


Das Problem des Bloat von Tabellen und Indizes ist weit verbreitet und betrifft nicht nur Postgres. Es gibt integrierte Möglichkeiten, damit umzugehen, wie VACUUM FULL oder CLUSTER, allerdings blockieren diese die Tabellen während des Betriebs und können daher nicht immer verwendet werden.
In diesem Artikel wird ein wenig Theorie darüber behandelt, wie Bloat entsteht, wie man damit umgehen kann, über deferierte Constraints und über die Probleme, die sie bei der Nutzung der Erweiterung pg_repack mit sich bringen.
Dieser Artikel basiert auf auf der PgConf.Russia 2020.
Warum entsteht Bloat?
Postgres basiert auf einem mehrversionellen Modell (). Das Grundprinzip besteht darin, dass jede Zeile in einer Tabelle mehrere Versionen haben kann, wobei Transaktionen nicht mehr als eine dieser Versionen sehen, jedoch nicht unbedingt dieselbe. Dies ermöglicht mehreren Transaktionen gleichzeitig zu arbeiten, ohne sich gegenseitig zu beeinträchtigen.
Es ist offensichtlich, dass all diese Versionen gespeichert werden müssen. Postgres arbeitet speicherseitig seitenweise, und eine Seite ist das kleinste Datenvolumen, das vom Speicher gelesen oder geschrieben werden kann. Lassen Sie uns ein kleines Beispiel betrachten, um zu verstehen, wie das geschieht.
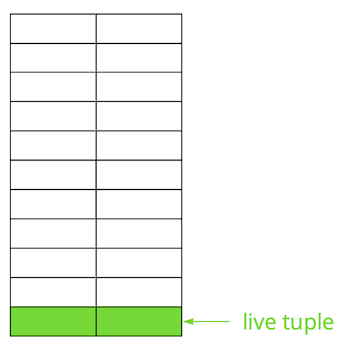
Angenommen, wir haben eine Tabelle, in die wir mehrere Datensätze hinzugefügt haben. Auf der ersten Seite der Datei, in der die Tabelle gespeichert ist, sind neue Daten aufgetaucht. Dies sind die Live-Versionen der Zeilen, die anderen Transaktionen nach dem Commit verfügbar sind (vereinfachend nehmen wir an, dass das Isolationsniveau Read Committed ist).
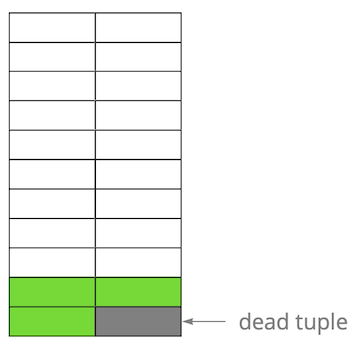
Anschließend haben wir einen der Datensätze aktualisiert und damit die alte Version als nicht mehr aktuell markiert.
Schritt für Schritt, während wir Zeilenversionen aktualisieren und löschen, erhalten wir eine Seite, auf der etwa die Hälfte der Daten „Müll“ sind. Diese Daten sind für keine Transaktion sichtbar.
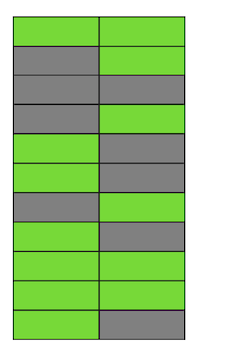
In Postgres gibt es einen Mechanismus , der nicht mehr aktuelle Versionen bereinigt und Platz für neue Daten schafft. Wenn er jedoch nicht aggressiv genug konfiguriert ist oder mit der Arbeit in anderen Tabellen beschäftigt ist, bleiben die „Mülldaten“ bestehen, und wir müssen zusätzliche Seiten für neue Daten verwenden.
So wird unsere Tabelle in unserem Beispiel zu einem bestimmten Zeitpunkt aus vier Seiten bestehen, aber nur die Hälfte davon sind aktive Daten. In der Folge werden wir beim Zugriff auf die Tabelle viel mehr Daten lesen, als tatsächlich erforderlich sind.
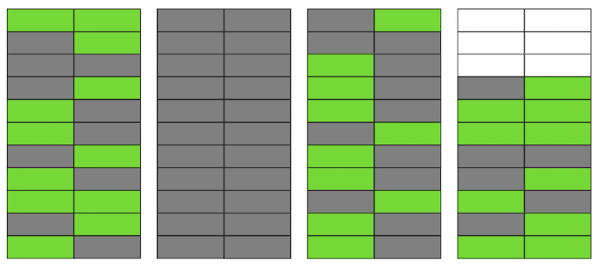
Selbst wenn VACUUM jetzt alle veralteten Zeilenversionen entfernt, wird sich die Situation nicht grundlegend verbessern. Wir erhalten zwar freien Platz auf den Seiten oder sogar ganze Seiten für neue Zeilen, aber wir müssen weiterhin mehr Daten ablesen, als nötig ist.
Übrigens, wenn eine vollständig leere Seite (die zweite in unserem Beispiel) am Ende der Datei wäre, könnte VACUUM sie kürzen. Aber da sie sich derzeit in der Mitte befindet, kann nichts damit gemacht werden.
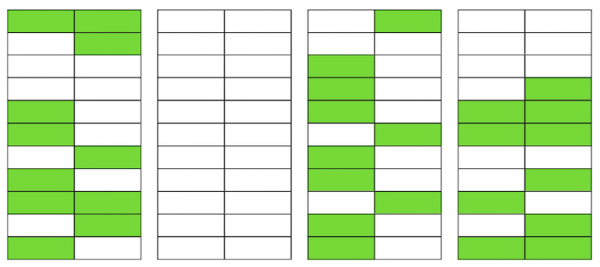
Wenn die Anzahl solcher leeren oder stark fragmentierten Seiten zu groß wird, was als Bloat bezeichnet wird, wirkt sich das negativ auf die Leistung aus.
Die oben beschriebene Mechanik führt zu Bloat in Tabellen. In Indizes passiert dies ähnlich.
Habe ich Bloat?
Es gibt mehrere Möglichkeiten, um festzustellen, ob Sie Bloat haben. Die Idee des ersten Ansatzes ist die Nutzung der internen Statistik von Postgres, die ungefähre Informationen über die Anzahl der Zeilen in den Tabellen, die Anzahl der "lebenden" Zeilen usw. enthält. Im Internet finden Sie zahlreiche Variationen bereits fertiger Skripte. Wir haben als Grundlage genommen von PostgreSQL-Experten, der die Bloat von Tabellen zusammen mit Toast und Bloat von Btree-Indizes bewertet. Nach unserer Erfahrung liegt seine Ungenauigkeit bei 10-20%.
Eine andere Möglichkeit ist die Verwendung der Erweiterung , die Einblick in Seiten ermöglicht und sowohl einen geschätzten als auch einen genauen Bloat-Wert liefert. Im zweiten Fall muss die gesamte Tabelle jedoch gescannt werden.
Ein geringer Bloat-Wert von bis zu 20% wird als akzeptabel angesehen. Er kann als analog zum Fillfactor für und . Bei 50% und mehr kann es zu Leistungsproblemen kommen.
Methoden zur Bekämpfung von Bloat
In Postgres gibt es mehrere Möglichkeiten, Bloat „out of the box“ zu bekämpfen, jedoch sind diese nicht immer für jeden geeignet.
AUTOVACUUM zu konfigurieren, damit kein Bloat entsteht. Und um genauer zu sein, um ein für Sie akzeptables Niveau zu halten. Es mag wie ein „Kapitänerat“ klingen, doch in der Realität ist dies nicht immer leicht umzusetzen. Beispielsweise kann es vorkommen, dass Sie aktiv an Entwicklungen arbeiten, bei denen sich das Datenschema regelmäßig ändert, oder dass eine Datenmigration stattfindet. In der Folge kann sich Ihr Lastprofil häufig ändern und variiert in der Regel für verschiedene Tabellen. Das bedeutet, dass Sie ständig etwas vorausplanen und AUTOVACUUM an das sich ändernde Profil jeder Tabelle anpassen müssen. Offensichtlich ist das jedoch keine einfache Aufgabe.
Ein weiteres häufiges Problem, warum AUTOVACUUM nicht in der Lage ist, Tabellen rechtzeitig zu verarbeiten, sind lang laufende Transaktionen, die ihm das Bereinigen der Daten verwehren, da diese Transaktionen darauf zugreifen. Die Empfehlung hier ist ebenfalls klar – befreien Sie sich von "hängenden" Transaktionen und minimieren Sie die Dauer aktiver Transaktionen. Wenn Ihre Anwendung jedoch sowohl OLAP- als auch OLTP-Lasten verarbeitet, kann es gleichzeitig sowohl viele häufige Updates und kurze Abfragen als auch langwierige Operationen geben – beispielsweise die Erstellung eines bestimmten Berichts. In solch einem Fall sollten Sie in Betracht ziehen, die Last auf verschiedene Datenbanken zu verteilen, um eine feinere Anpassung jeder einzelnen zu ermöglichen.
Ein weiteres Beispiel – selbst wenn das Profil homogen ist, aber die Datenbank unter extrem hoher Last steht, kann selbst das agilste AUTOVACUUM nicht mithalten, und es kann zu Bloat kommen. Skalierung (vertikal oder horizontal) ist die einzige Lösung.
Was tun, wenn Sie AUTOVACUUM konfiguriert haben, aber der Bloat weiterhin wächst?
Der Befehl VACUUM FULL rekonstruiert den Inhalt von Tabellen und Indizes und belässt nur die aktuellen Daten darin. Sie arbeitet perfekt zur Beseitigung von Bloat, jedoch wird während ihrer Ausführung eine exklusive Sperre auf die Tabelle (AccessExclusiveLock) gesetzt, die die Ausführung von Abfragen auf dieser Tabelle, selbst SELECT-Abfragen, verhindert. Wenn Sie es sich leisten können, Ihren Dienst oder Teile davon für eine Weile (von mehreren Minuten bis hin zu mehreren Stunden, abhängig von der Größe der Datenbank und Ihrer Hardware) auszusetzen, ist diese Option die beste. Leider schaffen wir es nicht, VACUUM FULL innerhalb der geplanten Wartung durchzuführen, weshalb diese Methode für uns nicht geeignet ist.
Der Befehl CLUSTER rekonstruiert ebenfalls den Inhalt von Tabellen wie VACUUM FULL, ermöglicht es jedoch, einen Index anzugeben, nach dem die Daten physisch auf der Festplatte geordnet werden (zukunftsweisend wird jedoch keine Ordnung für neue Zeilen garantiert). In bestimmten Situationen ist dies eine gute Optimierung für einige Abfragen – insbesondere für das Lesen mehrerer Datensätze über den Index. Der Nachteil des Befehls ist derselbe wie bei VACUUM FULL – während der Ausführung wird die Tabelle gesperrt.
Der Befehl REINDEX ähnelt den beiden vorherigen, führt jedoch eine Neuordnung eines bestimmten Index oder aller Indizes einer Tabelle durch. Die Sperren sind etwas schwächer: ShareLock auf die Tabelle (verhindert Änderungen, erlaubt jedoch SELECT) und AccessExclusiveLock auf den neuordnenden Index (blockiert Abfragen, die diesen Index verwenden). In der 12. Version von Postgres wurde jedoch ein Parameter eingeführt, , der es ermöglicht, den Index neu zu ordnen, ohne paralleles Hinzufügen, Ändern oder Löschen von Datensätzen zu blockieren.
In früheren Versionen von Postgres kann ein ähnliches Ergebnis wie REINDEX CONCURRENTLY mit erzielt werden. Es ermöglicht die Erstellung eines Index ohne strenge Sperrung (ShareUpdateExclusiveLock, das parallele Abfragen nicht behindert), dann den alten Index durch den neuen zu ersetzen und den alten Index zu löschen. Dies ermöglicht die Beseitigung von Index-Bloat, ohne den Betrieb Ihrer Anwendung zu stören. Es ist wichtig zu beachten, dass bei der Neuordnung von Indizes zusätzliche Belastungen auf das Datensystem anfallen.
Somit gibt es, wenn es Möglichkeiten zur Beseitigung von Bloat "im laufenden Betrieb" für Indizes gibt, für Tabellen keine solchen Methoden. Hier kommen verschiedene externe Erweiterungen ins Spiel: (früher pg_reorg), , und andere. In diesem Artikel werde ich diese nicht vergleichen und nur über pg_repack sprechen, das wir nach einigen Anpassungen bei uns verwenden.
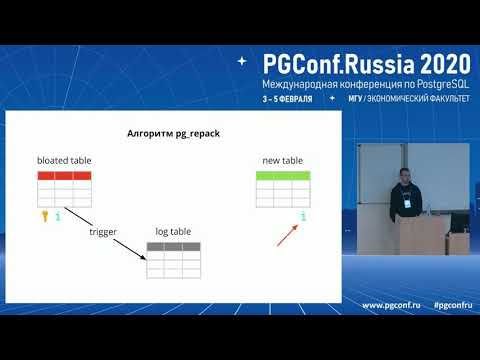
Wie pg_repack funktioniert

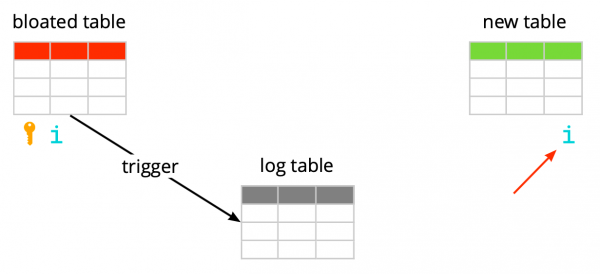
Angenommen, wir haben eine ganz gewöhnliche Tabelle – mit Indizes, Einschränkungen und leider mit Bloat. Im ersten Schritt erstellt pg_repack eine Log-Tabelle, um Informationen über alle Änderungen während der Ausführung zu speichern. Ein Trigger wird diese Änderungen bei jedem Insert, Update und Delete replizieren. Danach wird eine Tabelle erstellt, die in ihrer Struktur der ursprünglichen Tabelle ähnelt, jedoch ohne Indizes und Einschränkungen, um den Prozess der Dateneinfügung nicht zu verlangsamen.
Anschließend überträgt pg_repack die Daten aus der alten Tabelle in die neue und filtert automatisch alle irrelevanten Zeilen heraus, bevor Indizes für die neue Tabelle erstellt werden. Während der Ausführung all dieser Operationen werden in der Log-Tabelle Änderungen gesammelt.
Der nächste Schritt besteht darin, die Änderungen in die neue Tabelle zu übertragen. Der Transfer erfolgt in mehreren Iterationen, und wenn im Log-Table weniger als 20 Einträge verbleiben, erfasst pg_repack eine feste Sperre, überträgt die letzten Daten und ersetzt die alte Tabelle in den Systemtabellen von Postgres durch die neue. Dies ist der einzige, sehr kurze Moment, in dem Sie nicht mit der Tabelle arbeiten können. Danach werden die alte Tabelle und die Log-Tabelle gelöscht, und es wird Platz im Dateisystem freigegeben. Der Prozess ist abgeschlossen.
In der Theorie sieht alles gut aus, aber wie sieht es in der Praxis aus? Wir haben pg_repack sowohl unter Last als auch ohne Last getestet und geprüft, wie es sich bei einem vorzeitigen Abbruch verhält (einfach gesagt, bei Ctrl+C). Alle Tests waren positiv.
Wir sind in die Produktion gegangen – und plötzlich lief alles anders als erwartet.
Der erste Versuch in der Produktion
Bereits im ersten Cluster erhielten wir einen Fehler wegen eines Verstoßes gegen die eindeutige Einschränkung:
$ ./pg_repack -t tablename -o id
INFO: Tabelle "tablename" wird neu organisiert
ERROR: Abfrage fehlgeschlagen:
ERROR: Doppelter Schlüsselwert verletzt eindeutige Einschränkung "index_16508"
DETAIL: Schlüssel (id, index)=(100500, 42) existiert bereits.
Diese Einschränkung hatte den automatisch generierten Namen index_16508 – erstellt von pg_repack. Anhand der Attribute, die sie umfasst, haben wir unser entsprechendes Limit identifiziert. Das Problem war, dass dies keine ganz gewöhnliche Einschränkung ist, sondern eine aufgeschobene (), d.h. ihre Überprüfung erfolgt später als der SQL-Befehl, was zu unerwarteten Konsequenzen führt.
Aufgeschobene Einschränkungen: Warum sie wichtig sind und wie sie funktionieren
Ein wenig Theorie zu aufgeschobenen Einschränkungen.
Betrachten wir ein einfaches Beispiel: Wir haben eine Referenztabelle für Autos mit zwei Attributen – dem Namen und der Reihenfolge des Autos in der Tabelle.
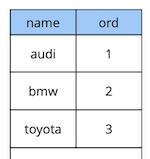
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Angenommen, wir müssen das erste und das zweite Auto vertauschen. Die naive Lösung wäre, den ersten Wert durch den zweiten zu ersetzen und umgekehrt:
begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Aber wenn wir diesen Code ausführen, werden wir wie erwartet eine Verletzung der Einschränkung erhalten, weil die Reihenfolge der Werte in der Tabelle einzigartig ist:
[23305] FEHLER: doppelter Schlüsselwert verletzt die einzigartige Einschränkung “uk_cars”
Detail: Schlüssel (ord)=(2) existiert bereits.
Wie kann man es anders machen? Erste Möglichkeit: Fügen Sie eine zusätzliche Reihenfolgeersetzung hinzu, die garantiert nicht in der Tabelle vorhanden ist, zum Beispiel „-1“. In der Programmierung nennt man das „Wertetausch zweier Variablen über eine dritte“. Der einzige Nachteil dieser Methode ist das zusätzliche Update.
Zweite Möglichkeit: Entwerfen Sie die Tabelle neu, um für die Reihenfolge einen Datentyp mit Gleitkomma anstelle von Ganzzahlen zu verwenden. Wenn Sie dann beispielsweise den Wert von 1 auf 2,5 aktualisieren, wird der erste Datensatz automatisch zwischen den zweiten und dritten eingeordnet. Diese Lösung funktioniert, hat jedoch zwei Einschränkungen. Erstens ist sie ungeeignet, wenn der Wert irgendwo in der Benutzeroberfläche verwendet wird. Zweitens haben Sie je nach Genauigkeit des Datentyps nur eine begrenzte Anzahl möglicher Einfügungen, bis alle Werte neu berechnet werden.
Dritte Möglichkeit: Machen Sie die Einschränkung verzögert, damit sie nur zum Zeitpunkt des Commits überprüft wird:
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);Da die Logik unserer ursprünglichen Anfrage garantiert, dass bis zum Commit alle Werte eindeutig sind, wird sie erfolgreich ausgeführt.
Das oben genannte Beispiel ist zwar sehr synthetisch, verdeutlicht aber das Konzept. In unserer Anwendung verwenden wir verzögerte Einschränkungen, um die Logik zu implementieren, die Konflikte löst, wenn mehrere Benutzer mit gemeinsamen Objekten-Widgets auf dem Board arbeiten. Der Einsatz solcher Einschränkungen ermöglicht es uns, den Anwendungscode etwas einfacher zu gestalten.
Insgesamt gibt es je nach Art der Einschränkung in Postgres drei Prüfungsstufen: Zeilenebene, Transaktionsebene und Ausdrucksebene.
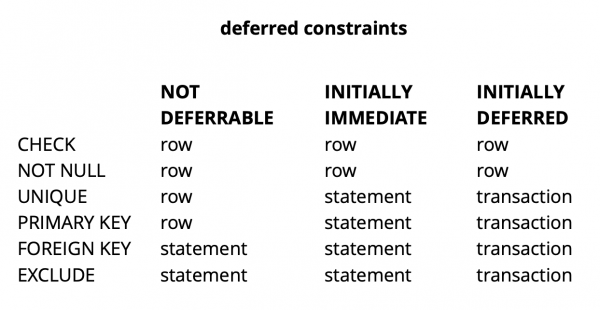
Quelle:
CHECK und NOT NULL werden immer auf Zeilenebene überprüft, während für die anderen Einschränkungen, wie aus der Tabelle ersichtlich, verschiedene Optionen existieren. Weitere Informationen finden Sie in der Dokumentation. .
Zusammenfassend lässt sich sagen, dass verzögerte Einschränkungen in bestimmten Situationen einen besser lesbaren Code und weniger Befehle bieten. Allerdings muss man dafür mit einem komplizierteren Debugging-Prozess rechnen, da der Zeitpunkt des Fehlerschutzes und der Moment, in dem man davon erfährt, zeitlich auseinanderfallen. Ein weiteres potentielles Problem besteht darin, dass der Planer nicht immer einen optimalen Plan erstellen kann, wenn eine verzögerte Einschränkung in der Anfrage beteiligt ist.
Verbesserung von pg_repack
Wir haben verstanden, was verzögerte Einschränkungen sind, aber wie hängen sie mit unserem Problem zusammen? Erinnern wir uns an den Fehler, den wir zuvor erhalten haben:
$ ./pg_repack -t tablename -o id
INFO: Tabelle "tablename" wird neu organisiert
ERROR: Abfrage fehlgeschlagen:
ERROR: Doppelter Schlüsselwert verletzt eindeutige Einschränkung "index_16508"
DETAIL: Schlüssel (id, index)=(100500, 42) existiert bereits.Er tritt beim Kopieren von Daten aus der Log-Tabelle in eine neue Tabelle auf. Das wirkt seltsam, da die Daten in der Log-Tabelle zusammen mit den Daten der ursprünglichen Tabelle festgeschrieben werden. Wenn sie die Einschränkungen der ursprünglichen Tabelle erfüllen, wie können sie dann dieselben Einschränkungen in der neuen Tabelle verletzen?
Wie sich herausstellte, liegt die Wurzel des Problems im vorherigen Schritt der Arbeit von pg_repack, in dem nur Indizes, jedoch keine Einschränkungen erstellt werden: In der alten Tabelle gab es eine eindeutige Einschränkung, und in der neuen wurde stattdessen ein eindeutiger Index erstellt.
Es ist wichtig zu beachten, dass, wenn die Einschränkung normal und nicht verschoben ist, der erstellte eindeutige Index dieser Einschränkung entspricht, da eindeutige Einschränkungen in Postgres durch die Erstellung eines eindeutigen Indexes umgesetzt werden. Im Fall einer verschobenen Einschränkung jedoch verhält es sich anders, da der Index nicht verschoben sein kann und immer zum Zeitpunkt der Ausführung des SQL-Befehls überprüft wird.
Das Hauptproblem liegt also in der „Verschobene“ Überprüfung: In der ursprünglichen Tabelle findet sie zum Zeitpunkt des Commits statt, in der neuen hingegen bei der Ausführung des SQL-Befehls. Daher müssen wir sicherstellen, dass die Überprüfungen in beiden Fällen gleich ablaufen: entweder immer verschoben oder immer sofort.
Also, welche Ideen hatten wir?
Einen Index erstellen, der dem verschobenen entspricht.
Die erste Idee ist, beide Überprüfungen im sofortigen Modus durchzuführen. Dies könnte einige False Positives bei den Einschränkungen verursacht, aber wenn es nur wenige sind, sollte das die Benutzer nicht beeinträchtigen, da solche Konflikte für sie normal sind. Sie treten beispielsweise auf, wenn zwei Benutzer gleichzeitig dasselbe Widget zu bearbeiten versuchen und der Client des zweiten Benutzers nicht rechtzeitig die Information erhält, dass das Widget bereits vom ersten Benutzer für die Bearbeitung gesperrt ist. In dieser Situation antwortet der Server dem zweiten Benutzer mit einer Ablehnung, und sein Client macht die Änderungen rückgängig und sperrt das Widget. Ein wenig später, wenn der erste Benutzer die Bearbeitung abgeschlossen hat, erhält der zweite die Information, dass das Widget nicht mehr gesperrt ist und dass er seine Aktion wiederholen kann.

Um sicherzustellen, dass die Überprüfungen immer im sofortigen Modus erfolgen, haben wir einen neuen Index erstellt, der dem ursprünglichen verzögerten Limit entspricht:
CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
-- run pg_repack
DROP INDEX CONCURRENTLY uk_tablename__immediate;In der Testumgebung haben wir nur einige erwartete Fehler festgestellt. Erfolg! Wir haben pg_repack erneut in der Produktion gestartet und innerhalb der ersten Stunde fünf Fehler im ersten Cluster festgestellt. Das ist ein akzeptables Ergebnis. Allerdings hat sich die Anzahl der Fehler im zweiten Cluster erheblich erhöht, weshalb wir pg_repack stoppen mussten.
Warum ist das passiert? Die Fehlerwahrscheinlichkeit hängt davon ab, wie viele Benutzer gleichzeitig mit denselben Widgets arbeiten. Anscheinend gab es zu diesem Zeitpunkt bei den Daten im ersten Cluster viel weniger konkurrierende Änderungen als in den anderen, d.h. wir hatten einfach „Glück“.
Die Idee hat nicht funktioniert. Zu diesem Zeitpunkt waren uns zwei andere Lösungsansätze bekannt: unseren Anwendungscode so umzuschreiben, dass wir auf verzögerte Einschränkungen verzichten oder pg_repack „beizubringen“, mit ihnen umzugehen. Wir haben uns für Letzteres entschieden.
Die Indizes in der neuen Tabelle durch verzögerte Einschränkungen aus der ursprünglichen Tabelle ersetzen.
Das Ziel der Anpassung war offensichtlich – wenn die ursprüngliche Tabelle eine verzögerte Einschränkung hat, muss für die neue eine solche Einschränkung und nicht ein Index erstellt werden.
Um unsere Änderungen zu überprüfen, haben wir einen einfachen Test geschrieben:
- Tabelle mit einer verzögerten Einschränkung und einem Eintrag;
- Wir fügen in einer Schleife Daten ein, die mit dem vorhandenen Datensatz in Konflikt stehen;
- Wir führen ein Update durch – die Daten stehen nicht mehr in Konflikt;
- Wir committen die Änderungen.
CREATE TABLE test_table
(
id SERIAL,
val INT,
CONSTRAINT uk_test_table__val UNIQUE (val) DEFERRABLE INITIALLY DEFERRED
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table SET val = i WHERE id = v_id;
COMMIT;
END;
END LOOP;Die ursprüngliche Version von pg_repack schlug beim ersten Insert fehl, die überarbeitete Version funktionierte fehlerfrei. Ausgezeichnet.
Wir gehen in die Produktion und erhalten erneut einen Fehler in derselben Phase, beim Kopieren der Daten aus der Log-Tabelle in die Neue:
$ ./pg_repack -t tablename -o id
INFO: Tabelle "tablename" wird neu organisiert
ERROR: Abfrage fehlgeschlagen:
ERROR: Doppelter Schlüsselwert verletzt eindeutige Einschränkung "index_16508"
DETAIL: Schlüssel (id, index)=(100500, 42) existiert bereits.Klassische Situation: In den Testumgebungen funktioniert alles, in der Produktion nicht?!
APPLY_COUNT und der Übergang zwischen zwei Batches
Wir haben den Code buchstäblich Zeile für Zeile analysiert und einen wichtigen Punkt entdeckt: Der Datenübertrag von der Log-Tabelle in die Neue erfolgt in Batches. Die Konstante APPLY_COUNT gab die Größe des Batches an:
for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue; /* Es könnten noch einige Tupel vorhanden sein, wiederholen. */
...
}Das Problem besteht darin, dass die Daten der ursprünglichen Transaktion, in der mehrere Operationen potenziell die Begrenzung verletzen können, beim Transfer an die Schnittstelle zweier Batch-Prozesse gelangen können – die eine Hälfte der Befehle wird im ersten Batch festgeschrieben, die andere im zweiten. Hier spielt das Glück eine Rolle: Wenn die Befehle im ersten Batch nichts verletzen, ist alles gut. Wenn sie jedoch eineverletzen, tritt ein Fehler auf.
APPLY_COUNT beträgt 1000 Datensätze, was erklärt, warum unsere Tests erfolgreich waren – sie deckten nicht den Fall des „Batch-Schnitts“ ab. Wir verwendeten zwei Befehle – insert und update, wobei genau 500 Transaktionen mit zwei Befehlen immer in den Batch passten und wir keine Probleme hatten. Nach dem Hinzufügen des zweiten Updates funktionierte unsere Anpassung nicht mehr:
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id; -- ein weiteres Update
COMMIT;
END;
END LOOP;Die nächste Aufgabe besteht darin, sicherzustellen, dass die Daten aus der ursprünglichen Tabelle, die in einer Transaktion geändert wurden, auch innerhalb einer Transaktion in die neue Tabelle gelangen.
Abandonment of Batching
Und wieder standen uns zwei Lösungsansätze zur Verfügung. Die erste: Lassen Sie uns die Aufteilung in Batches ganz vermeiden und die Daten in einer einzigen Transaktion übertragen. Der Vorteil dieser Lösung liegt in ihrer Einfachheit – die erforderlichen Codeänderungen sind minimal (übrigens funktionierte in älteren Versionen pg_reorg genau so). Aber es gibt ein Problem – wir schaffen eine langfristige Transaktion, und das stellt, wie bereits erwähnt, eine Gefahr für die Entstehung eines neuen Bloat dar.
Die zweite Lösung ist zwar komplizierter, aber vermutlich die sinnvollere: Einfügen einer Spalte in die Protokolltabelle, die die ID der Transaktion enthält, die die Daten in die Tabelle eingefügt hat. Dadurch können wir beim Kopieren der Daten diese nach diesem Attribut gruppieren und sicherstellen, dass miteinander verbundene Änderungen gemeinsam übertragen werden. Das Batch wird aus mehreren Transaktionen (oder einer großen) bestehen, und seine Größe wird variieren, abhängig davon, wie viele Daten in diesen Transaktionen geändert wurden. Wichtig ist, dass die Daten verschiedener Transaktionen in zufälliger Reihenfolge in die Protokolltabelle gelangen, sodass wir sie nicht mehr sequenziell lesen können wie zuvor. Ein sequenzieller Scan bei jeder Abfrage mit Filterung nach tx_id ist zu kostspielig; ein Index wäre notwendig, würde jedoch die Methode aufgrund der damit verbundenen Aktualisierungskosten verlangsamen. Insgesamt muss wie immer irgendwo Opfer gebracht werden.
Wir haben uns also entschieden, mit der ersten Variante zu beginnen, da sie einfacher ist. Zunächst mussten wir herausfinden, ob eine längere Transaktion ein wirkliches Problem darstellen würde. Da der Hauptdatenumzug von der alten Tabelle in die neue ebenfalls in einer langen Transaktion erfolgt, hat sich die Frage zu "wie sehr werden wir diese Transaktion verlängern?" gewandelt. Die Dauer der ersten Transaktion hängt hauptsächlich von der Größe der Tabelle ab. Die Dauer der neuen wiederum davon, wie viele Änderungen in der Tabelle während des Datenumzugs anfallen, also von der Intensität der Last. Der pg_repack-Lauf fand bei minimaler Auslastung des Dienstes statt, und das Volumen der Änderungen war im Vergleich zur ursprünglichen Tabellengröße vernachlässigbar gering. Wir sind zu dem Schluss gekommen, dass wir die Zeit der neuen Transaktion (im Durchschnitt etwa 1 Stunde und 2-3 Minuten) vernachlässigen können.
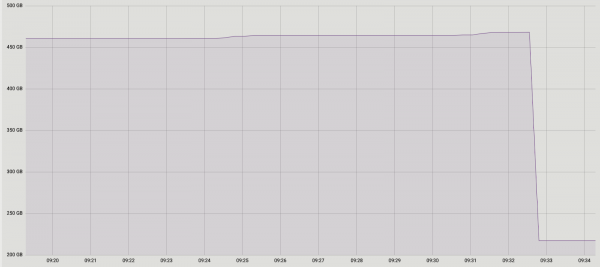
Die Ergebnisse der Experimente waren positiv. Der Start in der Produktion verlief ebenfalls erfolgreich. Zur Veranschaulichung – hier ist ein Bild der Größe einer der Datenbanken nach dem Repack:
Da wir mit dieser Lösung vollständig zufrieden sind, haben wir nicht versucht, eine zweite zu realisieren, aber wir ziehen in Betracht, sie mit den Entwicklern des Plugins zu besprechen. Unsere aktuelle Überarbeitung ist leider noch nicht bereit zur Veröffentlichung, da wir nur das Problem mit den einzigartigen verzögerten Einschränkungen gelöst haben und für einen vollständigen Patch auch die Unterstützung anderer Typen erforderlich ist. Wir hoffen, dass wir das in Zukunft umsetzen können.
Vielleicht fragen Sie sich, warum wir uns überhaupt auf diese Geschichte mit der Überarbeitung von pg_repack eingelassen haben, anstatt beispielsweise seine Alternativen zu nutzen? Irgendwann haben wir auch darüber nachgedacht, aber die positiven Erfahrungen mit der Nutzung in der Vergangenheit, bei Tabellen ohne verzögerte Einschränkungen, motivierten uns, die Grundlagen des Problems zu verstehen und es zu beheben. Außerdem benötigt die Verwendung anderer Lösungen ebenfalls Zeit für Tests, weshalb wir beschlossen haben, zunächst zu versuchen, das Problem hierin zu beheben, und falls wir feststellen, dass wir dies in einem angemessenen Zeitraum nicht leisten können, werden wir Alternativen in Betracht ziehen.
Fazit
Was wir aus eigener Erfahrung empfehlen können:
- Überwachen Sie Ihr Bloat. Anhand von Monitoring-Daten können Sie verstehen, wie gut Autovacuum konfiguriert ist.
- Konfigurieren Sie AUTOVACUUM, um Bloat auf einem akzeptablen Niveau zu halten.
- Wenn Bloat dennoch wächst und Sie ihn nicht mit den Standardwerkzeugen bekämpfen können, scheuen Sie sich nicht, externe Erweiterungen zu verwenden. Testen Sie alles gründlich.
- Scheuen Sie sich nicht, externe Lösungen an Ihre Bedürfnisse anzupassen – manchmal kann dies effektiver und sogar einfacher sein als Änderungen an Ihrem eigenen Code.
Quelle: habr.com
