

In diesem Artikel erzähle ich, wie das Projekt, an dem ich arbeite, sich von einem großen Monolithen in eine Sammlung von Mikrodiensten verwandelt hat.
Das Projekt hat seine Geschichte bereits Anfang der 2000er Jahre begonnen. Die ersten Versionen wurden in Visual Basic 6 geschrieben. Im Laufe der Zeit wurde klar, dass die Entwicklung in dieser Sprache in der Zukunft schwierig zu unterstützen sein würde, da sich sowohl die IDE als auch die Sprache nur wenig weiterentwickelten. Ende der 2000er Jahre wurde beschlossen, auf das vielversprechendere C# umzusteigen. Die neue Version wurde parallel zur Überarbeitung der alten geschrieben, wobei immer mehr Code in .NET verfasst wurde. Das Backend in C# war zunächst auf eine serviceorientierte Architektur ausgelegt, jedoch wurden gemeinsam genutzte Bibliotheken mit Logik verwendet und die Dienste wurden in einem einzigen Prozess ausgeführt. Es entstand eine Anwendung, die wir „dienstorientierten Monolithen“ nannten.
Einer der wenigen Vorteile dieser Kombination war die Möglichkeit, dass sich die Dienste über eine externe API gegenseitig aufrufen konnten. Es gab klare Anzeichen für den Übergang zu einer korrekteren serviceorientierten Architektur und in Zukunft sogar zu einer Mikrodienste-Architektur.
Unsere Arbeit an der Dekomposition begann etwa im Jahr 2015. Wir haben zwar noch nicht den idealen Zustand erreicht – einige Teile des großen Projekts lassen sich kaum noch als Monolithen bezeichnen, aber sie sind auch keine Mikrodienste. Dennoch ist der Fortschritt erheblich.
Darüber werde ich im Artikel berichten.
Inhalt
Architektur und Probleme der bestehenden Lösung
Ursprünglich sah die Architektur so aus: UI – eine separate Anwendung, der monolithische Teil wurde in Visual Basic 6 geschrieben, die Anwendung in .NET war eine Sammlung von verbundenen Diensten, die mit einer recht großen Datenbank arbeiteten.
Nachteile der vorherigen Lösung
Single Point of Failure
Wir hatten einen Single Point of Failure: Die .NET-Anwendung lief in einem Prozess. Wenn in einem der Module ein Fehler auftrat, fiel die gesamte Anwendung aus und musste neu gestartet werden. Da bei uns viele Prozesse für verschiedene Benutzer automatisiert werden, konnten aufgrund eines Fehlers in einem dieser Prozesse einige Zeit lang alle nicht arbeiten. Und bei einem Programmfehler half auch die Redundanz nicht.
Warteschlange für Anpassungen
Dieses Problem ist eher organisatorischer Natur. In unserer Anwendung gibt es viele Auftraggeber, die alle die Anpassungen so schnell wie möglich durchführen möchten. Früher war es unmöglich, dies parallel zu tun, und alle Auftraggeber mussten sich anstellen. Dieser Prozess führte zu Unmut im Geschäft, da sie beweisen mussten, dass ihre Anforderungen Wert hatten. Das Entwicklungsteam verbrachte Zeit damit, diese Warteschlange zu organisieren. Das nahm viel Zeit und Energie in Anspruch, und das Produkt konnte letztendlich nicht so schnell geändert werden, wie es gewünscht war.
Suboptimale Ressourcennutzung
Bei der Bereitstellung von Dienstleistungen in einem einheitlichen Prozess haben wir die Konfiguration immer vollständig von Server zu Server kopiert. Wir wollten die am stärksten ausgelasteten Dienste separat betreiben, um Ressourcen nicht zu verschwenden und ein flexibleres Management unseres Bereitstellungsschemas zu ermöglichen.
Moderne Technologien in die Praxis umzusetzen, ist schwierig.
Ein bekanntes Problem für alle Entwickler: Es besteht der Wunsch, moderne Technologien in ein Projekt einzuführen, aber es fehlt die Möglichkeit. Bei einer großen monolithischen Lösung verwandelt sich jedes Update der bestehenden Bibliothek, ganz zu schweigen von einem Wechsel zu einer neuen, in eine durchaus anspruchsvolle Aufgabe. Man muss lange argumentieren, um dem Teamleiter zu beweisen, dass dies mehr Vorteile bringt, als Nerven kostet.
Die Schwierigkeiten bei der Umsetzung von Änderungen.
Das war das größte Problem – wir veröffentlichten alle zwei Monate neue Versionen.
Jede Veröffentlichung wurde trotz Tests und der Anstrengungen der Entwickler zu einer echten Katastrophe für die Bank. Das Unternehmen war sich bewusst, dass zu Beginn der Woche ein Teil der Funktionalität nicht verfügbar sein würde. Und die Entwickler wussten, dass sie eine Woche ernsthafter Vorfälle erwarten würden.
Der Wunsch nach Veränderung war bei allen vorhanden.
Erwartungen an Mikrodienste
Bereitstellung von Komponenten gemäß ihrer Verfügbarkeit. Bereitstellung von Komponenten nach Verfügbarkeit durch Decomposition der Lösungen und Trennung verschiedener Prozesse.
Kleine Produktteams. Das ist wichtig, da es schwierig war, mit einem großen Team, das an einem alten Monolithen arbeitet, zu managen. Ein solches Team musste nach einem strengen Prozess arbeiten, während mehr Kreativität und Unabhängigkeit gewünscht war. Dies konnten sich nur kleine Teams leisten.
Isolation der Dienste in separaten Prozessen. Idealerweise wäre es wünschenswert, sie in Containern zu isolieren, allerdings laufen viele Dienste, die auf dem .NET Framework basieren, nur unter Windows. Es kommen nun Dienste auf .NET Core auf, aber davon gibt es bisher nur wenige.
Flexibilität bei der Bereitstellung. Wir möchten Dienste so kombinieren, wie es für uns notwendig ist, und nicht so, wie es der Code vorschreibt.
Nutzung neuer Technologien. Das ist für jeden Programmierer interessant.
Probleme beim Übergang
Natürlich, wenn es einfach wäre, den Monolithen in Mikrodienste zu zerlegen, müsste man nicht auf Konferenzen darüber sprechen und Artikel schreiben. In diesem Prozess gibt es viele Stolpersteine, von denen ich die wichtigsten beschreiben werde, die uns gehindert haben.
Das erste Problem typisch für die meisten Monolithen: die Kohärenz der Geschäftslogik. Wenn wir einen Monolithen schreiben, möchten wir unsere Klassen wiederverwenden, um keinen überflüssigen Code zu schreiben. Bei der Umstellung auf Microservices wird dies jedoch problematisch: Der gesamte Code ist relativ eng miteinander verbunden, und es ist schwierig, die Services zu trennen.
Zum Zeitpunkt des Projektstarts gab es im Repository mehr als 500 Projekte und über 700.000 Zeilen Code. Das ist ein recht umfangreiches Vorhaben und das zweite Problem. Einfach zu versuchen, es in Microservices zu teilen, war nicht möglich.
Das dritte Problem — fehlende notwendige Infrastruktur. Tatsächlich haben wir den Quellcode manuell auf die Server kopiert.
Wie man von einem Monolithen zu Mikrodiensten wechselt
Abtrennung von Microservices
Zunächst haben wir für uns selbst festgelegt, dass die Abtrennung von Microservices ein iterativer Prozess ist. Von uns wurde immer gefordert, parallel an der Entwicklung der Geschäftsanforderungen zu arbeiten. Wie wir dies technisch umsetzen, ist bereits unser Problem. Daher haben wir uns auf einen iterativen Prozess vorbereitet. Andernfalls funktioniert es nicht, wenn man eine große Anwendung hat, die ursprünglich nicht darauf ausgelegt ist, umgeschrieben zu werden.
Welche Methoden verwenden wir zur Abtrennung von Microservices?
Erste Methode — bestehende Module als Dienste herauszulösen. In dieser Hinsicht hatten wir Glück: Es gab bereits implementierte Dienste, die das WCF-Protokoll verwendeten. Diese waren in separate Assemblies aufgeteilt. Wir haben sie getrennt übertragen und jeder Assembly ein kleines Startmodul hinzugefügt. Dieses wurde mit der großartigen Topshelf-Bibliothek geschrieben, die es ermöglicht, die Anwendung sowohl als Dienst als auch als Konsole auszuführen. Das ist für die Fehlersuche praktisch, da keine zusätzlichen Projekte im Lösungsansatz erforderlich sind.
Die Dienste waren durch Geschäftslogik miteinander verbunden, da sie gemeinsame Assemblies verwendeten und mit einer gemeinsamen Datenbank arbeiteten. Man konnte sie nicht wirklich als reinrassige Mikrodienste bezeichnen. Dennoch konnten wir diese Dienste separat in unterschiedlichen Prozessen bereitstellen. Das allein reduziert den Einfluss, den sie aufeinander haben, und verringert das Problem mit paralleler Entwicklung und einem einzigen Fehlerpunkt.
Das Hosting mit einer Zeile Code in der Program-Klasse. Die Arbeit mit Topshelf haben wir in eine Hilfsklasse verborgen.
namespace RBA.Services.Accounts.Host
{
internal class Program
{
private static void Main(string[] args)
{
HostRunner.Run("RBA.Services.Accounts.Host");
}
}
}
Die zweite Möglichkeit zur Ausgliederung von Mikrodiensten: sie zur Lösung neuer Aufgaben zu erstellen. Wenn dabei das Monolith nicht wächst, ist das bereits ein guter Fortschritt, das bedeutet, dass wir auf dem richtigen Weg sind. Um neue Herausforderungen anzugehen, haben wir versucht, separate Dienste zu schaffen. Wo es möglich war, haben wir 'kanonischere' Dienste entwickelt, die vollständig ihre eigene Datenmodellierung und eine separate Datenbank verwalten.
Wie viele andere haben auch wir mit Authentifizierungs- und Autorisierungsdiensten begonnen. Diese eignen sich perfekt dafür. Sie sind unabhängig und verfügen in der Regel über ein separates Datenmodell. Diese Dienste interagieren nicht selbst mit dem Monolithen, sondern nur umgekehrt, wenn der Monolith sie zur Lösung bestimmter Aufgaben anfragt. Auf diesen Diensten kann man den Übergang zu einer neuen Architektur beginnen, die Infrastruktur testen und verschiedene Ansätze in Bezug auf Netzwerkbibliotheken ausprobieren. In unserer Organisation gibt es keine Teams, die keinen Authentifizierungsdienst erstellen könnten.
Der dritte Ansatz zur Herausbildung von Mikrodiensten, die wir verwenden, ist für uns etwas spezifisch. Es handelt sich um die Auslagerung von Geschäftslogik aus der UI-Schicht. Unsere Hauptanwendung ist eine Desktop-App, die, wie auch das Backend, in C# geschrieben ist. Die Entwickler haben gelegentlich Fehler gemacht und Teile der Logik, die im Backend existieren und wiederverwendet werden sollten, in die UI ausgelagert.
Ein konkretes Beispiel aus dem Code der UI-Komponente zeigt, dass ein großer Teil dieser Lösung echte Geschäftslogik enthält, die auch in anderen Prozessen nützlich ist, nicht nur für die Erstellung von UI-Formularen.
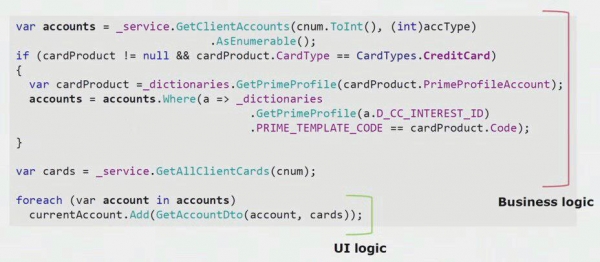
Die echte Logik in der UI beschränkt sich nur auf die letzten beiden Zeilen. Wir haben sie auf den Server übertragen, um die Wiederverwendbarkeit zu ermöglichen, was die UI reduziert und zu einer korrekten Architektur führt.
Der vierte, und wichtigste Weg zur Abgrenzung von Mikrodiensten, was eine Modularisierung ermöglicht – die Auslagerung bestehender Dienste mit anschließender Überarbeitung. Wenn wir bestehende Module unverändert übernehmen, entspricht das Ergebnis nicht immer den Erwartungen der Entwickler, und der Geschäftsprozess könnte seit der Erstellung der Funktionalität veraltet sein. Durch Refactoring können wir neue Geschäftsprozesse unterstützen, denn die Anforderungen an Unternehmen ändern sich ständig. Wir können den Quellcode verbessern, bekannte Mängel beseitigen und ein hochwertigeres Datenmodell erstellen. Es ergeben sich viele Vorteile.
Die Trennung von Dienstleistungen mit einer Verarbeitung ist untrennbar mit dem Konzept des begrenzten Kontexts verbunden. Dieses Konzept stammt aus der objektorientierten Gestaltung. Es bezeichnet einen Bereich des Domänenmodells, in dem alle Begriffe einer einheitlichen Sprache eindeutig definiert sind. Betrachten wir das Beispiel des Kontexts von Versicherungen und Rechnungen. Wir haben eine monolithische Anwendung und müssen in den Versicherungen mit der Rechnung arbeiten. Wir erwarten, dass der Entwickler in einem anderen Build die bestehende Klasse „Rechnung“ findet und von der Klasse „Versicherung“ darauf verweist, wodurch wir funktionierenden Code erhalten. Das DRY-Prinzip wird eingehalten, was die Aufgabe durch die Nutzung bestehenden Codes beschleunigt.
Letztendlich stellt sich heraus, dass die Kontexte von Rechnungen und Versicherungen miteinander verbunden sind. Wenn neue Anforderungen entstehen, wird diese Verbindung die Entwicklung behindern und die Komplexität der ohnehin schon komplizierten Geschäftslogik erhöhen. Um dieses Problem zu lösen, ist es notwendig, im Code die Grenzen zwischen den Kontexten zu finden und deren Verstöße zu beseitigen. Zum Beispiel könnte es für den Versicherungskontext ausreichend sein, eine 20-stellige Kontonummer der Zentralbank und das Eröffnungsdatum des Kontos zu verwenden.
Um diese begrenzten Kontexte voneinander zu trennen und den Prozess der Herauslösung von Mikrodiensten aus monolithischen Lösungen zu beginnen, haben wir den Ansatz verwendet, externe APIs innerhalb der Anwendung zu erstellen. Wenn wir wussten, dass ein bestimmtes Modul ein Mikrodienst werden sollte oder sich im Prozess ändern würde, führten wir sofort Aufrufe der Logik, die zu einem anderen eingeschränkten Kontext gehört, über externe Calls durch. Zum Beispiel über REST oder WCF.
Wir haben für uns entschieden, dass wir keinen Code vermeiden werden, der verteilte Transaktionen erfordert. In unserem Fall war es relativ einfach, diese Regel einzuhalten. Bislang gab es keine Situationen, in denen tatsächlich strikte verteilte Transaktionen erforderlich waren – die endgültige Konsistenz zwischen den Modulen war völlig ausreichend.
Betrachten wir ein konkretes Beispiel. Es gibt das Konzept des Orchestrators — eine Pipeline, die die Entität „Antrag“ verarbeitet. Sie erstellt nacheinander den Kunden, das Konto und die Bankkarte. Wenn der Kunde und das Konto erfolgreich erstellt wurden, die Erstellung der Karte jedoch fehlschlägt, wechselt der Antrag nicht in den Status „erfolgreich“ und bleibt im Status „Karte nicht erstellt“. Zukünftig wird ein Hintergrundprozess diese Aufgabe übernehmen und abschließen. Das System befindet sich für eine gewisse Zeit in einem inkonsistenten Zustand, was für uns jedoch insgesamt akzeptabel ist.
Sollte dennoch eine Situation auftreten, in der wir einen Teil der Daten konsistent speichern müssen, werden wir wahrscheinlich einem Service-Zusammenfassung zustimmen, um dies in einem einzigen Prozess zu behandeln.
Betrachten wir das Beispiel der Herausbildung eines Mikrodienstes. Wie können wir ihn relativ sicher in die Produktion bringen? In diesem Beispiel haben wir einen separaten Teil des Systems — das Modul für die Lohnabrechnung, von dem wir einen Teil des Codes in einen Mikrodienst umwandeln möchten.
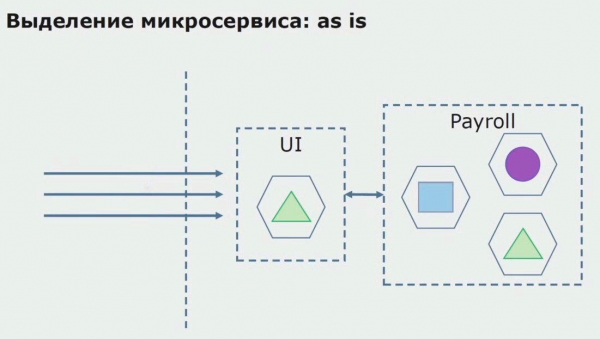
Zunächst erstellen wir einen Mikrodienst, indem wir den Code umschreiben. Wir verbessern bestimmte Aspekte, die uns nicht zufrieden stellten. Neue Geschäftsanfragen des Kunden werden umgesetzt. In die Verbindung zwischen UI und Backend fügen wir ein API Gateway ein, das die Durchleitung von Aufrufen sicherstellt.
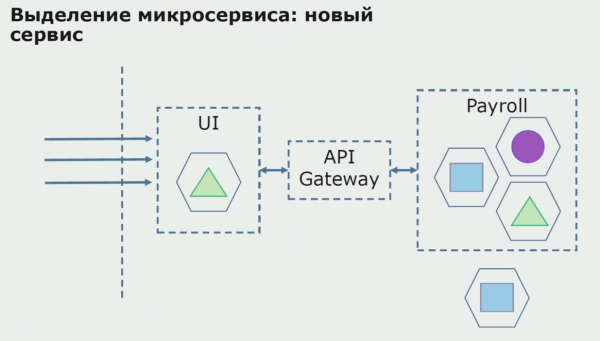
Anschließend setzen wir diese Konfiguration in Betrieb, jedoch im Pilotzustand. Die meisten Nutzer arbeiten weiterhin mit den alten Geschäftsprozessen. Für neue Nutzer entwickeln wir eine neue Version der monolithischen Anwendung, die diesen Prozess nicht mehr enthält. Im Grunde genommen funktioniert unsere Verbindung zwischen dem Monolithen und dem Mikrodienst im Pilotmodus.
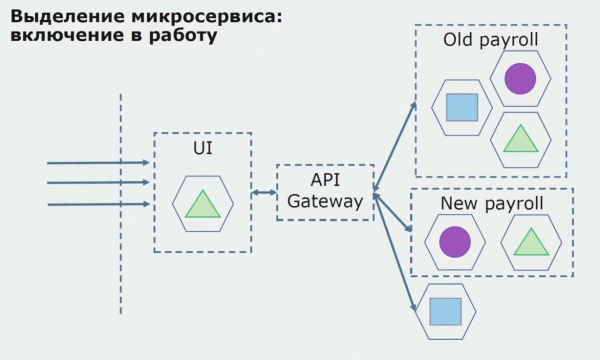
Bei einem erfolgreichen Pilotprojekt erkennen wir, dass die neue Konfiguration tatsächlich funktioniert. Wir können den alten Monolithen aus der Gleichung entfernen und die neue Konfiguration anstelle der alten Lösung beibehalten.
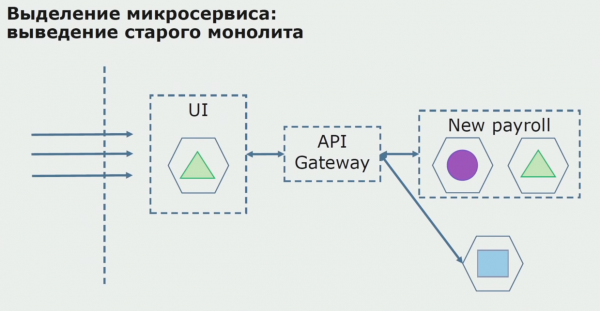
Insgesamt nutzen wir nahezu alle bestehenden Methoden zur Aufteilung des Quellcodes des Monolithen. Diese ermöglichen es uns, die Größe der App-Teile zu reduzieren und sie auf neue Bibliotheken zu migrieren, wodurch der Quellcode qualitativ hochwertiger wird.
Arbeiten mit der DB
Die Datenbank ist schwieriger zu partitionieren als der Quellcode, da sie nicht nur das aktuelle Schema enthält, sondern auch historische Daten, die sich angesammelt haben.
Unsere Datenbank hatte, wie viele andere, einen weiteren wichtigen Nachteil – ihre enorme Größe. Sie wurde gemäß der komplexen Geschäftslogik des Monolithen entworfen, und zwischen den Tabellen verschiedener begrenzter Kontexte sind viele Verbindungen entstanden.
In unserem Fall kam zu all den Schwierigkeiten (große Datenbank, zahlreiche Verbindungen, manchmal unklare Grenzen zwischen den Tabellen) das Problem, das in vielen großen Projekten vorkommt: die Verwendung des Shared-Database-Musters. Daten wurden über Views aus Tabellen abgerufen, teilweise repliziert und in andere Systeme geladen, wo diese Replikation benötigt wurde. Dadurch konnten wir die Tabellen nicht in ein separates Schema auslagern, da sie aktiv genutzt wurden.
Bei der Partitionierung hilft uns die zum Code passende Aufteilung in begrenzte Kontexte. Diese gibt uns in der Regel eine recht gute Vorstellung davon, wie wir die Daten auf Datenbankebene aufteilen. Wir verstehen, welche Tabellen zu einem begrenzten Kontext gehören und welche zu einem anderen.
Wir haben zwei globale Ansätze zur Datenbanktrennung angewendet: die Trennung bestehender Tabellen und die Trennung mit Umgestaltung.
Die Trennung bestehender Tabellen ist eine Methode, die gut anwendbar ist, wenn die Datenstruktur qualitativ hochwertig ist, den geschäftlichen Anforderungen entspricht und alle Beteiligten zufrieden sind. In diesem Fall können wir die bestehenden Tabellen in ein separates Schema auslagern.
Die Trennung mit Umgestaltung ist erforderlich, wenn sich das Geschäftsmodell erheblich verändert hat und die Tabellen uns nicht mehr zufriedenstellen.
Trennung bestehender Tabellen. Wir müssen festlegen, was wir trennen wollen. Ohne dieses Wissen wird es nicht funktionieren, und hier hilft uns die Trennung begrenzter Kontexte im Code. In der Regel wird klar, welche Tabellen in die Liste zur Trennung aufgenommen werden sollen, wenn wir die Grenzen der Kontexte im Quellcode verstehen.
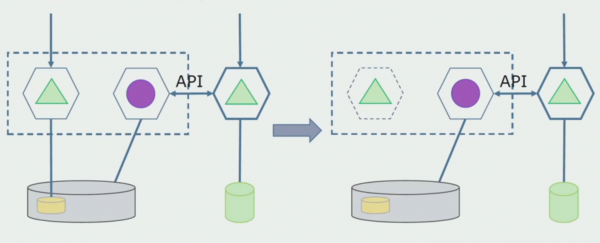
Stellen Sie sich vor, wir haben eine Lösung, bei der zwei Module des Monolithen mit einer einzigen Datenbank interagieren. Wir müssen sicherstellen, dass nur ein Modul mit den separierbaren Tabellen interagiert, während das andere über eine API damit kommuniziert. Für den Anfang reicht es, wenn nur Schreibzugriffe über die API erfolgen. Dies ist eine notwendige Bedingung, um von der Unabhängigkeit der Mikrodienste sprechen zu können. Leseverbindungen können bestehen bleiben, solange dies kein größeres Problem darstellt.
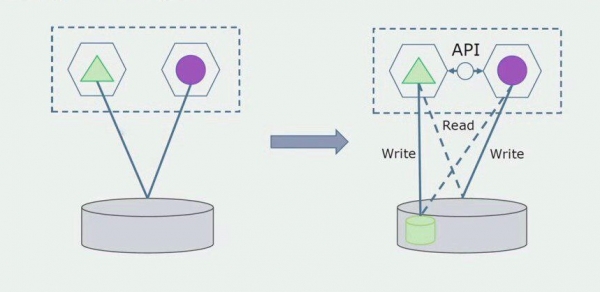
Im nächsten Schritt können wir den Codeabschnitt, der mit den separierbaren Tabellen arbeitet, mit oder ohne Überarbeitung in einen separaten Mikrodienst auslagern und ihn in einem eigenen Prozess oder Container ausführen. Dies wird ein separater Dienst sein, der eine Verbindung zur Datenbank des Monolithen und zu den Tabellen hat, die nicht direkt zu ihm gehören. Der Monolith greift weiterhin lesend auf den separierbaren Teil zu.
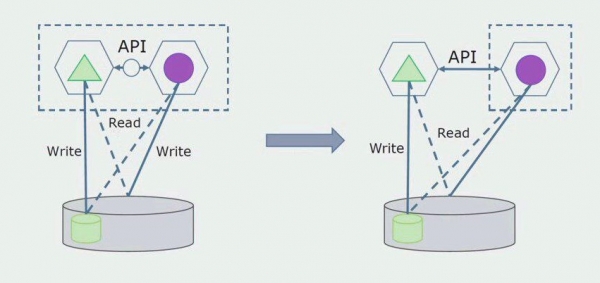
Später werden wir diese Verbindung entfernen, das heißt, auch die Lesezugriffe des monolithischen Anwendungs auf die separierbaren Tabellen werden auf die API umgestellt.
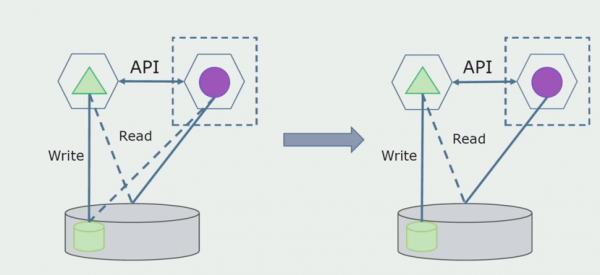
Als Nächstes isolieren wir aus der gesamten Datenbank die Tabellen, mit denen nur der neue Mikrodienst arbeitet. Wir können die Tabellen in ein separates Schema oder sogar in eine separate physische Datenbank auslagern. Es besteht eine Lesekommunikation zwischen dem Mikrodienst und der Datenbank des Monolithen, aber das ist nicht problematisch, in dieser Konfiguration kann er lange Zeit bestehen bleiben.
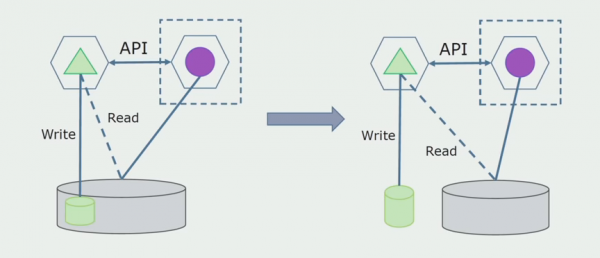
Der letzte Schritt besteht darin, alle Verbindungen vollständig zu entfernen. In diesem Fall benötigen wir möglicherweise einen Datenmigrationsprozess von der Hauptdatenbank. Manchmal möchten wir in mehreren Datenbanken replizierbare Daten oder Verzeichnisse aus externen Systemen wiederverwenden. Das kommt bei uns gelegentlich vor.
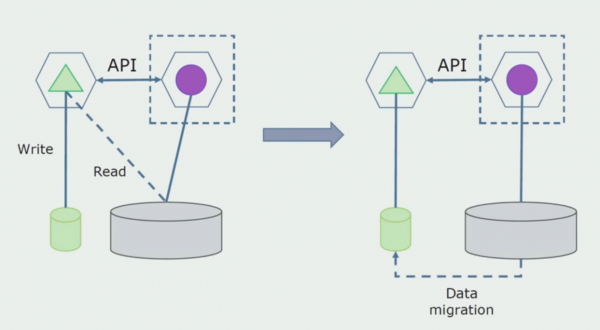
Abtrennung mit Umgestaltung. Diese Methode ähnelt der ersten, jedoch in umgekehrter Reihenfolge. Wir erstellen sofort eine neue Datenbank und einen neuen Mikrodienst, der über die API mit dem Monolithen interagiert. Dabei bleibt jedoch eine Reihe von Datenbanktabellen bestehen, die wir in Zukunft entfernen möchten. Diese werden nicht mehr benötigt, in dem neuen Modell haben wir sie ersetzt.
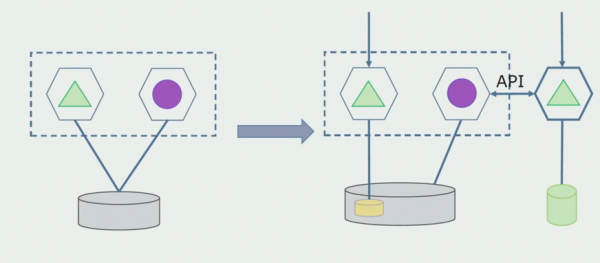
Damit dieses Schema funktioniert, benötigen wir wahrscheinlich einen Übergangszeitraum.
Es gibt zwei mögliche Ansätze.
Erster: Wir duplizieren alle Daten in der alten und neuen Datenbank. In diesem Fall entsteht Datenredundanz, was zu Synchronisierungsproblemen führen kann. Aber wir können zwei verschiedene Kunden bedienen. Einer arbeitet mit der neuen Version, der andere mit der alten.
Zweite: Wir teilen die Daten nach einem bestimmten Geschäftskriterium auf. Zum Beispiel hatten wir in unserem System 5 Produkte, die in der alten Datenbank gespeichert waren. Das sechste Produkt fügen wir im Rahmen einer neuen Geschäftsanforderung in die neue DB ein. Doch wir benötigen ein API-Gateway, das diese Daten synchronisiert und dem Kunden zeigt, woher und was er abrufen kann.
Beide Ansätze sind praktikabel, wählen Sie je nach Situation.
Sobald wir sicher sind, dass alles funktioniert, kann der Teil des Monolithen, der mit den alten DB-Strukturen arbeitet, abgeschaltet werden.
Der letzte Schritt wird die Löschung der alten Datenstrukturen sein.
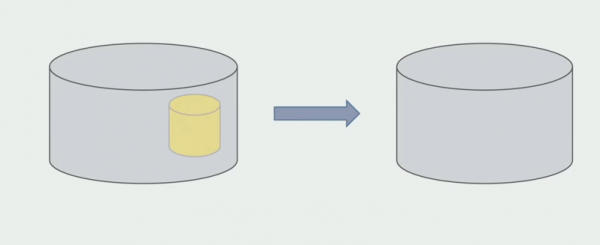
Zusammenfassend lässt sich sagen, dass wir Probleme mit der DB haben: Es ist schwieriger, damit zu arbeiten als mit dem Quellcode, das Trennen ist komplizierter, aber es ist möglich und notwendig. Wir haben einige Methoden gefunden, die es ermöglichen, dies relativ sicher zu tun, schließlich ist es einfacher, mit Daten einen Fehler zu machen als mit dem Quellcode.
Arbeiten mit Quellcode
So sah das Quellcode-Schema aus, als wir mit der Analyse des monolithischen Projekts begannen.
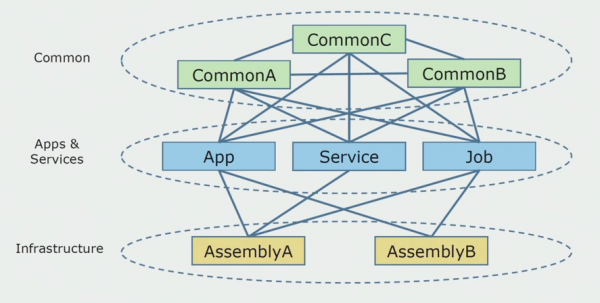
Es lässt sich grob in drei Schichten unterteilen. Dies ist die Schicht der ausführbaren Module, Plugins, Dienste und einzelner Aktivitäten. Tatsächlich waren dies die Einstiegspunkte innerhalb der monolithischen Lösung. Alle waren fest mit der Schicht Common verbunden. Darin befand sich die Geschäftslogik, die von den Diensten gemeinsam genutzt wurde, sowie zahlreiche Verbindungen. Jeder Dienst und jedes Plugin verwendete bis zu 10 und mehr Common-Bibliotheken, abhängig von ihrer Größe und dem Gewissen der Entwickler.
Wir hatten das Glück, Infrastruktur-Bibliotheken zu haben, die separat genutzt werden konnten.
Manchmal kam es vor, dass einige Common-Objekte eigentlich nicht zu dieser Schicht gehörten, sondern Infrastruktur-Bibliotheken waren. Dies wurde durch Umbenennung gelöst.
Die größte Besorgnis galt den begrenzten Kontexten. Es kam vor, dass 3-4 Kontexte in einer gemeinsamen Build-Version vermischt wurden und sich gegenseitig im Rahmen derselben Geschäftsfunktionen verwendeten. Es war notwendig zu verstehen, wo diese getrennt werden können und an welchen Grenzen, sowie was im Anschluss mit der Zuordnung dieser Trennung zu den Ursprungs-Code-Builds zu tun ist.
Wir haben mehrere Regeln für den Prozess der Code-Trennung formuliert.
Erstens: Wir wollten keine gemeinsame Nutzung der Geschäftslogik zwischen den Diensten, Aktivitäten und Plugins mehr. Unser Ziel war es, die Geschäftslogik innerhalb der Mikrodienste unabhängig zu gestalten. Idealerweise werden Mikrodienste als völlig eigenständige Services betrachtet. Ich halte diesen Ansatz jedoch für etwas verschwenderisch, da es auch schwierig ist, ihn zu erreichen. Beispielsweise werden Dienste, die in C# entwickelt werden, immer mit der Standardbibliothek verbunden sein. Unser System ist in C# geschrieben, andere Technologien mussten wir bisher nicht einsetzen. Daher haben wir entschieden, dass wir es uns leisten können, gemeinsame technische Assemblierungen zu nutzen. Wichtig ist nur, dass diese keinerlei Fragmente der Geschäftslogik enthalten. Wenn Sie ein nützliches Wrapper über das ORM haben, das Sie verwenden, ist es sehr kostspielig, dies von einem Dienst zum anderen zu kopieren.
Unser Team ist begeistert von objektorientiertem Design, daher passt die "Zwiebelarchitektur" perfekt zu uns. Die Grundlage unserer Dienste ist nicht die Datenauszugsschicht, sondern eine Sammlung mit der Domainlogik, die nur Geschäftslogik enthält und keine Bindungen zur Infrastruktur hat. Damit können wir die Domainzusammenstellung unabhängig weiterentwickeln, um Probleme im Zusammenhang mit Frameworks zu lösen.
In dieser Phase stießen wir auf das erste ernsthafte Problem. Der Dienst sollte sich auf ein domainübergreifendes Assembly beziehen, wobei wir die Logik unabhängig gestalten wollten, doch dabei stellte uns das DRY-Prinzip vor große Herausforderungen. Die Entwickler wollten zur Vermeidung von Duplikaten Klassen aus benachbarten Assemblies wiederverwenden, was dazu führte, dass die Domains erneut miteinander verknüpft wurden. Wir analysierten die Ergebnisse und kamen zu dem Schluss, dass das Problem möglicherweise auch im Bereich der Architektur des Quellcode-Repositorys lag. Wir hatten ein großes Repository, in dem sich alles Quellmaterial befand. Die Erstellung einer Solution für das gesamte Projekt war auf unserem lokalen Gerät äußerst kompliziert. Daher wurden für verschiedene Teile des Projekts separate, kleinere Solutions erstellt, und nichts sprach dagegen, dass man eine beliebige Common- oder Domain-Assembly hinzufügte und sie wiederverwendete. Das einzige Tool, das uns daran hinderte, war das Code-Review. Aber manchmal versagte auch dieses.
So haben wir begonnen, auf ein Modell mit separaten Repositories umzustellen. Die Geschäftslogik fließt nicht mehr von einem Service zum anderen, und die Domänen sind tatsächlich unabhängig geworden. Eingeschränkte Kontexte werden nun klarer unterstützt. Wie nutzen wir dabei die Infrastruktur-Bibliotheken erneut? Wir haben sie in ein separates Repository ausgegliedert, dann in Nuget-Pakete verpackt und in Artifactory abgelegt. Bei jeder Änderung erfolgt automatisch die Erstellung und Veröffentlichung.
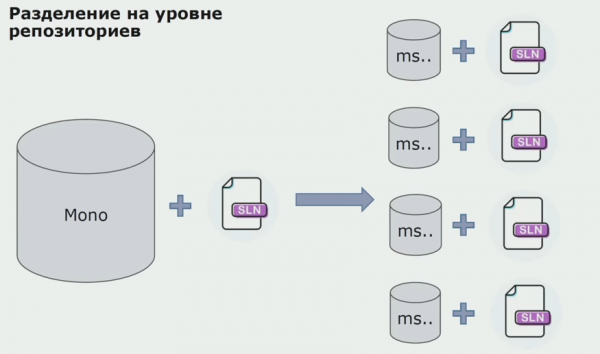
Unsere Services beziehen sich auf interne Infrastruktur-Pakete ebenso wie auf externe. Die externen Bibliotheken laden wir über Nuget herunter. Für die Arbeit mit Artifactory, wo wir diese Pakete abgelegt haben, haben wir zwei Paketmanager eingesetzt. In kleinen Repositories haben wir ebenfalls Nuget genutzt. In Repositories mit mehreren Services haben wir Paket verwendet, das eine größere Konsistenz der Versionen zwischen den Modulen gewährleistet.
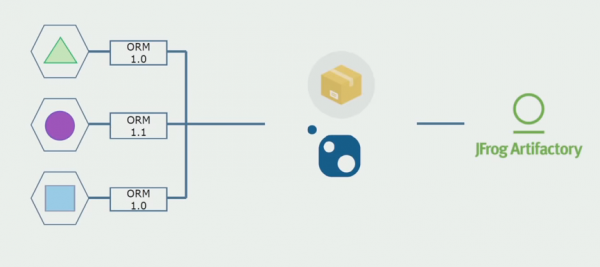
Durch die Arbeit am Quellcode haben wir, indem wir die Architektur etwas verändert und Repositories getrennt haben, unsere Services unabhängiger gemacht.
Infrastrukturprobleme
Die meisten Probleme beim Wechsel zu Microservices hängen mit der Infrastruktur zusammen. Sie benötigen automatisierte Bereitstellungen und neue Bibliotheken, um die Infrastruktur effizient zu betreiben.
Manuelle Installation in Umgebungen
Ursprünglich haben wir die Umgebungen manuell eingerichtet. Um diesen Prozess zu automatisieren, haben wir eine CI/CD-Pipeline eingerichtet. Wir haben uns für den kontinuierlichen Bereitstellungsprozess entschieden, da die kontinuierliche Bereitstellung für uns aus geschäftlichen Gründen momentan nicht akzeptabel ist. Daher erfolgt das Deployment per Knopfdruck, während die Tests automatisch ablaufen.
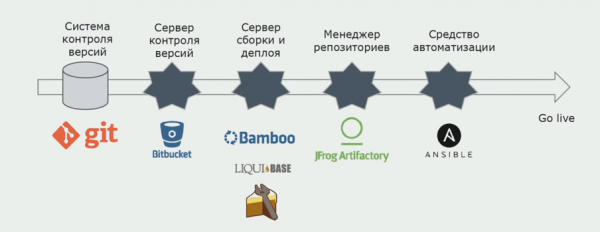
Wir nutzen Atlassian, Bitbucket zur Speicherung des Quellcodes und Bamboo für den Build-Prozess. Wir schreiben gerne Buildscripte in Cake, da es sich um dasselbe C# handelt. In Artifactory werden bereits fertige Pakete hinterlegt, und Ansible wird automatisch auf die Testserver übertragen, sodass diese sofort getestet werden können.
Getrennte Protokollierung
Eines der ursprünglichen Ziele des Monolithen war die gemeinsame Protokollierung. Wir mussten auch verstehen, wie wir mit den separaten Logs umgehen, die auf den Datenträgern liegen. Die Logs werden in Textdateien geschrieben. Wir haben uns entschieden, den Standard-ELK-Stack zu verwenden. Statt direkt über Provider in ELK zu schreiben, haben wir beschlossen, die Textlogs zu überarbeiten und die Trace-ID als Identifikator hinzuzufügen, indem wir den Servicenamen ergänzen, damit diese Logs später analysiert werden können.
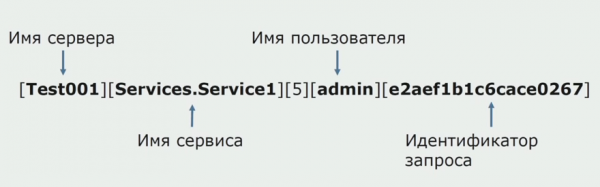
Mit Filebeat können wir unsere Logs von Serversammeln, sie dann transformieren, über Kibana Abfragen im UI erstellen und nachverfolgen, wie die Aufrufe zwischen den Services abliefen. Dabei hilft die Trace-ID erheblich.
Testen und Debuggen von verbundenen Diensten
Anfangs hatten wir nicht ganz verstanden, wie wir die entwickelten Dienste optimieren sollten. Bei einem Monolithen war alles einfach, wir konnten ihn auf einer lokalen Maschine starten. Zunächst haben wir auch mit Mikrodiensten versucht, dies zu tun, aber manchmal erfordert der vollständige Start eines Mikrodienstes, dass auch mehrere andere gestartet werden, was unpraktisch ist. Wir haben erkannt, dass wir zu einem Modell übergehen müssen, bei dem wir nur den Dienst oder die Dienste auf der lokalen Maschine lassen, die wir debuggen möchten. Die anderen Dienste laufen von Servern, die in der Konfiguration mit der Produktionsumgebung übereinstimmen. Nach dem Debugging werden bei jedem Test auf dem Testserver nur die geänderten Dienste bereitgestellt. So wird die Lösung in der Form getestet, in der sie später in der Produktion verfügbar sein wird.
Es gibt Server, auf denen nur die Produktionsversionen der Dienste installiert sind. Diese Server sind nötig für den Fall von Vorfällen, zur Überprüfung der Bereitstellung vor dem Deployment und für interne Schulungen.
Wir haben einen automatisierten Testprozess mit der beliebten SpecFlow-Bibliothek eingeführt. Die Tests werden direkt nach dem Deployment über Ansible automatisch mit NUnit ausgeführt. Wenn die Aufgaben vollständig automatisiert sind, ist kein manuelles Testen erforderlich. Manchmal ist jedoch zusätzliches manuelles Testen notwendig. Um zu bestimmen, welche Tests für eine bestimmte Aufgabe ausgeführt werden sollen, verwenden wir Tags in Jira.
Zudem ist der Bedarf an Lasttests gestiegen; zuvor wurden diese nur in seltenen Fällen durchgeführt. Für die Ausführung der Tests nutzen wir JMeter, zur Speicherung verwenden wir InfluxDB, und für die grafische Darstellung des Prozesses kommt Grafana zum Einsatz.
Was haben wir erreicht?
Erstens haben wir das Konzept des „Release“ abgeschafft. Die monatelangen großen Releases, bei denen dieses Monstrum in der Produktionsumgebung ausgerollt wurde und zeitweise die Geschäftsprozesse lahmlegte, gehören der Vergangenheit an. Jetzt führen wir durchschnittlich alle 1,5 Tage Deployments durch, gruppieren diese, da sie nach Abstimmung in Betrieb genommen werden.
In unserem System gibt es keine kritischen Fehler. Wenn wir einen Microservice mit einem Fehler bereitstellen, wird die damit verbundene Funktionalität beeinträchtigt, während alle anderen Funktionen unberührt bleiben. Das verbessert die Benutzererfahrung erheblich.
Wir können das Bereitstellungsschema steuern. Es ist möglich, Gruppen von Services von der restlichen Lösung zu trennen, wenn dies erforderlich ist.
Darüber hinaus haben wir das Problem mit langen Warteschlangen bei Anpassungen erheblich verringert. Wir haben separate Produktteams eingerichtet, die unabhängig an bestimmten Services arbeiten. Hier eignet sich der Scrum-Prozess gut. Ein bestimmtes Team kann einen eigenen Produktinhaber haben, der Aufgaben für das Team festlegt.
Zusammenfassung
- Microservices sind gut geeignet, um komplexe Systeme zu dekomponieren. Im Prozess beginnen wir zu verstehen, was in unserem System vorhanden ist, welche eingeschränkten Kontexte bestehen und wo deren Grenzen liegen. Dies ermöglicht es, Anpassungen korrekt auf die Module zu verteilen und Verwirrung im Code zu vermeiden.
- Mikroservices bieten organisatorische Vorteile. Oft wird nur über sie als Architektur gesprochen, jedoch dient jede Architektur dem Zweck, die Geschäftsbedürfnisse zu erfüllen, und nicht nur ihrer eigenen Existenz willen. Daher können wir sagen, dass Mikroservices besonders geeignet sind, um Aufgaben in kleinen Teams zu bewältigen, insbesondere da Scrum derzeit sehr beliebt ist.
- Die Aufteilung ist ein iterativer Prozess. Man kann eine Anwendung nicht einfach in Mikroservices teilen. Das resultierende Produkt wird wahrscheinlich nicht funktionsfähig sein. Bei der Herausbildung von Mikroservices ist es ratsam, bestehende Legacy-Systeme zu überarbeiten, um sie in einen Code umzuwandeln, der unseren Anforderungen bezüglich Funktionalität und Geschwindigkeit besser entspricht.
Eine kleine Warnung: Die Kosten für den Übergang zu Mikrodiensten sind beträchtlich. Allein die Lösung von Infrastrukturproblemen hat viel Zeit in Anspruch genommen. Daher, wenn Sie eine kleine Anwendung haben, die kein spezifisches Skalierung erfordert, und wenn es nicht viele Kunden gibt, die um die Aufmerksamkeit und Zeit Ihres Teams kämpfen, dann sind Mikrodienste möglicherweise nicht das, was Sie heute brauchen. Es ist durchaus kostspielig. Wenn Sie mit Mikrodiensten beginnen, werden die Anfangskosten höher sein, als wenn dasselbe Projekt als Monolith entwickelt wird.
P.S. Eine emotionalere Erzählung (als ob sie persönlich für Sie wäre) - zu .
Hier ist die vollständige Version des Berichts.
Quelle: habr.com
