


In diesem Frühling haben wir bereits einige Einführungsthemen besprochen, wie zum Beispiel und . In dem zweiten Artikel haben wir sogar versprochen, die Leistung verschiedener Multi-Disk-Topologien in ZFS weiter zu untersuchen. Dies ist ein Next-Generation-Dateisystem, das derzeit überall implementiert wird: von bis zu .
Nun, heute ist der perfekte Tag, um ZFS kennenzulernen, neugierige Leser. Seien Sie sich nur bewusst, dass, laut Schätzung des Entwicklers von OpenZFS, Matt Arens, „es wirklich komplex ist“.
Aber bevor wir zu den Zahlen kommen – und die werden kommen, das verspreche ich – müssen wir über das sprechen, als wie ZFS Daten auf dem Laufwerk speichert.
Zpool, vdev und device
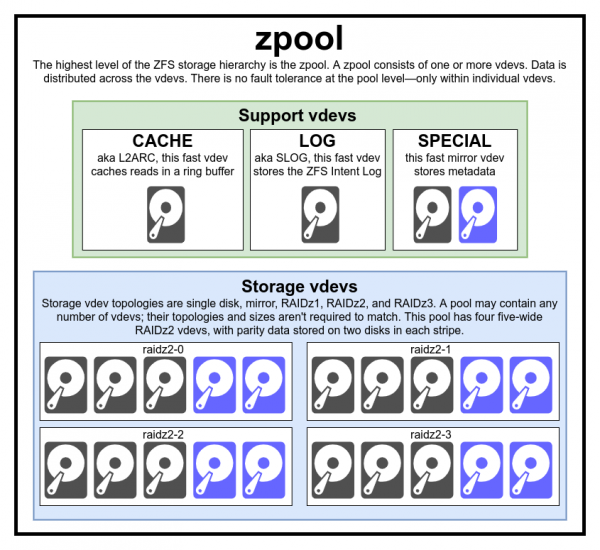
Dieses Diagramm des gesamten Pools umfasst drei Hilfs-vdevs, jeweils eines jeder Klasse, und vier für RAIDz2

Normalerweise gibt es keinen Grund, einen Pool aus unterschiedlichen Typen und Größen von vdev zu erstellen – aber wenn Sie möchten, steht Ihnen nichts im Wege.
Um das Dateisystem ZFS wirklich zu verstehen, ist es wichtig, seine tatsächliche Struktur genauer zu betrachten. Zunächst einmal vereint ZFS traditionelle Ebenen der Volumenverwaltung und des Dateisystems. Außerdem verwendet es einen transaktionalen Mechanismus zum Copy-on-Write. Diese Merkmale bedeuten, dass sich das System strukturell erheblich von herkömmlichen Dateisystemen und RAID-Arrays unterscheidet. Die ersten grundlegenden Bausteine für das Verständnis sind: der Storage-Pool (zpool), das virtuelle Gerät (vdev) und das physische Gerät (device).
zpool
Der Storage-Pool zpool ist die oberste Struktur von ZFS. Jeder Pool enthält ein oder mehrere virtuelle Geräte. Diese wiederum enthalten ein oder mehrere physische Geräte (device). Virtuelle Pools sind eigenständige Einheiten. Ein physischer Computer kann zwei oder mehr separate Pools enthalten, die jedoch vollständig unabhängig voneinander sind. Pools können keine virtuellen Geräte gemeinsam nutzen.
Die Redundanz von ZFS erfolgt auf der Ebene der virtuellen Geräte und nicht auf der Ebene der Pools. Auf der Pool-Ebene gibt es keinerlei Redundanz – wenn ein vdev-Speichergerät oder ein spezielles vdev verloren geht, geht der gesamte Pool ebenfalls verloren.
Moderne Storage-Pools können den Verlust des Caches oder des Journals eines virtuellen Geräts überstehen – sie können jedoch eine kleine Menge an nicht gespeicherten Daten verlieren, wenn sie das vdev-Journal während eines Stromausfalls oder Systemausfalls verlieren.
Ein weit verbreitetes Missverständnis ist, dass die 'Datenstreifen' (Striping) von ZFS über den gesamten Pool verteilt werden. Das ist falsch. Zpool ist keineswegs ein unterhaltsamer RAID0, es ist eher ein unterhaltsames mit einem komplexen, variablen Verteilungsmechanismus.
Im Wesentlichen werden die Schreibvorgänge gleichmäßig auf die verfügbaren virtuellen Geräte verteilt, basierend auf dem verfügbaren Speicherplatz. Theoretisch werden alle gleichzeitig belegt. In neueren Versionen von ZFS wird die aktuelle Auslastung (Utilisation) der vdev berücksichtigt – falls ein virtuelles Gerät wesentlich stärker belastet ist als ein anderes (z. B. aufgrund von Lesevorgängen), wird es vorübergehend für Schreibvorgänge übersprungen, selbst wenn es den höchsten freien Speicherplatz aufweist.
Der in moderne ZFS-Schreibstrategien integrierte Mechanismus zur Ermittlung der Auslastung kann die Latenz verringern und die Durchsatzrate während Zeiten ungewöhnlich hoher Belastung erhöhen – jedoch ist das nicht. Blankoscheck für das unbeabsichtigte Mischen von langsamen HDDs und schnellen SSDs in einem Pool. Ein solch unausgewogener Pool wird stets mit der Geschwindigkeit des langsamsten Geräts arbeiten, als ob er vollständig aus diesen Geräten zusammengesetzt wäre.
vdev
Jeder Speicherpool besteht aus einem oder mehreren virtuellen Geräten (virtual device, vdev). Jedes vdev umfasst wiederum eines oder mehrere physische Geräte. Die meisten virtuellen Geräte dienen der einfachen Datenspeicherung, aber es gibt mehrere unterstützende vdev-Klassen, einschließlich CACHE, LOG und SPECIAL. Jeder dieser vdev-Typen kann eine von fünf Topologien aufweisen: Einzelgerät (single-device), RAIDz1, RAIDz2, RAIDz3 oder Spiegelung (mirror).
RAIDz1, RAIDz2 und RAIDz3 sind spezielle Varianten dessen, was man früher als RAID mit doppelter (diagonaler) Parität bezeichnete. 1, 2 und 3 beziehen sich darauf, wie viele Paritätsblöcke für jedes Datenband bereitgestellt werden. Anstelle von einzelnen Festplatten zur Bereitstellung der Parität verteilen die virtuellen RAIDz-Geräte diese Parität gleichmäßig über die Festplatten. Ein RAIDz-Array kann so viele Festplatten verlieren, wie es Paritätsblöcke gibt; wenn eine weitere ausfällt, wird es inkompatibel und nimmt den Speicherpool mit sich.
In spiegelnden virtuellen Geräten (mirror vdev) wird jeder Block auf jedem Gerät im vdev gespeichert. Während die am häufigsten verwendeten Doppelspiegel (two-wide) sind, kann in einem Spiegel eine beliebige Anzahl von Geräten vorhanden sein – in größeren Installationen werden häufig dreifache Spiegel verwendet, um die Leseleistung und die Ausfallsicherheit zu erhöhen. Ein vdev-Spiegel kann jeden Ausfall überstehen, solange mindestens ein Gerät im vdev weiter funktioniert.
Einzelne vdevs sind von Natur aus gefährlich. Ein solches virtuelles Gerät übersteht keinen einzigen Ausfall – und wenn es als Speicher oder als spezieller vdev verwendet wird, führt sein Ausfall zur Zerstörung des gesamten Pools. Seien Sie hier äußerst vorsichtig.
Virtuelle Geräte wie CACHE, LOG und SPECIAL können in jeder der oben genannten Topologien erstellt werden – aber bedenken Sie, dass der Verlust eines virtuellen Geräts SPECIAL den Verlust des gesamten Pools bedeutet, daher wird eine redundante Topologie dringend empfohlen.
device
Wahrscheinlich ist dies der einfachste Begriff in ZFS – es ist buchstäblich ein Blockgerätespeicher. Denken Sie daran, dass virtuelle Geräte aus einzelnen Geräten bestehen und ein Pool aus virtuellen Geräten besteht.
Festplatten – egal ob magnetisch oder flashbasierend – sind die am häufigsten verwendeten Blockgeräte, die als Bausteine für vdev dienen. Aber jedes Gerät mit einem Deskriptor in /dev passt – sodass auch ganze hardwarebasierte RAID-Systeme als einzelne Geräte verwendet werden können.
Eine einfache Raw-Datei ist eines der wichtigsten alternativen Blockgeräte, aus denen ein vdev aufgebaut werden kann. Testpools aus sind eine sehr praktische Möglichkeit, um Befehle des Pools zu testen und zu sehen, wie viel Speicher im Pool oder im virtuellen Gerät dieser Topologie verfügbar ist.
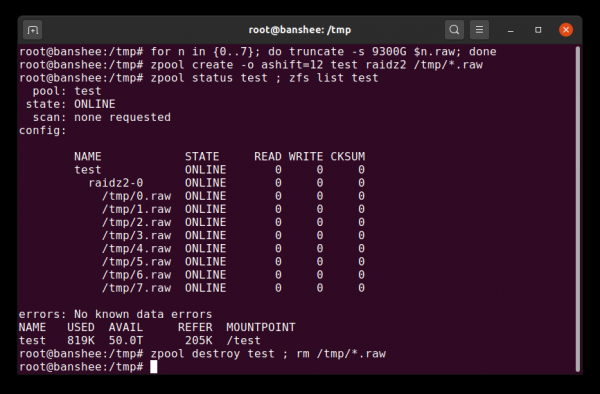
Sie können innerhalb von Sekunden einen Testpool aus Sparse-Dateien erstellen – aber vergessen Sie nicht, den gesamten Pool und seine Komponenten anschließend zu löschen.
Angenommen, Sie möchten einen Server mit acht Festplatten einrichten und planen, 10 TB (~9300 GiB) große Festplatten zu verwenden, sind sich jedoch nicht sicher, welche Topologie am besten zu Ihren Anforderungen passt. In dem obigen Beispiel erstellen wir in nur wenigen Sekunden einen Testpool aus dünn provisionierten Dateien – und jetzt wissen wir, dass ein RAIDz2 vdev aus acht Festplatten mit 10 TB eine nutzbare Kapazität von 50 TiB bietet.
Eine weitere spezielle Geräteklasse sind SPARE (Ersatzgeräte). Hot-Swap-Geräte gehören, im Gegensatz zu normalen Geräten, dem gesamten Pool an und nicht einem einzelnen virtuellen Gerät. Wenn ein vdev im Pool ausfällt und ein Ersatzgerät mit dem Pool verbunden und verfügbar ist, wird es automatisch mit dem betroffenen vdev verbunden.
Nachdem das Ersatzgerät mit dem betroffenen vdev verbunden ist, beginnt es, Kopien oder Rekonstruktionen der Daten zu empfangen, die auf dem fehlenden Gerät sein sollten. Dies wird in traditionellem RAID als Wiederherstellung (rebuilding) bezeichnet, während es in ZFS als „Wiederherstellung von Redundanz“ (resilvering) bekannt ist.
Es ist wichtig zu beachten, dass Ersatzgeräte nicht dauerhaft defekte Geräte ersetzen. Sie dienen nur als vorübergehende Lösung, um die Zeit zu verkürzen, in der eine vdev-Abwertung stattfindet. Nachdem der Administrator das defekte vdev-Gerät ersetzt hat, wird die Redundanz wieder auf das permanente Gerät hergestellt, während das SPARE von der vdev getrennt und wieder als Reserve im gesamten Pool verwendet wird.
Datensätze, Blöcke und Sektoren
Der nächste Block in unserer Erkundung von ZFS betrifft nicht so sehr die Hardware, sondern wie die Daten selbst organisiert und gespeichert werden. Hier überspringen wir einige Ebenen – wie den Metaslab – um Überladungen zu vermeiden und den Überblick über die Gesamtstruktur zu behalten.
Datensatz (dataset)
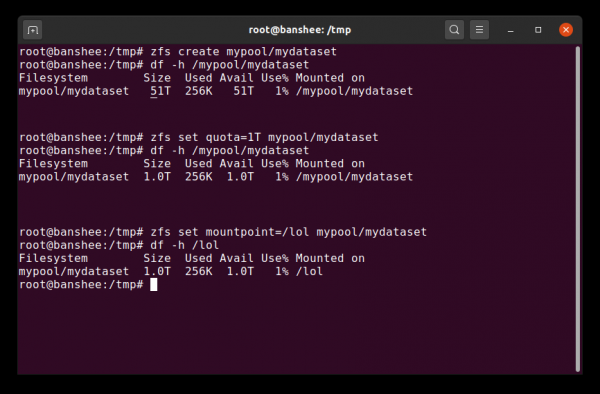
Wenn wir einen Datensatz erstellen, zeigt dieser den gesamten verfügbaren Speicherplatz im Pool an. Dann setzen wir ein Quota und ändern den Einhängepunkt. Voilà!
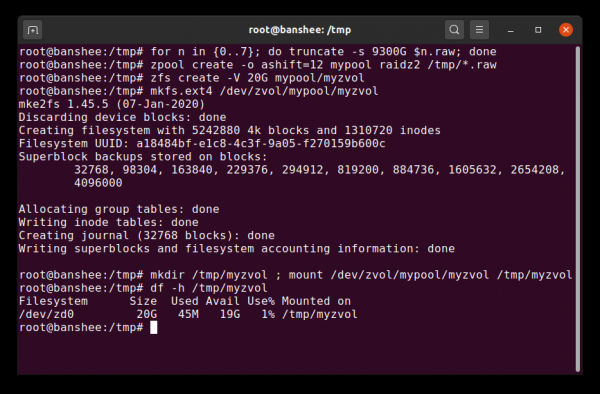
Zvol ist im Wesentlichen ein Datensatz ohne seine Dateisystemschicht, die wir hier durch ein ganz normales Dateisystem wie ext4 ersetzen.
Ein ZFS-Datensatz ist in etwa mit einem standardmäßigen gemounteten Dateisystem vergleichbar. Wie bei einem gewöhnlichen Dateisystem scheint er auf den ersten Blick „einfach nur ein weiterer Ordner“ zu sein. Aber auch wie bei herkömmlichen gemounteten Dateisystemen hat jeder ZFS-Datensatz seine eigenen grundlegenden Eigenschaften.
Zunächst kann einem Datensatz ein festgelegtes Kontingent zugewiesen werden. Wenn Sie zfs set quota=100G poolname/datasetnamefestlegen, können Sie nicht mehr als /poolname/datasetname 100 GiB in den gemounteten Ordner schreiben.
Haben Sie die Präsenz – und Abwesenheit – von Schrägstrichen am Anfang jeder Zeile bemerkt? Jeder Datensatz hat seinen eigenen Platz sowohl in der ZFS-Hierarchie als auch in der Hierarchie des System-Managements. In der ZFS-Hierarchie gibt es keinen führenden Schrägstrich – Sie beginnen mit dem Poolnamen und dann dem Pfad von einem Datensatz zum nächsten. Zum Beispiel: pool/parent/child für einen Datensatz mit dem Namen child unter dem übergeordneten Datensatz parent in einem Pool mit dem kreativen Namen pool.
Standardmäßig entspricht der Mount-Punkt eines Datensatzes seinem Namen in der ZFS-Hierarchie, beginnend mit einem Schrägstrich – der Pool mit dem Namen pool wird als /poolgemountet, der Datensatz parent wird in /pool/parentgemountet und der untergeordnete Datensatz child wird in /pool/parent/child. Aber der System-Mountpunkt des Datensatzes kann geändert werden.
Wenn wir angeben, zfs set mountpoint=/lol pool/parent/child, dann wird der Datensatz pool/parent/child im System als /lol.
Zusätzlich zu Datensätzen sollten wir Volumes (zvols) erwähnen. Ein Volume ist ungefähr vergleichbar mit einem Datensatz, wobei es jedoch tatsächlich kein Dateisystem hat – es handelt sich einfach um ein Blockgerät. Sie können beispielsweise ein zvol mit dem Namen mypool/myzvol, erstellen, es dann mit einem ext4-Dateisystem formatieren und dieses Dateisystem dann einhängen – jetzt haben Sie ein ext4-Dateisystem, jedoch mit Unterstützung für alle Sicherheitsfunktionen von ZFS! Das mag auf einem Computer seltsam erscheinen, macht jedoch viel mehr Sinn als Backend bei der Exportierung eines iSCSI-Geräts.
Blöcke
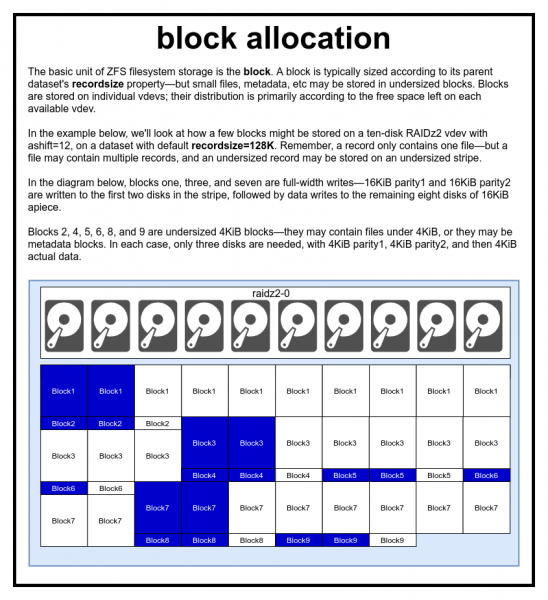
Eine Datei wird durch einen oder mehrere Blöcke dargestellt. Jeder Block wird auf einem virtuellen Gerät gespeichert. Die Blockgröße entspricht normalerweise dem Parameter recordsize, kann jedoch auf 2^ashiftverringert werden, wenn er Metadaten oder eine kleine Datei enthält.

Wir meinen es wirklich ernst, gibt es wirklich wenn wir vom enormen Leistungsdefizit sprechen, das entsteht, wenn der ashift zu klein eingestellt wird.
Im ZFS-Pool werden alle Daten, einschließlich Metadaten, in Blöcken gespeichert. Die maximale Blockgröße für jedes Dataset wird im Property festgelegt. recordsize (Recordgröße). Die Recordgröße kann sich ändern, jedoch beeinflusst dies nicht die Größe oder Position von bereits in das Dataset geschriebenen Blöcken – sie gilt nur für neue Blöcke, die beim Schreiben erstellt werden.
Sofern nicht anders festgelegt, beträgt die aktuelle Standard-Recordgröße 128 KiB. Dies stellt einen gewissen Kompromiss dar, bei dem die Leistung in den meisten Fällen weder ideal noch katastrophal sein wird. Recordsize kann auf jeden Wert von 4K bis 1M eingestellt werden (mit zusätzlichen Anpassungen recordsize kann sogar noch höher eingestellt werden, was jedoch selten eine gute Idee ist).
Jeder Block verweist nur auf die Daten einer einzigen Datei – Sie können nicht zwei verschiedene Dateien in einen Block quetschen. Jede Datei besteht aus einem oder mehreren Blöcken, abhängig von der Größe. Wenn die Größe der Datei kleiner als die Recordgröße ist, wird sie in einem kleineren Block gespeichert – beispielsweise belegt eine 2 KiB Datei im Block nur einen Sektor von 4 KiB auf der Festplatte.
Wenn die Datei groß genug ist und mehrere Blöcke benötigt, haben alle Einträge mit dieser Datei die Größe recordsize — einschließlich des letzten Eintrags, dessen Hauptteil ungenutzter Speicherplatz sein kann. .
Zvols haben keine Eigenschaft recordsize — stattdessen besitzen sie eine äquivalente Eigenschaft volblocksize.
Sektoren
Der letzte, grundlegende Baustein ist der Sektor. Dies ist die kleinste physische Einheit, die von einem Speichergerät geschrieben oder gelesen werden kann. Jahrzehntelang wurden in den meisten Festplatten 512-Byte-Sektoren verwendet. In letzter Zeit sind die meisten Festplatten auf 4 KiB-Sektoren konfiguriert, und in einigen – insbesondere SSDs – sind sogar 8 KiB oder noch größere Sektoren zu finden.
Im ZFS-System gibt es eine Eigenschaft, die es ermöglicht, die Sektorgröße manuell festzulegen. Diese Eigenschaft ashift. Es ist etwas verwirrend, dass ashift eine Potenz von zwei ist. Zum Beispiel, ashift=9 bedeutet eine Sektorgröße von 2^9 oder 512 Byte.
ZFS fordert vom Betriebssystem detaillierte Informationen zu jedem Blockgerät an, wenn es einem neuen vdev hinzugefügt wird, und stellt theoretisch ashift automatisch korrekt auf Basis dieser Informationen ein. Leider lügen viele Festplatten über ihre Sektorgröße, um die Kompatibilität mit Windows XP zu wahren, das nicht in der Lage war, Festplatten mit anderen Sektorgrößen zu verstehen.
Das bedeutet, dass ZFS-Administratoren dringend den tatsächlichen Sektorgrößen ihrer Geräte bekannt sein sollten und diese manuell einstellen müssen. ashift. Wenn ein zu kleiner ashift eingestellt wird, erhöht sich astronomisch die Anzahl der Lese- und Schreibvorgänge. Das bedeutet, dass die Schreiboperation für 512-Byte-'Sektoren' in einen echten 4 KiB-Sektor erfordert, zuerst den ersten 'Sektor' zu schreiben, dann den 4 KiB-Sektor zu lesen, ihn mit dem zweiten 512-Byte-'Sektor' zu verändern, zurück in den neuen 4 KiB-Sektor zu schreiben und so weiter für jede Aufzeichnung.
In der realen Welt betrifft dieser Strafe insbesondere SSDs von Samsung EVO, bei denen ashift=13gilt, jedoch lügen diese SSDs über ihre Sektorgröße, weshalb standardmäßig eingestellt wird. ashift=9. Wenn ein erfahrener Systemadministrator diese Einstellung nicht ändert, funktioniert dieses SSD langsamer als ein herkömmliches magnetisches HDD.
Im Vergleich dazu gibt es für zu große Größen ashift praktisch keine Strafe. Es gibt keine spürbare Leistungsminderung, und der Anstieg des ungenutzten Speicherplatzes ist unendlich gering (oder null, wenn die Kompression aktiviert ist). Daher empfehlen wir dringend, selbst für solche Festplatten, die tatsächlich 512-Byte-Sektoren nutzen, die Einstellung ashift=12 oder sogar ashift=13, um mit Zuversicht in die Zukunft zu blicken.
Die Eigenschaft ashift wird für jedes virtuelle vdev-Gerät festgelegt, und nicht für den Pool, wie viele fälschlicherweise denken – und kann nach der Festlegung nicht mehr geändert werden. Wenn Sie versehentlich ashift bei der Hinzufügung eines neuen vdev zum Pool verwirrt wurden, haben Sie diesen Pool unwiderruflich mit einem Gerät mit niedriger Leistung kontaminiert, und in der Regel gibt es keinen anderen Ausweg, als den Pool zu löschen und von vorne zu beginnen. Selbst das Entfernen des vdev wird nicht von einer fehlerhaften Einstellung befreien. ashift!
Der Schreibmechanismus
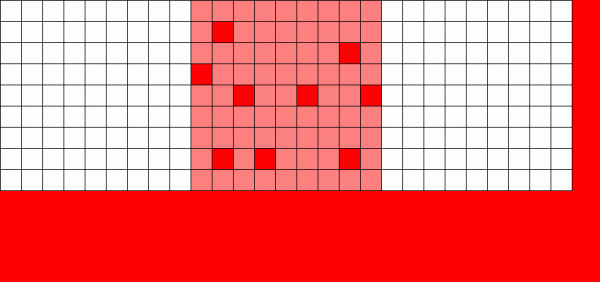
Wenn ein herkömmliches Dateisystem Daten überschreiben muss – ändert es jeden Block dort, wo er sich befindet.
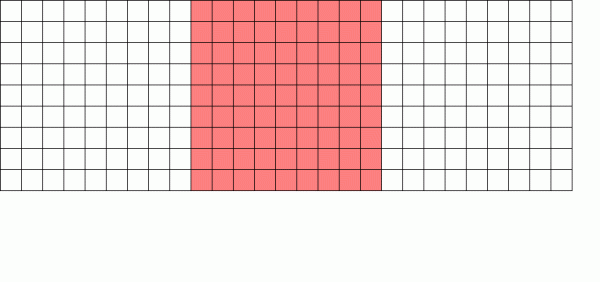
Das Copy-on-Write-Dateisystem speichert eine neue Version des Blocks und entsperrt dann die alte Version.

Im abstrakten Sinne, wenn man die tatsächliche physische Anordnung der Blöcke ignoriert, vereinfacht sich unser ‚Datenkomet‘ zu einem ‚Datenwurm‘, der von links nach rechts über die Karte des verfügbaren Raums bewegt.

Jetzt haben wir ein gutes Verständnis dafür, wie Copy-on-Write-Snapshots funktionieren – jeder Block kann mehreren Snapshots zugeordnet werden und bleibt bestehen, bis alle zugehörigen Snapshots gelöscht werden.
Der Copy-on-Write-Mechanismus (CoW) ist das Fundament dessen, was ZFS zu einem so beeindruckenden System macht. Das Grundkonzept ist einfach – wenn Sie ein traditionelles Dateisystem bitten, eine Datei zu ändern, wird es genau das tun, was Sie verlangen. Wenn Sie jedoch ein Copy-on-Write-Dateisystem bitten, dasselbe zu tun, wird es ‚Okay‘ sagen – aber Sie anlügen.
Stattdessen speichert das Copy-on-Write-Dateisystem eine neue Version des geänderten Blocks und aktualisiert dann die Metadaten der Datei, um die Verbindung zum alten Block zu trennen und den gerade geschriebenen neuen Block zu verknüpfen.
Das Trennen des alten Blocks und das Verknüpfen des neuen Blocks erfolgt in einem einzigen Vorgang, weshalb dieser nicht unterbrochen werden kann – wenn Sie die Stromversorgung nach Abschluss dieser Operation unterbrechen, haben Sie eine neue Version der Datei; wenn Sie vorher die Stromversorgung abstellen, haben Sie die alte Version. In jedem Fall entstehen in der Dateisystemstruktur keine Konflikte.
Das Copy-on-Write in ZFS erfolgt nicht nur auf der Ebene des Dateisystems, sondern auch auf der Ebene der Festplattenverwaltung. Das bedeutet, dass ZFS nicht unter einem Schreibfehler leidet () – einem Phänomen, bei dem der Stripe nur teilweise vor dem Systemausfall geschrieben werden konnte, was zu Beschädigungen des Arrays nach dem Neustart führt. Hier wird der Stripe atomar geschrieben, das vdev ist immer konsistent, und .
ZIL: ZFS Intent Log
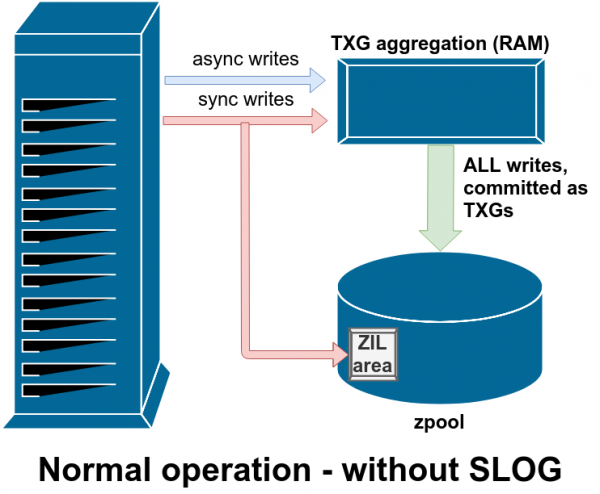
Das ZFS-System behandelt synchronisierte Schreibvorgänge auf spezielle Weise – es speichert sie vorübergehend, jedoch sofort im ZIL, bevor sie zusammen mit asynchronen Schreibvorgängen später dauerhaft geschrieben werden.
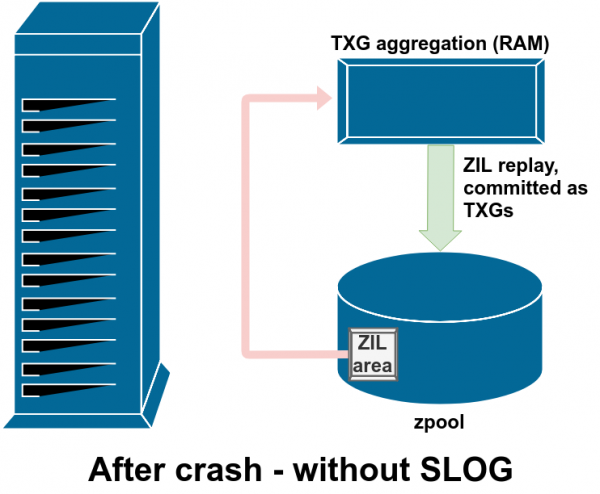
Normalerweise werden die im ZIL gespeicherten Daten nach der Speicherung nie wieder abgerufen. Dies ist jedoch nach einem Systemausfall möglich.
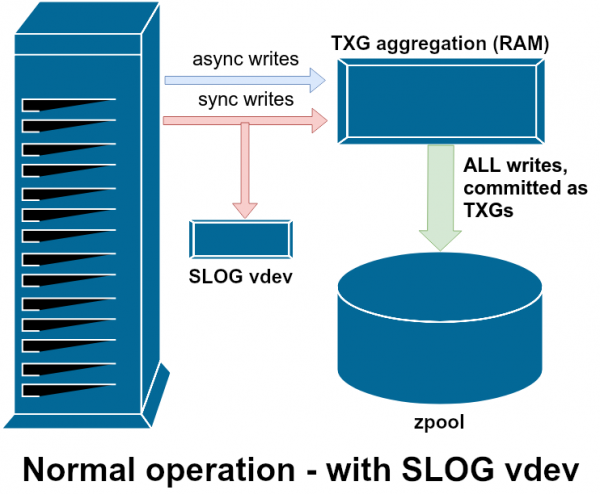
SLOG, oder sekundäres LOG-Gerät, ist einfach ein spezielles – und idealerweise sehr schnelles – vdev, wo das ZIL separat vom Hauptspeicher gespeichert werden kann.
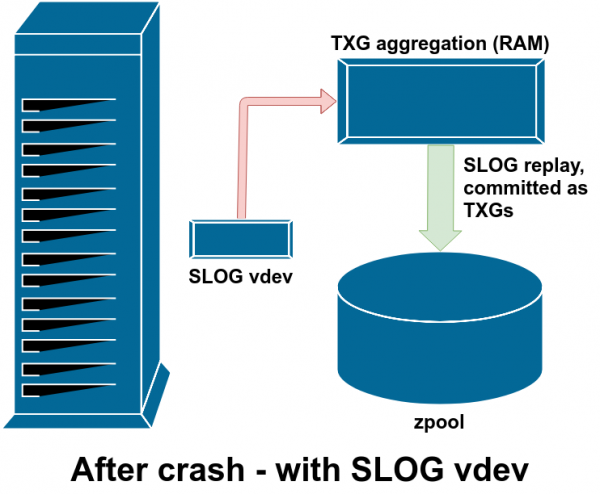
Nach einem Ausfall werden alle verschmutzten Daten im ZIL wiederhergestellt – in diesem Fall befindet sich das ZIL auf dem SLOG, sodass sie genau von dort wiederhergestellt werden.
Es gibt zwei Hauptkategorien von Schreiboperationen – synchron (sync) und asynchron (async). Für die meisten Workloads sind überwiegend asynchrone Schreibvorgänge – das Dateisystem erlaubt es, diese zu aggregieren und gepackt auszugeben, was die Fragmentierung reduziert und die Bandbreite signifikant erhöht.
Synchronisierte Schreibvorgänge sind eine ganz andere Angelegenheit. Wenn eine Anwendung eine synchronisierte Schreiboperation anfordert, sagt sie dem Dateisystem: 'Du musst dies im nichtflüchtigen Speicher festhalten.' jetzt sofort, und bis dahin kann ich nichts weiter tun.” Daher müssen die synchronen Schreibvorgänge sofort auf der Festplatte festgehalten werden – und wenn das die Fragmentierung erhöht oder die Bandbreite verringert, sei es so.
ZFS behandelt synchrone Schreibvorgänge anders als herkömmliche Dateisysteme – anstatt sie sofort in den regulären Speicher zu schreiben, speichert ZFS sie in einem speziellen Speicherbereich, der als ZFS Intent Log (ZIL) bekannt ist. Der Trick dabei ist, dass diese Einträge auch im Speicher bleiben, während sie zusammen mit den regulären asynchronen Schreibanforderungen aggregiert werden, um später als völlig normale TXG (Transaction Groups) in den Speicher geschrieben zu werden.
Im normalen Betriebsmodus wird das ZIL geschrieben und nie wieder gelesen. Wenn nach wenigen Augenblicken die Einträge aus dem ZIL im regulären TXG aus dem RAM in den Hauptspeicher geschrieben werden, werden sie vom ZIL getrennt. Das einzige Mal, dass etwas aus dem ZIL gelesen wird, ist beim Import eines Pools.
Wenn ein ZFS-Fehler auftritt – sei es ein Betriebssystemausfall oder ein Stromausfall – und es sich im ZIL Daten befinden, werden diese Daten beim nächsten Import des Pools (z.B. beim Neustart des fehlerhaften Systems) gelesen. Alles, was sich im ZIL befindet, wird gelesen, in TXG-Gruppen zusammengefasst, im Hauptspeicher gespeichert und dann im Importprozess vom ZIL abgetrennt.
Eine der Hilfsklassen von vdev wird als LOG oder SLOG bezeichnet, ein sekundäres LOG-Gerät. Es hat die Aufgabe, dem Pool ein separates und idealerweise viel schnelleres vdev-Gerät mit einer sehr hohen Schreibbeständigkeit für die Speicherung des ZIL zur Verfügung zu stellen, anstatt das ZIL im Hauptspeicher des vdev zu speichern. Das ZIL verhält sich unabhängig vom Speicherort gleich, aber wenn das vdev mit LOG eine sehr hohe Schreibgeschwindigkeit hat, werden die synchronen Schreibvorgänge schneller erfolgen.
Das Hinzufügen eines vdev mit LOG zu einem Pool kann die Leistung von asynchronen Schreibvorgängen nicht verbessern – selbst wenn Sie alle Schreibvorgänge im ZIL mit Hilfe von, sie werden dennoch ebenso wie ohne Protokoll an den Hauptspeicher in TXG gebunden sein und im selben Tempo arbeiten. Die einzige direkte Leistungsverbesserung ist die Verzögerung der synchronen Schreibvorgänge (da eine höhere Protokollgeschwindigkeit die Ausführung von Vorgängen beschleunigt) sync).
In einer Umgebung, die bereits eine große Anzahl synchroner Schreibvorgänge erfordert, kann vdev LOG indirekt die asynchrone Schreibgeschwindigkeit und nicht zwischengespeicherte Lesegeschwindigkeit erhöhen. Das Auslagern von ZIL-Einträgen in einen separaten vdev LOG bedeutet weniger Konkurrenz um IOPS im primären Speicher, was die Leistung aller Lese- und Schreibvorgänge in gewissem Maße steigert.
Snapshots
Der Schreibvorgangsspeichermechanismus ist auch eine notwendige Grundlage für atomare ZFS-Snapshots und inkrementelle asynchrone Replikation. In einem aktiven Dateisystem gibt es einen Zeigerbaum, der alle Einträge mit aktuellen Daten markiert – wenn Sie einen Snapshot erstellen, machen Sie einfach eine Kopie dieses Zeigerbaums.
Wenn in einem aktiven Dateisystem ein Eintrag überschrieben wird, schreibt ZFS zuerst eine neue Version des Blocks in ungenutzten Speicherplatz. Danach trennt es die alte Version des Blocks vom aktuellen Dateisystem. Sollte jedoch ein Snapshot auf den alten Block verweisen, bleibt dieser unverändert. Der alte Block wird tatsächlich nicht als freier Speicher wiederhergestellt, bis alle Snapshots, die auf diesen Block verweisen, gelöscht sind!
Replikation
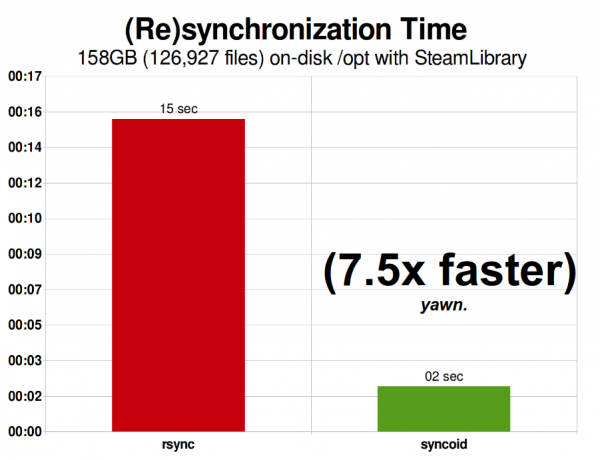
Meine Steam-Bibliothek nahm 2015 158 GiB ein und umfasste 126.927 Dateien. Das ist ziemlich nah an der optimalen Situation für rsync – die ZFS-Replikation über das Netzwerk war „nur“ 750 % schneller.
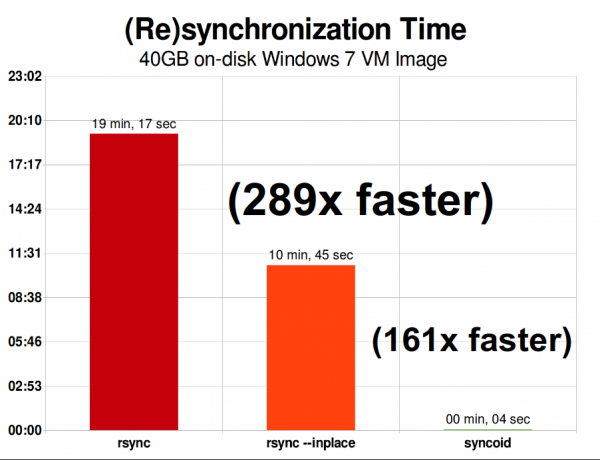
In demselben Netzwerk ist die Replikation einer 40-GiB großen Windows 7-VM-Image-Datei eine ganz andere Geschichte. Die ZFS-Replikation erfolgt 289-mal schneller als bei rsync – oder „nur“ 161-mal schneller, wenn Sie genug Wissen haben, um rsync mit dem Schalter --inplace aufzurufen.
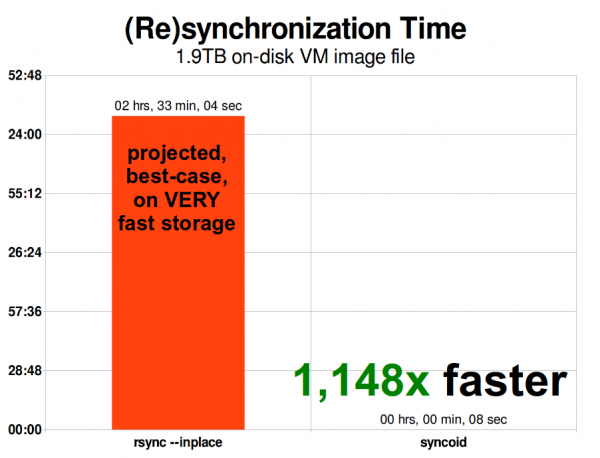
Wenn das Image einer virtuellen Maschine skaliert wird, skaliert auch das rsync-Probleme mit. Eine Größe von 1,9 TiB ist für ein modernes Image einer virtuellen Maschine nicht besonders groß – jedoch groß genug, damit die ZFS-Replikation 1148-mal schneller als rsync ist, selbst mit dem rsync-Argument —inplace.
Sobald Sie verstanden haben, wie Snapshots funktionieren, ist es nicht schwierig, die Grundzüge der Replikation zu erfassen. Da ein Snapshot lediglich ein Zeigerbaum auf die Datenblätter ist, folgt daraus, dass wir, wenn wir einen zfs send Snapshot erstellen, sowohl diesen Baum als auch alle damit verbundenen Datenblätter versenden. Wenn wir dies an den zfs send in zfs receive des Zielobjekts übergeben, werden sowohl der tatsächliche Inhalt des Blocks als auch der Zeigerbaum, der auf die Blöcke verweist, in den Ziel-Datensatz geschrieben.
Es wird noch interessanter bei der zweiten zfs send. Jetzt haben wir zwei Systeme, von denen jedes enthält poolname/datasetname@1, und Sie erstellen einen neuen Snapshot poolname/datasetname@2. Daher haben Sie im Quellpool datasetname@1 und datasetname@2, während im Zielpool bisher nur der erste Snapshot vorhanden ist. datasetname@1.
Da wir zwischen Quelle und Ziel einen gemeinsamen Snapshot haben datasetname@1, können wir einen inkrementellen zfs send darüber erstellen. Wenn wir dem System sagen zfs send -i poolname/datasetname@1 poolname/datasetname@2, es vergleicht zwei Zeigerbäume. Alle Zeiger, die nur in @2, verweisen offensichtlich auf neue Blöcke – daher benötigen wir den Inhalt dieser Blöcke.
In einem Remote-System ist die Verarbeitung der inkrementellen send genauso einfach. Zunächst schreiben wir alle neuen Einträge, die im Stream enthalten sind, send, und fügen dann Verweise auf diese Blöcke hinzu. Voilà, wir haben @2 im neuen System!
Die asynchrone inkrementelle ZFS-Replikation stellt eine enorme Verbesserung im Vergleich zu früheren, nicht snapshotbasierten Methoden wie rsync dar. In beiden Fällen werden nur die geänderten Daten übertragen – aber rsync muss zunächst hier lesen alle Daten von beiden Seiten von der Festplatte lesen, um die Prüfziffer zu überprüfen und zu vergleichen. Im Gegensatz dazu liest die ZFS-Replikation nichts außer den Zeigerbäumen – und gegebenenfalls die Blöcke, die im gemeinsamen Snapshot nicht vorhanden sind.
Integrierte Kompression
Der Mechanismus für Copy-on-Write vereinfacht auch das System der integrierten Kompression. In traditionellen Dateisystemen ist die Kompression problematisch – sowohl die alte als auch die neue Version der geänderten Daten befinden sich im selben Raum.
Wenn man einen Datenblock in der Mitte einer Datei betrachtet, der als Megabyte von Nullen bei 0x00000000 beginnt und so weiter, lässt er sich sehr leicht auf einen Sektor auf der Festplatte komprimieren. Aber was passiert, wenn wir dieses Megabyte an Nullen durch ein Megabyte unkomprimierbarer Daten, wie JPEG oder pseudorandom Rauschen, ersetzen? Unerwartet benötigt dieses Megabyte an Daten nicht einen, sondern 256 Sektoren mit 4 KiB, und an dieser Stelle auf der Festplatte ist nur ein Sektor reserviert.
ZFS hat dieses Problem nicht, da Änderungen immer in ungenutztem Speicher geschrieben werden – der ursprüngliche Block nimmt nur einen Sektor von 4 KiB ein, und der neue Eintrag benötigt 256, aber das ist kein Problem – der zuletzt geänderte Block aus der „Mitte“ der Datei würde unabhängig davon, ob seine Größe sich ändert oder nicht, in ungenutztem Speicher geschrieben werden, daher ist dies für ZFS eine ganz normale Situation.
Die integrierte Kompression von ZFS ist standardmäßig deaktiviert und das System bietet optionale Algorithmen an – aktuell gehören dazu LZ4, gzip (1-9), LZJB und ZLE.
- LZ4 — ist ein Streaming-Algorithmus, der extrem schnelles Komprimieren und Dekomprimieren sowie Leistungsgewinne für die meisten Anwendungsfälle bietet — sogar auf relativ langsamen CPUs.
- GZIP — ein angesehener Algorithmus, der von allen Nutzern von Unix-Systemen geschätzt wird. Er kann mit Komprimierungsstufen von 1 bis 9 implementiert werden, wobei die Komprimierungsrate zunimmt und der CPU-Verbrauch ansteigt, je näher man Stufe 9 kommt. Der Algorithmus eignet sich gut für alle textbasierten (oder anderen stark komprimierbaren) Anwendungsfälle, kann jedoch zu Problemen mit der CPU führen — verwenden Sie ihn mit Vorsicht, insbesondere auf höheren Stufen.
- LZJB — der ursprüngliche Algorithmus in ZFS. Er ist veraltet und sollte nicht mehr verwendet werden; LZ4 übertrifft ihn in allen Aspekten.
- ZLE — Null-Level-Encoding. Es berührt normale Daten überhaupt nicht, komprimiert jedoch große Nullfolgen. Nützlich für vollständig nicht komprimierbare Datensätze (z. B. JPEG, MP4 oder andere bereits komprimierte Formate), da es nicht komprimierbare Daten ignoriert, aber ungenutzten Platz in den endgültigen Aufzeichnungen komprimiert.
Wir empfehlen die LZ4-Kompression praktisch für alle Einsatzszenarien; die Leistungseinbußen bei der Verarbeitung nicht komprimierbarer Daten sind minimal, während der Leistungszuwachs für typische Daten erheblich ist. Das Kopieren eines Abbildes einer virtuellen Maschine für eine neue Windows-Betriebssysteminstallation (frisch installiert, keine Daten sind noch vorhanden) mit compression=lz4 geschah 27% schneller als mit compression=none, in .
ARC – adaptiver Austauschcache
ZFS ist das einzige moderne Dateisystem, das uns bekannt ist und das sein eigenes Lese-Cache-System verwendet, anstatt sich auf den Seiten-Cache des Betriebssystems zu verlassen, um Kopien von kürzlich gelesenen Blöcken im Arbeitsspeicher zu speichern.
Obwohl der eigene Cache nicht ohne Probleme ist – ZFS kann nicht so schnell auf neue Anfragen zur Speicherzuweisung reagieren wie der Kernel, weshalb ein neuer Aufruf malloc() zur Speicherausweisung fehlschlagen kann, wenn er RAM benötigt, der momentan vom ARC belegt ist. Aber es gibt gewichtige Gründe, den eigenen Cache zu verwenden, zumindest derzeit.
Alle gängigen modernen Betriebssysteme wie MacOS, Windows, Linux und BSD verwenden für die Implementierung des Seiten-Caches den LRU-Algorithmus (Least Recently Used). Dies ist ein einfacher Algorithmus, der einen im Cache gespeicherten Block nach jedem Zugriff «nach oben» in die Warteschlange verschiebt und Blöcke «nach unten» verdrängt, um Platz für neue Cache-Misshits (Blöcke, die vom Laufwerk und nicht aus dem Cache gelesen werden müssen) zu schaffen.
Normalerweise funktioniert der Algorithmus ordnungsgemäß, jedoch kann in Systemen mit großen Arbeitslasten LRU leicht zu thrashing führen – dem Verdrängen häufig benötigter Blöcke, um Platz für Blöcke zu schaffen, die niemals wieder aus dem Cache gelesen werden.
ist ein wesentlich weniger naiver Algorithmus, der als «gewichteter» Cache betrachtet werden kann. Nach jedem Zugriff auf einen im Cache gespeicherten Block wird dieser etwas «schwerer» und es wird schwieriger, ihn zu verdrängen – selbst nach der Verdrängung wird der Block verfolgt für einen bestimmten Zeitraum. Ein Block, der verdrängt wurde, aber dann wieder in den Cache gelesen werden muss, wird ebenfalls «schwerer».
Das Endergebnis all dessen ist ein Cache mit einer deutlich höheren Trefferquote – das Verhältnis zwischen Cache-Zugriffen (lesen aus dem Cache) und Fehlschlägen (lesen von der Festplatte). Diese Statistik ist äußerst wichtig – nicht nur werden Cache-Hits um ein Vielfaches schneller bearbeitet, sondern auch die Fehlschläge können schneller bearbeitet werden, da mehr Cache-Hits weniger parallele Anfragen an die Festplatte zur Folge haben, was die Verzögerung für die verbleibenden Fehlschläge, die von der Festplatte bearbeitet werden müssen, verringert.
Fazit
Nachdem wir die grundlegende Semantik von ZFS – wie das Copy-on-Write-Prinzip funktioniert sowie die Beziehungen zwischen Storage-Pools, virtuellen Geräten, Blöcken, Sektoren und Dateien – untersucht haben, sind wir bereit, die tatsächliche Leistung anhand realer Zahlen zu besprechen.
Im nächsten Teil werden wir die tatsächliche Leistung von Pools mit Mirror vdev und RAIDz miteinander vergleichen sowie im Vergleich zu den traditionellen RAID-Topologien des Linux-Kernels, die wir untersucht haben. .
Zunächst wollten wir uns nur auf die Grundlagen konzentrieren – die ZFS-Topologien selbst – aber nach der so vieler Wir sind bereit, über fortgeschrittene Konfigurationen und Tuning von ZFS zu sprechen, einschließlich der Verwendung von unterstützenden vdev-Typen wie L2ARC, SLOG und Special Allocation.
Quelle: habr.com
