

In der Praxis kommt es vor, dass ein Entwickler eine Anfrage schreibt und denkt: „die Datenbank ist schlau und meistert alles selbst!«
In einigen Fällen (teils aufgrund Unkenntnis der Möglichkeiten der Datenbank, teils wegen vorzeitiger Optimierungen) führt dieser Ansatz zur Entstehung von „Frankenstein-Lösungen“.
Zunächst ein Beispiel für eine solche Anfrage:
-- Für jedes Schlüssel-Paar finden wir die zugehörigen Feldwerte
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- Finden Sie min/max-Werte für jeden ersten Schlüssel
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- Verknüpfen Sie die Schlüsselpaare und min/max-Werte nach dem ersten Schlüssel
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;Um die Qualität der Anfrage konkret zu bewerten, lassen Sie uns eine beliebige Datensammlung erstellen:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
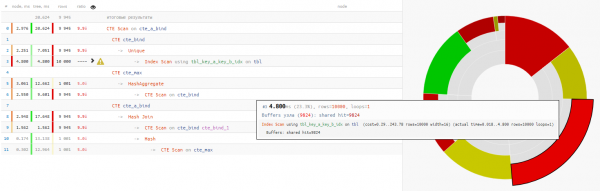
Es stellt sich heraus, dass das Lesen der Daten weniger als ein Viertel der Gesamtzeit für die Ausführung der Anfrage in Anspruch nahm:
Wir analysieren im Detail
Schauen wir uns die Anfrage genau an und denken nach:
- Warum ist hier WITH RECURSIVE, wenn es keine rekursiven CTE gibt?
- Warum min/max-Werte in einem separaten CTE gruppieren, wenn sie sowieso wieder an die ursprüngliche Abfrage gebunden werden?
+25% Zeit - Warum am Ende eine wiederholte Abfrage aus dem vorherigen CTE über ein bedingungsloses ‘SELECT * FROM’ verwenden?
+14% Zeit
In diesem Fall hatten wir Glück, dass für die Verknüpfung ein Hash Join und nicht ein Nested Loop gewählt wurde, denn dann hätten wir nicht nur einen CTE-Scan, sondern 10K erhalten!
ein wenig über CTE ScanHier sollten wir uns daran erinnern, dass CTE Scan das Pendant zu Seq Scan ist — das bedeutet, keine Indizierung, sondern nur eine vollständige Durchsuchung, die benötigen würde 10K x 0.3ms = 3000ms bei Zyklen über cte_max oder 1K x 1.5ms = 1500ms bei Zyklen über cte_bind!
Was wollten wir tatsächlich als Ergebnis erhalten? Genau, normalerweise kommt diese Frage etwa nach der 5. Minute des Durchgehens von «dreistöckigen» Anfragen.
Wir wollten für jedes einzigartige Schlüssel-Paar min/max aus der Gruppe nach key_a ausgeben.
Also nutzen wir dafür :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 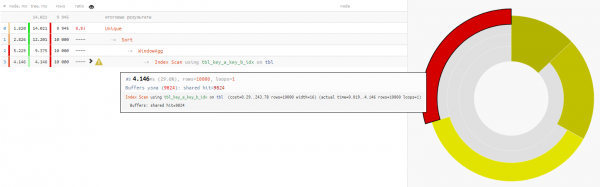
Da das Lesen von Daten in beiden Fällen etwa 4-5 ms in Anspruch nimmt, beträgt unser gesamter Zeitgewinn -32% — das ist rein die Last, die vom CPU der Datenbank genommen wurde, wenn eine solche Abfrage häufig genug ausgeführt wird.
Im Allgemeinen sollte man die Datenbank nicht zwingen, "rund zu tragen und quadratisch zu rollen".
Quelle: habr.com
