

Hallo, Habr!
Wir erinnern Sie daran, dass wir einen weiteren äußerst interessanten und nützlichen Artikel über Kubernetes-Patterns veröffentlicht haben. Alles begann noch mit "" von Brendan Burns, und ehrlich gesagt sind wir in diesem Bereich . Heute möchten wir Ihnen einen Beitrag aus dem MinIO Blog vorstellen, der die Trends und Besonderheiten der Datenspeicher-Patterns in Kubernetes zusammenfasst.
Kubernetes hat die traditionellen Patterns für die Entwicklung und Bereitstellung von Anwendungen grundlegend verändert. Nun kann das Team in nur wenigen Tagen eine Anwendung entwickeln, testen und bereitstellen – in verschiedenen Umgebungen, und das alles innerhalb von Kubernetes-Clustern. Mit Technologien früherer Generationen benötigte man dafür in der Regel Wochen, wenn nicht Monate.
Diese Beschleunigung wurde durch die Abstraktion ermöglicht, die Kubernetes bietet – das heißt, Kubernetes übernimmt selbst die Interaktion mit den niedrigstufigen Details physischer oder virtueller Maschinen. Benutzer können unter anderem die benötigte CPU, den gewünschten Arbeitsspeicher und die Anzahl der Containerinstanzen angeben. Da eine riesige Gemeinschaft die Unterstützung von Kubernetes übernimmt und der Umfang seiner Anwendung ständig wächst, führt es mit großem Abstand unter allen Plattformen zur Orchestrierung von Containern.
Mit der zunehmenden Verbreitung von Kubernetes wächst auch die Verwirrung über die angewandten Datenmuster..
In einem wettbewerbsintensiven Umfeld um das Datenlager Kubernetes (also um den Speicher) geht das Signal beim Thema Datenspeicherung im starken Rauschen unter.
Kubernetes verkörpert ein modernes Modell für die Entwicklung und Bereitstellung von Anwendungen sowie deren Verwaltung. Dieses moderne Modell trennt die Datenspeicherung von den Rechenoperationen. Um diese Trennung im Kontext von Kubernetes vollständig zu verstehen, ist es auch notwendig zu erkennen, was zustandsbehaftete und zustandslose Anwendungen sind und wie dies mit der Datenspeicherung zusammenhängt. Hierbei bietet der REST-API-Ansatz von S3 klare Vorteile im Vergleich zu dem POSIX/CSI-Ansatz, der für andere Lösungen charakteristisch ist.
In diesem Artikel werden wir die Muster der Datenspeicherung in Kubernetes besprechen und speziell auf die Debatte über zustandsbehaftete und zustandslose Anwendungen eingehen, um die Unterschiede zwischen ihnen richtig zu verstehen und deren Bedeutung zu erläutern. Weiterhin werden die in Anwendungen verwendeten Datenspeicherungsmuster im Lichte der besten Praktiken für den Umgang mit Containern und Kubernetes betrachtet.
Zustandslose Container
Container sind von Natur aus leicht und vergänglich. Sie können problemlos gestoppt, entfernt oder auf einem anderen Knoten bereitgestellt werden – all dies geschieht in wenigen Sekunden. In einem umfangreichen System zur Orchestrierung von Containern kommen solche Vorgänge ständig vor, und die Benutzer bemerken diese Veränderungen nicht einmal. Allerdings sind Verschiebungen nur möglich, wenn der Container keine Abhängigkeiten von dem Knoten hat, auf dem er sich befindet. Man spricht von Containern, die arbeiten ohne Zustandsspeicherung.
Container mit Zustandsspeicherung
Wenn ein Container Daten auf lokal angeschlossenen Geräten (oder auf einem Blockgerät) speichert, muss der Datenspeicher, auf dem er sich befindet, zusammen mit dem Container auf einen neuen Knoten verschoben werden – im Falle eines Ausfalls. Dies ist wichtig, da die in dem Container ausgeführte Anwendung ansonsten nicht korrekt funktionieren kann, da sie auf die auf den lokalen Speichermedien gespeicherten Daten zugreifen muss. Man spricht von Containern, die arbeiten mit Zustandsspeicherung.
Aus rein technischer Sicht können auch zustandsbehaftete Container auf andere Knoten verschoben werden. Dies wird normalerweise durch verteilte Dateisysteme oder blockbasierte Netzwerkdatenspeicher ermöglicht, die an alle Knoten angeschlossen sind, auf denen die Container laufen. Dadurch erhalten die Container Zugriff auf Volumes für die persistente Speicherung von Daten, und die Informationen werden auf Festplatten gespeichert, die im gesamten Netzwerk verteilt sind. Ich nenne diese Methode «zustandsbehafteter Containeransatz», und im weiteren Verlauf des Artikels werde ich ihn so zur Einheitlichkeit benennen.
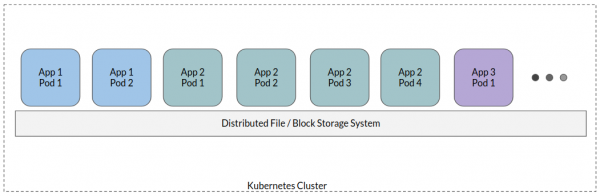
Bei dem typischen zustandsbehafteten Containeransatz werden alle Pods der Anwendungen an ein einziges verteiltes Dateisystem angehängt – es entsteht eine Art gemeinsamer Speicher, in dem alle Anwendungsdaten verwaltet werden. Obwohl es einige Variationen geben kann, ist dies ein hochgradiger Ansatz.
Lassen Sie uns nun untersuchen, warum der zustandsbehaftete Containeransatz in einer cloudorientierten Welt ein Antipattern ist.
Cloud-orientierte Anwendungsarchitektur
Traditionell verwendeten Anwendungen Datenbanken für die strukturierte Speicherung von Informationen und lokale Laufwerke oder verteilte Dateisysteme, in die alle unstrukturierten oder sogar halbstrukturierten Daten abgelegt wurden. Mit dem Wachstum der unstrukturierten Datenmengen erkannten die Entwickler, dass POSIX zu "gesprächig" ist, erhebliche Kosten verursacht und letztlich die Leistung der Anwendung bei der Skalierung auf wirklich große Umfänge behindert.
Dies hat in erster Linie zur Entstehung eines neuen Standards für die Datenspeicherung beigetragen, nämlich cloudbasierter Speicher, der hauptsächlich auf REST-APIs basiert und Anwendungen von der belastenden Wartung lokaler Datenspeicher befreit. In diesem Fall arbeitet die Anwendung faktisch im Zustand ohne Speicherung (da der Zustand in einem entfernten Speicher liegt). Moderne Anwendungen werden von Grund auf unter Berücksichtigung dieses Faktors entwickelt. In der Regel basiert jede moderne Anwendung, die irgendeine Art von Daten verarbeitet (Protokolle, Metadaten, Blobs usw.), auf dem cloudbasierten Paradigma, bei dem der Zustand in ein speziell dafür vorgesehenes Softwaresystem übertragen wird.
Der containerbasierte Ansatz mit Zustandsspeicherung zwingt dieses gesamte Paradigma genau dorthin zurück, wo es ursprünglich begonnen hat!
Wenn Anwendungen POSIX-Schnittstellen zur Datenspeicherung verwenden, verhalten sie sich ähnlich, als würden sie ihren Zustand speichern. Dadurch weichen sie von den wichtigsten Grundsätzen des cloudbasierten Designs ab — insbesondere von der Fähigkeit, die Größe der Arbeitslasten an die eingehende Nachfrage anzupassen, auf einen neuen Knoten zu wechseln, sobald der aktuelle Knoten ausfällt, und so weiter.
Ein genauerer Blick auf diese Situation zeigt, dass wir bei der Auswahl eines Datenspeichers immer wieder mit dem Dilemma „POSIX gegen REST API“ konfrontiert werden, wobei es jedoch zusätzliche Probleme gibt, die durch die verteilte Natur von Kubernetes-Umgebungen verstärkt werden. Insbesondere
- POSIX ist problematisch: Die Semantik von POSIX erfordert die Assoziation von Metadaten und Dateideskriptoren mit jeder Operation, was hilft, den Status der Operation aufrechtzuerhalten. Dies führt zu erheblichen Kosten, die keinen echten Wert haben. Die API für Objektspeicher, insbesondere die S3-API, hat sich von diesen Anforderungen befreit, sodass die Anwendung ausgeführt werden kann und dann den Aufruf vergessen kann. Die Rückmeldung des Speichersystems zeigt an, ob die jeweilige Aktion erfolgreich war oder nicht. Im Falle eines Fehlers kann die Anwendung einen erneuten Versuch durchführen.
- Netzwerkbeschränkungen: In einem verteilten System wird davon ausgegangen, dass es viele Anwendungen geben kann, die versuchen, Daten auf dasselbe angeschlossene Medium zu schreiben. Daher werden nicht nur die Anwendungen um die Bandbreite konkurrieren (um Daten auf das Medium zu senden), sondern auch das Speichersystem selbst wird um diese Bandbreite konkurrieren, indem es Daten auf physische Laufwerke verteilt. Aufgrund der Wortlastigkeit von POSIX steigen die Anzahl der Netzwerkaufrufe erheblich an. Andererseits sorgt die S3 API für eine klare Trennung der Netzwerkaufrufe zwischen denen, die vom Client an den Server gesendet werden, und denen, die innerhalb des Servers stattfinden.
- Sicherheit: Das Sicherheitsmodell von POSIX ist darauf ausgelegt, dass der Mensch aktiv beteiligt ist: Administratoren konfigurieren spezifische Zugriffslevels für jeden Benutzer oder jede Gruppe. Ein solches Paradigma lässt sich schwer auf eine cloudbasierte Welt anpassen. Moderne Anwendungen sind auf Sicherheitsmodelle angewiesen, die an APIs gebunden sind, wobei Zugriffsrechte als eine Sammlung von Richtlinien definiert werden, Servicekonten zugewiesen und temporäre Anmeldeinformationen vergeben werden, usw.
- Verwaltbarkeit: Zustandsbehaftete Container bringen bestimmte Kosten für das Management mit sich. Es geht um die Synchronisation des parallelen Zugriffs auf Daten und die Gewährleistung der Datenkonsistenz, was alles sorgfältige Überlegungen zu den zu verwendenden Datenzugriffsstrategien erfordert. Man muss zusätzliche Programme installieren, überwachen und konfigurieren, ganz zu schweigen von den zusätzlichen Bemühungen, die in die Entwicklung investiert werden.
Container-Speicher-Interface
Während das Container Storage Interface (CSI) großartig dabei geholfen hat, die Kubernetes-Volumes zu verbreiten, indem es teilweise an Drittanbieter von Datenspeicherlösungen übergeben wurde, hat es auch unabsichtlich zur Überzeugung beigetragen, dass der zustandsbehaftete Containeransatz die empfohlene Methode zur Datenspeicherung in Kubernetes ist.
CSI wurde als Standard zur Bereitstellung von beliebigen Block- und Dateispeichersystemen für Legacy-Anwendungen in Kubernetes entwickelt. Wie in diesem Artikel gezeigt, ist der containerbasierte Ansatz mit persistentem Speicher (und CSI in seiner aktuellen Form) nur sinnvoll, wenn die Anwendung selbst ein Legacy-System ist, dem es an Unterstützung für eine objektbasierte Datenspeicher-API mangelt.
Es ist wichtig zu verstehen, dass die Verwendung von CSI in seiner aktuellen Form – das Mappen von Volumes in modernen Anwendungen – uns mit ähnlichen Problemen konfrontieren wird wie in Systemen, in denen die Datenspeicherung im POSIX-Stil organisiert ist.
Ein qualitativ besserer Ansatz
In diesem Fall ist es wichtig zu verstehen, dass die meisten Anwendungen im Grunde nicht dafür ausgelegt sind, mit persistentem oder nicht persistentem Speicher zu arbeiten. Dieses Verhalten hängt von der Gesamtarchitektur des Systems und den spezifischen Optionen ab, die bei der Planung gewählt wurden. Lassen Sie uns ein wenig über zustandsbehaftete Anwendungen sprechen.
Grundsätzlich können alle Anwendungsdaten in mehrere umfassende Typen unterteilt werden:
- Protokolldaten
- Zeitstempeldaten
- Transaktionsdaten
- Metadaten
- Container-Images
- Blob-Daten (Binary Large Objects)
Alle diese Datentypen werden auf modernen Datenhaltungssystemen sehr gut unterstützt, und es gibt mehrere cloudbasierte Plattformen, die an die Bereitstellung von Daten in jedem dieser speziellen Formate angepasst sind. Beispielsweise können Transaktionsdaten und Metadaten in einer modernen cloudbasierten Datenbank wie CockroachDB, YugaByte usw. gespeichert werden. Container-Images oder Blob-Daten können in einem auf MinIO basierenden Docker-Registry gespeichert werden. Zeitstempeldaten können in einer Zeitreihendatenbank wie InfluxDB usw. gespeichert werden. Hier wollen wir nicht auf die Details jedes Datentyps und der entsprechenden Anwendungen eingehen, aber die Grundidee besteht darin, persistenten Datenspeicher zu vermeiden, der auf lokalen Laufwerks-Mounts basiert.
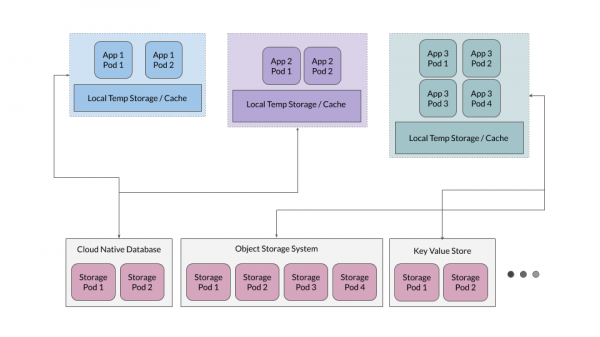
Zudem erweist es sich oft als effektiv, eine temporäre Cache-Ebene bereitzustellen, die als eine Art Speicher für temporäre Dateien für Anwendungen dient. Allerdings sollten Anwendungen nicht von dieser Ebene als Quelle der Wahrheit abhängen.
Speicher für zustandsbehaftete Anwendungen
Während es in den meisten Fällen vorteilhaft ist, Anwendungen ohne Zustand zu halten, sollten solche Anwendungen, die zum Speichern von Daten bestimmt sind – wie beispielsweise Datenbanken, Objektspeicher und Schlüssel-Wert-Speicher – ihren Zustand behalten. Lassen Sie uns untersuchen, warum diese Anwendungen auf Kubernetes bereitgestellt werden. Als Beispiel nehmen wir MinIO, aber ähnliche Prinzipien gelten auch für andere groß angelegte Cloud-orientierte Datenspeichersysteme.
Cloud-nativen Anwendungen werden mit dem Ziel entwickelt, die Flexibilität von Containern maximal effektiv zu nutzen. Das bedeutet, dass keine Annahmen über die Umgebung getroffen werden, in der sie bereitgestellt werden. Beispielsweise verwendet MinIO einen internen Mechanismus zur Redundanzkodierung (erasure coding), der dem System ausreichend Widerstandsfähigkeit verleiht, damit es selbst bei dem Ausfall der Hälfte der Festplatten funktionsfähig bleibt. Zudem verwaltet MinIO die Integrität und Sicherheit von Daten durch eigene Hashing- und Verschlüsselungsverfahren auf Serverseite.
Für solche cloud-nativen Anwendungen sind lokale persistente Volumes (PV) als Backup-Speicher besonders geeignet. Ein lokales PV ermöglicht die Speicherung von Rohdaten, während Anwendungen, die auf diesen PVs basieren, selbst Informationen zusammentragen, um Daten zu skalieren und wachsenden Datenanforderungen gerecht zu werden.
Dieser Ansatz ist viel einfacher und skalierbarer im Vergleich zu PV auf Basis von CSI, die eigene Datenmanagement- und Redundanzebenen in das System einbringen; das Problem ist, dass diese Ebenen normalerweise mit Anwendungen in Konflikt stehen, die im Sinne der Zustandserhaltung entworfen wurden.
Ein selbstbewusster Schritt in Richtung Entkopplung von Daten und Berechnungen
In diesem Artikel haben wir darüber gesprochen, wie Anwendungen sich darauf umorientieren, ohne Zustand zu arbeiten, oder anders ausgedrückt, die Datenspeicherung von den Berechnungen zu trennen. Abschließend betrachten wir einige echte Beispiele für diesen Trend.
, die bekannte Plattform für Datenanalysen, wurde traditionell mit Zustandserhaltung und einer Bereitstellung im HDFS-Dateisystem verwendet. Mit dem Übergang von Spark in eine cloudorientierte Welt wird diese Plattform jedoch zunehmend ohne Zustand mit der Verwendung von `s3a` genutzt. Spark verwendet s3a, um den Zustand in andere Systeme zu übertragen, während die Spark-Container vollständig zustandslos betrieben werden. Andere große Unternehmen im Bereich der Analyse von Big Data, insbesondere, , , gehen auch zur Arbeit mit der Trennung von Datenspeicherung und Berechnungen über diese.
Ähnliche Muster sind auch bei anderen großen Analyseplattformen wie Presto, Tensorflow zu R und Jupyter zu beobachten. Wenn der Zustand in entfernte Cloud-Datenspeichersysteme exportiert wird, wird es viel einfacher, Ihre Anwendung zu verwalten und zu skalieren. Darüber hinaus fördert es die Portabilität der Anwendung in verschiedene Umgebungen.
Quelle: habr.com
