


Das Hauptziel von Patroni ist die Gewährleistung der Hochverfügbarkeit für PostgreSQL. Aber Patroni ist nur eine Vorlage und kein fertiges Werkzeug (was in der Dokumentation auch erwähnt wird). Auf den ersten Blick mag es so erscheinen, als sei Patroni in einer Testumgebung ein hervorragendes Werkzeug, das unsere Versuche, den Cluster zu zerstören, mühelos verarbeitet. Doch in der Praxis, in einer Produktionsumgebung, läuft nicht immer alles so glatt und elegant wie im Testlabor.

Ein bisschen über mich: Ich habe als Systemadministrator angefangen. Ich habe in der Webentwicklung gearbeitet. Seit 2014 bin ich bei Data Egret tätig. Das Unternehmen beschäftigt sich mit Beratung im Bereich PostgreSQL. Wir betreuen ausschließlich PostgreSQL und arbeiten jeden Tag damit, weshalb wir über umfangreiche Expertise im Betrieb verfügen.
Ende 2018 haben wir begonnen, Patroni schrittweise einzusetzen. Und es hat sich eine bestimmte Erfahrung angesammelt. Wir haben es diagnostiziert, optimiert und sind zu unseren Best Practices gelangt. In diesem Vortrag werde ich darüber berichten.
Neben Postgres liebe ich Linux. Ich beschäftige mich gerne damit, erkunde es und baue Kerne zusammen. Virtualisierung, Container, Docker, Kubernetes – das alles interessiert mich, denn es spiegelt meine alten Admin-Gewohnheiten wider. Ich beschäftige mich auch gerne mit Monitoring-Systemen. Zudem liebe ich alles, was mit der Verwaltung von Postgres zu tun hat, d.h. Replikation, Backup. In meiner Freizeit programmiere ich in Go. Ich bin kein Software Engineer, programmiere einfach nur für mich selbst in Go. Es macht mir Freude.

- Ich denke, viele von Ihnen wissen, dass Postgres standardmäßig kein HA (High Availability) bietet. Um HA zu erhalten, muss man etwas installieren, einrichten und Aufwand betreiben, um es zu bekommen.
- Es gibt mehrere Werkzeuge und eines davon ist Patroni, das HA ziemlich gut und effektiv löst. Wenn wir dies alles in einer Testumgebung installieren und starten, können wir sehen, dass es alles funktioniert. Wir können Probleme nachstellen und beobachten, wie Patroni damit umgeht. Und wir werden sehen, dass alles hervorragend funktioniert.
- Aber in der Praxis sind wir auf verschiedene Probleme gestoßen. Und über diese Probleme werde ich berichten.
- Ich werde erzählen, wie wir diese diagnostiziert haben, was wir angepasst haben – ob es uns geholfen hat oder nicht.

- Ich werde nicht erklären, wie man Patroni installiert, denn das kann man leicht online finden. Man kann die Konfigurationsdateien einsehen, um zu verstehen, wie alles gestartet und konfiguriert wird. Es ist möglich, sich in die Schemen und Architekturen einzuarbeiten, indem man diesbezüglich Informationen im Internet sucht.
- Ich werde nicht über die Erfahrungen anderer sprechen. Ich teile nur die Probleme, mit denen wir konkret konfrontiert waren.
- Ich werde auch nicht über Probleme außerhalb von Patroni und PostgreSQL berichten. Wenn es beispielsweise um Probleme mit der Lastverteilung geht, als unser Cluster scheiterte, werde ich darüber nicht sprechen.

Und ein kleiner Disclaimer, bevor wir mit unserem Vortrag beginnen.
All diese Probleme, mit denen wir konfrontiert waren, traten in den ersten 6-7-8 Monaten unserer Nutzung auf. Im Laufe der Zeit haben wir unsere internen Best Practices entwickelt, und diese Probleme sind verschwunden. Daher wurde der Vortrag vor etwa sechs Monaten angekündigt, als alles noch frisch in meinem Gedächtnis war und ich mich gut daran erinnerte.
Während der Vorbereitung des Berichts habe ich bereits alte Post-Mortems durchgesehen und Protokolle überprüft. Dabei könnten einige Details vergessen worden sein oder es könnten einige Aspekte während der Problemanalyse nicht ausreichend untersucht worden sein. Daher kann es in manchen Punkten den Anschein erwecken, dass die Probleme nicht vollständig behandelt wurden oder dass es an Informationen mangelt. Ich bitte Sie daher um Verständnis für diesen Punkt.

Was ist Patroni?
- Es ist ein Framework für den Aufbau von Hochverfügbarkeitslösungen. So steht es in der Dokumentation. Ich finde, das ist eine sehr treffende Ausführung. Patroni ist keine universelle Lösung, die alle Ihre Probleme lösen wird; es erfordert Mühe, damit es funktioniert und Nutzen bringt.
- Es handelt sich um einen Agenten, der auf jedem Service mit einer Datenbank installiert wird und der eine Art Init-System für Ihre PostgreSQL-Datenbank darstellt. Er startet, stoppt und startet PostgreSQL neu, ändert die Konfiguration und passt die Topologie Ihres Clusters an.
- Um den Zustand eines Clusters zu speichern, benötigt man ein geeignetes Speichersystem. In dieser Hinsicht verfolgt Patroni den Ansatz, den State in einem externen System zu speichern. Dabei handelt es sich um ein verteiltes Konfigurationsspeichersystem. Dies können Etcd, Consul, ZooKeeper oder der Kubernetes-Etcd sein, also eine dieser Optionen.
- Ein besonderes Merkmal von Patroni ist, dass Sie die automatische Failover-Funktion direkt nach der Konfiguration erhalten. Im Vergleich zu Repmgr ist das Failover dort im Paket enthalten. Mit Repmgr erhalten wir einen Switchover, aber wenn wir ein automatisches Failover wünschen, muss dies zusätzlich konfiguriert werden. Bei Patroni ist das automatische Failover jedoch bereits integriert.
- Es gibt noch viele weitere Aspekte, wie die Verwaltung von Konfigurationen, das Hinzufügen neuer Replikate, Backups usw. Aber das geht über diesen Bericht hinaus, darüber werde ich nicht sprechen.

Zusammenfassend lässt sich sagen, dass die Hauptaufgabe von Patroni darin besteht, ein zuverlässiges automatisches Failover zu gewährleisten, sodass der Cluster funktionsfähig bleibt und die Anwendung keine Änderungen in der Cluster-Topologie bemerkt.

Doch wenn wir beginnen, Patroni zu verwenden, wird unser System etwas komplexer. Hatten wir vorher nur Postgres, so erhalten wir mit Patroni auch Patroni selbst, ein DCS, in dem der Zustand gespeichert wird. Und das Ganze muss irgendwie funktionieren. Also, was kann kaputtgehen?
Folgendes kann kaputtgehen:
- Postgres kann ausfallen. Es kann entweder der Master oder die Replikat sein, eines von beiden kann ausfallen.
- Auch Patroni kann ausfallen.
- Das DCS, in dem der Zustand gespeichert ist, kann ebenfalls kaputtgehen.
- Und auch das Netzwerk kann ausfallen.
Diese Punkte werde ich in meinem Vortrag behandeln.

Ich werde die Fälle nach ihrer Komplexität betrachten, jedoch nicht aus der Perspektive, dass der Fall viele Komponenten betrifft. Vielmehr werde ich meine subjektiven Empfindungen schildern, dass ein bestimmter Fall für mich kompliziert war und schwer zu analysieren… und umgekehrt, dass ein anderer Fall klar und einfach zu verstehen war.

Der erste Fall ist der einfachste. Das ist der Fall, wenn wir einen Datenbankcluster genommen und auf demselben Cluster unser DCS gespeichert haben. Das ist der häufigste Fehler – ein architektonischer Fehler, d. h. das Zusammenführen verschiedener Komponenten an einem Ort.
So, es gab einen Fehler in der Datei, und jetzt gehen wir dem nach, was passiert ist.

Hier interessiert uns der Zeitpunkt, an dem der Failover stattfand. Das heißt, wir wollen diesen Moment wissen, als sich der Status des Clusters geändert hat.
Aber der Failover ist nicht immer sofort, das heißt, er dauert nicht immer einen bestimmten Zeitraum, er kann sich über längere Zeit ziehen. Er kann ein langanhaltendes Ereignis sein.
Deshalb gibt es einen Anfangs- und Endzeitpunkt, das heißt, es handelt sich um ein fortlaufendes Ereignis. Wir teilen alle Ereignisse in drei Abschnitte: die Zeit vor dem Failover, während des Failovers und nach dem Failover. Das heißt, wir betrachten alle Ereignisse auf dieser Zeitachse.

Als Erstes, wenn der Failover stattgefunden hat, suchen wir nach der Ursache, was passiert ist und was zu dem Failover geführt hat.
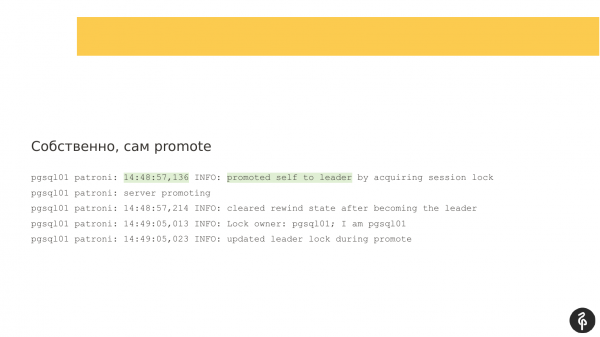
Wenn wir uns die Protokolle ansehen, sind dies die klassischen Protokolle von Patroni. Diese geben uns an, dass der Server zum Master wurde und die Master-Rolle auf diesen Knoten übergegangen ist. Das ist hier hervorgehoben.

Nun müssen wir verstehen, warum ein Failover aufgetreten ist, d. h. welche Ereignisse dazu geführt haben, dass die Masterrolle von einem Knoten auf einen anderen wechselt. In diesem Fall ist es ganz einfach. Wir haben einen Fehler bei der Interaktion mit dem Speichersystem. Der Master hat erkannt, dass er nicht mehr mit DCS arbeiten kann, d. h. es gab ein Problem bei der Interaktion. Er sagt, dass er nicht länger Master sein kann und legt seine Befugnisse nieder. Diese Zeile „demoted self“ beschreibt genau das.

Wenn wir die Ereignisse betrachten, die dem Failover vorausgingen, sehen wir die Ursachen, die das Problem für die Weiterarbeit des Masters verursacht haben.
Ein Blick auf die Patroni-Logs zeigt uns eine Vielzahl von Fehlern und Zeitüberschreitungen, d. h. der Patroni-Agent kann nicht mit DCS arbeiten. In diesem Fall handelt es sich um den Consul-Agenten, mit dem über Port 8500 kommuniziert wird.
Das Problem hier ist, dass Patroni und die Datenbank auf demselben Host ausgeführt werden. Und auf demselben Knoten wurden auch Consul-Server betrieben. Durch die Belastung des Servers haben wir Probleme sowohl für Server Consul geschaffen. Sie konnten nicht ordnungsgemäß kommunizieren.

Nach einer gewissen Zeit, als die Last nachgelassen hatte, konnte unser Patroni wieder mit den Agenten kommunizieren. Der normale Betrieb wurde wieder aufgenommen, und derselbe Server Pgdb-2 wurde erneut zum Master. Das heißt, es gab einen kurzen Flip, bei dem der Knoten seine Master-Rechte ablegte und sie dann wieder annahm, also alles kehrte zu dem zurück, was es war.

Das kann als Fehlalarm gewertet werden, oder man kann argumentieren, dass Patroni alles richtig gemacht hat. Das heißt, er erkannte, dass er den Zustand des Clusters nicht aufrechterhalten konnte und legte seine Master-Rechte nieder.
Das Problem entstand hier, weil sich die Consul-Server auf demselben Equipment wie die Datenbanken befinden. Jede Last, sei es auf die Festplatten oder Prozessoren, wirkt sich daher auch auf die Interaktion mit dem Consul-Cluster aus.

Wir haben beschlossen, dass dies nicht zusammenleben sollte, und haben ein separates Cluster für Consul eingerichtet. Patroni arbeitete dann mit einem separaten Consul, also gab es ein separates Postgres-Cluster und ein separates Consul-Cluster. Dies ist eine grundlegende Anleitung, wie man all diese Dinge verteilen und getrennt halten sollte, damit sie nicht zusammenleben.
Eine Möglichkeit wäre, die Parameter ttl, loop_wait und retry_timeout anzupassen, also zu versuchen, durch Erhöhung dieser Parameter diesen temporären Lastspitzen standzuhalten. Allerdings ist das nicht die beste Lösung, da diese Last auch längere Zeit andauern kann. Wir könnten einfach über die Grenzen dieser Parameter hinausgehen, und das könnte nicht wirklich helfen.
Das erste Problem ist, wie Sie verstanden haben, einfach. Wir haben DCS zusammen mit der Datenbank platziert und dadurch ein Problem erhalten.

Das zweite Problem ähnelt dem ersten. Es hat Ähnlichkeiten, da wir erneut Probleme mit der Interaktion mit dem DCS-System haben.

Wenn wir die Protokolle betrachten, sehen wir, dass erneut ein Kommunikationsfehler vorliegt. Und Patroni sagt, dass er nicht mit DCS kommunizieren kann, weshalb der aktuelle Master in den Replikationsmodus wechselt.
Der alte Master wird zur Replik, hier arbeitet Patroni wie vorgesehen. Er startet pg_rewind, um das Transaktionsprotokoll zurückzusetzen und sich dann mit dem neuen Master zu verbinden, um den neuen Master wieder einzuholen. Patroni hält sich hier an die vorgesehenen Abläufe.

Hier müssen wir den Punkt finden, der dem Failover vorausging, d.h. die Fehler, die dazu führten, dass unser Failover stattfand. In dieser Hinsicht sind die Logs von Patroni recht praktisch. Er schreibt in bestimmten Intervallen dieselben Nachrichten. Wenn wir diese Logs schnell durchscrollen, sehen wir, dass sich die Logs geändert haben, was bedeutet, dass Probleme aufgetreten sind. Wir kehren schnell an diesen Punkt zurück und schauen, was passiert.
In einer normalen Situation sehen die Logs ungefähr so aus: Der Besitzer der Sperre wird überprüft. Wenn der Besitzer beispielsweise gewechselt hat, können bestimmte Ereignisse eintreten, auf die Patroni reagieren muss. In diesem Fall haben wir jedoch alles in Ordnung. Wir suchen den Punkt, an dem die Fehler auftraten.

Wenn wir bis zu dem Punkt zurückscrollen, an dem die Fehler zu erscheinen begannen, sehen wir, dass ein automatisches Failover stattgefunden hat. Da die Fehler mit der Interaktion mit DCS zusammenhingen und wir in unserem Fall Consul verwendeten, schauen wir auch in die Logs von Consul, um zu sehen, was dort passiert ist.
Wenn wir die Zeit des File Servers und die Zeit in den Consul-Protokollen vergleichen, sehen wir, dass unsere Nachbarn im Consul-Cluster anfangen, an der Existenz anderer Teilnehmer des Consul-Clusters zu zweifeln.

Wenn wir uns die Protokolle anderer Consul-Agenten ansehen, erkennen wir ebenfalls, dass es dort zu einem Netzwerkzusammenbruch kommt. Alle Teilnehmer des Consul-Clusters zweifeln an der Existenz voneinander, und dies war der Anstoß für den File Server.
Wenn man betrachtet, was vor diesen Fehlern passiert ist, kann man verschiedene Fehler feststellen, zum Beispiel Deadline-Ausfälle, RPC-Fehler. Das deutet eindeutig auf ein Problem bei der Interaktion der Teilnehmer im Consul-Cluster hin.

Die einfachste Antwort wäre, das Netzwerk zu reparieren. Aber es ist leicht, das von meinem Standpunkt aus zu sagen. Die Umstände sind jedoch so, dass der Kunde nicht immer in der Lage ist, das Netzwerk zu reparieren. Er könnte in einem Rechenzentrum leben und möglicherweise keine Möglichkeit haben, das Netzwerk zu reparieren oder das Equipment zu beeinflussen. Daher sind alternative Lösungen notwendig.

Es gibt Alternativen:
- Die einfachste Möglichkeit, die, meiner Meinung nach, sogar in der Dokumentation beschrieben ist, besteht darin, die Consul-Überprüfungen zu deaktivieren, das heißt, einfach ein leeres Array zu übergeben. Damit sagen wir dem Consul-Agenten, dass er keine Überprüfungen durchführen soll. Dadurch können wir diese Netzwerkstörungen ignorieren und brauchen keine Dateiübertragungen zu initiieren.
- Eine andere Möglichkeit besteht darin, den raft_multiplier zu überprüfen. Dies ist ein Parameter des Consul-Servers. Standardmäßig ist er auf den Wert 5 eingestellt. Dieser Wert wird in der Dokumentation für Staging-Umgebungen empfohlen. Grundsätzlich beeinflusst dies die Frequenz des Nachrichtenaustauschs zwischen den Mitgliedern des Consul-Netzwerks. Dieser Parameter wirkt sich auf die Geschwindigkeit der Kommunikation zwischen den Mitgliedern des Consul-Clusters aus. Für die Produktionsumgebung wird empfohlen, den Wert zu verringern, damit die Knoten häufiger Nachrichten austauschen.
- Eine weitere Vorgehensweise, die wir implementiert haben, besteht darin, die Priorität der Consul-Prozesse im Vergleich zu anderen Prozessen für den Prozess-Scheduler des Betriebssystems zu erhöhen. Es gibt einen Parameter namens "nice", der genau die Priorität der Prozesse bestimmt, die der Betriebssystem-Scheduler bei der Planung berücksichtigt. Wir haben den Wert für unsere Consul-Agenten gesenkt, das heißt, ihre Priorität erhöht, damit das Betriebssystem den Consul-Prozessen mehr Zeit für die Ausführung ihrer Aufgaben und Codes einräumt. In unserem Fall hat dies unser Problem gelöst.
- Eine andere Option ist, Consul nicht zu verwenden. Ich habe einen Kollegen, der ein großer Fan von Etcd ist. Wir diskutieren regelmäßig darüber, was besser ist: Etcd oder Consul. In der Regel sind wir uns jedoch einig, dass Consul einen Agenten benötigt, der auf jedem Knoten mit der Datenbank ausgeführt wird. Das heißt, die Interaktion von Patroni mit dem Consul-Cluster erfolgt über diesen Agenten. Dieser Agent kann zum Engpass werden. Wenn mit dem Agenten etwas schiefgeht, kann Patroni nicht mehr mit dem Consul-Cluster arbeiten. Das ist das Problem. Bei Etcd gibt es keinen solchen Agenten. Patroni kann direkt mit der Liste der Etcd-Server arbeiten und kommunizieren. In dieser Hinsicht wäre Etcd wahrscheinlich die bessere Wahl als Consul, wenn Sie es in Ihrem Unternehmen verwenden. Allerdings sind wir bei unseren Kunden in der Regel an das gebunden, was der Kunde gewählt hat und verwendet. Überwiegend setzen unsere Kunden Consul ein.
- Der letzte Punkt ist, die Parameterwerte zu überprüfen. Wir können diese Parameter erhöhen in der Hoffnung, dass unsere kurzzeitigen Netzwerkprobleme kurz bleiben und nicht den Zeitraum dieser Parameter überschreiten. So können wir die Aggressivität von Patroni bei der automatischen Failover-Funktion verringern, falls Netzwerkprobleme auftreten.
Ich denke, viele, die Patroni verwenden, sind mit diesem Befehl vertraut.
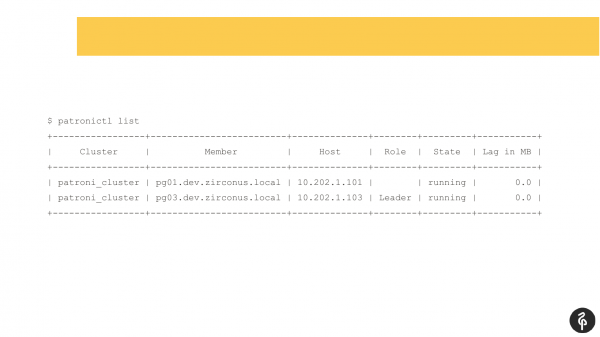
Dieser Befehl zeigt den aktuellen Zustand des Clusters an. Auf den ersten Blick könnte dieses Bild normal erscheinen. Wir haben einen Master, wir haben eine Replik, und es gibt keine Replikationsverzögerung. Aber dieses Bild ist nur dann normal, wenn wir wissen, dass in diesem Cluster drei Knoten und nicht zwei vorhanden sein sollten.

Entsprechend gab es ein automatisches Failover. Nach diesem Failover ist unsere Replik verschwunden. Wir müssen herausfinden, warum sie verschwunden ist und sie zurückholen, wiederherstellen. Und wir gehen erneut in die Logs und schauen, warum das Failover aufgetreten ist.

In diesem Fall ist die zweite Replik zum Master geworden. Hier ist alles in Ordnung.

Wir müssen uns die Replikat ansehen, die getrennt ist und nicht im Cluster ist. Wir öffnen die Patroni-Logs und sehen, dass ein Problem beim Verbindungsaufbau zum Cluster in der Phase pg_rewind aufgetreten ist. Um sich mit dem Cluster zu verbinden, muss das Transaktionsprotokoll zurückgedreht werden, das benötigte Transaktionsprotokoll vom Master angefordert und dann mit dem Master synchronisiert werden.
In diesem Fall haben wir kein Transaktionsprotokoll, und die Replikat kann nicht gestartet werden. Daher stoppen wir Postgres mit einem Fehler. Aus diesem Grund ist sie nicht im Cluster.

Es ist wichtig zu verstehen, warum sie nicht im Cluster ist und warum keine Logs vorhanden sind. Wir schauen uns den neuen Master an und überprüfen die Logs. Es stellt sich heraus, dass während des pg_rewind ein Checkpoint stattfand. Ein Teil der alten Transaktionsprotokolle wurde einfach umbenannt. Als der alte Master versuchte, sich mit dem neuen Master zu verbinden und diese Logs anzufordern, waren sie bereits umbenannt, sie waren einfach nicht mehr da.

Ich habe die Zeitstempel verglichen, als diese Ereignisse stattfanden. Die Differenz betrug nur 150 Millisekunden, d. h. der Checkpoint wurde in 369 Millisekunden abgeschlossen, die WAL-Segmente wurden umbenannt. Und nur 150 Millisekunden später, also nach 517 Millisekunden, startete das Rewind auf der alten Replik. Das heißt, wir hatten buchstäblich 150 Millisekunden, in denen die Replik keine Verbindung herstellen und nicht funktionieren konnte.

Welche Optionen gibt es?
Wir haben zunächst Replikationsslots verwendet. Wir dachten, das wäre gut. Obwohl wir in der ersten Phase des Betriebs die Slots deaktiviert haben. Wir hatten das Gefühl, dass, wenn die Slots zu viele WAL-Segmente anhäufen, wir den Master gefährden könnten. Er könnte ausfallen. Wir haben eine Weile ohne Slots gekämpft und festgestellt, dass wir die Slots brauchen, also haben wir sie zurückgebracht.
Aber hier gibt es ein Problem: Wenn der Master zur Replik wechselt, löscht er die Slots und damit auch die WAL-Segmente. Um diese Problematik zu vermeiden, haben wir beschlossen, den Parameter wal_keep_segments zu erhöhen. Der Standardwert beträgt 8 Segmente. Wir haben ihn auf 1.000 erhöht und geschaut, wie viel Freiraum wir haben. Und wir haben 16 Gigabyte für wal_keep_segments reserviert. Das heißt, bei einem Switch haben wir immer auf allen Knoten einen Puffer von 16 Gigabyte an Transaktionsprotokollen.
Und das ist auch relevant für langfristige Wartungsaufgaben. Angenommen, wir müssen eine der Replikate aktualisieren. Wir möchten sie ausschalten. Wir müssen die Software aktualisieren, möglicherweise das Betriebssystem oder etwas anderes. Wenn wir das Replikat ausschalten, wird auch der Slot für dieses Replikat entfernt. Und wenn wir nur eine kleine Anzahl von wal_keep_segments verwenden, können bei längerer Abwesenheit des Replikats die Transaktionsprotokolle wiedergegeben werden. Wir starten das Replikat neu, es fordert die Transaktionsprotokolle an, an dem Punkt, an dem es gestoppt wurde, aber vielleicht gibt es diese auf dem Master nicht mehr. Und dann kann sich das Replikat auch nicht verbinden. Daher halten wir eine große Menge an Protokollen bereit.

Wir haben eine Produktionsdatenbank. Dort laufen bereits Projekte.
Ein Dateisystemfehler ist aufgetreten. Wir haben nachgesehen und festgestellt, dass alles in Ordnung ist, die Replikate an Ort und Stelle sind, und es gibt keine Verzögerung bei der Replikation. Auch keine Fehler in den Protokollen, alles ist in Ordnung.
Das Produktteam sagt, dass es irgendwie Daten geben sollte, aber wir sehen sie nur an einer Quelle und nicht in der Datenbank. Wir müssen herausfinden, was mit ihnen passiert ist.

Es ist klar, dass pg_rewind sie überschrieben hat. Das haben wir sofort erkannt, aber wir sind gegangen, um zu sehen, was passiert ist.

In den Logs können wir immer feststellen, wann der Failover stattgefunden hat, wer der neue Master wurde und können bestimmen, wer der alte Master war und wann er repliziert werden wollte. Das heißt, wir benötigen diese Logs, um das Volumen der verlorenen Transaktionsprotokolle zu ermitteln.
Unser alter Master wurde neu gestartet. Und im Autostart war Patroni eingetragen. Patroni wurde gestartet und hat dann Postgres gestartet. Genauer gesagt, vor dem Start von Postgres und bevor er ihn replizierte, startete Patroni den Prozess pg_rewind. Dementsprechend hat er einen Teil der Transaktionsprotokolle gelöscht, neue heruntergeladen und sich verbunden. Hier hat Patroni hervorragend funktioniert, also genau wie es sein sollte. Unser Cluster wurde wiederhergestellt. Wir hatten 3 Nodes, nach dem Failover sind es wieder 3 Nodes – alles läuft super.

Wir haben einen Teil der Daten verloren. Und wir müssen herausfinden, wie viel wir verloren haben. Wir suchen genau nach dem Zeitpunkt, an dem der Rewind stattgefunden hat. Das können wir an solchen Einträgen im Log erkennen. Der Rewind wurde gestartet, hat etwas dort gemacht und wurde abgeschlossen.

Wir müssen die Position im Transaktionsprotokoll finden, an der der alte Master gestoppt hat. In diesem Fall ist das dieser Punkt. Und wir benötigen einen zweiten Punkt, also den Abstand, um den sich der alte Master vom neuen unterscheidet.
Wir nehmen die gewöhnliche pg_wal_lsn_diff und vergleichen diese beiden Markierungen. In diesem Fall erhalten wir 17 Megabyte. Ob das viel oder wenig ist, entscheidet jeder für sich. Denn für manche sind 17 Megabyte wenig, für andere viel und inakzeptabel. Hier muss jeder individuell gemäß den Bedürfnissen seines Unternehmens entscheiden.

Aber was haben wir für uns herausgefunden?
Zunächst müssen wir für uns klären – brauchen wir immer den automatischen Start von Patroni nach einem Neustart des Systems? Oftmals ist es so, dass wir auf den alten Master zugreifen müssen, um zu sehen, wie weit er fortgeschritten ist. Möglicherweise müssen wir die Segmente des Transaktionsprotokolls inspizieren und herausfinden, was dort vor sich geht. Und verstehen, ob wir diese Daten verlieren können oder ob wir den alten Master im Standalone-Modus starten müssen, um diese Daten zu extrahieren.
Erst danach sollten wir entscheiden, ob wir diese Daten verwerfen oder ob wir sie wiederherstellen können, indem wir diesen Knoten als Replik in unser Cluster einbinden.
Darüber hinaus gibt es den Parameter „maximum_lag_on_failover“. Standardmäßig hat dieser Parameter, wenn ich mich nicht irre, den Wert von 1 Megabyte.
Wie funktioniert es? Wenn unser Replikat bei der Replikationsverzögerung um 1 Megabyte hinterherhängt, nimmt es nicht an Wahlen teil. Und wenn es zu einem Failover kommt, schaut Patroni, welche Replikate hinterherhängen. Wenn sie bei einer großen Anzahl an Transaktionsprotokollen zurückliegen, können sie nicht zum Master werden. Das ist eine hervorragende Schutzfunktion, die hilft, den Verlust von Daten zu vermeiden.
Es gibt jedoch ein Problem: Die Replikationsverzögerung im Patroni-Cluster und DCS wird in bestimmten Intervallen aktualisiert. Meines Wissens beträgt der Standardwert für ttl 30 Sekunden.
Daher kann es Situationen geben, in denen die Replikationsverzögerung in DCS eine ist, während die tatsächliche Verzögerung entweder ganz anders oder sogar nicht vorhanden sein kann. Das bedeutet, es handelt sich nicht um Echtzeit. Es spiegelt nicht immer das tatsächliche Bild wider. Daher sollte man keine komplizierten Logiken darauf basieren.
Das Risiko von Datenverlust bleibt immer bestehen. Im schlimmsten Fall gilt eine Formel, im Durchschnitt eine andere. Das heißt, wenn wir die Implementierung von Patroni planen und bewerten, wie viele Daten wir verlieren können, müssen wir mit diesen Formeln rechnen und eine Vorstellung davon haben, wie viele Daten wir möglicherweise verlieren.
Die gute Nachricht ist, dass, wenn der alte Master vorgegangen ist, er dies möglicherweise durch einige Hintergrundprozesse tun konnte. Das bedeutet, dass ein Autovakuum lief, es wurden Daten geschrieben und im Transaktionsprotokoll gespeichert. Diese Daten können wir problemlos ignorieren und verlieren. Das stellt kein Problem dar.

So sehen die Protokolle aus, wenn maximum_lag_on_failover festgelegt ist und ein Failover stattgefunden hat, und ein neuer Master ausgewählt werden muss. Die Replik bewertet sich selbst als unfähig, an den Wahlen teilzunehmen, und zieht sich vom Rennen um die Führerschaft zurück. Sie wartet darauf, dass ein neuer Master gewählt wird, um sich dann mit ihm zu verbinden. Dies ist eine zusätzliche Maßnahme zur Vermeidung von Datenverlust.

Hier hat unser Produktteam geschrieben, dass ihr Produkt Probleme mit Postgres hat. Der Master selbst ist jedoch nicht erreichbar, da er über SSH nicht verfügbar ist. Außerdem findet kein automatisches Failover statt.
Dieser Host wurde gezwungen, neu gestartet zu werden. Aufgrund des Neustarts fand ein automatisches Failover statt, obwohl man auch manuelles Failover hätte durchführen können, wie ich jetzt verstehe. Nach dem Neustart schauen wir uns an, was mit unserem aktuellen Master passiert ist.
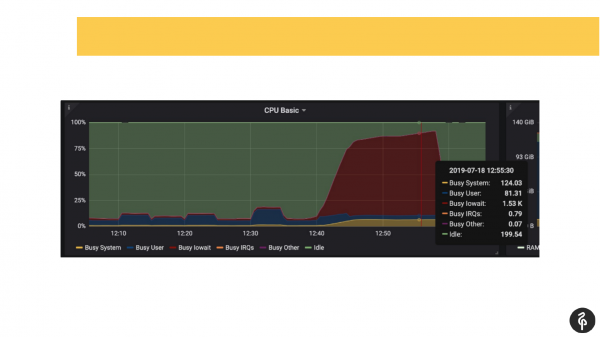
Dabei wussten wir bereits im Voraus, dass wir Probleme mit den Festplatten hatten, d.h. wir kannten anhand der Überwachung bereits den Bereich, in dem wir nachforschen mussten und wonach wir suchen sollten.

Wir haben die Postgres-Protokolle durchgesehen und geschaut, was dort vor sich geht. Wir haben Commit-Operationen gesehen, die jeweils ein bis drei Sekunden dauerten, was völlig unnormal war. Wir stellten fest, dass der Autovacuum-Prozess sehr lange und merkwürdig gestartet wurde. Zudem entdeckten wir temporäre Dateien auf der Festplatte. Das alles sind Anzeichen für Festplattenprobleme.

Wir haben uns die Systemdmesg (Kernmeldungen) angesehen und festgestellt, dass wir ein Problem mit einer der Festplatten haben. Das Festplattensystem stellte ein Software-RAID dar. Wir schauten in /proc/mdstat und bemerkten, dass eine Festplatte fehlte. Konkret handelt es sich um ein RAID aus 8 Festplatten, wobei eine nicht vorhanden ist. Wenn man sich die Folie genau betrachtet, kann man im Ausgabeprotokoll sehen, dass sde fehlt. Mit anderen Worten, eine Festplatte ist ausgefallen. Das hat die Festplattenprobleme ausgelöst, und die Anwendungen hatten ebenfalls Schwierigkeiten mit dem Postgres-Cluster.

In diesem Fall hätte uns Patroni nicht geholfen, da Patroni nicht dafür verantwortlich ist, den Zustand des Servers oder der Festplatten zu überwachen. Diese Situationen müssen wir mit externem Monitoring überwachen. Wir haben das externe Monitoring um eine Überwachung der Festplatten ergänzt.
Es kam der Gedanke auf – könnte uns ein Fence oder ein Software-Watchdog helfen? Wir dachten, dass das in diesem Fall wahrscheinlich nicht helfen würde, da Patroni während der Probleme weiterhin mit dem DCS-Cluster interagierte und keine Probleme feststellte. Das heißt, aus der Sicht von DCS und Patroni war im Cluster alles in Ordnung, obwohl tatsächlich Probleme mit der Festplatte und der Datenbankverfügbarkeit bestanden.
Meiner Meinung nach ist das eines der seltsamsten Probleme, die ich lange untersucht habe. Ich habe viele Logs durchgelesen und analysiert und nannte es den Cluster-Simulanten.

Das Problem war, dass der alte Master nicht zu einer normalen Replik werden konnte. Patroni startete ihn, und es wurde angezeigt, dass dieser Knoten als Replik vorhanden ist, aber gleichzeitig war er keine echte Replik. Jetzt werden Sie sehen, warum. Das habe ich aus der Analyse dieses Problems behalten.

Und wie alles begann? Es begann, ähnlich wie beim vorherigen Problem, mit den Festplattenspeichern. Wir hatten ein bis zwei Commits pro Sekunde.

Es gab Verbindungsabbrüche, das heißt, die Kunden wurden getrennt.

Es gab Blockierungen unterschiedlicher Schwere.

Demzufolge war das Speichersystem nicht sehr reaktionsschnell.

Und das Mysteriöseste für mich war der eingehende Immediate Shutdown Request. Postgres hat drei Abschaltmodi:
- Der erste ist graceful, wenn wir darauf warten, dass sich alle Clients selbstständig abmelden.
- Es gibt fast, wenn wir die Clients zum Abmelden zwingen, weil wir das System herunterfahren.
- Und immediate. In diesem Fall informiert immediate nicht einmal die Clients, dass sie sich abmelden sollen, es schaltet einfach ohne Vorwarnung ab. Allen Clients wird von der Betriebssystemnachricht RST (TCP-Nachricht, dass die Verbindung unterbrochen wurde und es für den Client nichts mehr zu holen gibt) gesendet.
Wer dieses Signal gesendet hat? Hintergrundprozesse von Postgres senden sich solche Signale nicht, das heißt, es ist ein kill-9. Sie senden sich solche Signale nicht, sie reagieren nur darauf, das heißt, es handelt sich um einen Notfallneustart von Postgres. Wer es gesendet hat, weiß ich nicht.
Ich habe mir das Team "last" angeschaut und gesehen, dass eine Person ebenfalls auf diesen Server eingeloggt war, aber ich habe mich nicht getraut zu fragen. Vielleicht war es ein kill -9. Ich hätte kill -9 in den Logs gesehen, da Postgres meldet, dass kill -9 empfangen wurde, aber ich habe es in den Logs nicht gefunden.

Als ich weiter nachforschte, fiel mir auf, dass Patroni ziemlich lange nicht in die Logs geschrieben hat – 54 Sekunden. Wenn ich die beiden Zeitstempel vergleiche, gab es etwa 54 Sekunden lang keine Meldungen.
In dieser Zeit kam es zu einem automatischen Failover. Patroni hat hier wieder hervorragend funktioniert. Unser alter Master war nicht erreichbar, es gab etwas mit ihm. Und es begannen die Wahlen eines neuen Masters. Das lief alles gut ab. Unser pgsql01 wurde zum neuen Leader.

Wir haben eine Replik, die zum Master geworden ist. Und es gibt eine zweite Replik. Und bei der zweiten Replik gab es Probleme. Sie versuchte, sich neu zu konfigurieren. Soweit ich verstehe, wollte sie die recovery.conf ändern, Postgres neu starten und sich mit dem neuen Master verbinden. Alle 10 Sekunden schreibt sie Meldungen, dass sie es versucht, aber es klappt nicht.

Während dieser Versuche hat der alte Master ein immediate-shutdown-Signal erhalten. Der Master startet neu. Auch die Wiederherstellung wird unterbrochen, da der alte Master neu gestartet wird. Das bedeutet, die Replica kann sich nicht mit ihm verbinden, da er im abgeschalteten Zustand ist.

Irgendwann hat es funktioniert, aber die Replikation wurde nicht gestartet.
Ich habe nur eine Hypothese: Im recovery.conf war die Adresse des alten Masters gespeichert. Als der neue Master auftauchte, versuchte die zweite Replica weiterhin, sich mit dem alten Master zu verbinden.
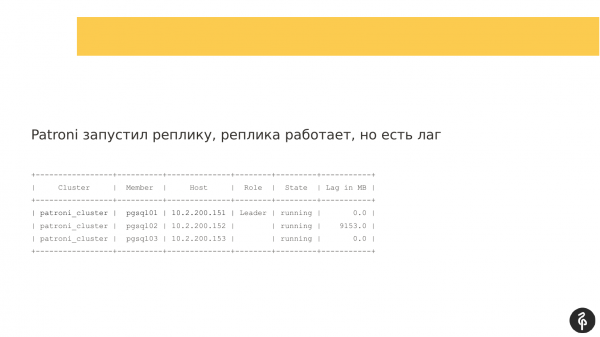
Als Patroni auf der zweiten Replica gestartet wurde, ist der Knoten hochgefahren, konnte sich jedoch nicht mit der Replikation verbinden. Dadurch entstand ein Replikationsverzug, der etwa so aussah. Das bedeutet, alle drei Knoten waren vorhanden, aber der zweite Knoten hatte Rückstand.
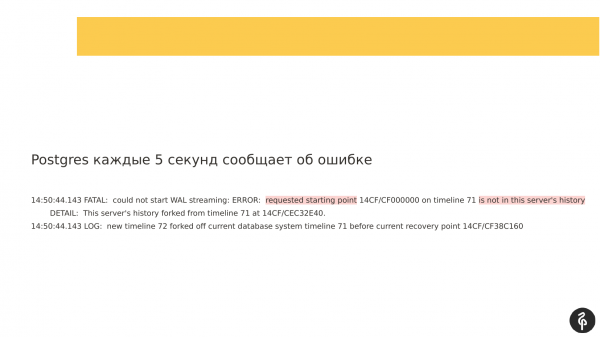
Wenn man sich die protokollierten Logs ansieht, konnte man feststellen, dass die Replikation nicht gestartet werden konnte, weil die Transaktionsprotokolle unterschiedlich waren. Die von dem Master angebotenen Transaktionsprotokolle, die in recovery.conf angegeben sind, passen einfach nicht zu unserem aktuellen Knoten.

Und hier habe ich einen Fehler gemacht. Ich hätte nachsehen müssen, was im recovery.conf steht, um meine Hypothese zu überprüfen, dass wir uns nicht mit dem richtigen Master verbinden. Aber ich habe mich damals gerade erst in dieses Thema eingearbeitet und es ist mir nicht eingefallen, oder ich habe gesehen, dass die Replikation hinterherhinkt und sie neu aufgesetzt werden müsste, also habe ich das mehr oder weniger schlampig erledigt. Das war mein Fehler.

Nach 30 Minuten kam der Admin, ich hatte Patroni auf der Replik gestartet. Ich hatte schon mit ihr abgeschlossen und dachte, dass ich sie neu aufsetzen müsste. Und dann dachte ich – ich starte Patroni erneut, vielleicht klappt ja etwas Positives. Der Recovery-Prozess startete. Und die Datenbank öffnete sich sogar, sie war bereit, Verbindungen anzunehmen.
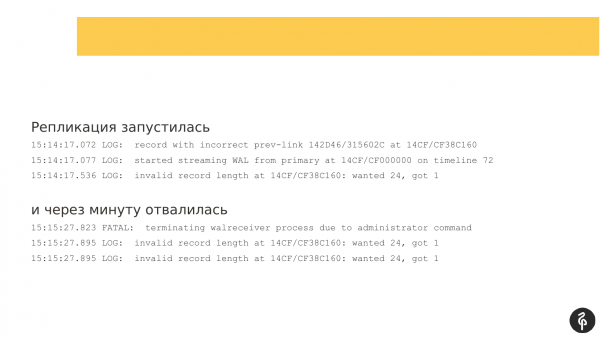
Die Replikation wurde gestartet. Aber nach einer Minute fiel sie mit dem Fehler aus, dass die Transaktionsprotokolle nicht passen.

Ich dachte, ich starte es nochmal neu. Ich habe Patroni erneut gestartet, und ich habe nicht Postgres neu gestartet, sondern speziell Patroni in der Hoffnung, dass er die Datenbank auf magische Weise aktivieren würde.

Die Replikation wurde erneut gestartet, jedoch waren die Einträge im Transaktionsprotokoll unterschiedlich; sie stimmten nicht mit denen bei dem vorherigen Versuch überein. Die Replikation stoppte wieder. Und die Nachricht war bereits etwas anders. Sie war für mich nicht besonders informativ.

Und da kam mir der Gedanke – was wäre, wenn ich Postgres neu starte und währenddessen auf dem aktuellen Master einen Checkpoint mache, um den Punkt im Transaktionsprotokoll ein wenig nach vorne zu verschieben, sodass die Wiederherstellung zu einem anderen Zeitpunkt beginnt? Außerdem hatten wir noch einige WAL-Reservoirs.

Ich habe Patroni neu gestartet, ein paar Checkpoints auf dem Master gemacht und einige Restart-Punkte auf der Replik, als sie geöffnet wurde. Und das hat geholfen. Ich habe lange darüber nachgedacht, warum das geholfen hat und wie es funktioniert hat. Und die Replikation lief. Und die Replikation riss nicht mehr ab.

Ein solches Problem gehört für mich zu den rätselhaftesten, über das ich immer noch nachdenke, was dort tatsächlich passiert ist.
Was sind die Erkenntnisse hier? Patroni kann wie vorgesehen funktionieren, ohne Fehler. Das bedeutet jedoch nicht, dass alles perfekt ist. Eine Replikation kann aktiviert werden, könnte sich jedoch im halbfertigen Zustand befinden, was bedeutet, dass die Anwendung nicht mit einer solchen Replikation arbeiten kann, da dort veraltete Daten vorhanden sind.
Nach jedem Failover sollten wir unbedingt überprüfen, ob alles in Ordnung mit dem Cluster ist, d.h. ob die erforderliche Anzahl an Replikaten vorhanden ist und kein Replikationsverzug besteht.
Während ich diese Probleme diskutieren werde, werde ich Empfehlungen formulieren. Ich habe versucht, sie in zwei Folien zu bündeln. Wahrscheinlich hätten alle Geschichten in zwei Folien zusammengefasst werden können, die man dann einfach erzählt.

Wenn Sie Patroni verwenden, ist eine Überwachung unerlässlich. Sie müssen immer wissen, wann ein Auto-Failover stattgefunden hat, denn wenn Sie nicht wissen, dass ein Auto-Failover passiert ist, haben Sie den Cluster nicht im Griff. Und das ist schlecht.
Nach jedem Failover sollten wir den Cluster immer manuell überprüfen. Wir müssen sicherstellen, dass wir immer die aktuelle Anzahl an Replikaten haben, kein Replikationsverzug besteht und dass die Protokolle keine Fehler im Zusammenhang mit der Streaming-Replikation, Patroni oder dem DCS-System aufweisen.
Automatisierung kann erfolgreich funktionieren, Patroni ist ein hervorragendes Werkzeug. Es kann arbeiten, aber das wird den Cluster nicht in den gewünschten Zustand versetzen. Und wenn wir das nicht wissen, haben wir ein Problem.
Und Patroni ist kein Allheilmittel. Wir müssen immer noch verstehen, wie Postgres funktioniert, wie die Replikation abläuft und wie Patroni mit Postgres zusammenarbeitet, sowie wie die Interaktion zwischen den Knoten gewährleistet wird. Dies ist notwendig, um Probleme manuell beheben zu können.

Wie gehe ich an die Diagnose heran? Es stellt sich heraus, dass wir mit verschiedenen Kunden arbeiten und niemand das ELK-Stack hat, sodass wir in den Logs nachsehen müssen, indem wir 6 Konsolen und 2 Tabs öffnen. In einem Tab sind die Logs von Patroni für jeden Knoten, im anderen Tab die Logs von Consul oder, falls notwendig, von Postgres. Das Diagnostizieren ist sehr schwierig.
Welche Ansätze habe ich entwickelt? Zum einen schaue ich immer, wann der Failover eingetreten ist. Für mich ist dies ein entscheidender Moment. Ich achte darauf, was vor dem Failover, während des Failovers und nach dem Failover passiert ist. Der Failover hat zwei Zeitmarken: den Beginn und das Ende.
Als nächstes schaue ich in den Logs nach den Ereignissen vor dem Failover, also suche ich nach den Ursachen, warum das Failover stattgefunden hat.
Das gibt mir ein Bild davon, was passiert ist und was ich in der Zukunft tun kann, um solche Umstände zu vermeiden und somit ein erneutes Failover zu verhindern.
Und wohin schauen wir normalerweise? Ich schaue:
- Zuerst in die Patroni-Logs.
- Dann überprüfe ich die Postgres-Logs oder die DCS-Logs, je nachdem, was ich in den Patroni-Logs gefunden habe.
- Auch die Systemlogs können manchmal Aufschluss darüber geben, was die Ursache für das Failover war.

Wie denke ich über Patroni? Ich halte sehr viel von Patroni. Meiner Meinung nach ist es das Beste, was es zurzeit gibt. Ich kenne viele andere Produkte: Stolon, Repmgr, Pg_auto_failover, PAF. Insgesamt vier Tools. Ich habe sie alle ausprobiert. Patroni hat mir am besten gefallen.
Wenn man mich fragt: „Empfehle ich Patroni?“, sage ich ja, denn Patroni gefällt mir und ich habe das Gefühl, dass ich gelernt habe, es effektiv zu nutzen.
Wenn Sie interessiert sind, welche weiteren Probleme mit Patroni auftreten können, abgesehen von den, die ich erwähnt habe, können Sie jederzeit die Seite besuchen auf GitHub. Dort gibt es viele verschiedene Geschichten und interessante Diskussionen zu Problemen. Am Ende wurden einige Bugs erfasst und gelöst, d. h. es ist eine spannende Lektüre.
Dort gibt es interessante Geschichten darüber, wie Menschen sich ins Bein schießen. Sehr lehrreich. Man liest und versteht, dass man so etwas vermeiden sollte. Ich habe mir eine Notiz gemacht.
Ich möchte ein großes Dankeschön an die Firma Zalando aussprechen, insbesondere an Alexander Kukushkin und Alexey Klyukin, für die Unterstützung dieses Projekts. Alexey Klyukin ist einer der Mitwirkenden, der nicht mehr bei Zalando arbeitet, aber das sind die zwei Personen, die mit diesem Produkt angefangen haben.
Ich halte Patroni für ein ganz tolles Tool. Ich bin froh, dass es existiert; es ist sehr interessant. Und ein großes Dankeschön an alle Mitwirkenden, die Patches für Patroni schreiben. Ich hoffe, dass Patroni mit der Zeit reifer, besser und leistungsfähiger wird. Es funktioniert schon gut, aber ich hoffe, es wird noch besser. Wenn Sie also planen, Patroni zu verwenden, haben Sie keine Angst. Es ist eine gute Lösung, die Sie implementieren und verwenden können.
Das war's. Wenn Sie Fragen haben, stellen Sie diese bitte.

Fragen
Danke für den Bericht! Wenn wir nach der automatischen Filesicherung trotzdem genau hinschauen müssen, warum brauchen wir dann einen automatischen Filesicherer?
Weil es sich um etwas Neues handelt. Wir arbeiten erst seit einem Jahr damit. Es ist besser, auf Nummer sicher zu gehen. Wir möchten überprüfen, ob alles tatsächlich so funktioniert hat, wie es sollte. Das ist ein Zeichen von gesundem Misstrauen – besser noch einmal nachprüfen.
Zum Beispiel haben wir morgens nachgesehen, richtig?
Nicht morgens, wir erfahren normalerweise fast sofort über die automatische Filesicherung. Wir erhalten Benachrichtigungen und sehen, dass die automatische Filesicherung stattgefunden hat. Wir schauen fast sofort nach. Aber all diese Überprüfungen sollten in das Monitoring übertragen werden. Wenn man über die REST API auf Patroni zugreift, gibt es eine Historie. Anhand dieser Historie kann man die Zeitstempel einsehen, wann die Filesicherung stattfand. Darauf basierend kann man das Monitoring einrichten. Man kann sehen, wie viele Ereignisse dort vorhanden sind. Wenn es mehr Ereignisse gibt, hat eine automatische Filesicherung stattgefunden. Man kann nachschauen. Oder unser Monitoring-System hat überprüft, dass alle Replikate vorhanden sind, keine Lag besteht und alles gut ist.
Danke!
Vielen Dank für die großartige Erzählung! Wenn wir den DCS-Cluster von dem Postgres-Cluster entfernen, muss dieser Cluster dann auch regelmäßig gewartet werden? Welche Best Practices gibt es in Bezug darauf, dass Teile des DCS-Clusters deaktiviert werden, was man damit machen sollte usw.? Wie funktioniert das gesamte System dabei? Und wie sollte man diese Aufgaben erledigen?
Für ein Unternehmen war es notwendig, eine Problemmatrix zu erstellen, die beschreibt, was passiert, wenn einer oder mehrere Komponenten ausfallen. Anhand dieser Matrix gehen wir alle Komponenten durch und entwickeln Szenarien für den Ausfall dieser Komponenten. Entsprechend für jedes Ausfall-Szenario gibt es einen Aktionsplan zur Wiederherstellung. Im Fall von DCS ist dies Teil der Standardinfrastruktur. Der Administrator verwaltet dies, und wir verlassen uns bereits auf die Administratoren, die dies überwachen, und auf ihre Fähigkeiten, im Falle eines Ausfalls Reparaturen vorzunehmen. Wenn DCS nicht vorhanden ist, kümmern wir uns um dessen Bereitstellung, aber wir überwachen es nicht besonders, da wir nicht für die Infrastruktur verantwortlich sind, geben jedoch Empfehlungen, was und wie überwacht werden sollte.
Das heißt, habe ich richtig verstanden, dass wir Patroni, den Fileserver und alles andere deaktivieren müssen, bevor wir etwas mit den Hosts machen?
Das hängt davon ab, wie viele Knoten wir im DCS-Cluster haben. Wenn es viele Knoten gibt und wir nur einen Knoten (Replikat) außer Betrieb nehmen, bleibt das Quorum im Cluster erhalten. Patroni bleibt funktionsfähig und es wird nichts ausgelöst. Wenn wir jedoch komplexe Operationen durchführen, die mehr Knoten betreffen und deren Abwesenheit das Quorum gefährden könnte, macht es vielleicht Sinn, Patroni vorübergehend anzuhalten. Dafür gibt es einen entsprechenden Befehl – patronictl pause, patronictl resume. Wir setzen es einfach auf Pause, und der Auto-Failover wird in dieser Zeit nicht aktiviert. Wir führen dann Wartungsarbeiten am DCS-Cluster durch, heben die Pause auf und machen weiter.
Vielen Dank!
Vielen Dank für die Präsentation! Wie steht das Produktteam dazu, dass Daten verloren gehen könnten?
Das Produktteam ist das egal, aber die Teamleiter machen sich Sorgen.
Welche Garantien gibt es dafür?
Mit Garantien ist es sehr schwierig. Es gibt einen Bericht von Alexander Kukushkin mit dem Titel „Wie man RPO und RTO berechnet“, also die Wiederherstellungszeit und wie viele Daten wir verlieren können. Ich denke, wir sollten diese Folien finden und sie studieren. Soweit ich mich erinnere, gibt es spezifische Schritte, wie man diese Dinge berechnet. Wie viele Transaktionen können wir verlieren, wie viele Daten können verloren gehen? Eine Möglichkeit wäre die Verwendung von synchroner Replikation auf der Stufe von Patroni, aber das ist ein zweischneidiges Schwert: Wir haben entweder Datenzuverlässigkeit oder verlieren an Geschwindigkeit. Es gibt zwar synchrone Replikation, aber sie garantiert auch keinen 100%-igen Schutz vor Datenverlust.
Alexey, danke für den großartigen Vortrag! Gibt es Erfahrungen mit der Verwendung von Patroni für den Zero-Level-Schutz? Also in Kombination mit einem synchronen Standby? Das ist die erste Frage. Und die zweite Frage: Sie haben verschiedene Lösungen genutzt. Wir haben Repmgr verwendet, aber ohne Auto-Failover und planen jetzt, Auto-Failover zu integrieren. Wir betrachten Patroni als alternative Lösung. Was können Sie als Vorteile im Vergleich zu Repmgr sagen?
Die erste Frage betraf die synchronen Replikate. Bei uns nutzt niemand die synchrone Replikation, weil die meisten Bedenken haben (einige Kunden verwenden sie bereits, und wir haben grundsätzlich keine Leistungsprobleme bemerkt — Hinweis des Referenten). Aber wir haben für uns die Regel aufgestellt, dass in einem Cluster mit synchroner Replikation mindestens drei Knoten vorhanden sein sollten. Wenn wir nur zwei Knoten haben und ein Master- oder Replikat ausfällt, versetzt Patroni diesen Knoten in den Standalone-Modus, damit die Anwendung weiterarbeiten kann. In diesem Fall gibt es Risiken für den Datenverlust.
Bezüglich der zweiten Frage haben wir Repmgr verwendet und setzen es aus historischen Gründen weiterhin bei einigen Clients ein. Was kann man dazu sagen? In Patroni gibt es den Auto-Failover standardmäßig, während bei Repmgr der Auto-Failover als zusätzliche Funktion aktiviert werden muss. Es muss der Repmgr-Daemon auf jedem Knoten gestartet werden, und dann können wir den Auto-Failover einrichten.
Repmgr überprüft, ob die PostgreSQL-Knoten aktiv sind. Die Repmgr-Prozesse kontrollieren sich gegenseitig, was jedoch kein sehr effektiver Ansatz ist, da es komplexe Fälle von Netzwerktrennung geben kann, bei denen ein großer Repmgr-Cluster in mehrere kleine zerfällt und weiterhin funktioniert. Ich habe schon lange nichts mehr über Repmgr verfolgt; vielleicht wurde das behoben... vielleicht auch nicht. Die Übertragung von Informationen über den Zustand des Clusters in DCS, wie es Stolon oder Patroni machen, ist jedoch die tragfähigste Lösung.
Alexej, ich habe eine vielleicht etwas naive Frage. In einem der ersten DCS-Beispiele haben Sie von einem lokalen Rechner auf einen Remote-Knoten übertragen. Wir wissen, dass das Netzwerk Eigenschaften hat, die es einzigartig machen, es lebt für sich. Was passiert, wenn aus irgendeinem Grund der DCS-Cluster nicht mehr verfügbar ist? Gründe möchte ich nicht nennen, es kann viele geben: von ungeschickten Netzwerkadministratoren bis hin zu echten Problemen.
Ich habe es nicht laut gesagt, aber der DCS-Cluster muss ebenfalls ausfallsicher sein, d. h. es sollte eine ungerade Anzahl von Knoten vorhanden sein, damit ein Quorum erreicht werden kann. Was passiert, wenn der DCS-Cluster nicht mehr verfügbar ist oder das Quorum nicht erreicht werden kann, beispielsweise durch ein Netzwerk-Partition oder den Ausfall von Knoten? In diesem Fall wechselt der Patroni-Cluster in den Nur-Lesen-Modus. Der Patroni-Cluster kann den Zustand des Clusters und die erforderlichen Maßnahmen nicht bestimmen. Er kann nicht mit dem DCS kommunizieren und den neuen Zustand des Clusters speichern, weshalb der gesamte Cluster in den Nur-Lesen-Modus wechselt. Er wartet entweder auf manuelles Eingreifen des Operators oder darauf, dass das DCS wiederhergestellt wird.
Um es einfach auszudrücken, wird DCS für uns zu einem Dienst, der ebenso wichtig ist wie die Datenbank selbst?
Ja, genau. In vielen modernen Unternehmen ist Service Discovery ein fester Bestandteil der Infrastruktur. Es wird sogar noch bevor eine Datenbank in der Infrastruktur vorhanden ist, implementiert. Um es vereinfacht zu sagen: Wir haben die Infrastruktur gestartet, uns im Rechenzentrum eingerichtet, und schon haben wir Service Discovery. Wenn es sich um Consul handelt, kann darauf auch DNS aufgebaut werden. Wenn es Etcd ist, könnte es Teil eines Kubernetes-Clusters sein, in dem dann alles andere bereitgestellt wird. Ich denke, dass Service Discovery bereits ein unverzichtbarer Bestandteil moderner Infrastrukturen ist. Darüber wird oft viel früher nachgedacht als über Datenbanken.
Danke!
Quelle: habr.com
