

Vor drei Jahren standen Viktor Tarnawski und Alexej Milovidov von Yandex auf der Bühne HighLoad++ , wie gut ClickHouse ist und dass es nicht langsam wird. Auf der benachbarten Bühne war Alexander Saitzev mit zum Wechsel von ClickHouse von einem anderen analytischen DBMS und zu dem Schluss, dass ClickHouse, natürlich gut, aber nicht sehr benutzerfreundlich. Als im Jahr 2016 die Firma LifeStreet, in der Alexander damals arbeitete, ein mehrpetabyte großes Analysesystem auf ClickHousewie diese spannend war – eine 'Straße aus Ziegeln', voll unbekannter Gefahren – ClickHouse und es erinnerte an ein Minenfeld.
Drei Jahre später ClickHouse ist es viel besser geworden – in der Zwischenzeit hat Alexander die Firma Altinity gegründet, die nicht nur bei den Migrationen auf ClickHouse Dutzende von Projekten hilft, sondern das Produkt selbst zusammen mit Kollegen von Yandex weiter verbessert. Heute ClickHouse ist es immer noch kein entspannter Spaziergang, aber auch kein Minenfeld mehr.
Alexander beschäftigt sich seit 2003 mit verteilten Systemen und hat große Projekte mit MySQL, Oracle und Vertica. Auf dem vergangenen HighLoad++ 2019 erzählte Alexander, einer der Pioniere der Nutzung von ClickHouse, was dieses DBMS heutzutage ausmacht. Wir werden die Hauptmerkmale kennenlernen. ClickHouse: wie es sich von anderen Systemen unterscheidet und in welchen Fällen es effektiver eingesetzt werden kann. An Beispielen werden wir aktuelle und bewährte Praktiken zum Aufbau von Systemen betrachten auf ClickHouse.

Rückblick: Was war vor 3 Jahren
Vor drei Jahren haben wir die Firma LifeStreet findet man ClickHouse von einer anderen analytischen Datenbank migriert, und die Migration der Analytics des Ad-Netzwerks sah so aus:
- Juni 2016. In OpenSource wurde ClickHouse startete unser Projekt;
- August. Proof Of Concept: ein großes Werbenetzwerk, Infrastruktur und 200-300 Terabyte Daten;
- Oktober. Erste Produktionsdaten;
- Dezember. Volle Produktlast — 10-50 Milliarden Ereignisse pro Tag.
- Juni 2017. Erfolgreicher Umzug der Nutzer auf ClickHouse, 2,5 Petabyte Daten auf einem Cluster aus 60 Servern.
Während des Migrationsprozesses wuchs das Verständnis, dass ClickHouse ein gutes System ist, mit dem es Freude macht zu arbeiten, aber es ist ein internes Projekt von Yandex. Daher gibt es besondere Aspekte: Yandex wird zuerst eigene interne Kunden bedienen und erst dann — die Bedürfnisse der externen Nutzer, und ClickHouse war damals in vielen funktionalen Bereichen nicht auf Enterprise-Niveau. ClickHouse schneller und benutzerfreundlicher nicht nur für Yandex, sondern auch für andere Nutzer. Und jetzt bieten wir:
- Schulungen an und unterstützen den Aufbau von Lösungen auf ClickHouse so dass die Kunden keine Fehler machen und die Lösung letztlich funktioniert;
- Wir bieten 24/7 Unterstützung an ClickHouse-Installationen;
- Wir entwickeln eigene Ökosystemprojekte;
- Wir engagieren uns aktiv in der ClickHouse, um den Anforderungen der Nutzer gerecht zu werden, die bestimmte Funktionen sehen möchten.
Und natürlich helfen wir bei der Migration zu ClickHouse mit MySQL, Vertica, Oracle, Greenplum, Redshift und anderen Systemen. Wir haben an vielen Migrationen teilgenommen, und alle waren erfolgreich.
Warum überhaupt zu wechseln zu ClickHouse
Es wird nicht langsam! Das ist der wichtigste Grund. ClickHouse — eine sehr schnelle Datenbank für verschiedene Szenarien:

Zufällige Zitate von Menschen, die lange mit ClickHouse.
Skalierbarkeit. Mit einer anderen Datenbank kann man eine angemessene Leistung auf einer Maschine erreichen, aber ClickHouse man kann nicht nur vertikal, sondern auch horizontal skalieren, indem man einfach Server hinzufügt. Es läuft nicht immer so reibungslos, wie man es sich wünscht, aber es funktioniert. Das System kann mit dem Wachstum des Unternehmens mitwachsen. Es ist wichtig, dass wir momentan nicht durch die Lösung eingeschränkt sind und immer Potenzial für Entwicklung haben.
Portabilität. Keine Bindung an etwas Bestimmtes. Zum Beispiel, mit Amazon Redshift ist es schwierig, irgendwohin umzuziehen. Aber ClickHouse man kann es auf einem Laptop, einem Server installieren, in die Cloud deployen oder sich zurückziehen Kubernetes – es gibt keine Einschränkungen bei der Nutzung der Infrastruktur. Das ist für alle praktisch und stellt einen großen Vorteil dar, den viele andere ähnliche DBs nicht bieten können.
Flexibilität. ClickHouse bleibt nicht auf etwas Bestimmtem stehen, zum Beispiel auf Yandex.Metrica, sondern entwickelt sich weiter und wird in immer mehr verschiedenen Projekten und Branchen eingesetzt. Es kann erweitert werden, indem man neue Funktionen hinzufügt, um neue Herausforderungen zu bewältigen. Zum Beispiel gilt es als unmodern, Logs in einer DB zu speichern, weshalb dafür Elasticsearcherfunden wurde. Aber dank der Flexibilität ClickHousekann man auch Logs darin speichern, und oft ist das sogar besser als in Elasticsearch – dafür braucht man 10-mal weniger Hardware. ClickHouse Kostenlos
. Man muss für nichts bezahlen. Es ist nicht erforderlich, eine Genehmigung zu holen, um das System auf seinem Laptop oder Server zu installieren. Es gibt keine versteckten Gebühren. Dennoch kann keine andere Open Source Datenbanktechnologie mit der Geschwindigkeit von Open SourceMySQL, MariaDB, Greenplum ClickHouse. – sie sind alle wesentlich langsamer. Community, Antrieb und
Spaß . Bei. U ClickHouse Eine großartige Community: Meetups, Chats und Alexey Milovidov, der uns alle mit seiner Energie und seinem Optimismus ansteckt.
Umzug zu ClickHouse
Für den Umstieg auf ClickHouse von etwas anderem benötigen Sie nur drei Dinge:
- Die Einschränkungen zu verstehen ClickHouse und für was er nicht geeignet ist.
- Die Vorteile der Technologie und ihre stärksten Seiten zu nutzen.
- Experimentieren. Selbst wenn man versteht, wie es funktioniert ClickHouse, ist es nicht immer möglich vorherzusagen, wann es schneller, wann langsamer, wann besser und wann schlechter sein wird. Deshalb probieren Sie es aus.
Das Problem des Umzugs
Es gibt nur ein "Aber": Wenn Sie zu ClickHouse von etwas anderem umziehen, läuft normalerweise etwas nicht nach Plan. Wir sind an bestimmte Praktiken und Dinge gewöhnt, die in unserer bevorzugten Datenbank funktionieren. Zum Beispiel hält jeder, der mit SQL-Datenbanken arbeitet, eine solche Funktionalität für unerlässlich:
- Transaktionen;
- Constraints;
- Konsistenz;
- Indizes;
- UPDATE/DELETE;
- NULLs;
- Millisekunden;
- automatische Typanpassungen;
- mehrere Joins;
- beliebige Partitionen;
- Cluster-Management-Tools.
Die erforderliche Funktionalität war jedoch vor drei Jahren anders. ClickHouse Es fehlte an all diesen Funktionen! Weniger als die Hälfte der nicht umgesetzten Dinge sind jetzt noch übrig: Transaktionen, Constraints, Konsistenz, Millisekunden und Typumwandlungen.
Und das Wichtigste ist, dass ClickHouse einige Standardpraktiken und Ansätze nicht funktionieren oder anders funktionieren, als wir es gewohnt sind. Alles, was in ClickHouse, entspricht dem „ClickHouse-Prinzip“, das heißt, die Funktionen unterscheiden sich von anderen Datenbanken. Zum Beispiel:
- Indizes wählen nicht aus, sondern überspringen.
- UPDATE/DELETE sind nicht synchron, sondern asynchron.
- Es gibt mehrere Joins, aber keinen Abfrage-Planer. Wie diese dann ausgeführt werden, ist für Menschen aus der Datenbankwelt überhaupt nicht klar.
ClickHouse-Szenarien
Im Jahr 1960 schrieb der amerikanische Mathematiker ungarischer Herkunft Wigner E. P. einen Artikel „The unreasonable effectiveness of mathematics in the natural sciences“ über die erstaunliche Effektivität der Mathematik in den Naturwissenschaften und darüber, dass die Umwelt aus irgendeinem Grund gut durch mathematische Gesetze beschrieben werden kann. Mathematik ist eine abstrakte Wissenschaft, und die physikalischen Gesetze, die mathematisch formuliert sind, sind nicht trivial und Wigner E. P. hervorgehoben, dass das sehr merkwürdig ist.
Aus meiner Sicht, ClickHouse — eine ähnliche Eigenheit. Um Wigner neu zu formulieren, könnte man sagen: die unbegreifliche Effizienz ist erstaunlich ClickHouse in den unterschiedlichsten Analyseanwendungen!
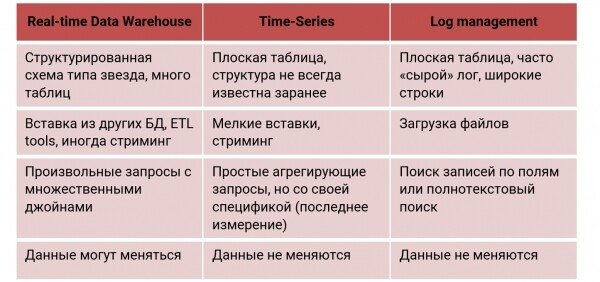
Nehmen wir zum Beispiel ein Echtzeit-Datenlager, in das Daten nahezu kontinuierlich geladen werden. Wir möchten Abfragen mit einer Sekundengenauigkeit erhalten. Bitte — verwenden wir ClickHouse, denn dafür wurde dieses Szenario entwickelt. ClickHouse So wird es nicht nur im Web, sondern auch in der Marketing- und Finanzanalyse eingesetzt, AdTech, sowie in Betrugserkennung.In einem Echtzeit-Datenlager wird ein komplexes strukturiertes Schema vom Typ „Stern“ oder „Schneeflocke“ verwendet, viele Tabellen mit JOIN (manchmal mehreren), und die Daten werden normalerweise in bestimmten Systemen gespeichert und geändert.
Nehmen wir ein anderes Szenario — Zeitreihen: Überwachung von Geräten, Netzwerken, Nutzungstatistiken, Internet der Dinge. Hier treffen wir auf zeitlich geordnete, recht einfache Ereignisse. ClickHouse darauf war ursprünglich nicht ausgelegt, hat sich jedoch bewährt, weshalb große Unternehmen es verwenden ClickHouse als Speicher für Überwachungsinformationen. Um zu prüfen, ob es geeignet ist ClickHouse Für Zeitreihen haben wir Benchmarks basierend auf Ansätzen und Ergebnissen erstellt. InfluxDB und TimescaleDB — spezialisierte Zeitreihen- Datenbanken. , dass ClickHouse, dass selbst ohne Optimierung für solche Aufgaben die Leistung auch auf anderen Feldern überzeugt:
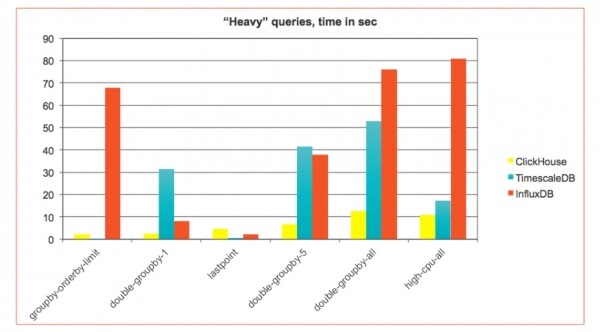
In Zeitreihen- gewöhnlich wird eine schmale Tabelle verwendet — einige kleine Spalten. Aus der Überwachung können riesige Datenmengen eintreffen — Millionen von Einträgen pro Sekunde — und sie kommen in der Regel in kleinen Einfügungen (Echtzeit Streaming). Daher ist ein anderes Einfügeszenario erforderlich, und die Anfragen haben ihren eigenen spezifischen Charakter.
Protokollverwaltung. Das Speichern von Protokollen in einer DB ist normalerweise nicht ideal, aber in ClickHouse kann es mit bestimmten Vorbehalten gemacht werden, wie oben beschrieben. Viele Unternehmen verwenden ClickHouse gerade dafür. In diesem Fall wird eine flache, breite Tabelle verwendet, in der wir die Protokolle vollständig speichern (zum Beispiel in Form von JSON), oder wir zerteilen sie in Teile. Die Daten werden in der Regel in großen Chargen (Dateien) hochgeladen, und wir suchen nach einem bestimmten Feld.
Für jede dieser Funktionen werden normalerweise spezialisierte DBs verwendet. ClickHouse Eine kann dies alles so gut tun, dass sie in der Leistung überlegen ist. Schauen wir uns nun das Zeitreihen- Szenario im Detail an und wie man es richtig „vorbereitet“. ClickHouse unter diesem Szenario.
Zeitreihe
Aktuell ist dies das Hauptszenario, für das ClickHouse es als Standardlösung angesehen wird. Zeitreihe ist eine Reihe von zeitlich geordneten Ereignissen, die Veränderungen eines bestimmten Prozesses im Laufe der Zeit darstellen. Zum Beispiel könnte dies die Herzfrequenz über einen Tag oder die Anzahl der Prozesse im System sein. Alles, was zeitliche Ticks mit irgendwelchen Messungen liefert – das ist Zeitreihen-:

Der Großteil solcher Ereignisse stammt aus der Überwachung. Dies kann nicht nur die Überwachung von Webseiten, sondern auch von realen Geräten sein: Autos, Industrieanlagen, IoT, Produktionsstätten oder autonomer Taxis, in deren Kofferraum Yandex bereits jetzt einen ClickHouse-Server legt.
Es gibt zum Beispiel Unternehmen, die Daten von Schiffen sammeln. Alle paar Sekunden senden Sensoren von Containerschiffen Hunderte verschiedener Messungen. Ingenieure analysieren diese, erstellen Modelle und versuchen zu verstehen, wie effizient das Schiff genutzt wird, da ein Containerschiff keine Sekunde stillstehen sollte. Jede Standzeit ist ein Geldverlust, weshalb es wichtig ist, den Kurs so zu prognostizieren, dass die Liegezeiten minimal sind.
Aktuell gibt es einen Anstieg spezialisierter Datenbanken, die messen Zeitreihen-. Auf der Webseite DB-Engines werden unterschiedliche Datenbanken auf irgendeine Weise bewertet und können nach Typen durchgesehen werden:
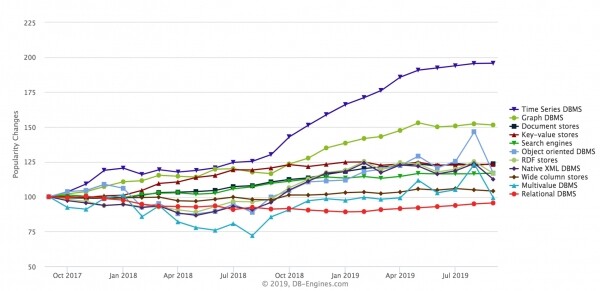
Der am schnellsten wachsende Typ ist Zeitreihen-Datenbanken. Auch Graphdatenbanken wachsen, aber Zeitreihen-Datenbanken wachsen in den letzten Jahren schneller. Typische Vertreter dieser Datenbankfamilie sind InfluxDB, Prometheus, KDB, TimescaleDB (aufgebaut auf PostgreSQL), Lösungen von Amazon. ClickHouse können hier ebenfalls genutzt werden und werden tatsächlich verwendet. Ich nenne einige öffentliche Beispiele.
Einer der Pioniere ist das Unternehmen CloudFlare ((CDN-Anbieter). Sie überwachen ihre (CDN über ClickHouse (DNS-Anfragen, HTTP-Anfragen) mit enormer Last - 6 Millionen Ereignisse pro Sekunde. Alle Daten gehen über Kafka, werden gesendet an ClickHouse, welches die Möglichkeit bietet, in Echtzeit Dashboards von Ereignissen im System zu sehen.
Comcast ist einer der führenden Telekommunikationsanbieter in den USA: Internet, digitales Fernsehen, Telefonie. Sie haben ein ähnliches Managementsystem entwickelt (CDN im Rahmen des Open Source Projekts Apache Traffic Control für die Arbeit mit ihren riesigen Datenmengen. ClickHouse wird als Backend für Analytik verwendet.
Percona hat ClickHouse in ihr PMM, integriert, um die Überwachung verschiedener MySQL.
spezifischer Anforderungen
Time-Series-Datenbanken haben ihre eigenen spezifischen Anforderungen.
- Schnelle Einspeisung von vielen Agenten.Wir müssen Daten von vielen Streams sehr schnell einspeisen. ClickHouse Das gelingt gut, da alle Einspeisungen nicht blockierend sind. Jede Einspeisung stellt eine neue Datei auf der Festplatte dar, und kleine Einspeisungen können auf verschiedene Weise gepuffert werden. In ClickHouse ist es besser, Daten in großen Paketen anstelle von einzelnen Zeilen einzuspeisen.
- Flexible Schema.In Zeitreihen- kennen wir normalerweise die Datenstruktur nicht bis ins Letzte. Man kann ein Überwachungssystem für eine spezifische Anwendung aufbauen, aber dann ist es schwer für eine andere Anwendung zu verwenden. Dafür braucht es ein flexibleres Schema. ClickHouse, das dies ermöglicht, auch wenn es sich um eine strikt typisierte Datenbank handelt.
- Effiziente Speicherung und das "Vergessen" von Daten.Normalerweise handelt es sich um Zeitreihen- gigantische Datenmengen, weshalb sie so effizient wie möglich gespeichert werden müssen. Zum Beispiel hat InfluxDB eine gute Kompression – das ist sein Hauptmerkmal. Aber neben der Speicherung muss man auch in der Lage sein, alte Daten "zu vergessen" und eine Art von Downsampling zu machen – automatische Aggregatzählung.
- Schnelle Abfragen aggregierter Daten.. Manchmal ist es interessant, die letzten 5 Minuten mit einer Genauigkeit von Millisekunden zu betrachten, aber bei monatlichen Daten ist eine minutengenaue oder sekundengenaue Granularität oft nicht nötig — allgemeine Statistiken sind ausreichend. Eine solche Unterstützung ist notwendig, sonst könnte eine Anfrage über 3 Monate sehr lange dauern, selbst in ClickHouse.
- Anfragen vom Typ „letzter Punkt, Stand von». Das sind typische Zeitreihen- Anfragen: Wir betrachten die letzte Messung oder den Zustand des Systems zu einem bestimmten Zeitpunkt t. Für Datenbanken sind dies nicht gerade angenehme Anfragen, aber sie müssen ebenfalls beherrscht werden.
- Das „Zusammenfügen“ von Zeitreihen. Zeitreihe ist eine Zeitreihe. Wenn es zwei Zeitreihen gibt, müssen sie oft verbunden und korreliert werden. Das ist nicht in allen Datenbanken einfach, insbesondere nicht bei nicht synchronisierten Zeitreihen: hier — andere Zeitmarken, dort — andere. Man kann Durchschnittswerte berechnen, aber vielleicht gibt es trotzdem eine Lücke, weshalb es unklar bleibt.
Schauen wir uns an, wie diese Anforderungen in ClickHouse.
Schema
In ClickHouse der Schema für Zeitreihen- verschiedene Ansätze haben, abhängig von der Regelmäßigkeit der Daten. Man kann ein System auf der Grundlage regulärer Daten aufbauen, wenn alle Metriken im Voraus bekannt sind. Zum Beispiel hat CloudFlare es mit der Überwachung gemacht. (CDN — das ist ein gut optimiertes System. Es kann ein allgemeineres System erstellt werden, das die gesamte Infrastruktur und verschiedene Dienste überwacht. Bei unregelmäßigen Daten wissen wir im Voraus nicht, was wir überwachen — und das ist wahrscheinlich der allgemeinste Fall.
Regelmäßige Daten. Spalten. Das Schema ist einfach – Spalten mit den benötigten Typen:
CREATE TABLE cpu (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now(),
time String,
tags_id UInt32, /* join to dim_tag */
usage_user Float64,
usage_system Float64,
usage_idle Float64,
usage_nice Float64,
usage_iowait Float64,
usage_irq Float64,
usage_softirq Float64,
usage_steal Float64,
usage_guest Float64,
usage_guest_nice Float64
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);Dies ist eine gewöhnliche Tabelle, die irgendeine Aktivität zur Systemauslastung überwacht (Benutzer, System, Im Leerlauf, nice). Einfach und bequem, aber nicht flexibel. Wenn wir ein flexibleres Schema wollen, können wir Arrays verwenden.
Unregelmäßige Daten. Arrays:
CREATE TABLE cpu_alc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
)
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
SELECT max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...
Struktur Verschachtelt — dies sind zwei Arrays: metrics.name und metrics.value. Hier können beliebige Überwachungsdaten wie ein Array von Namen und ein Array von Messwerten für jedes Ereignis gespeichert werden. Zur weiteren Optimierung kann anstelle einer einzigen solchen Struktur mehrere davon erstellt werden. Zum Beispiel eine für float-Werte, eine andere für int-Werte, denn int man möchte effizienter speichern.
Aber mit einer solchen Struktur ist der Zugriff komplizierter. Man muss eine spezielle Konstruktion verwenden, um die Werte zuerst über den Index und dann über das Array abzurufen:
SELECT max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...Aber das funktioniert trotzdem schnell genug. Eine andere Möglichkeit, unregelmäßige Daten zu speichern, ist Zeilen-basiert.
Unregelmäßige Daten. Zeilen. Bei dieser traditionellen Methode, die ohne Arrays auskommt, werden sofort Namen und Werte gespeichert. Wenn von einem Gerät auf einmal 5.000 Messwerte kommen, werden 5.000 Zeilen in der DB generiert:
CREATE TABLE cpu_rlc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metric_name LowCardinality(String),
metric_value Float64
) ENGINE = MergeTree(created_date, (metric_name, tags_id, created_at), 8192);
SELECT
maxIf(metric_value, metric_name = 'usage_user'),
...
FROM cpu_r
WHERE metric_name IN ('usage_user', ...)
ClickHouse damit kann man umgehen – es gibt spezielle Erweiterungen ClickHouse SQL. Zum Beispiel maxIf — eine spezielle Funktion, die das Maximum einer Metrik unter bestimmten Bedingungen berechnet. Man kann in einer Anfrage mehrere solcher Ausdrücke schreiben und gleichzeitig Werte für mehrere Metriken berechnen.
Lassen Sie uns drei Ansätze vergleichen:
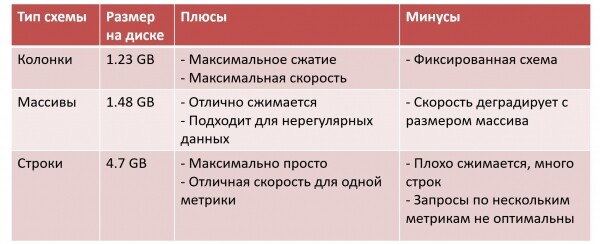
Hier habe ich «Datengröße auf der Festplatte» für einen bestimmten Datensatz hinzugefügt. Bei den Spalten haben wir die kleinste Datengröße: maximale Kompression, maximale Abfragegeschwindigkeit, aber wir zahlen den Preis, dass wir alles sofort fixieren müssen.
Bei Arrays sieht es etwas schlechter aus. Die Daten lassen sich immer noch gut komprimieren, und man kann ein unregelmäßiges Schema speichern. Aber ClickHouse — eine spaltenbasierte Datenbank, und wenn wir beginnen, alles in einem Array zu speichern, verwandelt sie sich in eine zeilenbasierte, und wir bezahlen für die Flexibilität mit Effizienzverlust. Jede Operation erfordert, dass das gesamte Array in den Speicher geladen wird, anschließend muss das gewünschte Element darin gefunden werden – und wenn das Array wächst, verschlechtert sich die Geschwindigkeit.
In einem der Unternehmen, das diesen Ansatz verwendet (zum Beispiel, ), Arrays werden in Stücke von 128 Elementen zerschnitten. Daten von mehreren Tausend Metriken in einem Volumen von 200 TB pro Tag werden nicht in einem einzigen Array, sondern in 10 oder 30 Arrays mit spezieller Logik zur Speicherung gehalten.
Der einfachste Ansatz besteht darin, mit Strings zu arbeiten. Doch die Daten lassen sich schlecht komprimieren, wodurch die Tabellengröße groß wird. Außerdem arbeitet ClickHouse ineffizient, wenn Abfragen für mehrere Metriken erfolgen.
Hybrides Schema
Angenommen, wir haben uns für das Array-Schema entschieden. Wenn wir jedoch wissen, dass die meisten unserer Dashboards nur die Metriken 'user' und 'system' anzeigen, können wir diese Metriken zusätzlich auf Tabellenebene aus dem Array in Spalten materialisieren, und zwar wie folgt:
CREATE TABLE cpu_alc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
),
usage_user Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_user')],
usage_system Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_system')]
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
Beim Einfügen ClickHouse wird dies automatisch berechnet. So kann man das Angenehme mit dem Nützlichen verbinden: Das Schema ist flexibel und allgemein, aber die am häufigsten verwendeten Spalten wurden herausgezogen. Ich möchte anmerken, dass dies keine Änderungen am Einfügen erforderte und ETL, der weiterhin Arrays in die Tabelle einfügt. Wir haben einfach ALTER TABLE, ein paar Spalten hinzugefügt und ein hybrides, schnelleres Schema erhalten, mit dem sofort gearbeitet werden kann.
Codecs und Kompression
Für Zeitreihen- es ist wichtig, wie gut Sie die Daten verpacken, da die Informationsmenge sehr groß sein kann. In ClickHouse gibt es eine Reihe von Werkzeugen, um einen Kompressionseffekt von 1:10, 1:20 und manchmal noch mehr zu erzielen. Das bedeutet, dass unverpackte Daten von 1 TB auf der Festplatte 50-100 GB einnehmen. Ein kleinerer Speicherplatz ist vorteilhaft, da die Daten schneller gelesen und verarbeitet werden können.
Um ein hohes Niveau an Kompression zu erreichen, ClickHouse unterstützt die folgenden Codecs:
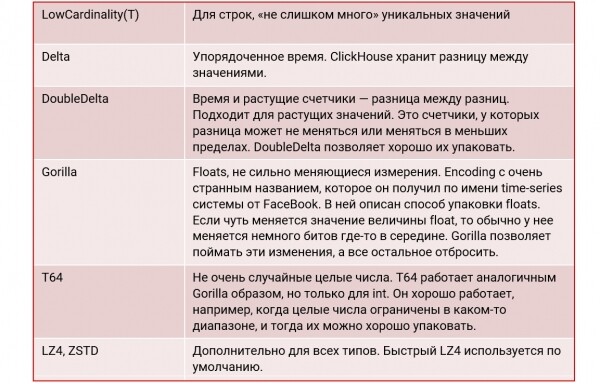
Beispiel für eine Tabelle:
CREATE TABLE benchmark.cpu_codecs_lz4 (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now() Codec(DoubleDelta, LZ4),
tags_id UInt32,
usage_user Float64 Codec(Gorilla, LZ4),
usage_system Float64 Codec(Gorilla, LZ4),
usage_idle Float64 Codec(Gorilla, LZ4),
usage_nice Float64 Codec(Gorilla, LZ4),
usage_iowait Float64 Codec(Gorilla, LZ4),
usage_irq Float64 Codec(Gorilla, LZ4),
usage_softirq Float64 Codec(Gorilla, LZ4),
usage_steal Float64 Codec(Gorilla, LZ4),
usage_guest Float64 Codec(Gorilla, LZ4),
usage_guest_nice Float64 Codec(Gorilla, LZ4),
additional_tags String DEFAULT ''
)
ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);Hier definieren wir den Codec DoubleDelta im einen Fall, im anderen — Gorilla, und wir fügen noch hinzu LZ4 Kompression. Dadurch wird die Datengröße auf der Festplatte erheblich reduziert:
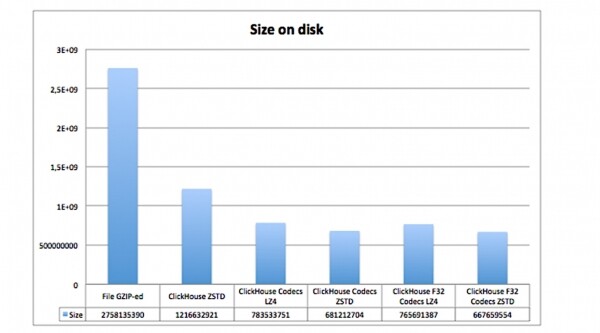
Hier sehen Sie, wie viel Platz dieselben Daten mit verschiedenen Codecs und Kompressionen einnehmen:
- in einer GZIP-komprimierten Datei auf der Festplatte;
- in ClickHouse ohne Codecs, aber mit ZSTD-Kompression;
- in ClickHouse mit den Codecs und Kompressionen LZ4 und ZSTD.
Es ist offensichtlich, dass Tabellen mit Codecs viel weniger Platz beanspruchen.
Größe zählt
Ebenso wichtig ist der richtige Datentyp:
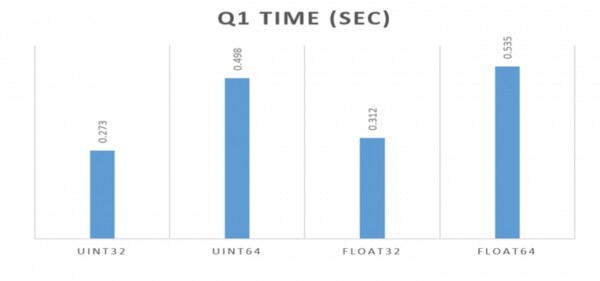
In allen obigen Beispielen habe ich Float64verwendet. Aber wenn wir Float32gewählt hätten, wäre das sogar besser gewesen. Dies wurde gut von den Leuten bei Percona in dem verlinkten Artikel demonstriert. Es ist wichtig, den kompaktesten Typ zu verwenden, der für die Aufgabe geeignet ist: auch in geringerem Maße hinsichtlich der Größe auf der Festplatte als bezüglich der Abfragegeschwindigkeit. ClickHouse darauf sehr empfindlich.
Wenn Sie verwenden können int32 statt int64, erwarten Sie fast eine Verdopplung der Leistung. Die Daten benötigen weniger Speicher, und die gesamte „Arithmetik“ läuft viel schneller. ClickHouse eine sehr streng typisierte Struktur in sich selbst, die alle Möglichkeiten, die moderne Systeme bieten, optimal nutzt.
Aggregation und materialisierte Ansichten
Aggregation und materialisierte Ansichten ermöglichen es, Aggregate für verschiedene Anwendungsfälle zu erstellen:
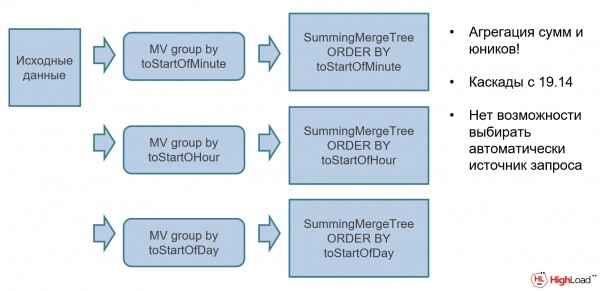
Zum Beispiel haben Sie möglicherweise nicht aggregierte Rohdaten, zu denen verschiedene materialisierte Ansichten mit automatischer Summierung über einen speziellen Motor hinzugefügt werden können. SummingMergeTree (SMT). SMT – ist eine spezielle aggregierende Datenstruktur, die Aggregate automatisch berechnet. Rohdaten werden in die Datenbank eingefügt, automatisch aggregiert und können sofort für Dashboards verwendet werden.
TTL – "vergessen" alte Daten
Wie vergisst man Daten, die nicht mehr benötigt werden? ClickHouse das kann. Bei der Erstellung von Tabellen können Sie TTL Ausdrücke angeben: zum Beispiel, dass minutengenaue Daten einen Tag gespeichert werden, tägliche Daten 30 Tage und wöchentliche oder monatliche nie berührt werden:
CREATE TABLE aggr_by_minute
…
TTL time + interval 1 day
CREATE TABLE aggr_by_day
…
TTL time + interval 30 day
CREATE TABLE aggr_by_week
…
/* no TTL */
Multi-tier – teilen wir Daten auf Festplatten auf
Diese Idee weiterführend können Daten in ClickHouse an verschiedenen Orten. Angenommen, wir möchten die heißen Daten der letzten Woche auf einem extrem schnellen lokalen SSD, während wir die älteren Daten an einem anderen Ort speichern. In ClickHouse ist das jetzt möglich:

Es kann eine Speicherungspolitik (storage policy) so konfiguriert werden, dass ClickHouse Daten automatisch verschoben werden, sobald bestimmte Bedingungen erfüllt sind.
Doch das ist noch nicht alles. Auf der Ebene einer bestimmten Tabelle können Regelungen definiert werden, wann genau die Daten zeitlich in die kalte Speicherung überführt werden. Zum Beispiel liegen Daten 7 Tage auf einer sehr schnellen Festplatte, alles, was älter ist, wird auf eine langsamere Festplatte verschoben. Das hat den Vorteil, dass das System auf maximaler Leistung bleibt, während gleichzeitig die Kosten kontrolliert werden und keine Mittel für kalte Daten ausgegeben werden:
CREATE TABLE
...
TTL date + INTERVAL 7 DAY TO VOLUME 'cold_volume',
date + INTERVAL 180 DAY DELETE
Einzigartige Möglichkeiten ClickHouse
Fast alles in ClickHouse hat solche "Besonderheiten", aber diese werden durch Exklusivität - Dinge, die in anderen Datenbanken nicht vorhanden sind - aufgehoben. Zum Beispiel sind hier einige der einzigartigen Funktionen ClickHouse:
- ArraysIn ClickHouse sehr gute Unterstützung für Arrays sowie die Möglichkeit, komplexe Berechnungen darauf durchzuführen.
- Datenaggregationsstrukturen. Dies ist eines der "Killer-Features" ClickHouse. Obwohl die Leute von Yandex sagen, dass wir keine Daten aggregieren wollen, aggregiert jeder in ClickHouse, weil es schnell und bequem ist.
- Materialisierte Sichten. Zusammen mit den Datenaggregationsstrukturen ermöglichen materialisierte Sichten eine benutzerfreundliche Echtzeit Aggregation.
- ClickHouse SQL. Dies ist eine Erweiterung der Sprache SQL mit einigen zusätzlichen und exklusiven Funktionen, die nur in ClickHouseverfügbar sind. Früher war es einerseits eine Erweiterung, andererseits jedoch ein Nachteil. Jetzt haben wir fast alle Nachteile im Vergleich zu SQL 92 beseitigt, jetzt ist es nur noch eine Erweiterung.
- Lambda-Ausdrücke. Gibt es diese auch in anderen Datenbanken?
- ML-Unterstützung. Dies gibt es in verschiedenen DBs, in einigen besser, in anderen schlechter.
- Open Source. Wir können ClickHouse gemeinsam erweitern. Momentan gibt es in ClickHouse ungefähr 500 Mitwirkende, und diese Zahl wächst ständig.
Clever abgefragte
In ClickHouse gibt es viele verschiedene Möglichkeiten, das Gleiche zu tun. Zum Beispiel kann man das letzte Wert aus der Tabelle auf drei verschiedene Arten zurückgeben für CPU (es gibt noch eine vierte, aber die ist noch exzentrischer).
Der erste zeigt, wie bequem es ist, in ClickHouse Abfragen, wenn Sie überprüfen möchten, ob Tupel in der Unterabfrage enthalten ist. Das habe ich persönlich in anderen Datenbanken sehr vermisst. Wenn ich etwas mit einer Unterabfrage vergleichen möchte, kann ich in anderen Datenbanken nur mit einem Skalar vergleichen, während ich für mehrere Spalten schreiben muss JOINIn ClickHouse man kann Tupel verwenden:
SELECT *
FROM cpu
WHERE (tags_id, created_at) IN
(SELECT tags_id, max(created_at)
FROM cpu
GROUP BY tags_id)Die zweite Methode macht dasselbe, verwendet jedoch die Aggregatfunktion argMax:
SELECT
argMax(usage_user), created_at),
argMax(usage_system), created_at),
...
FROM cpu In ClickHouse Es gibt mehrere Dutzend Aggregatfunktionen, und wenn man Kombinatoren verwendet, ergeben sich gemäß den Kombinatorikgesetzen etwa tausend. ArgMax ist eine der Funktionen, die den maximalen Wert berechnet: Die Abfrage gibt den Wert zurück usage_user, bei dem der maximale Wert erreicht wird created_at:
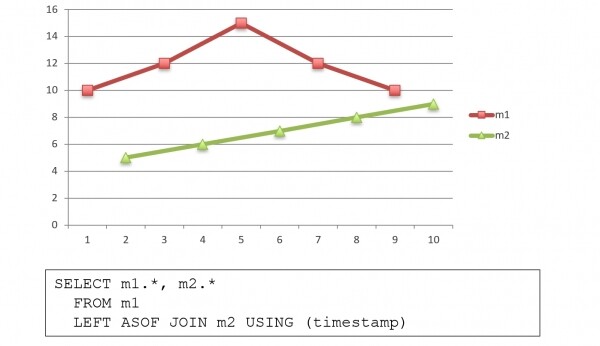
SELECT now() as created_at,
cpu.*
FROM (SELECT DISTINCT tags_id from cpu) base
ASOF LEFT JOIN cpu USING (tags_id, created_at)
ASOF JOIN ist das „Zusammenfügen“ von Zeilen mit unterschiedlichen Zeitstempeln. Dies ist eine einzigartige Funktion für Datenbanken, die auch nur in kdb+verfügbar ist. Wenn zwei Zeitreihen mit unterschiedlichen Zeitstempeln vorhanden sind, ASOF JOIN ermöglicht es, diese in einer Anfrage zu verschieben und zusammenzufügen. Für jeden Wert in einer Zeitreihe gibt es den nächstgelegenen Wert in einer anderen, und sie werden in einer Zeile zurückgegeben:
Analytische Funktionen
Im Standard SQL-2003 kann man so schreiben:
SELECT origin,
timestamp,
timestamp -LAG(timestamp, 1) OVER (PARTITION BY origin ORDER BY timestamp) AS duration,
timestamp -MIN(timestamp) OVER (PARTITION BY origin ORDER BY timestamp) AS startseq_duration,
ROW_NUMBER() OVER (PARTITION BY origin ORDER BY timestamp) AS sequence,
COUNT() OVER (PARTITION BY origin ORDER BY timestamp) AS nb
FROM mytable
ORDER BY origin, timestamp;
In ClickHouse das ist nicht erlaubt – es unterstützt den Standard nicht SQL-2003 und wird es wahrscheinlich niemals tun. Stattdessen ClickHouse ist es üblich, so zu schreiben:

Ich habe versprochen, Lamba-Funktionen – hier sind sie!
Das ist das Äquivalent einer analytischen Abfrage im Standard SQL-2003: es berechnet die Differenz zwischen zwei timestamp, duration, Reihenfolge – alles, was wir normalerweise als analytische Funktionen betrachten. In ClickHouse wir sie über Arrays: zuerst fassen wir die Daten in einem Array zusammen, danach führen wir alles, was wir wollen, auf dem Array durch und entfalten es dann wieder. Das ist nicht sehr benutzerfreundlich, erfordert eine Vorliebe für funktionale Programmierung, mindestens, aber es ist sehr flexibel.
Spezialfunktionen
Außerdem in ClickHouse viele spezialisierte Funktionen. Zum Beispiel, wie definiert man, wie viele Sitzungen gleichzeitig ablaufen? Eine typische Aufgabe beim Monitoring besteht darin, die maximale Last durch eine Anfrage zu bestimmen. In ClickHouse gibt es eine spezielle Funktion für dieses Ziel:

Generell gibt es für viele Zwecke in ClickHouse spezielle Funktionen:
- runningDifference, runningAccumulate, neighbor;
- sumMap(key, value);
- timeSeriesGroupSum(uid, timestamp, value);
- timeSeriesGroupRateSum(uid, timestamp, value);
- skewPop, skewSamp, kurtPop, kurtSamp;
- WITH FILL / WITH TIES;
- simpleLinearRegression, stochasticLinearRegression.
Dies ist keine vollständige Liste von Funktionen; insgesamt sind es 500-600. Hinweis: alle Funktionen in ClickHouse sind in der Systemtabelle enthalten (nicht alle sind dokumentiert, aber alle sind interessant):
select * from system.functions order by nameClickHouse enthält an sich viele Informationen über sich selbst, einschließlich log tables, query_log, Trace-Log, Log für Datenbankoperationen (part_log), Metrik-Log und das System-Log, das normalerweise auf die Festplatte geschrieben wird. Das Metrik-Log ist Zeitreihen- in ClickHouse von selbst ClickHouse: Die Datenbank kann für sich selbst eine Rolle spielen Zeitreihen- von Datenbanken, indem sie sich somit „selbst verzehrt“.

Das ist auch etwas Einzigartiges — wenn wir gute Arbeit für Zeitreihen-leisten, warum können wir dann nicht alles Notwendige in uns selbst speichern? Wir brauchen kein Prometheus, wir speichern alles in uns. Wir haben Grafana und überwachen uns selbst. Allerdings, wenn ClickHouse Wenn es ausfällt, werden wir nicht sehen, warum, deshalb macht man das normalerweise nicht.
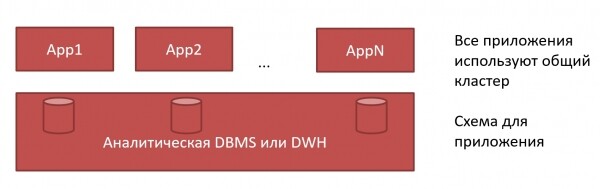
Ein großer Cluster oder viele kleine ClickHouse
Was ist besser – ein großer Cluster oder viele kleine ClickHouse? Der traditionelle Ansatz für DWH ist ein großer Cluster, in dem für jede Anwendung Schemas erstellt werden. Wir kommen zu dem DB-Administrator – geben Sie uns ein Schema, und es wird uns ausgehändigt:
In ClickHouse man kann es auch anders machen. Jede Anwendung kann ihr eigenes ClickHouse:
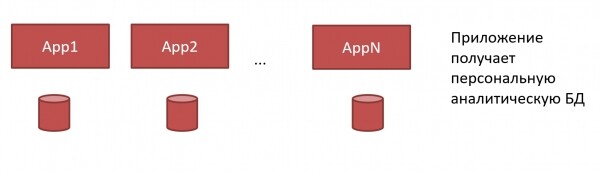
Wir benötigen keinen großen, monstruösen DWH und unkooperativen Administrator mehr. Wir können jeder Anwendung ihr eigenes ClickHouse, und der Entwickler kann das selbst machen, da ClickHouse es sehr einfach zu installieren ist und kein aufwändiges Management erfordert:
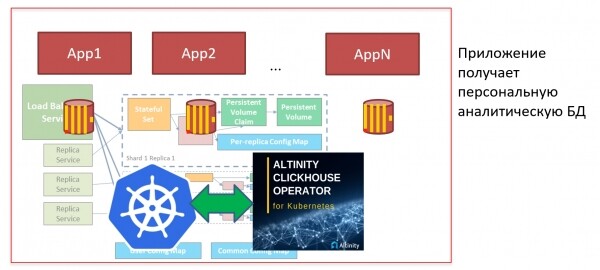
Aber wenn wir viele haben ClickHouse, und es oft installiert werden muss, möchte man diesen Prozess automatisieren. Dazu kann man beispielsweise die Kubernetes und clickhouse-Operator verwenden. In Kubernetes ClickHouse lässt sich mit einem Klick installieren: Ich kann den Knopf drücken, das Manifest starten, und die Datenbank ist bereit. Man kann sofort ein Schema erstellen, beginnen, Metriken hochzuladen, und nach 5 Minuten habe ich bereits ein Dashboard bereit Grafana. So einfach ist das!
Was ist das Ergebnis?
Also, ClickHouse – das ist:
- Schnell. Das ist allgemein bekannt.
- Einfach. Es ist etwas umstritten, aber ich denke, dass man sagt: Hart im Lernen, leicht im Kampf. Wenn man versteht, wie ClickHouse es funktioniert, ist alles andere sehr einfach.
- Universell. Es eignet sich für verschiedene Szenarien: DWH, Zeitreihen, Log-Speicherung. Aber das ist keine OLTP- Datenbank, also versuchen Sie nicht, dort kurze Einfügungen und Abfragen zu machen.
- Interessant. Wahrscheinlich hat jeder, der mit ClickHousearbeitet, viele interessante Momente im guten und im schlechten Sinne erlebt. Zum Beispiel, wenn ein neues Release herauskommt und nichts mehr funktioniert. Oder wenn Sie zwei Tage lang an einem Problem gearbeitet haben, aber die Lösung dann in zwei Minuten nach einer Frage im Telegram-Chat gefunden wird. Oder wie bei der Konferenz, als bei einem Bericht von Alexey Milovidov ein Screenshot von ClickHouse den Stream unterbrochen hat. HighLoad++Solche Dinge passieren ständig und machen unser Leben mit ClickHouse lebendig und interessant!
Die Präsentation kann angesehen werden .

Das lang erwartete Treffen der Entwickler von hochbelasteten Systemen findet am 9. und 10. November in Skolkovo statt. Endlich wird es eine Offline-Konferenz sein (wenn auch unter Einhaltung aller Vorsichtsmaßnahmen), denn die Energie von HighLoad++ lässt sich nicht online verpacken.
Für die Konferenz finden und präsentieren wir Ihnen Beispiele für die maximalen Möglichkeiten der Technologien: HighLoad++ war, ist und wird der einzige Ort sein, an dem Sie in zwei Tagen erfahren können, wie Facebook, Yandex, VKontakte, Google und Amazon aufgebaut sind.
Seit 2007 halten wir unsere Treffen ohne Unterbrechung und in diesem Jahr treffen wir uns zum 14. Mal. In dieser Zeit hat sich die Konferenz verzehnfacht; im letzten Jahr versammelten sich 3339 Teilnehmer, 165 Referenten für Vorträge und Meetups, während gleichzeitig 16 Tracks stattfanden.
Letztes Jahr standen Ihnen 20 Busse, 5280 Liter Tee und Kaffee, 1650 Liter Fruchtsäfte und 10200 Flaschen Wasser zur Verfügung. Zudem gab es 2640 Kilogramm Essen, 16000 Teller und 25000 Becher. Übrigens haben wir von den Erlösen des recycelten Papiers 100 Eichensetzlinge gepflanzt 🙂Tickets können gekauft werden , um Neuigkeiten zur Konferenz zu erhalten — , und um zu reden — in allen sozialen Netzwerken: , , und .
Quelle: habr.com
