

Wenn Ihre IT-Infrastruktur zu schnell wächst, stehen Sie irgendwann vor der Wahl – entweder die personellen Ressourcen linear zu erhöhen oder mit der Automatisierung zu beginnen. Bis zu einem gewissen Punkt lebten wir in der ersten Paradigme, bevor der lange Weg zur Infrastruktur als Code begann.

Natürlich ist NSPK kein Startup, aber eine solche Atmosphäre herrschte in den ersten Jahren des Unternehmens, und es waren sehr interessante Jahre. Ich heiße , ich unterstütze seit über 10 Jahren eine hochverfügbare Linux-Infrastruktur. Ich trat dem NSPK-Team im Januar 2016 bei und hatte leider nicht die Gelegenheit, die Anfänge des Unternehmens zu erleben, kam jedoch in einer Phase großer Veränderungen.
Insgesamt lässt sich sagen, dass unser Team zwei Produkte für das Unternehmen bereitstellt. Das erste ist die Infrastruktur. Die E-Mails müssen zugestellt werden, DNS muss funktionieren, und die Domain Controller müssen Ihnen den Zugang zu Servern ermöglichen, die nie ausfallen sollten. Die IT-Landschaft des Unternehmens ist riesig! Es handelt sich um business- und mission-critical Systeme, für die einige eine Verfügbarkeitsanforderung von 99,999 % haben. Das zweite Produkt sind die Server selbst, sowohl physische als auch virtuelle. Bestehende Server müssen überwacht und neue regelmäßig an Kunden aus vielen Abteilungen geliefert werden. In diesem Artikel möchte ich hervorheben, wie wir die Infrastruktur entwickelt haben, die für den Lebenszyklus verantwortlich ist. Server.
Der Beginn des Weges
Zu Beginn sah unser Technologie-Stack folgendermaßen aus:
OS CentOS 7
Domain Controller FreeIPA
Automatisierung – Ansible (+Tower), Cobbler
All dies war auf drei Domänen verteilt, die in mehreren Rechenzentren untergebracht waren. In einem Rechenzentrum – Bürosysteme und Testumgebungen, in den anderen PROD.
Die Erstellung von Servern sah zu einem bestimmten Zeitpunkt so aus:
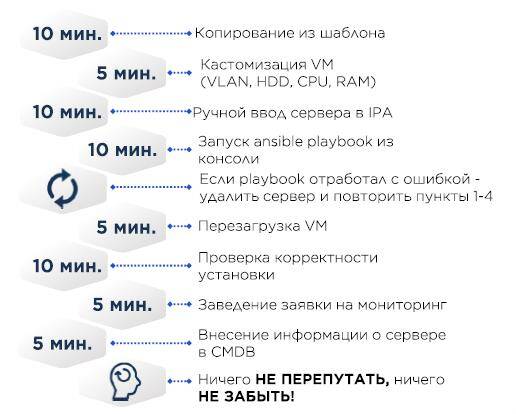
Im VM-Template CentOS minimal und das notwendige Minimum, wie z.B. eine korrekte /etc/resolv.conf, der Rest wird über Ansible bereitgestellt.
CMDB – Excel.
Wenn der Server physisch ist, wurde anstelle der Kopie einer virtuellen Maschine das Betriebssystem mit Hilfe von Cobbler installiert – dabei werden die MAC-Adressen des Zielservers in die Cobbler-Konfiguration eingefügt, der Server erhält per DHCP seine IP-Adresse und das Betriebssystem wird anschließend installiert.
Anfangs haben wir sogar versucht, eine Art Konfigurationsmanagement in Cobbler zu betreiben. Doch im Laufe der Zeit brachte dies Probleme mit der Portabilität der Konfigurationen sowohl zu anderen Rechenzentren als auch zu dem Ansible-Code zur VM-Vorbereitung.
Zu diesem Zeitpunkt schätzten viele von uns Ansible als eine praktische Erweiterung von Bash und nutzten bereitwillig Konstruktionen mit Shell und sed – kurz gesagt, Bashsible. Das führte letztendlich dazu, dass, wenn das Playbook aus irgendeinem Grund nicht auf dem Server funktionierte, es einfacher war, den Server zu löschen, das Playbook anzupassen und alles erneut durchzuführen. Es gab im Grunde kein Versionsmanagement für Skripte und auch keine Portabilität der Konfigurationen.
Zum Beispiel wollten wir eine bestimmte Konfiguration auf allen Servern ändern:
- Wir ändern die Konfiguration auf bestehenden Servern im logischen Segment/Rechenzentrum. Manchmal nicht an einem Tag – die Verfügbarkeit und das Gesetz der großen Zahlen erlauben es nicht, alle Änderungen gleichzeitig umzusetzen. Einige Änderungen sind potenziell destruktiv und erfordern einen Neustart – von Diensten bis hin zum Betriebssystem.
- Korrekturen in Ansible
- Korrekturen in Cobbler
- Wiederholung N-mal für jedes logische Segment/Rechenzentrum
Damit alle Änderungen reibungslos ablaufen, mussten zahlreiche Faktoren berücksichtigt werden, und Veränderungen treten ständig auf.
- Refactoring des Ansible-Codes, der Konfigurationsdateien
- Änderung interner Best Practices
- Änderungen basierend auf der Analyse von Vorfällen/Notfällen
- Änderung der Sicherheitsstandards, sowohl intern als auch extern. Zum Beispiel werden die Anforderungen des PCI DSS jedes Jahr um neue Vorschriften ergänzt.
Wachstum der Infrastruktur und der Beginn des Weges
Die Anzahl der Server/logischen Domänen/Rechenzentren wuchs, ebenso wie die Anzahl der Fehler in den Konfigurationen. Irgendwann kamen wir zu drei Bereichen, in die wir das Configuration Management weiterentwickeln müssen:
- Automatisierung. Soweit möglich, sollte der menschliche Faktor bei sich wiederholenden Vorgängen vermieden werden.
- Vorhersehbarkeit. Das管理en von Infrastruktur wird erheblich einfacher, wenn sie vorhersehbar ist. Die Konfiguration von Servern und den dafür erforderlichen Tools sollte überall einheitlich sein. Dies ist ebenso wichtig für Produkt-Teams – die Anwendung muss sicher nach der Testphase in eine produktive Umgebung überführt werden, die ähnlich wie die Testumgebung konfiguriert ist.
- Einfachheit und Transparenz bei Änderungen im Konfigurationsmanagement.
Wir müssen nur noch ein paar Werkzeuge hinzufügen.
Für die Codeverwaltung haben wir GitLab CE gewählt, nicht zuletzt wegen der integrierten CI/CD-Module.
Das Geheimnis-Management erfolgt über Hashicorp Vault, insbesondere aufgrund der hervorragenden API.
Konfigurations- und Ansible-Rollentests – Molecule + Testinfra. Die Tests verlaufen deutlich schneller, wenn Sie Mitogen mit Ansible koppeln. Parallel dazu haben wir begonnen, unsere eigene CMDB und einen Orchestrator für automatische Deployments zu schreiben (im Bild über Cobbler), aber das ist eine ganz andere Geschichte, über die in Zukunft mein Kollege und Hauptentwickler dieser Systeme berichten wird.
Unsere Auswahl:
Molecule + Testinfra
Ansible + Tower + AWX
Welt der Server + DITNET (Eigenentwicklung)
Cobbler
GitLab + GitLab Runner
Hashicorp Vault

Übrigens zu Ansible-Rollen. Zuerst gab es nur eine, nach mehreren Refaktorisierungen sind es nun 17. Ich empfehle dringend, das Monolithische in idempotente Rollen zu zerlegen, die dann separat ausgeführt werden können. Zudem können Tags hinzugefügt werden. Wir haben die Rollen nach Funktionalität aufgeteilt – Netzwerk, Logging, Pakete, Hardware, Molecule usw. Im Übrigen haben wir uns an der folgenden Strategie orientiert. Ich behaupte nicht, dass dies die einzige Wahrheit ist, aber es hat bei uns gut funktioniert.
- Das Kopieren von Servern aus einem "Gold-Image" ist eine schlechte Idee!Zu den Hauptnachteilen gehört, dass Sie genau nicht wissen, in welchem Zustand sich die Images derzeit befinden, und dass alle Änderungen auf alle Images in allen Virtualisierungsfarmen angewendet werden.
- Verwenden Sie Standardkonfigurationsdateien nur minimal und vereinbaren Sie mit anderen Abteilungen, dass Sie für die Hauptsystemdateien verantwortlich sind., zum Beispiel:
- Halten Sie /etc/sysctl.conf leer. Die Einstellungen sollten nur in /etc/sysctl.d/ liegen. Ihre Standardkonfiguration in einer Datei, individuelle Anpassungen für die Anwendung in einer anderen.
- Verwenden Sie Überschreibungsdateien zur Bearbeitung von systemd-Einheiten.
- Templateisieren Sie alle Konfigurationen und integrieren Sie sie vollständig, soweit möglich, keine sed- oder ähnliche Scripting-Tools in Playbooks verwenden.
- Beim Refaktorisieren des Konfigurationsmanagement-Codes:
- Zerteilen Sie Aufgaben in logische Einheiten und überarbeiten Sie das Monolithische System nach Rollen.
- Nutzen Sie Linter! Ansible-lint, yaml-lint usw.
- Ändern Sie den Ansatz! Kein Bashsible. Der Zustand des Systems muss beschrieben werden.
- Für alle Ansible-Rollen sollten Tests in Molecule geschrieben werden, und einmal täglich sollten Berichte erstellt werden.
- In unserem Fall, nach der Vorbereitung von über 100 Tests, fanden wir etwa 70.000 Fehler. Die Korrekturen dauerten mehrere Monate.

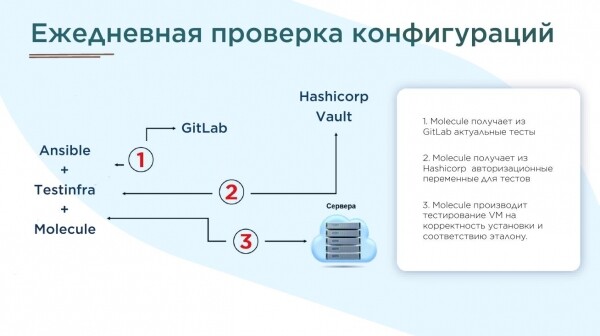
Unsere Umsetzung
Die Ansible-Rollen waren also bereit, templatisiert und durch Linter überprüft. Und auch die Git-Repositories wurden überall eingerichtet. Doch die Frage der zuverlässigen Bereitstellung des Codes in verschiedene Segmente blieb offen. Wir entschieden uns, dies mit Skripten zu synchronisieren. So sieht es aus:
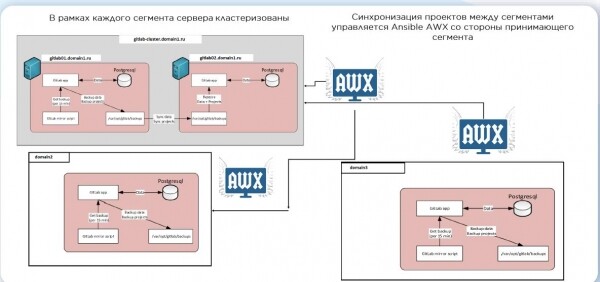
Sobald die Änderung eintrifft, wird CI gestartet, ein Testserver erstellt, die Rollen angewendet und mit Molecule getestet. Wenn alles in Ordnung ist, geht der Code in den Produktionsbranch. Wir wenden den neuen Code jedoch nicht automatisch auf bestehende Server an. Das ist eine Art Stopper, der für die hohe Verfügbarkeit unserer Systeme notwendig ist. Wenn die Infrastruktur dann riesig wird, kommt auch das Gesetz der großen Zahlen ins Spiel – selbst wenn Sie sicher sind, dass die Änderung harmlos ist, kann sie zu unerfreulichen Konsequenzen führen.
Es gibt viele Möglichkeiten zur Erstellung von Servern. Am Ende haben wir uns für maßgeschneiderte Skripte in Python entschieden. Für CI verwenden wir Ansible:
- name: create1.yml - VM aus einer Vorlage erstellen
vmware_guest:
hostname: "{{datacenter}}".domain.de
username: "{{ username_vc }}"
password: "{{ password_vc }}"
validate_certs: no
cluster: "{{cluster}}"
datacenter: "{{datacenter}}"
name: "{{ name }}"
state: poweredon
folder: "/{{folder}}"
template: "{{template}}"
customization:
hostname: "{{ name }}"
domain: domain.de
dns_servers:
- "{{ ipa1_dns }}"
- "{{ ipa2_dns }}"
networks:
- name: "{{ network }}"
type: static
ip: "{{ip}}"
netmask: "{{netmask}}"
gateway: "{{gateway}}"
wake_on_lan: True
start_connected: True
allow_guest_control: True
wait_for_ip_address: yes
disk:
- size_gb: 1
type: thin
datastore: "{{datastore}}"
- size_gb: 20
type: thin
datastore: "{{datastore}}"Das ist das Ergebnis, unser System lebt und entwickelt sich weiter.
- 17 Ansible-Rollen zur Serverkonfiguration. Jede Rolle ist dafür ausgelegt, eine bestimmte logische Aufgabe zu lösen (Protokollierung, Auditing, Benutzerautorisierung, Monitoring usw.).
- Testen der Rollen. Molecule + TestInfra.
- Eigenentwicklung: CMDB + Orchestrator.
- Die Servererstellungszeit beträgt etwa 30 Minuten, automatisiert und nahezu unabhängig von der Warteschlange.
- Gleichbleibender Zustand/Bezeichnung der Infrastruktur in allen Segmenten – Playbooks, Repositories, Virtualisierungselemente.
- Tägliche Überprüfung des Serverstatus mit der Erstellung von Berichten über Abweichungen vom Standard.
Ich hoffe, mein Bericht ist hilfreich für diejenigen, die am Anfang ihres Weges stehen. Welchen Automatisierungs-Stack verwenden Sie?
Quelle: habr.com
