

Kürzlich berichtete ich darüber, wie man mit Standardrezepten aus einer PostgreSQL-Datenbank steigern kann. Heute geht es darum, wie man die Datenspeicherung in der DB effektiver gestalten kann, ohne irgendwelche „Schrauben“ in der Konfiguration zu verwenden – einfach durch eine ordnungsgemäße Organisation der Datenströme.

#1. Секционирование
Der Artikel behandelt, wie und warum es sinnvoll ist, zu organisieren und hier wird es um die praktische Anwendung einiger Ansätze in unserem .
„Long time ago…“
Ursprünglich, wie bei jedem MVP, startete unser Projekt mit einer relativ geringen Last – das Monitoring erfolgte nur für ein Dutzend der kritischsten Server, alle Tabellen waren relativ kompakt… Doch die Zeit verging, die überwachten Hosts wurden immer zahlreicher, und als wir erneut versuchten, etwas mit einer der Tabellen mit einer Größe von 1,5 TB, zu machen, erkannten wir, dass es zwar möglich war, so weiterzuleben, aber es war äußerst unpraktisch.
Die Zeiten waren fast schon legendär, unterschiedliche Versionen von PostgreSQL 9.x waren aktuell, und daher musste die gesamte Partitionierung „manuell“ vorgenommen werden – durch Tabellenvererbung und Trigger Routing mit dynamischem EXECUTE.
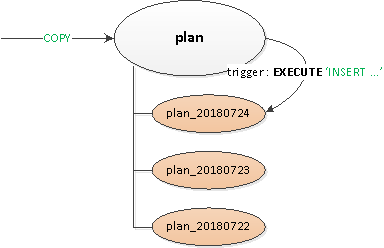
Die entstandene Lösung erwies sich als ausreichend universell, um sie auf alle Tabellen anwenden zu können:
- Eine leere „Header“-Elterntabelle wurde definiert, in der alle erforderlichen Indizes und Trigger beschrieben wurden.
- Die Datensätze wurden aus Sicht des Clients in die „Root“-Tabelle geschrieben, und innerhalb dieser durch den Routing-Trigger
BEFORE INSERTwurde der Datensatz „physisch“ in den erforderlichen Abschnitt eingefügt. Sollte dieser noch nicht existieren – fingen wir die Ausnahme und … - … mit Hilfe von wurde entsprechend der Vorlage der Elterntabelle ein Abschnitt mit einer Einschränkung auf das erforderliche Datum erstellt, damit bei der Datenauslesung nur darin gelesen wird.
PG10: Der erste Versuch
Aber die Partitionierung über Vererbung war historisch gesehen nicht besonders gut geeignet für aktive Schreibströme oder eine große Anzahl an Nachkommen-Partitionen. Man kann sich erinnern, dass der Algorithmus zur Auswahl des benötigten Abschnitts quadratische Komplexität, sodass bei 100+ Abschnitten, Sie wissen schon, wie das funktioniert…
In PG10 wurde diese Situation stark optimiert, indem die Unterstützung für . Daher haben wir es sofort nach der Migration des Speichers ausprobiert, aber…
Wie sich nach eingehender Durchsicht des Handbuchs herausstellte, unterstützt die nativ partitionierte Tabelle in dieser Version:
- keine Indexbeschreibungen
- keine Trigger
- kann nicht selbst ein Nachkomme sein
- unterstützt nicht
INSERT ... ON CONFLICT - kann keine Sektion automatisch erzeugen
Nach dem schmerzhaften Schock haben wir verstanden, dass wir ohne Modifikation der Anwendung nicht auskommen werden und haben die weiteren Untersuchungen um ein halbes Jahr verschoben.
PG10: eine zweite Chance
Also begannen wir, die aufgetretenen Probleme nacheinander zu lösen:
- Da Trigger und
ON CONFLICTuns doch an einigen Stellen benötigt wurden, haben wir dafür eine Zwischen- Proxy-Tabelle erstellt. - Wir haben das "Routing" in den Triggern entfernt — also
EXECUTE. - Wir haben separat eine Vorlage-Tabelle mit allen Indizes erstellt, damit sie nicht einmal in der Proxy-Tabelle vorhanden sind.
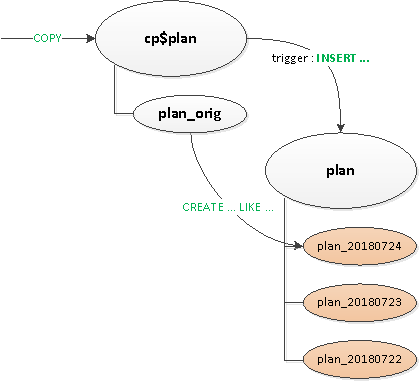
Schließlich haben wir nach all dem die Haupttabelle nativ partitioniert. Die Erstellung eines neuen Abschnitts verblieb bis dahin in der Verantwortung der Anwendung.
"Wir bearbeiten" Wörterbücher
Wie in jedem analytischen System hatten wir auch bei uns "Fakten" und "Schnitte" (Wörterbücher). In unserem Fall waren dies beispielsweise homogener langsamer Abfragen oder der Abfrage selbst.
Die «Fakten» waren bei uns bereits seit langem nach Tagen segmentiert, weshalb wir ruhig veraltete Abschnitte entfernen konnten, und sie haben uns nicht gestört (die Protokolle eben!). Mit den Wörterbüchern jedoch gab es Probleme…
Es kann nicht gesagt werden, dass es sehr viele waren, aber etwa für 100TB «Fakten» gab es ein Wörterbuch von 2,5TB.Aus so einer Tabelle lässt sich nichts einfach entfernen, nicht einpacken in angemessener Zeit, und das Schreiben wurde allmählich immer langsamer.
Es scheint ein Wörterbuch zu sein… In ihm sollte jeder Eintrag genau einmal vorhanden sein… und das ist korrekt, aber!.. Nichts hindert uns daran, ein separates Wörterbuch für jeden Tag! Ja, das bringt einen gewissen Überfluss, aber es ermöglicht:
- schnelleres Schreiben/Lesen wegen der kleineren Abschnittsgröße
- weniger Speicher zu verbrauchen durch die Arbeit mit kompakteren Indizes
- weniger Daten zu speichern durch die Möglichkeit, veraltete schnell zu entfernen.
Infolge des gesamten Maßnahmenpakets sank die CPU-Auslastung um ~30%, die Festplattenauslastung um ~50%.:
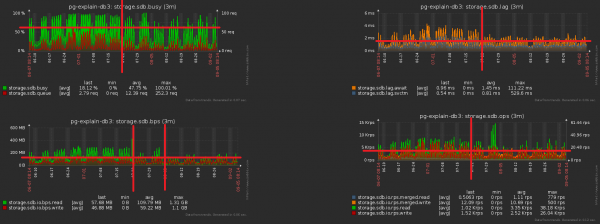
Dabei haben wir weiterhin genau dieselben Daten in die Datenbank geschrieben, jedoch mit einer geringeren Belastung.
#2. Эволюция и рефакторинг БД
Also, wir sind zu dem Punkt gekommen, dass wir für jeden Tag einen eigenen Abschnitt mit Daten haben. Tatsächlich CHECK (dt = '2018-10-12'::date) — das ist der Schlüssel zur Partitionierung und die Bedingung, dass ein Datensatz in den bestimmten Abschnitt fällt.
Da alle Berichte in unserem Dienst auf spezifischen Daten beruhen, waren die Indizes aus den "nicht partitionierten Zeiten" auch alle vom Typ (Server, Datum, Planvorlage), (Server, Datum, Knoten des Plans), (Datum, Fehlerklasse, Server),…
Aber jetzt wohnen in jedem Abschnitt eigenständige Instanzen jeder dieser Indizes… Und innerhalb jedes Abschnitts ist das Datum eine Konstante… Das bedeutet, dass wir jetzt in jeden solchen Index einfach eine Konstante als eines der Felder eintragen, was sowohl das Volumen als auch die Suchzeit erhöht, jedoch keinen Nutzen bringt. Wir haben uns selbst Fallstricke hinterlassen, ups…

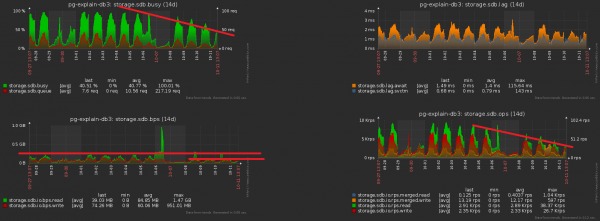
Die Richtung der Optimierung ist offensichtlich — einfach das Datumsfeld aus allen Indizes in den partitionierten Tabellen entfernen. Bei unseren Volumina ergibt sich ein Gewinn von etwa 1TB/Woche!
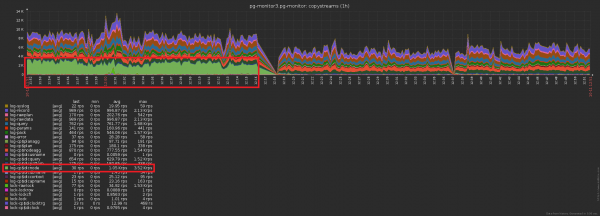
Und jetzt lassen Sie uns beachten, dass dieses Terabyte auch irgendwie aufgezeichnet werden musste. Das heißt, wir mussten auch Die Festplatte sollte jetzt weniger belastet werden.! Auf diesem Bild ist der erhaltene Effekt der durchgeführten Reinigung gut sichtbar, der eine Woche in Anspruch nahm:
#3. «Размазываем» пиковую нагрузку
Eine der größten Herausforderungen für belastete Systeme ist übermäßige Synchronisation von Operationen, die dies nicht erfordern. Manchmal „weil wir es nicht bemerkt haben“, manchmal „weil es einfacher war“, aber irgendwann müssen wir uns davon befreien.
Wenn wir das vorherige Bild vergrößern, sehen wir, dass die Festplatte in der Last mit doppelter Amplitude „schwankt“ zwischen benachbarten Messpunkten, was statistisch nicht der Fall sein sollte bei dieser Anzahl von Operationen:
Das zu erreichen ist recht einfach. Wir hatten bereits fast 1000 Server, jeder wird von einem separaten logischen Prozess verarbeitet, und jeder Prozess sendet die gesammelten Informationen zu bestimmten Zeitintervallen an die Datenbank, etwa so:
setInterval(sendToDB, interval)Das Problem liegt genau darin, dass alle Prozesse ungefähr zur gleichen Zeit starten, deshalb stimmen die Übermittlungszeitpunkte fast immer „über Punkt“ überein. Ups Nr. 2…
Zum Glück lässt sich das relativ einfach beheben, indem man eine „zufällige“ Zeitversetzung hinzufügt:
setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))#4. Кэшируем, что нужно можно
Das dritte traditionelle Hochlastproblem ist das Fehlen von Cache an Orten, wo er einfügen könnte benötigt wird.
Zum Beispiel haben wir die Möglichkeit zur Analyse im Hinblick auf die Knoten im Plan geschaffen (alle diese Seq Scan on users), aber man sollte sofort denken, dass sie in der Masse gleich sind – das wurde übersehen.
Natürlich wird nichts erneut in die Datenbank geschrieben, das wird durch den Trigger mit INSERT ... ON CONFLICT DO NOTHINGverhindert. Aber die Daten erreichen die Datenbank dennoch, was zusätzliches Lesen zur Überprüfung von Konflikten notwendig macht. Ups Nr. 3…
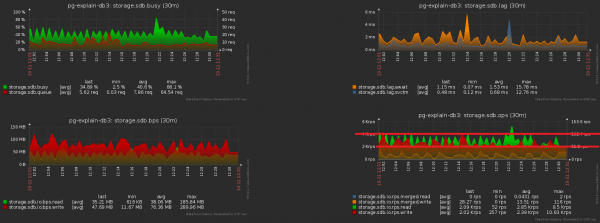
Der Unterschied in der Anzahl der in die Datenbank gesendeten Datensätze vor/nach der Aktivierung des Cachings ist offensichtlich:
Und das ist der begleitende Rückgang der Belastung des Speichers:
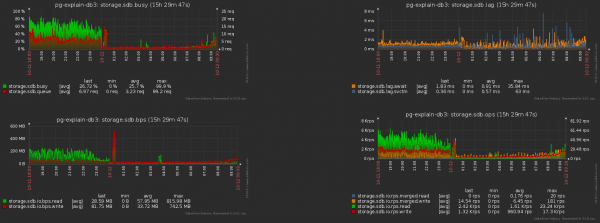
Gesamt
„Terabyte-pro-Tag“ klingt nur erschreckend. Wenn Sie alles richtig machen, sind das lediglich 2^40 Byte / 86400 Sekunden = ~12,5 MB/s, was selbst Desktop-IDE-Festplatten verkraften konnten. 🙂
Und ehrlich gesagt, selbst bei einer zehnfachen „Verzerrung“ der Last über einen Tag können Sie problemlos die Kapazitäten moderner SSDs ausschöpfen.

Quelle: habr.com
