

— ein äußerst leistungsfähiger und praktischer Mechanismus, wenn die gleichen Aktionen bei miteinander verbundenen Daten „nach unten“ ausgeführt werden. Aber unkontrollierte Rekursion ist eine Gefahr, die zu endlosen Ausführungen des Prozesses führen kann oder (was häufiger vorkommt) zu dem „Verschlingen“ des gesamten verfügbaren Speichers..

Datenbanksysteme arbeiten in dieser Hinsicht nach denselben Prinzipien — „Sie sagten, graben Sie, also grabe ich.“. Ihre Abfrage kann nicht nur benachbarte Prozesse verlangsamen, indem sie ständig CPU-Ressourcen verbraucht, sondern auch die gesamte Datenbank „zum Absturz bringen“, indem sie den gesamten verfügbaren Speicher „auffrisst“. Daher ist der Schutz vor endloser Rekursion die Verantwortung des Entwicklers selbst.
In PostgreSQL besteht die Möglichkeit, rekursive Abfragen über schon seit den „guten alten Zeiten“ der Version 8.4, aber bis heute können regelmäßig potenziell anfällige „schutzlose“ Abfragen festgestellt werden. Wie können Sie sich von solchen Problemen befreien?
Schreiben Sie keine rekursiven Abfragen.
Sondern schreiben Sie nicht-rekursiven. Mit Respekt, Ihr K.O.
Tatsächlich bietet PostgreSQL eine Vielzahl an Funktionen, die man nutzen kann, um nicht Rekursion anzuwenden.
Einen grundlegend anderen Ansatz für das Problem verwenden
Manchmal kann man die Aufgabe auch einfach aus einer anderen Perspektive betrachten. Ein Beispiel für eine solche Situation habe ich in dem Artikel gebracht – die Multiplikation einer Anzahl von Zahlen ohne benutzerdefinierte Aggregatfunktionen:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY -- Auswahl des finalen Ergebnisses
i DESC
LIMIT 1;Eine solche Abfrage kann durch die Methode von Mathematikern ersetzt werden:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;generate_series anstelle von Schleifen verwenden
Angenommen, wir stehen vor der Aufgabe, alle möglichen Präfixe für die Zeichenfolge 'abcdefgh':
zu generieren:
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T; Ist hier wirklich Rekursion nötig?.. Wenn wir LATERAL und generate_series, verwenden, dann sind nicht einmal CTE erforderlich:
WÄHLEN
substr(str, 1, ln) str
VON
(WERT('abcdefgh')) T(str)
, LATERAL(
WÄHLEN generate_series(länge(str), 1, -1) ln
) X;Datenbankstruktur ändern
Zum Beispiel haben Sie eine Tabelle mit Forenbeiträgen, die zeigt, wer wem geantwortet hat oder den Thread in :
ERSTELLEN TABELLE nachricht(
nachricht_id
uuid
PRIMARY KEY
, antwort_auf
uuid
REFERENZEN nachricht
, text
text
);
INDEX ERSTELLEN FÜR nachricht(antwort_auf); 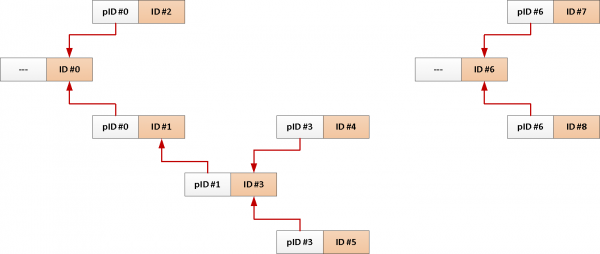
Ein typischer Abfrage zum Laden aller Nachrichten zu einem Thema sieht etwa so aus:
MIT REKURSIV T ALS (
WÄHLEN
*
VON
nachricht
WO
nachricht_id = $1
UNION ALLE
WÄHLEN
m.*
VON
T
JOIN
nachricht m
ON m.antwort_auf = T.nachricht_id
)
TABELLE T;Aber da wir immer das gesamte Thema vom Ausgangsnachricht benötigen, warum fügen wir nicht seine ID automatisch in jeden Datensatz ?
-- Fügen wir ein Feld mit der gemeinsamen Themen-ID und einen Index darauf hinzu
ALTER TABLE nachricht
FÜGE SPALTE theme_id uuid HINZU;
INDEX ERSTELLEN FÜR nachricht(theme_id);
-- initialisieren Sie die Themen-ID in einem Trigger bei der Einfügung
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = FALLS
WENN NEW.antwort_auf IST NULL DANN NEW.nachricht_id -- nehmen Sie vom Startereignis
SONST ( -- oder von der Nachricht, auf die wir antworten
WÄHLEN
theme_id
VON
nachricht
WO
nachricht_id = NEW.antwort_auf
)
END;
GEBEN SIE NEU ZURÜCK;
END;
$$ SPRACHE plpgsql;
CREATE TRIGGER ins VOR INSERT
AUF nachricht
FÜR JEDEN DATENZEILE
FÜHREN SIE DAS VERFAHREN ins AUS; 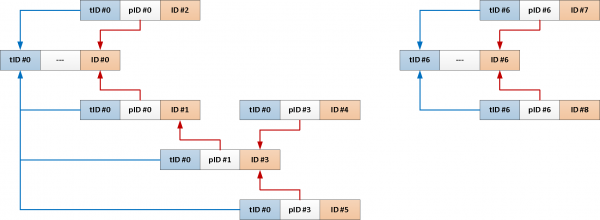
Jetzt kann unsere rekursive Abfrage auf folgendes reduziert werden:
SELECT
*
FROM
message
WHERE
theme_id = $1;Anwendungsbezogene "Grenzen" nutzen
Falls wir die Struktur der Datenbank aus bestimmten Gründen nicht ändern können, sollten wir überlegen, auf welche Aspekte wir uns stützen können, damit selbst ein Fehler in den Daten nicht zu einer endlosen Rekursion führt.
Zähler für die Rekursionstiefe
Wir erhöhen einfach den Zähler bei jedem Schritt der Rekursion bis zu dem Punkt, den wir als eindeutig unangemessen erachten:
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 -- Grenze
) Pro: Bei einem Versuch zur Endlosschleife werden wir dennoch nicht mehr als die angegebene Anzahl an Iterationen "nach unten" durchführen.
Contra: Es gibt keine Garantie, dass wir nicht einen gleichen Datensatz mehrfach verarbeiten – beispielsweise auf der Tiefe 15 und 25, und dann jeweils alle 10 tiefer. Auch zum "seitlichen" Zugriff wurde nichts versprochen.
Formal wird diese Rekursion nicht unendlich sein, aber wenn die Anzahl der Datensätze bei jedem Schritt exponentiell zunimmt, wissen wir alle, wie das endet…
Wächter des "Pfades"
Wir fügen nacheinander alle Identifikatoren der Objekte, die wir auf dem Weg der Rekursion treffen, in ein Array ein, das den einzigartigen "Weg" zu ihnen darstellt:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id ALL(T.path) -- entspricht keinem der
) Pro: Wenn ein Zyklus in den Daten vorhanden ist, werden wir auf keinen Fall den gleichen Datensatz im Rahmen eines einzigen Weges erneut verarbeiten.
Contra: Aber dabei können wir tatsächlich alle Datensätze durchlaufen, ohne uns zu wiederholen.
Einschränkung der Pfadlänge
Um die Situation des "Umherirrens" der Rekursion in unverständlicher Tiefe zu vermeiden, können wir die beiden vorherigen Methoden kombinieren. Oder, falls wir keine zusätzlichen Felder unterstützen wollen, die Fortsetzung der Rekursion mit einer Bewertung der Pfadlänge ergänzen:
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id ALL(T.path) AND
array_length(T.path, 1) < 10
) Wählen Sie die Methode nach Ihrem Geschmack!
Quelle: habr.com
