beispiel, das ich verwendet habe, nutzt genau diese Felder zur Einschätzung der Workload-Eigenschaften. Daher können wir uns auch darauf stützen. Es ist jedoch wichtig zu beachten, dass es sich um Tuples und nicht um Bytes handelt, weshalb wir dies nicht einfach in Bytes umrechnen können.
Auf Grundlage dieser Daten können wir sogenannte TopN-Tabellen erstellen, zum Beispiel Top-5 oder Top-10. Damit lässt sich verfolgen, welche Tabellen stärker beansprucht werden als andere. Beispielsweise die 5 'heißen' Tabellen im Hinblick auf Inserts. Anhand dieser TopN-Tabellen bewerten wir unsere Workload und können auch Spitzenlasten nach verschiedenen Releases, Updates und Deployments einschätzen.
Es ist ebenfalls wichtig, die Größe der Tabellen zu bewerten, da Entwickler manchmal neue Funktionen ausrollen und unsere Tabellen aufgrund des Hinzufügens zusätzlicher Datenmenge stark anwachsen. Dabei wird jedoch häufig nicht vorhergesehen, wie sich dies auf die Größe der Datenbank auswirkt. Solche Fälle können für uns ebenfalls überraschend sein.

Und jetzt eine kurze Frage an Sie. Welche Fragen kommen auf, wenn Sie eine Belastung auf einem Server mit einer Datenbank feststellen? Welche Fragen stellen Sie sich als Nächstes?

Tatsächlich stellt sich jedoch die folgende Frage: Welche Anfragen verursachen die Belastung? Es ist nicht interessant zu beobachten, welche Prozesse die Belastung verursachen. Es ist klar, dass, wenn der Host eine Datenbank verwaltet, dort eine Datenbank läuft, und logisch ist, dass nur Datenbanken dort Ressourcen nutzen. Wenn wir Top öffnen, sehen wir eine Liste von Prozessen in PostgreSQL, die etwas tun. Aus dem Top wird jedoch nicht ersichtlich, was genau sie tun.

Daher müssen wir die Anfragen identifizieren, die die größte Belastung verursachen, da die Optimierung dieser Anfragen in der Regel mehr Vorteile bringt als die Optimierung der PostgreSQL-Konfiguration, des Betriebssystems oder sogar der Hardware. Nach meiner Einschätzung liegt dieser Gewinn bei etwa 80-85-90 %. Und das geht viel schneller. Es ist schneller, eine Anfrage zu optimieren, als die Konfiguration zu ändern, einen Neustart zu planen, insbesondere wenn die Datenbank nicht neu gestartet werden kann, oder zusätzliche Hardware hinzuzufügen. Es ist einfacher, eine Anfrage umzuformulieren oder einen Index hinzuzufügen, um bereits bessere Ergebnisse aus dieser Anfrage zu erzielen.
Dementsprechend müssen Anfragen und deren Angemessenheit überwacht werden. Nehmen wir ein weiteres Beispiel für das Monitoring. Auch hier gibt es ein ansprechendes Monitoring. Es sind Informationen zur Replikation vorhanden, Informationen zur Bandbreite, zu Blockierungen und zur Ressourcennutzung. Alles sieht gut aus, aber es fehlen Informationen zu den Anfragen. Unklar bleibt, welche Anfragen in unserer Datenbank ausgeführt werden, wie lange sie dauern und wie viele Anfragen es sind. Im Monitoring müssen wir diese Informationen immer vorliegen haben.

Für den Erhalt dieser Informationen können wir das Modul pg_stat_statements verwenden. Darauf basierend lassen sich verschiedenste Grafiken erstellen. Zum Beispiel können wir die Informationen zu den häufigsten Anfragen abrufen, also zu denjenigen Anfragen, die am häufigsten ausgeführt werden. Nach Deployments ist es ebenfalls sehr hilfreich, einen Blick darauf zu werfen und zu prüfen, ob es zu einem Anstieg der Anfragen gekommen ist.
Wir können auch die längsten Anfragen überwachen, also diejenigen, die am längsten ausgeführt werden. Diese beanspruchen die CPU und verbrauchen E/A-Ressourcen. Auch das können wir anhand der Felder total_time, mean_time, blk_write_time und blk_read_time bewerten.
Wir können die ressourcenintensivsten Anfragen bewerten und überwachen, insbesondere solche, die von der Festplatte lesen, mit dem Speicher arbeiten oder umgekehrt eine Schreiblast erzeugen.
Wir sind in der Lage, die großzügigsten Anfragen zu bewerten. Dies sind Anfragen, die eine große Menge an Zeilen zurückgeben. Zum Beispiel könnte das eine Anfrage sein, bei der man vergessen hat, ein Limit zu setzen, sodass sie einfach den gesamten Inhalt der Tabelle oder der angeforderten Tabellen zurückgibt.
Wir können auch Anfragen überwachen, die temporäre Dateien oder temporäre Tabellen verwenden.

Und da sind auch unsere Hintergrundprozesse zu beachten. Hintergrundprozesse sind in erster Linie Checkpoints, auch Kontrollpunkte genannt, sowie Autovacuum und Replikation.
Ein weiteres Beispiel für die Überwachung. Es gibt auf der linken Seite einen Reiter "Wartung", den wir aufrufen und hoffen, etwas Nützliches zu sehen. Aber hier gibt es nur die Betriebszeit des Vacuum und der Statistiksammlung, nichts weiter. Diese Informationen sind sehr spärlich, weshalb es immer wichtig ist zu wissen, wie unsere Hintergrundprozesse in der Datenbank arbeiten und ob es dabei zu Problemen kommt.

Wenn wir über Kontrollpunkte sprechen, sollten wir berücksichtigen, dass diese 'schmutzigen' Seiten aus dem shardierten Speicher auf die Festplatte geschrieben werden, bevor ein Kontrollpunkt erstellt wird. Dieser Kontrollpunkt kann dann als Ausgangspunkt für eine Wiederherstellung verwendet werden, falls PostgreSQL unerwartet beendet wird.
Um alle 'schmutzigen' Seiten auf die Festplatte zu schreiben, ist eine gewisse Menge an Schreibvorgängen erforderlich. In Systemen mit viel RAM kann das sehr viel sein. Wenn Kontrollpunkte in kurzen Abständen sehr häufig durchgeführt werden, kann dies die Festplattenleistung stark beeinträchtigen. Das führt dazu, dass Kundenanfragen unter Ressourcenmangel leiden. Sie werden um Ressourcen kämpfen und es wird an Leistung fehlen.
Über die pg_stat_bgwriter können wir die Anzahl der aufgetretenen Checkpoints anhand der angegebenen Felder überwachen. Wenn wir in einem bestimmten Zeitraum (z. B. 10-15-20 Minuten oder eine halbe Stunde) eine hohe Anzahl von Checkpoints verzeichnen, beispielsweise 3-4-5, könnte das bereits ein Problem darstellen. In diesem Fall sollten wir die Datenbank und die Konfiguration untersuchen, um herauszufinden, was diese Vielzahl an Checkpoints verursacht. Möglicherweise läuft eine große Schreiboperation. Anhand unserer Workload-Diagramme können wir die Situation bereits einschätzen, da wir diese Grafiken hinzugefügt haben. Wir können die Parameter für die Checkpoints entsprechend anpassen, um sicherzustellen, dass sie die Anfragen nicht negativ beeinflussen.

Ich komme erneut auf das Thema Autovacuum zurück, denn wie bereits erwähnt, kann es sowohl die Leistung der Festplatten als auch der Anfragen erheblich beeinträchtigen. Daher ist es immer wichtig, die Anzahl der Autovacuum-Läufe zu bewerten.
Die Anzahl der Autovacuum-Worker in der Datenbank ist begrenzt. Standardmäßig gibt es drei. Wenn also ständig drei Worker in der Datenbank aktiv sind, deutet das darauf hin, dass das Autovacuum nicht optimal konfiguriert ist. In diesem Fall sollten die Limits angehoben und die Autovacuum-Einstellungen überprüft werden.
Es ist wichtig zu bewerten, welche Vakuum-Worker bei uns aktiv sind. Entweder ist es ein vom Benutzer initiiertes Vakuum, das durch einen DBA manuell gestartet wurde und dadurch eine Last erzeugt hat, was zu einem Problem geführt hat. Oder es handelt sich um die Anzahl der Vakuum-Operationen, die den Transaktionszähler zurücksetzen. Für einige Versionen von PostgreSQL können diese Vakuum-Operationen sehr ressourcenintensiv sein, da sie die gesamte Tabelle lesen und alle Blöcke in dieser Tabelle scannen.
Und natürlich die Dauer der Vakuumprozesse. Wenn wir lange Vakuumprozesse haben, die sehr lange dauern, bedeutet das, dass wir die Vakuumkonfiguration erneut prüfen und möglicherweise anpassen sollten. Denn es kann zu einer Situation kommen, in der das Vakuum lange an einer Tabelle arbeitet (3-4 Stunden), aber in der Zwischenzeit sich wieder eine große Anzahl toter Zeilen in der Tabelle angesammelt hat. Sobald das Vakuum beendet ist, muss es diese Tabelle erneut verarbeiten. Das führt zu einem Zustand – einem endlosen Vakuum. In diesem Fall kann das Vakuum seine Aufgabe nicht erfüllen, und die Tabellen beginnen allmählich zu wachsen, obwohl das Volumen an nützlichen Daten gleich bleibt. Daher überprüfen wir bei langen Vakuumprozessen immer die Konfiguration und versuchen, sie zu optimieren, ohne die Leistung der Benutzeranfragen zu beeinträchtigen.

Aktuell gibt es kaum eine PostgreSQL-Installation, die keine Streaming-Replikation hat. Replikation ist der Prozess der Übertragung von Daten vom Master zur Replik.
Die Replikation in PostgreSQL erfolgt über das Transaktionsprotokoll. Der Master erstellt das Transaktionsprotokoll. Über eine Netzwerkverbindung wird das Protokoll an die Replik übertragen, wo es dann reproduziert wird. Ganz einfach.
Zur Überwachung des Replikationslag wird die Ansicht pg_stat_replication verwendet. Aber damit ist nicht alles einfach. In Version 10 wurde die Ansicht geändert. Erstens wurden einige Felder umbenannt. Zudem wurden einige Felder hinzugefügt. In der Version 10 sind Felder hinzugekommen, die die Einschätzung des Replikationslags in Sekunden ermöglichen. Das ist sehr praktisch. In Version 10 gab es auch weiterhin die Möglichkeit, den Lag in Bytes zu bewerten. Diese Möglichkeit besteht nach wie vor in Version 10, d. h. Sie können wählen, was Ihnen besser passt – den Lag in Bytes oder in Sekunden zu bewerten. Viele nutzen beides.
Um den Replikations-Lag zu bewerten, müssen wir jedoch die Journal-Position in der Transaktion kennen. Diese Positionen der Transaktionsjournale sind in der Ansicht pg_stat_replication enthalten. Mit der Funktion pg_xlog_location_diff() können wir sozusagen zwei Punkte im Transaktionsjournal festlegen, die Differenz zwischen ihnen berechnen und den Replikations-Lag in Bytes erhalten. Das ist sehr praktisch und einfach.
In der Version 10 wurde diese Funktion in pg_wal_lsn_diff() umbenannt. Generell wurde in allen Funktionen, Sichten und Tools, in denen das Wort „xlog“ vorkam, es durch „wal“ ersetzt. Dies gilt sowohl für Sichten als auch für Funktionen. Das ist eine solche Neuerung.
Außerdem wurden in der 10. Version spezifische Zeilen hinzugefügt, die den Lag anzeigen. Dazu gehören Write Lag, Flush Lag und Replay Lag. Es ist wichtig, diese Werte zu überwachen. Wenn wir sehen, dass es einen Replikations-Lag gibt, müssen wir untersuchen, warum er aufgetreten ist, woher er kommt und das Problem beheben.

Mit den Systemmetriken ist fast alles in Ordnung. Bei jedem Monitoring, das entsteht, beginnen wir mit den Systemmetriken. Dazu gehören die Auslastung von Prozessoren, Speicher, Swap, Netzwerk und Festplatte. Dennoch fehlen viele Parameter standardmäßig.
Wenn die Prozessnutzung in Ordnung ist, gibt es Probleme mit der Datenträgernutzung. Entwickler von Monitoring-Tools fügen in der Regel Informationen zur Bandbreite hinzu. Diese kann in IOPS oder Bytes angegeben werden. Doch sie vergessen oft die Latenz und die Auslastung der Speichergeräte. Dies sind entscheidende Parameter, die helfen zu beurteilen, wie stark unsere Festplatten belastet sind und wie stark sie verlangsamen. Wenn die Latenz hoch ist, bedeutet das, dass es Probleme mit den Festplatten gibt. Eine hohe Auslastung deutet darauf hin, dass die Festplatten überlastet sind. Diese Parameter sind qualitativ hochwertiger als die Bandbreite.
Obwohl diese Statistiken auch aus dem Dateisystem /proc abgerufen werden können, wie es bei der CPU-Auslastung der Fall ist. Warum diese Informationen nicht in Monitoring-Tools integriert werden, weiß ich nicht. Nichtsdestotrotz ist es wichtig, diese in deinem Monitoring zu haben.
Das Gleiche gilt für Netzwerkinterfaces. Es gibt Informationen zur Netzwerkbandbreite in Paketen oder Bytes, aber es fehlen Informationen zur Latenz und zur Auslastung, obwohl diese ebenfalls nützlich wären.

Jede Überwachung hat ihre Schwächen. Egal, welches Monitoring Sie auswählen, es wird immer gewissen Kriterien nicht gerecht werden. Dennoch entwickeln sie sich weiter, neue Funktionen und Features kommen hinzu. Wählen Sie also etwas aus und passen Sie es an.
Um Anpassungen vorzunehmen, ist es wichtig, stets zu verstehen, was die übermittelten Statistiken bedeuten und wie man sie zur Problemlösung nutzen kann.
Hier sind einige Schlüsselüberlegungen:
- Die Verfügbarkeit sollte stets überwacht werden, und Dashboards sind notwendig, damit Sie schnell erkennen können, ob die Datenbank in Ordnung ist.
- Es ist wichtig zu wissen, welche Kunden mit Ihrer Datenbank interagieren, um schlechte Kunden auszuschließen.
- Es ist entscheidend zu bewerten, wie diese Kunden mit den Daten umgehen. Ein klares Bild über Ihre Arbeitslast ist notwendig.
- Es ist wichtig zu analysieren, wie sich diese Arbeitslast zusammensetzt und welche Anfragen dies beeinflussen. Sie können Anfragen bewerten, optimieren, refaktorisieren und Indizes für sie erstellen. Das ist von großer Bedeutung.
- Hintergrundprozesse können negative Auswirkungen auf Kundenanfragen haben, weshalb es wichtig ist, sicherzustellen, dass sie nicht zu viele Ressourcen beanspruchen.
- Systemmetriken ermöglichen es Ihnen, Skalierungspläne zu erstellen und die Kapazität Ihrer Server zu erhöhen. Daher ist es wichtig, sie ebenfalls zu verfolgen und zu bewerten.

Wenn Sie sich für dieses Thema interessieren, können Sie diese Links durchsehen.
— dies ist die offizielle Dokumentation mit den Statistiksammlern. Dort finden Sie eine Beschreibung aller statistischen Ansichten sowie der entsprechenden Felder. Sie können diese lesen, verstehen und analysieren, um basierend darauf eigene Grafiken zu erstellen und Ihr Monitoring zu erweitern.
Beispiele für Anfragen:
Dies ist unser unternehmensinterner und mein eigener Repository. Dort gibt es Beispiele für Anfragen. Es sind keine Abfragen wie "select * from irgendetwas" enthalten. Stattdessen sind bereits fertige Anfragen mit Joins und interessanten Funktionen vorhanden, die es ermöglichen, aus Rohdaten lesbare und nützliche Werte abzuleiten, wie z. B. Bytes oder Zeit. Sie können diese untersuchen, analysieren und in Ihr Monitoring integrieren, um eigene Monitoring-Lösungen darauf aufzubauen.
Fragen
Frage: Sie haben gesagt, dass Sie keine Marken bewerben werden, aber ich bin dennoch neugierig – welche Dashboards verwenden Sie in Ihren Projekten?
Antwort: Das ist unterschiedlich. Manchmal kommen wir zu einem Kunden, der bereits sein eigenes Monitoring hat. Wir beraten den Kunden dann, was er in sein Monitoring hinzufügen sollte. Besonders schwierig sind die Dinge mit Zabbiх. Denn dort gibt es keine Möglichkeit, TopN-Diagramme zu erstellen. Wir selbst nutzen , weil wir diese Jungs im Bereich Monitoring beraten haben. Sie haben das Monitoring für PostgreSQL basierend auf unserem Lastenheft erstellt. Ich arbeite an meinem eigenen pet-project, das Daten über Prometheus sammelt und diese in . Mein Ziel ist es, in Prometheus meinen eigenen Exporter zu erstellen und alles dann in Grafana darzustellen.
Frage: Gibt es Analogien zu AWR-Berichten oder … Aggregationen? Wissen Sie darüber etwas?
Antwort: Ja, ich weiß, was AWR ist, das ist eine großartige Sache. Zurzeit gibt es verschiedene Lösungen, die ein ähnliches Modell umsetzen. In bestimmten Zeitintervallen werden einige Baselines in dasselbe PostgreSQL oder in ein separates Speicherformat geschrieben. Man kann sie im Internet suchen, sie sind verfügbar. Einer der Entwickler einer solchen Lösung ist im Forum sql.ru in der PostgreSQL-Diskussion aktiv. Dort kann man ihn erreichen. Ja, solche Lösungen gibt es, sie können genutzt werden. Zudem in meiner Ich arbeite auch an einem Tool, das dasselbe ermöglicht.
P.S.1 Wenn Sie postgres_exporter verwenden, welches Dashboard verwenden Sie? Es gibt mehrere. Einige davon sind bereits veraltet. Könnte die Community ein aktualisiertes Template erstellen?
P.S.2 Ich habe pganalyze entfernt, da es sich um ein proprietäres SaaS-Angebot handelt, das auf Leistungsüberwachung und automatisierte Anpassungsvorschläge fokussiert ist.
Nur registrierte Benutzer können an der Umfrage teilnehmen. Sind Sie an Contour interessiert?
Welches selbstgehostete Monitoring für PostgreSQL (mit Dashboard) halten Sie für das beste?
30,0%Zabbix + Erweiterungen von Alexey Lesovsky oder zabbix 4.4 oder libzbxpgsql + zabbix libzbxpgsql + zabbix3
0,0%https://github.com/lesovsky/pgcenter0
0,0%https://github.com/pg-monz/pg_monz0
20,0%https://github.com/cybertec-postgresql/pgwatch22
20,0%https://github.com/postgrespro/mamonsu2
0,0%https://www.percona.com/doc/percona-monitoring-and-management/conf-postgres.html0
10,0%pganalyze ist ein proprietäres SaaS – ich kann es nicht entfernen.
10,0%https://github.com/powa-team/powa1
0,0%https://github.com/darold/pgbadger0
0,0%https://github.com/darold/pgcluu0
0,0%https://github.com/zalando/PGObserver0
10,0%https://github.com/spotify/postgresql-metrics1
10 Benutzer haben abgestimmt. 26 Benutzer haben sich enthalten.
Quelle: habr.com
