


Vor einigen Jahren wurde Kubernetes im offiziellen GitHub-Blog. Seitdem hat es sich zur Standardtechnologie für das Bereitstellen von Diensten entwickelt. Heute verwaltet Kubernetes einen erheblichen Teil der internen und öffentlichen Dienste. Mit dem Wachstum unserer Cluster und den zunehmend strengen Leistungsanforderungen bemerkten wir sporadische Latenzen in einigen Kubernetes-Diensten, die nicht durch die Last der Anwendung erklärt werden konnten.
Es scheint, dass in den Anwendungen zufällige Netzwerkverzögerungen von bis zu 100 ms und mehr auftreten, was zu Timeouts oder Wiederholungsversuchen führt. Es wurde erwartet, dass die Dienste viel schneller als 100 ms auf Anfragen reagieren können. Doch das ist unmöglich, wenn die Verbindung selbst so viel Zeit in Anspruch nimmt. Zusätzlich beobachteten wir sehr schnelle MySQL-Anfragen, die millisekundenschnell bearbeitet werden sollten, und MySQL schaffte das auch in Millisekunden. Aus der Sicht der anfragenden Anwendung benötigte die Antwort jedoch 100 ms oder mehr.
Es war sofort klar, dass das Problem nur bei der Verbindung mit dem Kubernetes-Knoten auftritt, selbst wenn der Aufruf von außerhalb von Kubernetes kam. Am einfachsten kann das Problem in einem Test reproduziert werden, der von einem beliebigen internen Host mit dem Kubernetes-Dienst über einen bestimmten Port gestartet wird und sporadisch hohe Latenzen registriert. In diesem Artikel sehen wir uns an, wie wir die Ursache dieses Problems verfolgen konnten.
Wir reduzieren die unnötige Komplexität in der Fehlerkette.
Indem wir das gleiche Beispiel nachgestellt haben, wollten wir den Fokus des Problems eingrenzen und überflüssige Komplexitätsschichten entfernen. Ursprünglich gab es zu viele Elemente im Fluss zwischen Vegeta und den Pods in Kubernetes. Um ein tiefergehendes Netzwerkproblem zu identifizieren, mussten einige von ihnen ausgeschlossen werden.
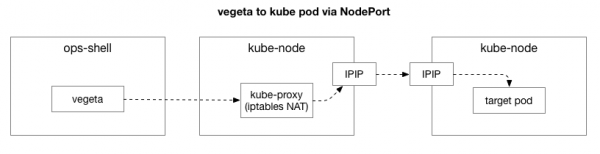
Der Client (Vegeta) stellt eine TCP-Verbindung zu einem beliebigen Knoten im Cluster her. Kubernetes agiert als Overlay-Netzwerk (oberhalb des bestehenden Rechenzentrumsnetzwerks), das verwendet, d.h. es kapselt IP-Pakete des Overlay-Netzwerks in IP-Pakete des Rechenzentrums ein. Bei der Verbindung mit dem ersten Knoten findet eine Netzaddressummsetzung statt. (NAT) mit Statusverfolgung zur Umwandlung der IP-Adresse und des Ports des Kubernetes-Knotens in die IP-Adresse und den Port im Overlay-Netzwerk (insbesondere des Pods mit der Anwendung). Für eingehende Pakete wird die umgekehrte Reihenfolge ausgeführt. Dies ist ein komplexes System mit vielen Zuständen und Elementen, die sich ständig aktualisieren und ändern, während Dienste bereitgestellt und verschoben werden.
Dienstprogramm tcpdump im Vegeta-Test verursacht es Verzögerungen während des TCP-Handshakes (zwischen SYN und SYN-ACK). Um diese zusätzliche Komplexität zu entfernen, können Sie hping3 für einfache "Pings" mit SYN-Paketen verwenden. Wir überprüfen, ob es eine Verzögerung im Antwortpaket gibt, und setzen dann die Verbindung zurück. Wir können die Daten filtern, indem wir nur Pakete mit über 100 ms einbeziehen und so eine einfachere Möglichkeit zur Reproduktion des Problems erhalten als bei einem vollständigen Level-7-Netzwerktest in Vegeta. Hier sind die "Pings" des Kubernetes-Knotens mit TCP SYN/SYN-ACK am "Knotenport" des Dienstes (30927) mit einem Intervall von 10 ms, gefiltert nach den langsamsten Antworten:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106,2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104,1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109,2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109,2 ms
Zunächst kann man eine erste Beobachtung machen. Anhand der Sequenznummern und Zeitstempel ist zu erkennen, dass es sich nicht um einmalige Störungen handelt. Die Verzögerungen bauen sich häufig auf und werden letztendlich verarbeitet.
Als nächstes wollen wir herausfinden, welche Komponenten möglicherweise zur Entstehung des Staus beitragen. Könnte es eines der Hunderte von iptables-Regeln im NAT sein? Oder gibt es Probleme mit der IPIP-Tunnellierung im Netzwerk? Eine Möglichkeit, dies zu überprüfen, besteht darin, jeden Schritt des Systems auszuschließen. Was passiert, wenn wir NAT und die Logik der Firewall entfernen und nur den IPIP-Teil behalten:
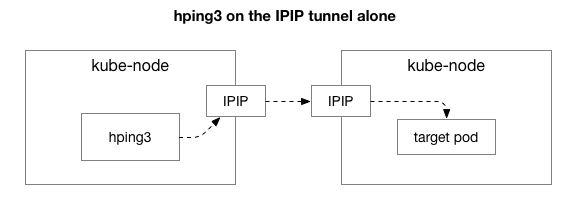
Glücklicherweise ermöglicht Linux einen einfachen Zugriff auf die Overlay-Schicht von IP, wenn die Maschine im gleichen Netzwerk ist:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127,3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117,3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107,2 ms
Nach den Ergebnissen besteht das Problem weiterhin! Das schließt iptables und NAT aus. Bedeutet das, dass das Problem im TCP-Bereich liegt? Lassen Sie uns sehen, wie der normale ICMP-Ping aussieht:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 ms
Die Ergebnisse zeigen, dass das Problem nicht verschwunden ist. Könnte es sich um das IPIP-Tunneling handeln? Lassen Sie uns den Test weiter vereinfachen:
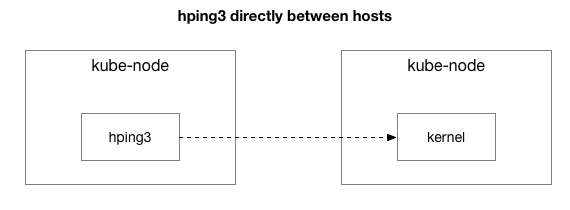
Werden alle Pakete zwischen diesen beiden Hosts gesendet?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104,2 ms
Wir haben die Situation auf zwei Kubernetes-Knoten vereinfacht, die sich gegenseitig jedes Paket, auch ICMP-Pings, senden. Sie stellen trotzdem Verzögerungen fest, wenn der Zielhost "schlecht" ist (einige sind schlechter als andere).
Nun die letzte Frage: Warum tritt die Verzögerung nur auf den kube-node-Servern auf? Und passiert sie, wenn der kube-node Absender oder Empfänger ist? Glücklicherweise ist dies auch ziemlich leicht herauszufinden, indem man ein Paket von einem Host außerhalb von Kubernetes an den selben "bekannten schlechten" Empfänger sendet. Wie wir sehen, ist das Problem nicht verschwunden:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108,5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119,4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139,9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131,2 ms
Führen wir dann die gleichen Anfragen vom vorherigen Ursprung kube-node an einen externen Host aus (was den Ursprungshost ausschließt, da das Ping sowohl RX- als auch TX-Komponenten umfasst):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping Statistik ---
22352 Pakete übertragen, 22350 Pakete empfangen, 1% Paketverlust
Hin- und Rückweg min/avg/max = 0,2/7,6/1010,6 ms
Nach der Analyse der Paket-Trace mit Verzögerung haben wir einige zusätzliche Informationen erhalten. Insbesondere sieht der Absender (unten) dieses Timeout, während der Empfänger (oben) es nicht sieht – siehe die Delta-Spalte (in Sekunden):
Darüber hinaus zeigt die Analyse der Reihenfolge der TCP- und ICMP-Pakete (nach Sequenznummern) auf der Empfängerseite, dass ICMP-Pakete immer in der gleichen Reihenfolge ankommen, in der sie gesendet wurden, jedoch mit unterschiedlichen Zeitpunkten. Gleichzeitig können TCP-Pakete manchmal durcheinandergeraten, und einige davon bleiben stecken. Insbesondere zeigt die Untersuchung der SYN-Pakete, dass sie auf der Absenderseite in der richtigen Reihenfolge gesendet werden, auf der Empfängerseite jedoch nicht.
Es gibt einen feinen Unterschied in der Art und Weise, wie Moderne Server (wie in unserem Rechenzentrum) verarbeiten Pakete, die TCP oder ICMP enthalten. Wenn ein Paket eintrifft, hashert der Netzwerkadapter es gemäß der Verbindung, das heißt, er versucht, Verbindungen in Warteschlangen zu gliedern und jede Warteschlange an einen separaten Prozessor-Kern zu senden. Für TCP beinhaltet dieser Hash sowohl die Quell- als auch die Ziel-IP-Adresse und den Port. Mit anderen Worten, jede Verbindung wird (potenziell) unterschiedlich gehasht. Für ICMP werden nur die IP-Adressen gehasht, da keine Ports vorhanden sind.
Eine weitere neue Beobachtung: Während dieses Zeitraums sehen wir ICMP-Verzögerungen bei allen Kommunikationen zwischen zwei Hosts, während TCP keine zeigt. Das deutet darauf hin, dass die Ursache wahrscheinlich mit dem Hashing der RX-Warteschlangen zusammenhängt: Fast sicher entsteht der Engpass in der Verarbeitung von RX-Paketen und nicht beim Senden von Antworten.
Dies schließt das Senden von Paketen als mögliche Ursache aus. Jetzt wissen wir, dass das Problem mit der Paketverarbeitung auf der Empfangsseite bei bestimmten kube-node-Servern liegt.
Wir untersuchen die Paketverarbeitung im Linux-Kernel.
Um zu verstehen, warum das Problem bei Empfängern auf einigen kube-node-Servern auftritt, schauen wir uns an, wie der Linux-Kernel Pakete verarbeitet.
Zurück zur einfachsten traditionellen Implementierung: die Netzwerkkarte empfängt ein Paket und sendet an den Linux-Kernel, dass ein Paket zur Verarbeitung ansteht. Der Kernel stoppt andere Arbeiten, wechselt den Kontext zum Interrupt-Handler, verarbeitet das Paket und kehrt dann zu den aktuellen Aufgaben zurück.
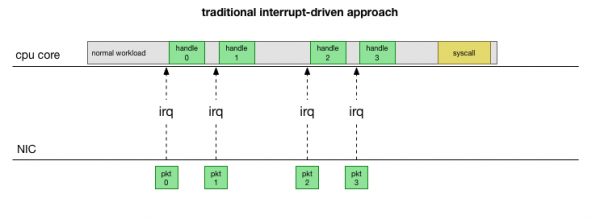
Dieser Kontextwechsel erfolgt langsam: Möglicherweise war die Verzögerung auf 10-Mbit-Netzwerkkarten in den 90er Jahren unauffällig, aber auf modernen 10G-Karten mit einer maximalen Bandbreite von 15 Millionen Paketen pro Sekunde kann jeder Kern eines kleinen achtkernigen Servers Millionen von Malen pro Sekunde unterbrochen werden.
Um die ständige Verarbeitung von Unterbrechungen zu vermeiden, wurde vor vielen Jahren in Linux : eine Netz-API, die von allen modernen Treibern verwendet wird, um die Leistung bei hohen Geschwindigkeiten zu erhöhen. Bei niedrigen Geschwindigkeiten empfängt der Kernel weiterhin Interrupts von der Netzwerkkarte auf die alte Weise. Sobald eine ausreichende Anzahl von Paketen eintrifft, die den Schwellenwert überschreitet, deaktiviert der Kernel die Interrupts und beginnt stattdessen, den Netzwerkadapter abzufragen und Pakete in Chargen abzuholen. Die Verarbeitung erfolgt im softirq, also im nach Systemaufrufen und hardwarebasierten Interrupts, wenn der Kernel (im Gegensatz zum Benutzermodus) bereits gestartet ist.
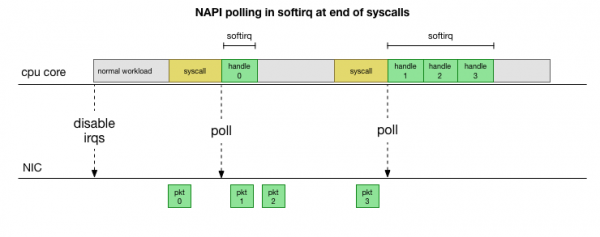
Das ist viel schneller, bringt aber ein anderes Problem mit sich. Wenn es zu viele Pakete gibt, wird die gesamte Zeit mit der Verarbeitung der Pakete von der Netzwerkkarte verbracht, während die Prozesse im Benutzermodus nicht dazu kommen, diese Warteschlangen tatsächlich abzubauen (zum Beispiel das Lesen von TCP-Verbindungen usw.). Schließlich füllen sich die Warteschlangen, und wir beginnen, Pakete abzulehnen. Um ein Gleichgewicht zu finden, legt der Kernel ein Budget für die maximale Anzahl von Paketen fest, die im Kontext von softirq verarbeitet werden dürfen. Sobald dieses Budget überschritten wird, wird ein separater Thread geweckt. ksoftirqd (Sie werden einen davon in ps für jeden Kern sehen), der diese Softirqs außerhalb des normalen syscall-/Interrupt-Pfads verarbeitet. Dieser Thread wird mit dem Standard-Prozessplaner geplant, der versucht, Ressourcen gerecht zu verteilen.
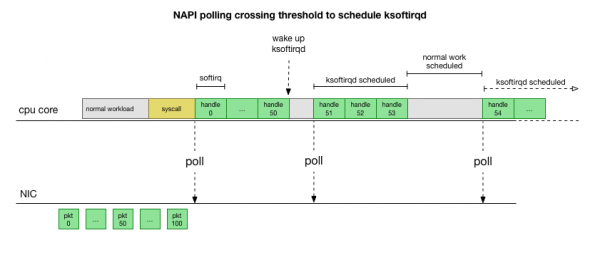
Wenn man untersucht, wie der Kernel Pakete verarbeitet, fällt auf, dass es hier eine gewisse Wahrscheinlichkeit für Engpässe gibt. Wenn die Softirq-Aufrufe seltener eintreffen, müssen die Pakete eine gewisse Zeit in der RX-Warteschlange der Netzwerkkarte warten, um verarbeitet zu werden. Dies könnte durch eine Aufgabe verursacht werden, die den Prozessor blockiert, oder etwas anderes hindert den Kernel daran, Softirqs auszuführen.
Wir verengen die Verarbeitung auf den Kern oder die Methode
Die Verzögerungen bei Softirqs sind bisher nur eine Vermutung. Aber sie macht Sinn, und wir wissen, dass wir etwas sehr Ähnliches beobachten. Daher besteht der nächste Schritt darin, diese Theorie zu bestätigen. Sollte sie bestätigt werden, gilt es, die Ursache für die Verzögerungen zu finden.
Kommen wir zurück zu unseren langsamen Paketen:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 ms
Wie bereits zuvor besprochen, werden diese ICMP-Pakete in eine Warteschlange der NIC RX gehämmert und von einem CPU-Kern verarbeitet. Um das Verhalten von Linux zu verstehen, ist es hilfreich zu wissen, wo (auf welchem CPU-Kern) und wie (softirq, ksoftirqd) diese Pakete verarbeitet werden, um den Prozess nachzuvollziehen.
Jetzt ist es an der Zeit, Werkzeuge zu verwenden, die es ermöglichen, die Arbeit des Linux-Kernels in Echtzeit zu überwachen. Hier haben wir verwendet . Dieses Toolkit ermöglicht es, kleine Programme in C zu schreiben, die beliebige Funktionen im Kernel abfangen und Ereignisse in ein Python-Programm des Benutzers puffern, das sie verarbeiten und Ihnen das Ergebnis zurückgeben kann. Hooks für beliebige Funktionen im Kernel sind komplex, aber das Tool wurde mit maximaler Sicherheit entwickelt und ist darauf ausgelegt, genau solche Produktionsprobleme zu verfolgen, die sich schwer in einer Test- oder Entwicklungsumgebung reproduzieren lassen.
Der Plan ist einfach: Wir wissen, dass der Kernel diese ICMP-Pings verarbeitet, also setzen wir einen Hook auf die Kernel-Funktion , die eingehende ICMP-Paket-Anfrage «echo request» akzeptiert und eine ICMP-Antwort «echo response» initiiert. Wir können das Paket anhand der erhöhten Nummer icmp_seq identifizieren, die zeigt hping3 oben.
Code wirkt komplex, ist aber nicht so furchterregend, wie es scheint. Die Funktion icmp_echo überträgt struct sk_buff *skb: dies ist das Paket mit der Anfrage «echo request». Wir können es verfolgen, die Sequenz echo.sequence (die mit icmp_seq von hping3 oben), und sie in den Benutzermodus senden. Es ist auch praktisch, den aktuellen Prozessnamen/Identifier zu erfassen. Unten sind die Ergebnisse dargestellt, die wir während der Paketverarbeitung durch den Kernel direkt sehen:
TGID PID PROZESSNAME ICMP_SEQ 0 0 swapper/11 770 0 0 swapper/11 771 0 0 swapper/11 772 0 0 swapper/11 773 0 0 swapper/11 774 20041 20086 prometheus 775 0 0 swapper/11 776 0 0 swapper/11 777 0 0 swapper/11 778 4512 4542 spokes-report-s 779
Hier sollte beachtet werden, dass im Kontext softirq Prozesse, die Systemaufrufe gemacht haben, als «Prozesse» angezeigt werden, obwohl das Kernel tatsächlich sicher Pakete im Kontext des Kernels verarbeitet.
Mit diesem Tool können wir spezifische Prozesse mit bestimmten Paketen verbinden, die Verzögerungen in zeigen. hping3Wir führen eine einfache grep Analyse bei dieser Erfassung für bestimmte Werte durch. icmp_seqDie Pakete, die den oben genannten Werten von icmp_seq entsprechen, wurden zusammen mit ihren RTT markiert, die wir oben beobachtet haben (in Klammern sind die erwarteten RTT-Werte der Pakete angegeben, die wir aufgrund von RTT-Werten unter 50 ms herausgefiltert haben):
TGID PID PROZESSNAME ICMP_SEQ ** RTT -- 10137 10436 cadvisor 1951 10137 10436 cadvisor 1952 76 76 ksoftirqd/11 1953 ** 99ms 76 76 ksoftirqd/11 1954 ** 89ms 76 76 ksoftirqd/11 1955 ** 79ms 76 76 ksoftirqd/11 1956 ** 69ms 76 76 ksoftirqd/11 1957 ** 59ms 76 76 ksoftirqd/11 1958 ** (49ms) 76 76 ksoftirqd/11 1959 ** (39ms) 76 76 ksoftirqd/11 1960 ** (29ms) 76 76 ksoftirqd/11 1961 ** (19ms) 76 76 ksoftirqd/11 1962 ** (9ms) -- 10137 10436 cadvisor 2068 10137 10436 cadvisor 2069 76 76 ksoftirqd/11 2070 ** 75ms 76 76 ksoftirqd/11 2071 ** 65ms 76 76 ksoftirqd/11 2072 ** 55ms 76 76 ksoftirqd/11 2073 ** (45ms) 76 76 ksoftirqd/11 2074 ** (35ms) 76 76 ksoftirqd/11 2075 ** (25ms) 76 76 ksoftirqd/11 2076 ** (15ms) 76 76 ksoftirqd/11 2077 ** (5ms)
Die Ergebnisse zeigen uns mehrere Dinge. Erstens, all diese Pakete werden vom Kontext ksoftirqd/11. Dies bedeutet, dass für dieses spezifische Maschinenpaar die ICMP-Pakete auf Kern 11 der empfangenden Seite gehasht wurden. Wir sehen auch, dass bei jedem Stau Pakete vorhanden sind, die im Kontext eines Systemaufrufs verarbeitet werden. cadvisor. Dann ksoftirqd übernimmt die Aufgabe und verarbeitet die angesammelte Warteschlange: genau die Anzahl der Pakete, die sich danach angesammelt hat. cadvisor.
Die Tatsache, dass kurz davor immer cadvisor, impliziert seine Beteiligung an dem Problem. Ironischerweise ist die Aufgabe — "Ressourcennutzung und Leistungsmerkmale der ausgeführten Container zu analysieren", und nicht diese Leistungsproblematik auszulösen.
Wie bei anderen Aspekten der Containerarbeit ist dies ein äußerst fortschrittliches Werkzeug, von dem man durchaus erwarten kann, dass es in bestimmten unvorhergesehenen Umständen zu Leistungsproblemen führt.
Was macht cadvisor, das die Paketwarteschlange verlangsamt?
Jetzt haben wir ein recht gutes Verständnis davon, wie der Fehler auftritt, welcher Prozess ihn verursacht und auf welchem CPU. Wir sehen, dass aufgrund eines strengen Lockings der Linux-Kernel nicht rechtzeitig planen kann. ksoftirqd. Und wir sehen, dass die Pakete im Kontext verarbeitet werden. cadvisor. Es liegt nahe zu vermuten, dass cadvisor ein langsamer Systemaufruf ausgeführt wird, nach dem alle in der Zwischenzeit angesammelten Pakete verarbeitet werden:
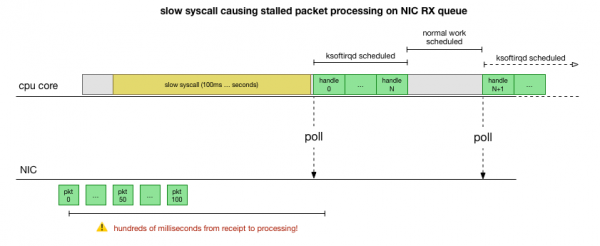
Das ist die Theorie, aber wie überprüfen wir sie? Was wir tun können, ist, die CPU-Kernaktivität während dieses Prozesses zu verfolgen, den Punkt zu finden, an dem das Budget für die Anzahl der Pakete überschritten wird und ksoftirqd aufgerufen wird, und dann kurz vorher zu schauen, was genau auf dem CPU-Kern direkt davor gelaufen ist. Es ist wie ein Röntgenbild der CPU alle paar Millisekunden. Es würde ungefähr so aussehen:
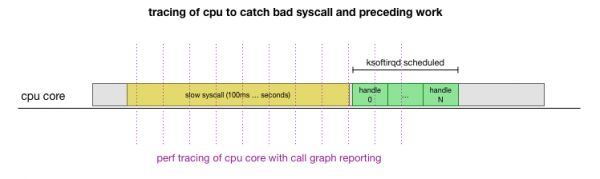
Es ist praktisch, dass all dies mit bestehenden Tools gemacht werden kann. Zum Beispiel überprüft mit einer angegebenen Frequenz den angegebenen CPU-Kern und kann ein Aufrufverlauf-Diagramm des laufenden Systems erzeugen, einschließlich sowohl des Benutzer- als auch des Linux-Kernels. Man kann diese Aufzeichnung nehmen und sie mit einem kleinen Fork des Programms von Brendan Gregg, der die Stack-Traces aufbewahrt. Wir können einzeilige Stack-Traces alle 1 ms speichern und dann alle 100 Millisekunden ein Sample extrahieren und speichern, bevor es in den Trace gelangt. ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
Hier sind die Ergebnisse:
(Hunderte von Traces, die ähnlich aussehen)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
Hier gibt es viel zu entdecken, aber das Wichtigste ist, dass wir das Muster „cadvisor vor ksoftirqd“ finden, das wir zuvor im ICMP-Tracer gesehen haben. Was bedeutet das?
Jede Zeile ist eine CPU-Trace zu einem bestimmten Zeitpunkt. Jeder Aufruf im Stack wird durch ein Semikolon getrennt. In der Mitte der Zeilen sehen wir den aufgerufenen syscall: read(): .... ;do_syscall_64;sys_read; .... Somit verbringt cadvisor viel Zeit mit dem Systemaufruf read(), der sich auf die Funktionen mem_cgroup_* bezieht (obere Stackebene/Ende der Zeile).
Im Trace ist es unpraktisch zu sehen, was genau gelesen wird, also starten wir strace und schauen, was cadvisor macht und finden Systemaufrufe, die länger als 100 ms dauern:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] ) = 0
[pid 10432] ) = 0
[pid 10137] ) = 0
[pid 10384] ) = 0
[pid 10436] "cache 154234880nrss 507904nrss_h"..., 4096) = 658
[pid 10384] ) = 0
[pid 10436] ) = 0
[pid 10436] "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577
[pid 10427] "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577
[pid 10411] ) = 0
[pid 10382] ) = 0 (Timeout)
[pid 10436] "cache 154234880nrss 507904nrss_h"..., 4096) = 660
[pid 10417] ) = 0
[pid 10436] ) = 0
[pid 10417] ) = 0
[pid 10417] "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576
Wie zu erwarten, sehen wir hier langsame Aufrufe read(). Aus dem Inhalt der Lesevorgänge und dem Kontext mem_cgroup ist ersichtlich, dass diese Aufrufe read() sich auf die Datei memory.stat, die die Speichernutzung und die Begrenzungen der cgroup (Ressourcensperrtechnologie in Docker) zeigt. Das Tool cadvisor greift auf diese Datei zu, um Informationen über die Ressourcennutzung der Container zu erhalten. Lassen Sie uns überprüfen, ob es am Kernel liegt oder ob cadvisor etwas Unerwartetes tut:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m0.153s
user 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $
Jetzt können wir den Fehler reproduzieren und verstehen, dass der Linux-Kernel mit einer Anomalie konfrontiert ist.
Was macht den Lesevorgang so langsam?
An diesem Punkt ist es viel einfacher, Berichte anderer Benutzer über ähnliche Probleme zu finden. Wie sich herausstellte, wurde in der Cadvisor-Tracking-Datenbank über diesen Fehler berichtet als , nur hat niemand bemerkt, dass die Verzögerung auch zufällig im Netzwerk-Stack reflektiert wird. Tatsächlich wurde festgestellt, dass Cadvisor mehr Rechenleistung verbraucht als erwartet, aber dem wurde nicht viel Bedeutung beigemessen, da unsere Server über ausreichende CPU-Ressourcen verfügen, weshalb das Problem nicht eingehender untersucht wurde.
Das Problem liegt darin, dass die Kontrollgruppen (cgroups) den Speicherverbrauch innerhalb des Namensraums (Containers) berücksichtigen. Wenn alle Prozesse in dieser cgroup beendet sind, gibt Docker die Speicher-Kontrollgruppe frei. Allerdings ist „Speicher“ nicht nur der Speicher des Prozesses. Auch wenn der Speicher der Prozesse nicht mehr verwendet wird, stellt sich heraus, dass der Kernel zusätzlich noch zwischengespeicherte Inhalte wie dentries und inodes (Metadaten von Verzeichnissen und Dateien) zuweist, die in der Speicher-cgroup zwischengespeichert werden. Aus der Problembeschreibung:
Zombie-cgroups: Kontrollgruppen, in denen keine Prozesse mehr vorhanden sind und die gelöscht wurden, für die jedoch weiterhin Speicher zugewiesen ist (in meinem Fall aus dem dentry-Cache, aber sie kann auch aus dem Seiten-Cache oder tmpfs zugewiesen werden).
Die Überprüfung durch den Kernel aller Seiten im Cache beim Freigeben der cgroup kann sehr zeitaufwändig sein, weshalb ein langsamer Prozess gewählt wurde: zu warten, bis diese Seiten erneut angefordert werden, und erst dann, wenn der Speicher tatsächlich benötigt wird, die cgroup letztendlich zu bereinigen. Bis zu diesem Zeitpunkt wird die cgroup weiterhin bei der Erfassung von Statistiken berücksichtigt.
In Bezug auf die Leistung wurde RAM zugunsten der Performance geopfert: Die anfängliche Bereinigung wird beschleunigt, da ein wenig Cache-RAM übrig bleibt. Das ist in Ordnung. Wenn der Kernel den letzten Teil des cache-RAMs nutzt, wird die cgroup schließlich bereinigt, sodass dies nicht als "Leak" bezeichnet werden kann. Leider führt die spezifische Implementierung des Suchmechanismus memory.stat in dieser Kernelversion (4.9), in Kombination mit der enormen Menge an RAM auf unseren Servern, dazu, dass das Wiederherstellen der letzten gecachten Daten und das Bereinigen von cgroup-Zombis viel mehr Zeit in Anspruch nimmt.
Es stellte sich heraus, dass auf einigen unserer Knoten so viele cgroup-Zombies vorhanden waren, dass das Lesen und die Verzögerung über eine Sekunde betrugen.
Ein Weg, das Problem von cadvisor zu umgehen, besteht darin, die Cache-Dentries/Inodes im gesamten System sofort freizugeben, was sofort die Leseverzögerung beseitigt, sowie die Netzwerkverzögerung auf dem Host, da das Entfernen des Caches auch die gecachten Seiten der cgroup-Zombies einschließt, die ebenfalls freigegeben werden. Das ist keine Lösung, bestätigt jedoch die Ursache des Problems.
Es stellte sich heraus, dass in neueren Kernelversionen (4.19+) die Leistungsfähigkeit der Aufrufe verbessert wurde. memory.stat, sodass der Wechsel zu diesem Kernel das Problem behob. Gleichzeitig hatten wir Werkzeuge zur Identifizierung problematischer Knoten in Kubernetes-Clustern, deren eleganten Abbau und Neustart. Wir durchsuchten alle Cluster, fanden Knoten mit ausreichend hoher Latenz und führten deren Neustart durch. Das gab uns Zeit, das Betriebssystem auf den verbleibenden Servern zu aktualisieren.
Zusammenfassend
Da dieser Bug die Verarbeitung der NIC RX-Warteschlangen um Hunderte von Millisekunden stoppte, verursachte er gleichzeitig sowohl große Verzögerungen bei kurzen Verbindungen als auch Verzögerungen in der Mitte der Verbindung, beispielsweise zwischen MySQL-Anfragen und den entsprechenden Paketen.
Das Verständnis und die Unterstützung der Leistung der grundlegendsten Systeme wie Kubernetes sind entscheidend für die Zuverlässigkeit und Geschwindigkeit aller darauf basierenden Dienste. Alle betriebenen Systeme profitieren von Leistungsverbesserungen in Kubernetes.
Quelle: habr.com
