

Hallo zusammen! Ich bin Backend-Entwickler und schreibe Microservices mit Java + Spring. Ich arbeite in einem der Teams, die interne Produkte bei Tinkoff entwickeln.

In unserem Team taucht häufig die Frage der Optimierung von Datenbankabfragen auf. Wir möchten immer noch ein bisschen schneller sein, aber es reicht nicht immer aus, durchdachte Indizes zu haben – manchmal müssen wir nach alternativen Lösungen suchen. Während ich eines dieser Streifzüge im Internet nach sinnvollen Optimierungen bei der Arbeit mit Datenbanken unternahm, fand ich , dem Autor des Buches SQL Performance Explained. Das ist eine der seltenen Arten von Blogs, in denen man alle Artikel hintereinander lesen kann.
Ich möchte eine kleine Artikelübersetzung von Markus für Sie anfertigen. Man kann sie in gewisser Weise als Manifest betrachten, das die Aufmerksamkeit auf ein altes, aber nach wie vor aktuelles Problem der Leistung der OFFSET-Operation gemäß dem SQL-Standard lenkt.
An einigen Stellen werde ich den Autor mit Erklärungen und Kommentaren ergänzen. Alle solche Stellen werde ich als „Anm.“ zur besseren Klarheit kennzeichnen.
Eine kurze Einführung
Ich denke, viele wissen, wie problematisch und langsam die Verwendung von paginierten Selektionsanfragen mit Offset sein kann. Aber wissen Sie, dass man dies recht einfach durch eine leistungsfähigere Struktur ersetzen kann?
Das Schlüsselwort Offset gibt der Datenbank an, die ersten n Datensätze im Query zu überspringen. Dennoch muss die Datenbank diese ersten n Datensätze immer noch in der angegebenen Reihenfolge (Hinweis: Sortierung anwenden, wenn angegeben) vom Speicher lesen, bevor sie die Datensätze ab dem n+1 zurückgeben kann. Am spannendsten ist, dass das Problem nicht in der spezifischen Implementierung der DBMS liegt, sondern in der ursprünglichen Definition im Standard:
…die Zeilen werden zuerst gemäß der sortiert und anschließend begrenzt, indem die Anzahl der in der angegebenen Zeilen vom Anfang verworfen wird…
-SQL:2016, Teil 2, 4.15.3 Abgeleitete Tabellen (Hinweis: derzeit der am häufigsten verwendete Standard)
Ein wichtiger Punkt hier ist, dass Offset einen einzigen Parameter akzeptiert - die Anzahl der Datensätze, die übersprungen werden sollen, und das war's. Laut dieser Definition kann das DBMS nur alle Datensätze abrufen und dann die unnötigen verwerfen. Offensichtlich zwingt diese Definition von Offset zu überflüssiger Arbeit. Dabei spielt es keine Rolle, ob es sich um SQL oder NoSQL handelt.
Noch ein wenig Schmerz
Die Probleme mit dem Offset enden hier nicht, und das sind die Gründe dafür. Wenn zwischen dem Lesen von zwei Datenseiten eine andere Operation einen neuen Eintrag hinzufügt, was passiert dann?
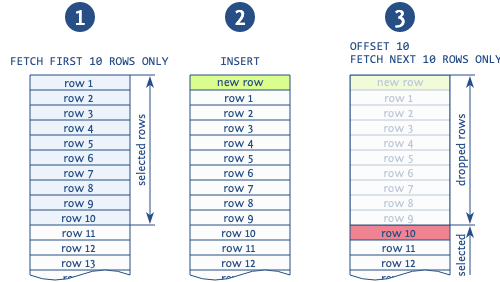
Wenn der Offset verwendet wird, um Einträge von vorherigen Seiten zu überspringen, wird in der Situation, in der ein neuer Eintrag zwischen den Leseoperationen verschiedener Seiten hinzugefügt wird, höchstwahrscheinlich ein Duplikat zurückgegeben (Anmerkung: Dies ist möglich, wenn wir seitenweise mit einer 'order by'-Klausel lesen, sodass ein neuer Eintrag in unsere Ergebnisse hineinfällt).
Das Bild veranschaulicht eine solche Situation. Die Datenbank liest die ersten 10 Einträge, anschließend wird ein neuer Eintrag hinzugefügt, der alle gelesenen Einträge um 1 verschiebt. Dann nimmt die Datenbank die neue Seite mit den nächsten 10 Einträgen und beginnt nicht mit dem 11. Eintrag, wie es sein sollte, sondern mit dem 10. und dupliziert diesen Eintrag. Es gibt auch andere Anomalien, die mit der Verwendung dieses Ausdrucks verbunden sind, aber diese ist die häufigste.
Wie bereits festgestellt, liegt das Problem nicht an einer bestimmten Datenbank oder deren Implementierungen. Das Problem besteht darin, wie die Pagination gemäß dem SQL-Standard definiert ist. Wir teilen der Datenbank mit, welche Seite abgerufen werden soll oder wie viele Datensätze übersprungen werden müssen. Die Datenbank ist einfach nicht in der Lage, eine solche Abfrage zu optimieren, da die dafür erforderlichen Informationen zu gering sind.
Es ist auch wichtig zu klären, dass dies kein spezifisches Schlüsselwort-Problem ist, sondern eher eine semantische Anfrage-Thematik. Es gibt noch mehrere identische syntaktische Probleme:
- Das Schlüsselwort OFFSET, wie bereits erwähnt.
- Die Konstruktion bestehend aus den beiden Schlüsselwörtern LIMIT [OFFSET] (obwohl LIMIT an sich nicht so schlecht ist).
- Die Filterung basierend auf unteren Grenzen, die auf der Zeilennummerierung aufbaut (zum Beispiel row_number(), rownum usw.).
All diese Ausdrücke geben lediglich an, wie viele Zeilen übersprungen werden müssen, ohne zusätzliche Informationen oder Kontext.
Im weiteren Verlauf dieses Artikels wird das Schlüsselwort OFFSET als Sammelbegriff für all diese Varianten verwendet.
Leben ohne OFFSET
Stellen Sie sich vor, wie unsere Welt ohne all diese Probleme wäre. Es stellt sich heraus, dass das Leben ohne Offset gar nicht so kompliziert ist: Mit einem Select können wir nur die Zeilen auswählen, die wir noch nicht gesehen haben (d.h. die, die auf der vorherigen Seite nicht da waren), indem wir eine Bedingung in der Where-Klausel verwenden.
In diesem Fall gehen wir davon aus, dass Selects über eine geordnete Menge ausgeführt werden (das altbewährte Order By). Da wir eine geordnete Menge haben, können wir einen ziemlich einfachen Filter verwenden, um nur die Daten abzurufen, die hinter dem letzten Eintrag der vorherigen Seite liegen:
SELECT ...
FROM ...
WHERE ...
AND id < ?last_seen_id
ORDER BY id DESC
FETCH FIRST 10 ROWS ONLYUnd das ist das Prinzip dieses Ansatzes. Natürlich wird es bei der Sortierung nach mehreren Spalten spannender, aber die Idee bleibt dieselbe. Es ist wichtig zu bemerken, dass diese Konstruktion in vielen -Lösungen anwendbar ist.
Dieser Ansatz wird als Seek-Methode oder Keyset-Pagination bezeichnet. Er löst das Problem mit schwebenden Ergebnissen (Anmerkung: die Situation mit Datensätzen zwischen dem Lesen von Seiten, wie zuvor beschrieben) und, was wir alle mögen, funktioniert schneller und stabiler als die klassische Offset-Pagination. Die Stabilität liegt darin, dass die Verarbeitungszeit der Anfrage nicht proportional zur Nummer der angeforderten Tabelle steigt (Anmerkung: Wenn Sie mehr über die verschiedenen Ansätze zur Pagination erfahren möchten, können Sie . Dort finden Sie auch vergleichende Benchmarks zu verschiedenen Methoden).
Eine der Folien , dass die Schlüssel-Pagination natürlich nicht allmächtig ist – sie hat ihre eigenen Grenzen. Die bedeutendste ist, dass man keine zufälligen Seiten lesen kann (Anm.: nicht sequenziell). In der Ära des unendlichen Scrollens (Anm.: im Frontend) ist dies jedoch nicht so problematisch. Die Angabe einer Seitenzahl zum Klicken ist ohnehin eine schlechte Lösung bei der UI-Entwicklung (Anm.: Meinung des Autors des Artikels).
Und wie sieht es mit den Werkzeugen aus?
Die Paginierung über Schlüssel ist oft unzureichend, da es an instrumenteller Unterstützung für diese Methode fehlt. Die meisten Entwicklungstools, einschließlich verschiedener Frameworks, geben nicht an, auf welche Weise die Paginierung durchgeführt werden soll.
Die Situation wird dadurch erschwert, dass die beschriebene Methode durchgängige Unterstützung in den verwendeten Technologien erfordert — beginnend bei der Datenbank und endend mit der Ausführung von AJAX-Anfragen im Browser beim unendlichen Scrollen. Statt nur die Seitenzahl anzugeben, muss nun ein Satz von Schlüsseln für alle Seiten gleichzeitig angegeben werden.
Die Anzahl der Frameworks, die die Schlüssel-Paginierung unterstützen, wächst jedoch allmählich. Hier sind die aktuellen Optionen:
- für Java;
- für Ruby;
- und für Django;
- für Python;
- — Kriterien-API für JPA-Implementierungen;
- für Perl;
- , мапер для Node.js .
(Hinweis: Einige Links wurden entfernt, da einige Bibliotheken zum Zeitpunkt der Übersetzung seit 2017-2018 nicht aktualisiert wurden. Bei Interesse kann der ursprüngliche Link besucht werden.)
Genau hier brauchen wir Ihre Unterstützung. Wenn Sie ein Framework entwickeln oder unterstützen, das Pagination in irgendeiner Form verwendet, bitte ich Sie, ich fordere Sie auf, ich bitte Sie inständig, native Unterstützung für Pagination über Schlüssel zu implementieren. Wenn Sie Fragen haben oder Hilfe benötigen, stehe ich gerne zur Verfügung (, , ) (Anmerkung: Nach meiner Erfahrung mit Markus kann ich sagen, dass er wirklich enthusiastisch an der Verbreitung dieses Themas interessiert ist).
Wenn Sie jedoch fertige Lösungen nutzen, die Ihrer Meinung nach Unterstützung für Schlüssel-Pagination verdienen, erstellen Sie bitte einen Request oder schlagen Sie sogar eine fertige Lösung vor, wenn das möglich ist. Sie können auch diesen Artikel in den Link einfügen.
Fazit
Der Grund, warum ein so einfacher und nützlicher Ansatz wie die Schlüssel-Pagination wenig verbreitet ist, liegt nicht daran, dass er technisch kompliziert wäre oder große Anstrengungen erfordert. Der Hauptgrund ist, dass viele daran gewöhnt sind, mit Offsets zu arbeiten – dieser Ansatz wird durch den Standard selbst diktiert.
Daher denken nur wenige über einen Wechsel in der Pagination nach, was dazu führt, dass die Unterstützung durch Frameworks und Bibliotheken nur langsam vorankommt. Wenn Ihnen die Idee und das Ziel einer offsetfreien Pagination am Herzen liegen, unterstützen Sie bitte deren Verbreitung!
Quelle:
Autor: Markus Winand
Quelle: habr.com
