


In Linux gibt es eine Vielzahl von Werkzeugen zur Fehlersuche im Kernel und in Anwendungen. Die meisten davon beeinträchtigen die Anwendungsleistung negativ und können nicht in der Produktion eingesetzt werden.
Vor einigen Jahren wurde — eBPF. Es ermöglicht die Nachverfolgung des Kernels und von Benutzeranwendungen mit geringem Overhead, ohne dass Programme neu kompiliert oder externe Module in den Kernel geladen werden müssen.
Mittlerweile existieren zahlreiche Anwendungsutilities, die eBPF verwenden, und in diesem Artikel werden wir erörtern, wie man eine eigene Profilierungsutility auf der Grundlage der Bibliothek . Der Artikel basiert auf realen Ereignissen. Wir werden den Weg vom Auftreten des Problems bis zu dessen Behebung beschreiten, um zu zeigen, wie bereits bestehende Utilities in konkreten Situationen genutzt werden können.
Ceph ist langsam
Ein neuer Host wurde zum Ceph-Cluster hinzugefügt. Nach der Migration eines Teils der Daten darauf stellten wir fest, dass die Schreibgeschwindigkeit deutlich niedriger ist als auf anderen Servern.
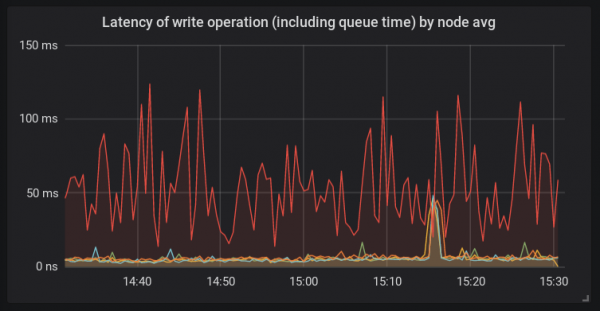
Im Gegensatz zu anderen Plattformen wurde auf diesem Hosting-Server bcache und der neue Kernel Linux 4.15 verwendet. Diese Konfiguration kam hier zum ersten Mal zum Einsatz. Zu diesem Zeitpunkt war klar, dass die Ursache des Problems theoretisch alles Mögliche sein konnte.
Untersuchung des Hosts
Beginnen wir damit, einen Blick darauf zu werfen, was innerhalb des Prozesses ceph-osd geschieht. Dafür nutzen wir und (nähere Informationen dazu finden Sie ):

Das Bild zeigt uns, dass die Funktion fdatasync() viel Zeit beim Senden einer Anfrage in der Funktion generic_make_request()verbrachte. Das deutet darauf hin, dass die Probleme vermutlich außerhalb des OSD-Daemons liegen. Das könnte entweder am Kernel oder an den Festplatten liegen. Die iostat-Ausgabe zeigte eine hohe Verzögerung bei der Bearbeitung von Anfragen an den bcache-Festplatten.
Bei der Überprüfung des Hosts stellten wir fest, dass der Daemon systemd-udevd erhebliche CPU-Zeit in Anspruch nimmt – etwa 20 % auf mehreren Kernen. Dieses seltsame Verhalten muss weiter untersucht werden. Da systemd-udevd mit uevent-Änderungen arbeitet, haben wir beschlossen, sie über udevadm monitor. Es stellte sich heraus, dass eine große Anzahl an Änderungsereignissen für jedes Blockgerät im System generiert wurde. Das ist ziemlich ungewöhnlich, daher sollten wir uns anschauen, was all diese Events erzeugt.
Mit dem BCC Toolkit
Wie wir bereits herausgefunden haben, verbringt der Kernel (und der Ceph-Daemon im Systemaufruf) viel Zeit mit generic_make_request(). Versuchen wir, die Geschwindigkeit dieser Funktion zu messen. In gibt es bereits ein hervorragendes Tool — funclatency. Wir werden den Daemon anhand seiner PID mit einem Intervall von 1 Sekunde zwischen den Ausgaben abtasten und das Ergebnis in Millisekunden ausgeben.
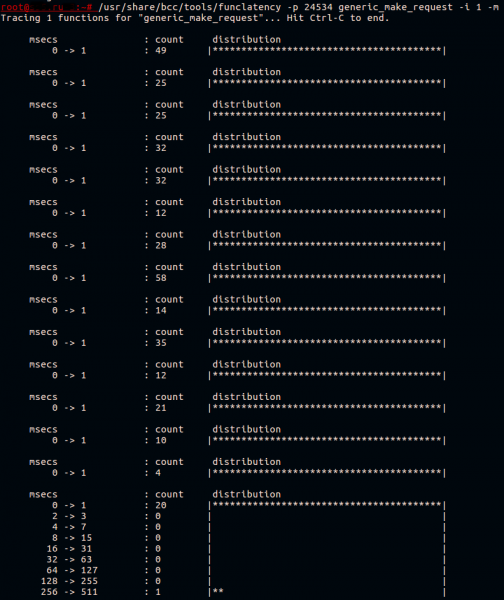
Normalerweise funktioniert diese Funktion schnell. Alles, was sie tut, ist, die Anfrage in die Warteschlange des Gerätetreibers zu übergeben.
Bcache ist ein komplexes Gerät, das tatsächlich aus drei Festplatten besteht:
- Backing Device (cachierter Disk), in diesem Fall eine langsame HDD;
- Caching Device (cachierende Disk), hier ist es eine Partition des NVMe-Geräts;
- ein virtuelles Gerät bcache, mit dem die Anwendung arbeitet.
Wir wissen, dass die Übertragung der Anfrage stockt, aber bei welchem dieser Geräte? Damit werden wir uns gleich später beschäftigen.
Jetzt wissen wir, dass uevents wahrscheinlich zu Problemen führen. Es ist nicht ganz einfach herauszufinden, was genau ihre Generierung verursacht. Nehmen wir an, es handelt sich um eine Software, die regelmäßig ausgeführt wird. Schauen wir uns an, welche Software im System ausgeführt wird, mithilfe eines Skripts. execsnoop aus demselben . Lassen Sie uns es ausführen und die Ausgabe in eine Datei umleiten.
Zum Beispiel so:
/usr/share/bcc/tools/execsnoop | tee ./execdump
Wir werden hier die vollständige Ausgabe von execsnoop nicht wiedergeben, aber eine interessante Zeile sah so aus:
sh 1764905 5802 0 sudo arcconf getconfig 1 AD | grep Temperature | awk -F '[:\/]' '{print $2}' | sed 's\/^ ([0-9]*) C.*\/1\/'
Die dritte Spalte ist die PPID (Parent PID) des Prozesses. Der Prozess mit der PID 5802 stellte sich als einer der Threads unseres Überwachungssystems heraus. Bei der Überprüfung der Konfiguration des Überwachungssystems wurden fälschlicherweise festgelegte Parameter gefunden. Die Temperatur des HBA-Adapters wurde alle 30 Sekunden gemessen, was viel häufiger war als nötig. Nach der Anpassung des Überwachungsintervalls auf einen längeren Zeitraum stellten wir fest, dass die Verzögerung bei der Verarbeitung von Anfragen auf diesem Host nicht mehr im Vergleich zu anderen Hosts auffiel.
Doch es bleibt unklar, warum das bcache-Gerät so langsam war. Wir haben eine Testumgebung mit identischer Konfiguration vorbereitet und versucht, das Problem nachzustellen, indem wir fio auf bcache ausgeführt haben und dabei regelmäßig udevadm trigger gestartet haben, um uevents zu generieren.
Tools auf Basis von BCC schreiben
Wir werden versuchen, ein einfaches Tool zu erstellen, um die langsamsten Aufrufe zu verfolgen und anzuzeigen. generic_make_request()Dabei interessiert uns auch der Name der Festplatte, für die diese Funktion aufgerufen wurde.
Der Plan ist einfach:
- Registrieren Sie kprobe findet man generic_make_request():
- Wir speichern den Namen der Festplatte, der über das Argument der Funktion verfügbar ist;
- Wir speichern den Zeitstempel.
- Registrieren Sie kretprobe bei der Rückkehr von generic_make_request():
- Wir erhalten den aktuellen Zeitstempel;
- Wir suchen den gespeicherten Zeitstempel und vergleichen ihn mit dem aktuellen;
- Wenn das Ergebnis größer als der festgelegte Wert ist, finden wir den gespeicherten Festplattennamen und geben ihn im Terminal aus.
Kprobes und kretprobes verwenden einen Mechanismus von Haltepunkten, um den Code von Funktionen zur Laufzeit zu verändern. Sie können einen und Artikel zu diesem Thema lesen. Wenn man sich den Code verschiedener Utilities in , anschaut, fällt auf, dass sie eine identische Struktur haben. In diesem Artikel werden wir das Parsen der Skriptargumente auslassen und direkt zur BPF-Programm kommen.
Der eBPF-Code innerhalb des Python-Skripts sieht folgendermaßen aus:
bpf_text = """ # Hier wird der BPF-Programmiercode stehen """
Für den Datenaustausch zwischen Funktionen nutzen eBPF-Programme . So verfahren wir auch. Als Schlüssel verwenden wir die PID des Prozesses, und als Wert definieren wir die Struktur:
struct data_t {
u64 pid;
u64 ts;
char comm[TASK_COMM_LEN];
u64 lat;
char disk[DISK_NAME_LEN];
};
BPF_HASH(p, u64, struct data_t);
BPF_PERF_OUTPUT(events);
Hier registrieren wir eine Hash-Tabelle, die genannt wird p, mit einem Schlüssel des Typs u64 und einem Wert des Typs struct data_t. Die Tabelle wird im Kontext unseres BPF-Programms verfügbar sein. Das Makro BPF_PERF_OUTPUT registriert eine weitere Tabelle, die genannt wird events, die verwendet wird für in den Benutzerspeicher.
Bei der Messung von Verzögerungen zwischen Funktionsaufruf und Rückgabe oder zwischen verschiedenen Funktionsaufrufen muss berücksichtigt werden, dass die gewonnenen Daten zu einem Kontext gehören sollten. Mit anderen Worten, man sollte sich des möglichen parallelen Aufrufs von Funktionen bewusst sein. Wir haben die Möglichkeit, die Verzögerung zwischen dem Funktionsaufruf im Kontext eines Prozesses und der Rückgabe aus dieser Funktion im Kontext eines anderen Prozesses zu messen, was jedoch wahrscheinlich nutzlos ist. Ein gutes Beispiel hierfür könnte , wo der Schlüssel der Hash-Tabelle einen Verweis auf struct request, der eine Anfrage an die Festplatte repräsentiert.
Als nächstes müssen wir den Code schreiben, der bei der Aufruf der untersuchten Funktion ausgeführt wird:
void start(struct pt_regs *ctx, struct bio *bio) {
u64 pid = bpf_get_current_pid_tgid();
struct data_t data = {};
u64 ts = bpf_ktime_get_ns();
data.pid = pid;
data.ts = ts;
bpf_probe_read_str(&data.disk, sizeof(data.disk), (void*)bio->bi_disk->disk_name);
p.update(&pid, &data);
}
Hier wird als zweites Argument das erste Argument der aufgerufenen Funktion eingesetzt . Danach erhalten wir die PID des Prozesses, in dessen Kontext wir arbeiten, sowie den aktuellen Zeitstempel in Nanosekunden. Wir speichern all dies in der frisch zugewiesenen struct data_t data. Den Namen der Festplatte erhalten wir aus der Struktur bio, die beim Aufruf übergeben wird generic_make_request(), und speichern ihn in der gleichen Struktur data. Als letzten Schritt fügen wir einen Eintrag in die zuvor erwähnte Hash-Tabelle hinzu.
Die nächste Funktion wird bei der Rückgabe aus generic_make_request():
void stop(struct pt_regs *ctx) {
u64 pid = bpf_get_current_pid_tgid();
u64 ts = bpf_ktime_get_ns();
struct data_t* data = p.lookup(&pid);
if (data != 0 && data->ts > 0) {
bpf_get_current_comm(&data->comm, sizeof(data->comm));
data->lat = (ts - data->ts) / 1000;
if (data->lat > MIN_US) {
FACTOR
data->pid >>= 32;
events.perf_submit(ctx, data, sizeof(struct data_t));
}
p.delete(&pid);
}
}
Diese Funktion ähnelt der vorherigen: Wir ermitteln die PID des Prozesses und den Zeitstempel, jedoch reservieren wir keinen neuen Speicher für die Struktur data. Stattdessen suchen wir in der Hash-Tabelle nach der bereits existierenden Struktur anhand des Schlüssels == aktuelle PID. Wenn die Struktur gefunden wird, erfahren wir den Namen des gestarteten Prozesses und fügen ihn hinzu.
Die binäre Verschiebung, die wir hier verwenden, dient dazu, die Thread-GID zu erhalten, d.h. die PID des übergeordneten Prozesses, der den Thread gestartet hat, in dem Kontext, in dem wir arbeiten. Die von uns aufgerufene Funktion gibt sowohl die GID des Threads als auch seine PID in einem 64-Bit-Wert zurück.
Bei der Ausgabe im Terminal interessiert uns momentan der Thread nicht, sondern der übergeordnete Prozess. Nach dem Vergleich der erhaltenen Latenz mit dem festgelegten Schwellenwert übergeben wir unsere Struktur data an den Benutzerspace über die Tabelle events, danach löschen wir den Eintrag aus p.
Im Python-Skript, das diesen Code lädt, müssen wir MIN_US und FACTOR durch die Verzögerungsgrenzen und Zeiteinheiten ersetzen, die wir als Argumente übergeben:
bpf_text = bpf_text.replace('MIN_US', str(min_usec))
if args.milliseconds:
bpf_text = bpf_text.replace('FACTOR', 'data->lat /= 1000;')
label = "msec"
else:
bpf_text = bpf_text.replace('FACTOR', '')
label = "usec"
Jetzt müssen wir das BPF-Programm durch und die Proben registrieren:
b = BPF(text=bpf_text)
b.attach_kprobe(event="generic_make_request", fn_name="start")
b.attach_kretprobe(event="generic_make_request", fn_name="stop")
Wir müssen außerdem definieren struct data_t in unserem Skript, sonst lässt sich nichts lesen:
TASK_COMM_LEN = 16 # linux/sched.h
DISK_NAME_LEN = 32 # linux/genhd.h
class Data(ct.Structure):
_fields_ = [("pid", ct.c_ulonglong),
("ts", ct.c_ulonglong),
("comm", ct.c_char * TASK_COMM_LEN),
("lat", ct.c_ulonglong),
("disk", ct.c_char * DISK_NAME_LEN)]
Der letzte Schritt ist die Ausgabe der Daten im Terminal:
def print_event(cpu, data, size):
global start
event = ct.cast(data, ct.POINTER(Data)).contents
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-1s %s %s" % (time_s, event.comm, event.pid, event.lat, label, event.disk))
b["events"].open_perf_buffer(print_event)
# Ausgabe formatieren
start = 0
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
Das Skript ist verfügbar auf . Lassen Sie uns versuchen, es auf der Testplattform zu starten, wo fio läuft und auf bcache schreibt, und udevadm monitor aufzurufen:
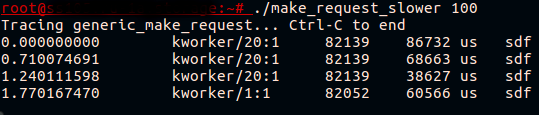
Endlich! Jetzt sehen wir, dass das, was wie ein langsames bcache-Gerät aussah, tatsächlich ein langsamer Aufruf ist generic_make_request() für die zwischengespeicherte Festplatte.
Tauchen Sie in den Kernel ein
Was genau verursacht die Verzögerung bei der Anforderung? Wir sehen, dass die Verzögerung sogar vor dem Beginn der Abrechnung der Anfrage auftritt, d.h. die spezifische Anfrage für die weitere statistische Ausgabe (/proc/diskstats oder iostat) ist noch nicht gestartet. Dies lässt sich leicht überprüfen, indem man iostat während der Problemmultiplikation ausführt, oder , das auf dem Beginn und dem Ende der Abrechnung der Anfragen basiert. Keines dieser Tools zeigt Probleme bei Anfragen an die zwischengespeicherte Festplatte an.
Wenn wir uns die Funktion ansehen generic_make_request(), sehen wir, dass vor Beginn der Abrechnung der Anfrage zwei weitere Funktionen aufgerufen werden. Die erste ist generic_make_request_checks(), die die Legitimitätsprüfung der Anfrage hinsichtlich der Festplatteneinstellungen durchführt. Die zweite ist , in der es einen interessanten Aufruf gibt :
ret = wait_event_interruptible(q->mq_freeze_wq,
(atomic_read(&q->mq_freeze_depth) == 0 &&
(preempt || !blk_queue_preempt_only(q))) ||
blk_queue_dying(q));
Der Kernel wartet darauf, die Warteschlange aufzutauen. Lassen Sie uns die Verzögerung messen. blk_queue_enter():
~# /usr/share/bcc/tools/funclatency blk_queue_enter -i 1 -m
Verfolge 1 Funktionen für "blk_queue_enter"... Drücken Sie Ctrl-C, um zu beenden.
msecs : count distribution
0 -> 1 : 341 |****************************************|
msecs : count distribution
0 -> 1 : 316 |****************************************|
msecs : count distribution
0 -> 1 : 255 |****************************************|
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 1 | |
Es scheint, dass wir kurz vor dem Durchbruch stehen. Die Funktionen, die zum "Einfrieren/-Auftauen" der Warteschlange verwendet werden, sind und . Sie werden verwendet, wenn es erforderlich ist, die Warteschlangeneinstellungen zu ändern, was potenziell gefährlich für die Anfragen in dieser Warteschlange sein kann. Bei der Aufruf von blk_mq_freeze_queue() wird der Zähler in erhöht. q->mq_freeze_depth. Danach wartet der Kernel darauf, dass die Warteschlange in .
geleert wird, wobei die Wartezeit für das Leeren dieser Warteschlange der Festplattenträgheit entspricht, da der Kernel darauf wartet, dass alle in der Warteschlange gestellten Operationen abgeschlossen sind. Sobald die Warteschlange leer ist, werden die Einstellungen angewendet. Danach wird , der Zähler wird dekrementiert freeze_depth.
Jetzt wissen wir genug, um die Situation zu beheben. Der Befehl udevadm trigger wendet die Einstellungen für das Blockgerät an. Diese Einstellungen sind in den udev-Regeln beschrieben. Wir können herausfinden, welche spezifischen Einstellungen die Warteschlange „einfrieren“, indem wir versuchen, sie über sysfs zu ändern oder den Quellcode des Kernels zu betrachten. Außerdem können wir das BCC-Tool ausprobieren. , das die Kernel- und Benutzerraum-Stack-Traces für jeden Aufruf im Terminal ausgibt. blk_freeze_queue, zum Beispiel:
~# /usr/share/bcc/tools/trace blk_freeze_queue -K -U
PID TID COMM FUNC
3809642 3809642 systemd-udevd blk_freeze_queue
blk_freeze_queue+0x1 [kernel]
elevator_switch+0x29 [kernel]
elv_iosched_store+0x197 [kernel]
queue_attr_store+0x5c [kernel]
sysfs_kf_write+0x3c [kernel]
kernfs_fop_write+0x125 [kernel]
__vfs_write+0x1b [kernel]
vfs_write+0xb8 [kernel]
sys_write+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
__write_nocancel+0x7 [libc-2.23.so]
[unknown]
3809631 3809631 systemd-udevd blk_freeze_queue
blk_freeze_queue+0x1 [kernel]
queue_requests_store+0xb6 [kernel]
queue_attr_store+0x5c [kernel]
sysfs_kf_write+0x3c [kernel]
kernfs_fop_write+0x125 [kernel]
__vfs_write+0x1b [kernel]
vfs_write+0xb8 [kernel]
sys_write+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
__write_nocancel+0x7 [libc-2.23.so]
[unknown]
Udev-Regeln ändern sich recht selten und in der Regel unter Kontrolle. Wir beobachten, dass selbst die Anwendung bereits festgelegter Werte einen Anstieg der Verzögerung bei der Anfrageübermittlung vom Anwendungssystem an die Festplatte verursacht. Natürlich ist es keine besonders gute Praxis, udev-Ereignisse zu generieren, wenn es keine Veränderungen in der Festkonfiguration gibt (z. B. wenn ein Gerät nicht angeschlossen oder getrennt wird). Dennoch können wir dem Kernel helfen, unnötige Arbeiten zu vermeiden und die Anfragewarteschlange nicht "einzufrieren", wenn dies nicht erforderlich ist. die Situation verbessern.
Fazit
eBPF ist ein äußerst flexibles und leistungsstarkes Werkzeug. In diesem Artikel haben wir einen praktischen Anwendungsfall betrachtet und einen kleinen Teil dessen demonstriert, was möglich ist. Wenn Sie an der Entwicklung von BCC-Utilities interessiert sind, sollten Sie einen Blick auf , das die Grundlagen gut beschreibt.
Es gibt auch andere interessante Werkzeuge zum Debuggen und Profilieren, die auf eBPF basieren. Eines davon ist , welches das Schreiben von leistungsstarken Einzeilern und kleinen Programmen in einer awk-ähnlichen Sprache ermöglicht. Ein weiteres ist , um hochauflösende Low-Level-Metriken direkt auf Ihren Prometheus-Server zu sammeln, mit der Möglichkeit, später eine ansprechende Visualisierung und sogar Alarme zu erhalten.
Quelle: habr.com
