

, ein Tool zur Sammlung, Transformation und Übertragung von Protokolldaten, Metriken und Ereignissen.
→
Geschrieben in Rust, bietet es eine hohe Leistung und einen geringen RAM-Verbrauch im Vergleich zu anderen Lösungen. Zudem wird großer Wert auf Korrektheit gelegt, insbesondere auf die Möglichkeit, nicht gesendete Ereignisse im Puffer auf der Festplatte zu speichern und die Verwaltung von Protokolldateien.
Architektonisch ist Vector ein Event-Router, der Nachrichten aus einer oder mehreren Quellen, optional diese Nachrichten bearbeitet und sie an einen oder mehrereSenken sendet. Vector ist ein Ersatz für Filebeat und Logstash, es kann in beiden Rollen fungieren (Protokolle empfangen und senden), mehr dazu in ihrer.
Wenn die Pipeline in Logstash wie input → filter → output aufgebaut ist, dann ist dies in Vector .
sources → →
Diese Anleitung ist eine überarbeitete Version der Anleitung von
Wjatscheslaw Rachinski . In der Originalanleitung gibt es eine GeoIP-Verarbeitung. Bei meinen Tests von der internen Netzwerkverbindung aus gab es einen Fehler mit Vector.
05. Aug 06:25:31.889 DEBUG transform{name=nginx_parse_rename_fields type=rename_fields}: vector::transforms::rename_fields: Feld existiert nicht, field=«geoip.country_name» rate_limit_secs=30Wenn jemand GeoIP verarbeiten muss, wenden Sie sich bitte an die Originalanleitung von .
Wir werden die Verbindung Nginx (Zugriffsprotokolle) → Vector (Client | Filebeat) → Vector (Server | Logstash) → separat in Clickhouse und separat in Elasticsearch einrichten. Wir installieren 4 Server. Es ist jedoch möglich, es mit 3 Servern zu machen.
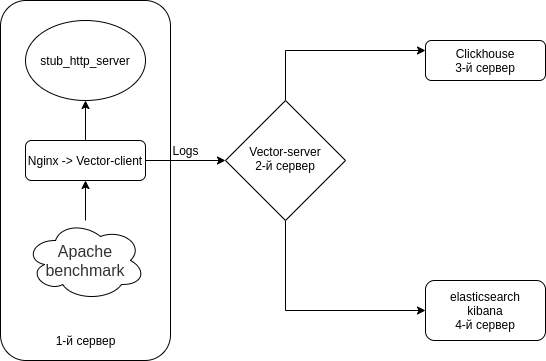
Das Schema sieht ungefähr so aus.
Wir deaktivieren Selinux auf all Ihren Servern.
sed -i 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
rebootAuf allen Servern installieren wir einen HTTP-Server-Emulator + Tools.
Als HTTP-Server-Emulator verwenden wir ab
Nodejs-stub-server hat kein rpm. Wir erstellen ihm ein rpm. Das rpm wird mit Hilfe von
Wir fügen das Repository antonpatsev/nodejs-stub-server hinzu.
yum -y install yum-plugin-copr epel-release
yes | yum copr enable antonpatsev/nodejs-stub-serverWir installieren nodejs-stub-server, Apache Benchmark und den Terminal-Multiplexer screen auf allen Servern.
yum -y install stub_http_server screen mc httpd-tools screenIch habe die Antwortzeit des stub_http_server in der Datei /var/lib/stub_http_server/stub_http_server.js angepasst, um mehr Protokolle zu erhalten.
var max_sleep = 10;Wir starten den stub_http_server.
systemctl start stub_http_server
systemctl enable stub_http_serverauf dem 3. Server.
ClickHouse verwendet den SSE 4.2 Befehlssatz. Daher wird die Unterstützung durch den verwendeten Prozessor, sofern nicht anders angegeben, zu einer zusätzlichen Systemanforderung. Hier ist der Befehl, um zu überprüfen, ob der aktuelle Prozessor SSE 4.2 unterstützt:
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 unterstützt" || echo "SSE 4.2 nicht unterstützt"Zuerst müssen Sie das offizielle Repository aktivieren:
sudo yum install -y yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64Um Pakete zu installieren, führen Sie die folgenden Befehle aus:
sudo yum install -y clickhouse-server clickhouse-clientErlauben Sie clickhouse-server, die Netzwerkkarte in der Datei /etc/clickhouse-server/config.xml zu hören.
0.0.0.0Ändern Sie die Protokollierung von trace auf debug.
debug
Die Kompressionseinstellungen sind standardmäßig:
min_compress_block_size 65536
max_compress_block_size 1048576Um die Zstd-Kompression zu aktivieren, wird empfohlen, die Konfiguration nicht zu ändern und besser DDL zu verwenden.
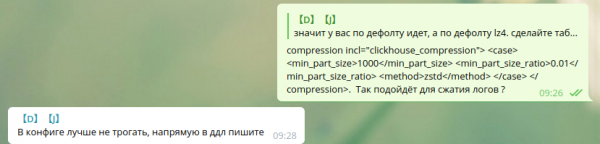
Wie man Zstd-Kompression über DDL anwendet, habe ich bei Google nicht gefunden. Daher habe ich es so belassen.
Kollegen, die Zstd-Kompression in ClickHouse verwenden – bitte teilen Sie Ihre Anleitungen.
Um den Server als Daemon zu starten, führen Sie aus:
service clickhouse-server startJetzt wenden wir uns der Konfiguration von ClickHouse zu.
Loggen Sie sich in ClickHouse ein.
clickhouse-client -h 172.26.10.109 -m172.26.10.109 — IP-Adresse des Servers, auf dem Clickhouse installiert ist.
Erstellen wir die Datenbank vector
CREATE DATABASE vector;Überprüfen wir, ob die Datenbank vorhanden ist.
show databases;Wir erstellen die Tabelle vector.logs.
/* Это таблица где хранятся логи как есть */
CREATE TABLE vector.logs
(
`node_name` String,
`timestamp` DateTime,
`server_name` String,
`user_id` String,
`request_full` String,
`request_user_agent` String,
`request_http_host` String,
`request_uri` String,
`request_scheme` String,
`request_method` String,
`request_length` UInt64,
`request_time` Float32,
`request_referrer` String,
`response_status` UInt16,
`response_body_bytes_sent` UInt64,
`response_content_type` String,
`remote_addr` IPv4,
`remote_port` UInt32,
`remote_user` String,
`upstream_addr` IPv4,
`upstream_port` UInt32,
`upstream_bytes_received` UInt64,
`upstream_bytes_sent` UInt64,
`upstream_cache_status` String,
`upstream_connect_time` Float32,
`upstream_header_time` Float32,
`upstream_response_length` UInt64,
`upstream_response_time` Float32,
`upstream_status` UInt16,
`upstream_content_type` String,
INDEX idx_http_host request_http_host TYPE set(0) GRANULARITY 1
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY timestamp
TTL timestamp + toIntervalMonth(1)
SETTINGS index_granularity = 8192;Überprüfen wir, ob die Tabellen erstellt wurden. Starten wir clickhouse-client und machen eine Anfrage.
Wir wechseln zur Datenbank vector.
use vector;
Ok.
0 Zeilen im Ergebnis. Verstrichene Zeit: 0.001 Sekunden.Sehen wir uns die Tabellen an.
show tables;
┌─name────────────────┐
│ logs │
└─────────────────────┘Installation von Elasticsearch auf dem vierten Server, um dieselben Daten an Elasticsearch zu senden und mit Clickhouse zu vergleichen
Fügen wir den öffentlichen RPM-Schlüssel hinzu
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchLegen wir 2 Repositories an:
/etc/yum.repos.d/elasticsearch.repo
[elasticsearch]
name=Elasticsearch-Repository für 7.x-Pakete
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md/etc/yum.repos.d/kibana.repo
[kibana-7.x]
name=Kibana-Repository für 7.x-Pakete
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdInstallieren wir Elasticsearch und Kibana
yum install -y kibana elasticsearchDa es in einer Instanz sein wird, müssen wir in die Datei /etc/elasticsearch/elasticsearch.yml Folgendes hinzufügen:
discovery.type: single-nodeDamit Vector Daten von einem anderen Server an Elasticsearch senden kann, ändern wir network.host.
network.host: 0.0.0.0Um eine Verbindung zu Kibana herzustellen, ändern wir den Parameter server.host in die Datei /etc/kibana/kibana.yml
server.host: "0.0.0.0"Wir starten und aktivieren Elasticsearch im Autostart
systemctl enable elasticsearch
systemctl start elasticsearchund Kibana
systemctl enable kibana
systemctl start kibanaEinstellungen für Elasticsearch im Single-Node-Modus mit 1 Shard und 0 Replikaten. Wahrscheinlich haben Sie ein Cluster mit vielen Servern und müssen dies nicht tun.
Für zukünftige Indizes aktualisieren wir die Standardvorlage:
curl -X PUT http://localhost:9200/_template/default -H 'Content-Type: application/json' -d '{"index_patterns": ["*"],"order": -1,"settings": {"number_of_shards": "1","number_of_replicas": "0"}}' Installation von als Ersatz für Logstash auf dem zweiten Server
yum install -y https://packages.timber.io/vector/0.9.X/vector-x86_64.rpm mc httpd-tools screenWir konfigurieren Vector als Ersatz für Logstash. Bearbeiten Sie die Datei /etc/vector/vector.toml.
# /etc/vector/vector.toml
data_dir = "/var/lib/vector"
[sources.nginx_input_vector]
# General
type = "vector"
address = "0.0.0.0:9876"
shutdown_timeout_secs = 30
[transforms.nginx_parse_json]
inputs = [ "nginx_input_vector" ]
type = "json_parser"
[transforms.nginx_parse_add_defaults]
inputs = [ "nginx_parse_json" ]
type = "lua"
version = "2"
hooks.process = """
function (event, emit)
function split_first(s, delimiter)
result = {};
for match in (s..delimiter):gmatch("(.-)"..delimiter) do
table.insert(result, match);
end
return result[1];
end
function split_last(s, delimiter)
result = {};
for match in (s..delimiter):gmatch("(.-)"..delimiter) do
table.insert(result, match);
end
return result[#result];
end
event.log.upstream_addr = split_first(split_last(event.log.upstream_addr, ', '), ':')
event.log.upstream_bytes_received = split_last(event.log.upstream_bytes_received, ', ')
event.log.upstream_bytes_sent = split_last(event.log.upstream_bytes_sent, ', ')
event.log.upstream_connect_time = split_last(event.log.upstream_connect_time, ', ')
event.log.upstream_header_time = split_last(event.log.upstream_header_time, ', ')
event.log.upstream_response_length = split_last(event.log.upstream_response_length, ', ')
event.log.upstream_response_time = split_last(event.log.upstream_response_time, ', ')
event.log.upstream_status = split_last(event.log.upstream_status, ', ')
if event.log.upstream_addr == "" then
event.log.upstream_addr = "127.0.0.1"
end
if (event.log.upstream_bytes_received == "-" or event.log.upstream_bytes_received == "") then
event.log.upstream_bytes_received = "0"
end
if (event.log.upstream_bytes_sent == "-" or event.log.upstream_bytes_sent == "") then
event.log.upstream_bytes_sent = "0"
end
if event.log.upstream_cache_status == "" then
event.log.upstream_cache_status = "DISABLED"
end
if (event.log.upstream_connect_time == "-" or event.log.upstream_connect_time == "") then
event.log.upstream_connect_time = "0"
end
if (event.log.upstream_header_time == "-" or event.log.upstream_header_time == "") then
event.log.upstream_header_time = "0"
end
if (event.log.upstream_response_length == "-" or event.log.upstream_response_length == "") then
event.log.upstream_response_length = "0"
end
if (event.log.upstream_response_time == "-" or event.log.upstream_response_time == "") then
event.log.upstream_response_time = "0"
end
if (event.log.upstream_status == "-" or event.log.upstream_status == "") then
event.log.upstream_status = "0"
end
emit(event)
end
"""
[transforms.nginx_parse_remove_fields]
inputs = [ "nginx_parse_add_defaults" ]
type = "remove_fields"
fields = ["data", "file", "host", "source_type"]
[transforms.nginx_parse_coercer]
type = "coercer"
inputs = ["nginx_parse_remove_fields"]
types.request_length = "int"
types.request_time = "float"
types.response_status = "int"
types.response_body_bytes_sent = "int"
types.remote_port = "int"
types.upstream_bytes_received = "int"
types.upstream_bytes_send = "int"
types.upstream_connect_time = "float"
types.upstream_header_time = "float"
types.upstream_response_length = "int"
types.upstream_response_time = "float"
types.upstream_status = "int"
types.timestamp = "timestamp"
[sinks.nginx_output_clickhouse]
inputs = ["nginx_parse_coercer"]
type = "clickhouse"
database = "vector"
healthcheck = true
host = "http://172.26.10.109:8123" # Адрес Clickhouse
table = "logs"
encoding.timestamp_format = "unix"
buffer.type = "disk"
buffer.max_size = 104900000
buffer.when_full = "block"
request.in_flight_limit = 20
[sinks.elasticsearch]
type = "elasticsearch"
inputs = ["nginx_parse_coercer"]
compression = "none"
healthcheck = true
# 172.26.10.116 - сервер где установен elasticsearch
host = "http://172.26.10.116:9200"
index = "vector-%Y-%m-%d"Sie können den Abschnitt transforms.nginx_parse_add_defaults anpassen.
Da diese Konfigurationen für ein kleines CDN verwendet und in upstream_* mehrere Werte ankommen können.
Zum Beispiel:
"upstream_addr": "128.66.0.10:443, 128.66.0.11:443, 128.66.0.12:443"
"upstream_bytes_received": "-, -, 123"
"upstream_status": "502, 502, 200"Wenn dies nicht Ihre Situation ist, kann dieser Abschnitt vereinfacht werden.
Erstellen Sie die Dienstkonfiguration für systemd unter /etc/systemd/system/vector.service.
# /etc/systemd/system/vector.service
[Unit]
Description=Vector
After=network-online.target
Requires=network-online.target
[Service]
User=vector
Group=vector
ExecStart=/usr/bin/vector
ExecReload=/bin/kill -HUP $MAINPID
Restart=no
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=vector
[Install]
WantedBy=multi-user.targetNach der Erstellung der Tabellen können Sie Vector starten.
systemctl enable vector
systemctl start vectorDie Logs von Vector können so eingesehen werden:
journalctl -f -u vectorIn den Logs sollten solche Einträge vorhanden sein.
INFO vector::topology::builder: Gesundheitscheck: Bestanden.
INFO vector::topology::builder: Gesundheitscheck: Bestanden.Auf dem Client (Webserver) — 1. Server
Auf dem Server mit nginx muss IPv6 deaktiviert werden, da in der Tabelle logs in ClickHouse das Feld upstream_addr IPv4 verwendet wird, da ich innerhalb des Netzwerks kein IPv6 nutze. Wenn IPv6 nicht deaktiviert wird, treten folgende Fehler auf:
DB::Exception: Ungültiger IPv4-Wert.: (während das Schlüsselwert upstream_addr gelesen wurde)Möglicherweise möchten die Leser Unterstützung für IPv6 hinzufügen.
Erstellen Sie die Datei /etc/sysctl.d/98-disable-ipv6.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1Einstellungen anwenden
sysctl --systemWir installieren nginx.
Habe die nginx-Repository-Datei /etc/yum.repos.d/nginx.repo hinzugefügt
[nginx-stable]
name=nginx stabil repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=trueInstallieren Sie das Paket nginx
yum install -y nginxZunächst müssen wir das Logformat in Nginx in der Datei /etc/nginx/nginx.conf konfigurieren.
Benutzer nginx;
# Sie müssen die Anzahl der Worker-Prozesse basierend auf Ihrer CPU-Kerne festlegen, nginx profitiert nicht davon, mehr als das einzustellen.
worker_processes auto; # einige letzte Versionen berechnen dies automatisch
# Anzahl der für nginx verwendeten Dateideskriptoren
# Das Limit für die maximalen FDs auf dem Server wird normalerweise vom Betriebssystem festgelegt.
# Wenn Sie die FDs nicht festlegen, werden die OS-Einstellungen verwendet, die standardmäßig 2000 betragen.
worker_rlimit_nofile 100000;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
# gibt den Kontext der Konfigurationsdatei an, in dem die Anweisungen zur Verbindung verarbeitet werden.
events {
# bestimmt, wie viele Clients pro Worker bedient werden
# max clients = worker_connections * worker_processes
# max clients wird auch durch die Anzahl der auf dem System verfügbaren Socket-Verbindungen (~64k) begrenzt
worker_connections 4000;
# optimiert, um viele Clients mit jedem Thread zu bedienen, essentiell für Linux – für Testumgebungen
use epoll;
# so viele Verbindungen wie möglich akzeptieren, kann Worker-Verbindungen überfluten, wenn zu niedrig eingestellt – für Testumgebungen
multi_accept on;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format vector escape=json
'{'
'"node_name":"nginx-vector",'
'"timestamp":"$time_iso8601",'
'"server_name":"$server_name",'
'"request_full": "$request",'
'"request_user_agent":"$http_user_agent",'
'"request_http_host":"$http_host",'
'"request_uri":"$request_uri",'
'"request_scheme": "$scheme",'
'"request_method":"$request_method",'
'"request_length":"$request_length",'
'"request_time": "$request_time",'
'"request_referrer":"$http_referer",'
'"response_status": "$status",'
'"response_body_bytes_sent":"$body_bytes_sent",'
'"response_content_type":"$sent_http_content_type",'
'"remote_addr": "$remote_addr",'
'"remote_port": "$remote_port",'
'"remote_user": "$remote_user",'
'"upstream_addr": "$upstream_addr",'
'"upstream_bytes_received": "$upstream_bytes_received",'
'"upstream_bytes_sent": "$upstream_bytes_sent",'
'"upstream_cache_status":"$upstream_cache_status",'
'"upstream_connect_time":"$upstream_connect_time",'
'"upstream_header_time":"$upstream_header_time",'
'"upstream_response_length":"$upstream_response_length",'
'"upstream_response_time":"$upstream_response_time",'
'"upstream_status": "$upstream_status",'
'"upstream_content_type":"$upstream_http_content_type"'
'}';
access_log /var/log/nginx/access.log main;
access_log /var/log/nginx/access.json.log vector; # Neuer Log im JSON-Format
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}Um Ihre aktuelle Konfiguration nicht zu beschädigen, erlaubt Nginx mehrere access_log-Direktiven.
access_log /var/log/nginx/access.log main; # Standardprotokoll
access_log /var/log/nginx/access.json.log vector; # Neues Protokoll im JSON-FormatVergeuden Sie nicht, eine Regel in logrotate für die neuen Protokolle hinzuzufügen (wenn die Protokolldatei nicht auf .log endet).
Entfernen Sie default.conf aus /etc/nginx/conf.d/
rm -f /etc/nginx/conf.d/default.confFügen Sie den virtuellen Host /etc/nginx/conf.d/vhost1.conf hinzu.
server {
listen 80;
server_name vhost1;
location / {
proxy_pass http://172.26.10.106:8080;
}
}Fügen Sie den virtuellen Host /etc/nginx/conf.d/vhost2.conf hinzu.
server {
listen 80;
server_name vhost2;
location / {
proxy_pass http://172.26.10.108:8080;
}
}Fügen Sie den virtuellen Host /etc/nginx/conf.d/vhost3.conf hinzu.
server {
listen 80;
server_name vhost3;
location / {
proxy_pass http://172.26.10.109:8080;
}
}Fügen Sie den virtuellen Host /etc/nginx/conf.d/vhost4.conf hinzu.
server {
listen 80;
server_name vhost4;
location / {
proxy_pass http://172.26.10.116:8080;
}
}Fügen Sie die virtuellen Hosts in die Datei /etc/hosts ein (172.26.10.106 ist die IP des Servers, auf dem Nginx installiert ist) auf allen Servern:
172.26.10.106 vhost1
172.26.10.106 vhost2
172.26.10.106 vhost3
172.26.10.106 vhost4Und wenn alles bereit ist,
nginx -t
systemctl restart nginxJetzt installieren wir es.
yum install -y https://packages.timber.io/vector/0.9.X/vector-x86_64.rpmErstellen Sie die Einstellungsdatei für systemd unter /etc/systemd/system/vector.service.
[Unit]
Description=Vector
After=network-online.target
Requires=network-online.target
[Service]
User=vector
Group=vector
ExecStart=/usr/bin/vector
ExecReload=/bin/kill -HUP $MAINPID
Restart=no
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=vector
[Install]
WantedBy=multi-user.targetUnd wir werden die Datei Filebeat im Konfigurationsfile /etc/vector/vector.toml anpassen. Die IP-Adresse 172.26.10.108 ist die IP-Adresse des Log-Servers (Vector-Server).
data_dir = "/var/lib/vector"
[sources.nginx_file]
type = "file"
include = [ "/var/log/nginx/access.json.log" ]
start_at_beginning = false
fingerprinting.strategy = "device_and_inode"
[sinks.nginx_output_vector]
type = "vector"
inputs = [ "nginx_file" ]
address = "172.26.10.108:9876"Vergessen Sie nicht, den Benutzer vector der entsprechenden Gruppe hinzuzufügen, damit er die Logdateien lesen kann. Zum Beispiel erstellt nginx unter CentOS Logs mit den Rechten der Gruppe adm.
usermod -a -G adm vectorWir starten den Vector-Dienst.
systemctl enable vector
systemctl start vectorDie Logs von Vector können so eingesehen werden:
journalctl -f -u vectorIn den Logs sollte folgender Eintrag erscheinen:
INFO vector::topology::builder: Healthcheck: Passed.Lasttest
Der Test wird mit Apache Benchmark durchgeführt.
Auf allen Servern wurde das Paket httpd-tools installiert.
Wir starten den Test mit Apache Benchmark von 4 verschiedenen Servern in Screen. Zuerst starten wir den terminal multiplexer Screen, und dann führen wir den Test mit Apache Benchmark aus. Wie man mit Screen arbeitet, finden Sie in .
Server 1
while true; do ab -H "User-Agent: 1server" -c 100 -n 10 -t 10 http://vhost1/; sleep 1; doneVom 2. Server
while true; do ab -H "User-Agent: 2server" -c 100 -n 10 -t 10 http://vhost2/; sleep 1; doneVom 3. Server
while true; do ab -H "User-Agent: 3server" -c 100 -n 10 -t 10 http://vhost3/; sleep 1; doneVom 4. Server
while true; do ab -H "User-Agent: 4server" -c 100 -n 10 -t 10 http://vhost4/; sleep 1; doneWir überprüfen die Daten in Clickhouse
Loggen Sie sich in ClickHouse ein.
clickhouse-client -h 172.26.10.109 -mWir führen eine SQL-Abfrage durch
SELECT * FROM vector.logs;
┌─node_name────┬───────────timestamp─┬─server_name─┬─user_id─┬─request_full───┬─request_user_agent─┬─request_http_host─┬─request_uri─┬─request_scheme─┬─request_method─┬─request_length─┬─request_time─┬─request_referrer─┬─response_status─┬─response_body_bytes_sent─┬─response_content_type─┬───remote_addr─┬─remote_port─┬─remote_user─┬─upstream_addr─┬─upstream_port─┬─upstream_bytes_received─┬─upstream_bytes_sent─┬─upstream_cache_status─┬─upstream_connect_time─┬─upstream_header_time─┬─upstream_response_length─┬─upstream_response_time─┬─upstream_status─┬─upstream_content_type─┐
│ nginx-vector │ 2020-08-07 04:32:42 │ vhost1 │ │ GET / HTTP/1.0 │ 1server │ vhost1 │ / │ http │ GET │ 66 │ 0.028 │ │ 404 │ 27 │ │ 172.26.10.106 │ 45886 │ │ 172.26.10.106 │ 0 │ 109 │ 97 │ DISABLED │ 0 │ 0.025 │ 27 │ 0.029 │ 404 │ │
└──────────────┴─────────────────────┴─────────────┴─────────┴────────────────┴────────────────────┴───────────────────┴─────────────┴────────────────┴────────────────┴────────────────┴──────────────┴──────────────────┴─────────────────┴──────────────────────────┴───────────────────────┴───────────────┴─────────────┴─────────────┴───────────────┴───────────────┴─────────────────────────┴─────────────────────┴───────────────────────┴───────────────────────┴──────────────────────┴──────────────────────────┴────────────────────────┴─────────────────┴───────────────────────Ermitteln der Tabellengrößen in Clickhouse
select concat(database, '.', table) as table,
formatReadableSize(sum(bytes)) as size,
sum(rows) as rows,
max(modification_time) as latest_modification,
sum(bytes) as bytes_size,
any(engine) as engine,
formatReadableSize(sum(primary_key_bytes_in_memory)) as primary_keys_size
from system.parts
where active
group by database, table
order by bytes_size desc;Erfahren, wie viel Platz die Logs in Clickhouse beanspruchen.
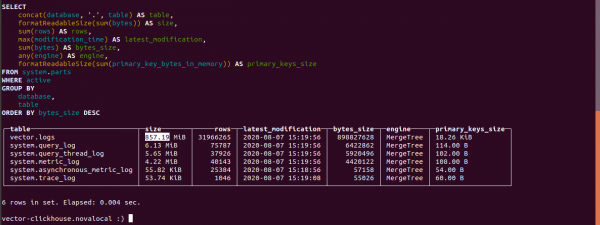
Die Größe der Tabelle logs beträgt 857,19 MB.
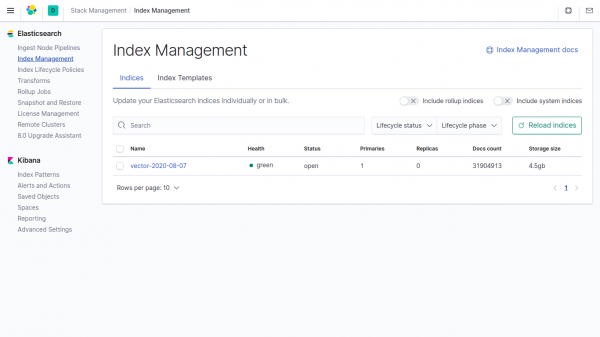
Die Größe der gleichen Daten im Index in Elasticsearch beträgt 4,5 GB.
Wenn im Vector in den Parametern keine Angaben gemacht werden, verbraucht Clickhouse 4500/857,19 = 5,24 Mal weniger als Elasticsearch.
Im Vector-Feld wird die Kompression standardmäßig verwendet.
Telegram-Chat über
Telegram-Chat über
Telegram-Chat über ""
Quelle: habr.com
