

In komplexen ERP-Systemen haben viele Entitäten eine hierarchische Natur., wenn homogene Objekte in einen Baum von Beziehungen „Elternteil - Nachkomme“ angeordnet werden. Dies umfasst sowohl die organisatorische Struktur des Unternehmens (alle diese Niederlassungen, Abteilungen und Arbeitsgruppen) als auch den Produktkatalog, die Arbeitsbereiche und die geografischen Standorte der Verkaufsstellen,…
Tatsächlich gibt es keinen in dem nicht irgendwie eine Hierarchie vorhanden ist. Aber selbst wenn Sie nicht im „Geschäft“ arbeiten, können Sie leicht mit hierarchischen Beziehungen konfrontiert werden. Einfach gesagt, selbst Ihr Stammbaum oder der Grundriss eines Einkaufszentrums ist eine ähnliche Struktur.
Es gibt viele Möglichkeiten, einen solchen Baum in einer DBMS zu speichern, aber heute konzentrieren wir uns nur auf eine Möglichkeit:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid); -- Denken Sie daran, dass der FK nicht automatisch einen Index erstellt, im Gegensatz zum PK.
Und während Sie in die Tiefe der Hierarchie schauen, wartet sie geduldig, wie ineffektiv Ihre 'naiven' Ansätze im Umgang mit einer solchen Struktur sein werden.

Lassen Sie uns typische auftretende Aufgaben besprechen, deren Umsetzung in SQL analysieren und versuchen, deren Leistung zu verbessern.
#1. Насколько глубока кроличья нора?
Nehmen wir zur Klarheit an, dass diese Struktur die Unterordnung der Abteilungen in der Organisationsstruktur widerspiegelt: Abteilungen, Divisionen, Sektoren, Zweigstellen, Arbeitsgruppen,... ganz gleich, wie man sie nennt.
Zuerst generieren wir unser 'Baum'-Modell mit 10K Elementen.
INSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;Beginnen wir mit der einfachsten Aufgabe – alle Mitarbeiter zu finden, die innerhalb eines bestimmten Sektors arbeiten, oder in hierarchischen Begriffen – alle Nachkommen des Knotens finden.. Und es wäre auch gut, die 'Tiefe' des Nachkommen zu erhalten... All dies kann notwendig sein, zum Beispiel zur Erstellung einer .
Alles wäre in Ordnung, wenn es dort nur ein paar Ebenen und insgesamt nur ein Dutzend Nachkommen gäbe, aber wenn es mehr als 5 Ebenen sind und bereits Dutzende von Nachkommen existieren, können Probleme auftreten. Lassen Sie uns betrachten, wie die traditionellen Varianten der „Baumabwärtsuche“ geschrieben (und funktionieren) gehören. Aber zuerst definieren wir, welche Knoten für unsere Untersuchungen am interessantesten sind.
Die meisten „tiefen“ Unterbäume:
WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC; id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...Die meisten „breite“ Unterbäume:
...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
Für diese Abfragen haben wir einen typischen rekursiven JOIN:
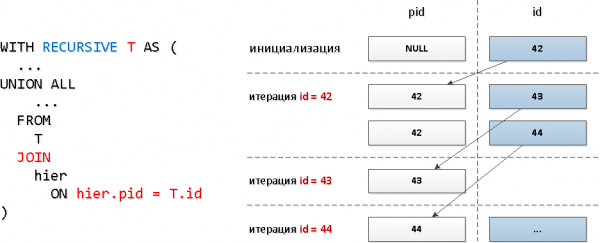
Offensichtlich wird bei einem solchen Abfragemodell die Anzahl der Iterationen mit der Gesamtzahl der Nachkommen übereinstimmen (und da gibt es mehrere Dutzend), und das kann beträchtliche Ressourcen und folglich Zeit beanspruchen.
Überprüfen wir das am „breitesten“ Unterbaum:
MIT REKURSION T ALS (
AUSWÄHLEN
id
VON
hier
WO
id = 5300
VEREINIGUNG ALL (
AUSWÄHLEN
hier.id
VON
T
JOIN
hier
ON hier.pid = T.id
)
TABELLE T; 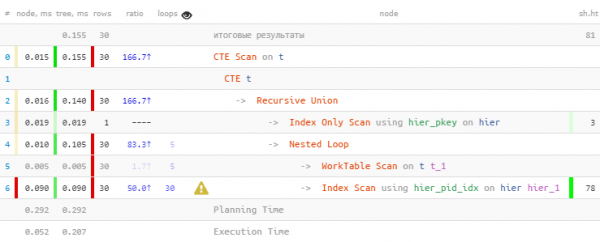
Wie erwartet haben wir alle 30 Datensätze gefunden. Aber wir haben dafür 60 % der gesamten Zeit gebraucht – weil wir dabei auch 30 Indexpfaden gemacht haben. Geht es nicht schneller?
Massenabgleich nach Index
Müssen wir für jeden Knoten eine separate Anfrage an den Index stellen? Es stellt sich heraus, dass wir dies nicht tun müssen – wir können gleichzeitig über mehrere Schlüssel mit einem Zugriff lesen. mit Hilfe von = ANY(array).
In jede solche Gruppe von Identifikatoren können wir alle in der vorherigen Stufe gefundenen IDs nach „Knoten“ einfügen. Das heißt, in jedem nächsten Schritt werden wir sofort alle Nachkommen einer bestimmten Ebene suchen..
Nur ist das Problem, dass wir in der rekursiven Auswahl nicht auf uns selbst im verschachtelten Abfrage zugreifen können,, aber wir müssen ja irgendwie nur das auswählen, was auf der vorhergehenden Ebene gefunden wurde... Es stellt sich heraus, dass man keine verschachtelte Anfrage für die gesamte Auswahl machen kann, sondern für ein bestimmtes Feld – und dieses Feld kann auch ein Array sein – das ist genau das, was wir für die Nutzung benötigen. ANY.
Das klingt etwas verrückt, aber auf dem Schema – ist alles einfach.
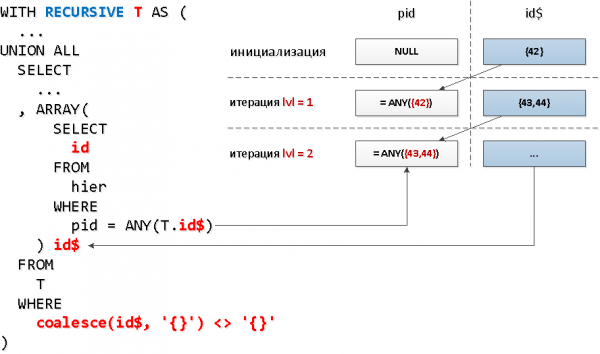
MIT REKURSIVEN T AS (
WÄHLEN
ARRAY[id] id$
VON
hier
WO
id = 5300
UNION ALL
WÄHLEN
ARRAY(
WÄHLEN
id
VON
hier
WO
pid = ANY(T.id$)
) id$
VON
T
WO
coalesce(id$, '{}') >> '{}' -- Bedingung für das Verlassen der Schleife - leeres Array
)
WÄHLEN
unnest(id$) id
VON
T; 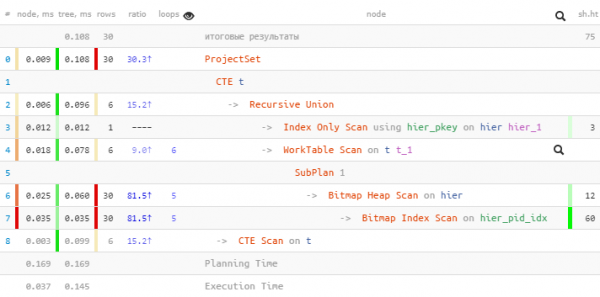
Hier ist das Wichtigste nicht einmal der Gewinn von 1,5-facher Zeit, sondern dass wir weniger Buffers abgezogen haben, da wir nur 5 statt 30 Zugriffe auf den Index hatten!
Ein zusätzlicher Vorteil ist, dass nach dem endgültigen unnest die Identifikatoren nach "Ebenen" geordnet bleiben.
Knotensignal
Der nächste Gedanke, der hilft, die Leistung zu verbessern - „Blätter“ können keine Kinder haben, das bedeutet, dass wir für sie nach „unten“ überhaupt nicht suchen müssen. In der Formulierung unserer Aufgabe bedeutet dies, dass, wenn wir einer Kette von Abteilungen gefolgt sind und beim Mitarbeiter angelangt sind, es nicht mehr nötig ist, weiter in diesem Ast zu suchen.
Lassen Sie uns in unsere Tabelle ein zusätzliches boolean-Feldeinführen, das uns sofort sagt, ob dieser spezifische Datensatz in unserem Baum ein „Knoten“ ist - das heißt, ob er überhaupt Nachkommen haben kann.
ÄNDERN SIE TABELLE hier
FÜGE SPALTE branch boolean HINZU;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
-- Anfrage erfolgreich ausgeführt: 3033 Zeilen in 42 ms geändert.Großartig! Es stellt sich heraus, dass wir nur etwas mehr als 30 % aller Elemente im Baum Nachkommen haben.
Jetzt wenden wir eine etwas andere Mechanik an – Verbindungen mit dem rekursiven Teil über LATERAL, was es uns ermöglicht, direkt auf die Felder der rekursiven „Tabelle“ zuzugreifen, und die Aggregatfunktion mit der Filterbedingung nach dem Knotenmerkmal verwenden wir, um die Schlüsselauswahl zu reduzieren:
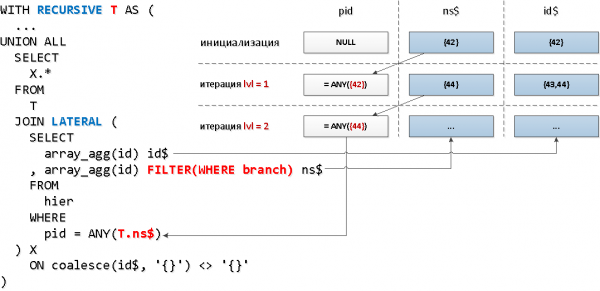
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') '{}'
)
SELECT
unnest(id$) id
FROM
T; 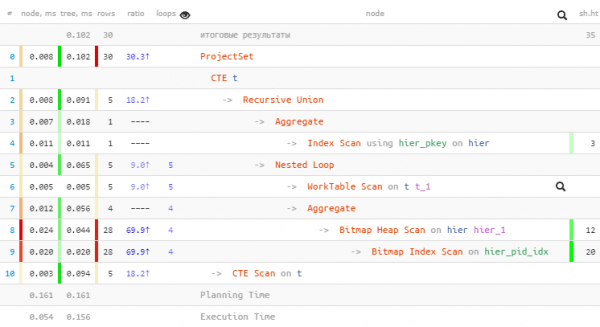
Wir konnten einen weiteren Zugriff auf den Index reduzieren und über 2 Mal bei der Menge gewonnen der gelesenen Daten.
#2. Вернемся к корням
Dieser Algorithmus ist nützlich, wenn Sie Aufzeichnungen für alle Elemente "nach oben im Baum" sammeln müssen, während Sie die Informationen beibehalten, welches Ausgangsblatt (und mit welchen Kennzahlen) zu dessen Aufnahme in die Auswahl geführt hat – zum Beispiel zur Erstellung eines konsolidierten Berichts mit Aggregation auf Knoten.
Das Folgende ist lediglich als Proof-of-Concept zu verstehen, da die Anfrage sehr umständlich wird. Wenn sie jedoch dominant in Ihrer Datenbank ist, sollten Sie darüber nachdenken, solche Methoden anzuwenden.
Lassen Sie uns mit ein paar einfachen Aussagen beginnen:
- Einen und dieselben Datensatz aus der Datenbank sollte man besser nur einmal lesen.
- Datensätze aus der Datenbank lesen sich effizienter "in Paketen", als einzeln.
Jetzt versuchen wir, die benötigte Abfrage zu konstruieren.
Schritt 1
Offensichtlich müssen wir bei der Initialisierung der Rekursion (wie könnte es anders sein!) die Aufzeichnungen der Blätter anhand der ursprünglichen Identifikatoren einlesen:
WITH RECURSIVE tree AS (
SELECT
rec -- dies ist der vollständige Datensatz der Tabelle
, id::text chld -- dies ist der "Satz" der ursprünglichen Blätter, die hierher geführt haben
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
... Falls jemand es seltsam fand, dass ein „Set“ als String und nicht als Array gespeichert wird, gibt es dafür eine einfache Erklärung. Für Strings gibt es eine integrierte aggregierende „Verkettungs“-Funktion string_agg, für Arrays jedoch nicht. Auch wenn sie .
Schritt 2
Nun möchten wir die IDs der Abschnitte ermitteln, die wir weiter bearbeiten müssen. Fast immer werden sie bei verschiedenen Einträgen des Ausgangssets dupliziert – daher sollten wir sie gruppieren, während wir die Informationen über die Quellblätter beibehalten.
Aber hier erwarten uns drei unangenehme Überraschungen:
- Der „unterrekursive“ Teil der Abfrage kann keine Aggregatfunktionen enthalten.
GROUP BY. - Der Zugriff auf die rekursive „Tabelle“ darf sich nicht in einer verschachtelten Unterabfrage befinden.
- Die Abfrage im rekursiven Teil darf keine CTE enthalten.
Glücklicherweise lassen sich all diese Probleme recht einfach umgehen. Fangen wir am Ende an.
CTEs im rekursiven Teil
So nicht funktioniert:
WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)Und so funktioniert es – die Klammern regeln das!
WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)Eine verschachtelte Abfrage zur rekursiven „Tabelle“
Hmm... Ein Verweis auf eine rekursive CTE kann nicht in einer verschachtelten Abfrage sein. Aber es kann innerhalb einer CTE sein! Und eine verschachtelte Abfrage kann bereits auf diese CTE zugreifen!
GROUP BY innerhalb der Rekursion
Das ist unangenehm, aber... Es gibt einen einfachen Weg, wie man GROUP BY mit Hilfe von DISTINCT ON und Fensterfunktionen simulieren kann!
SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1 -- funktioniert nicht!So funktioniert es allerdings!
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULLJetzt sehen wir, warum die numerische ID in Text umgewandelt wurde — damit sie durch Kommas verbunden werden konnten!
Schritt 3
Für das Finale bleibt uns nur noch wenig übrig:
- Wir lesen die "Abschnitte" nach einer Gruppe von IDs aus
- und ordnen die ausgelesenen Abschnitte den "Sätzen" der Ausgangsblätter zu
- "entpacken" die Zeilen-Sätze mit Hilfe von
unnest(string_to_array(chld, ',')::integer[])
MIT REKURSIVEN Baum ALS (
AUSWÄHLEN
rec
, id::text chld
AUS
hier rec
WO
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
VEREINIGEN ALLES
(
MIT prnt ALS (
AUSWÄHLEN DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') ÜBER(PARTITIONIEREN VON (rec).pid) chld
AUS
Baum
WO
(rec).pid IST NICHT NULL
)
, knoten ALS (
AUSWÄHLEN
rec
AUS
hier rec
WO
id = ANY(ARRAY(
AUSWÄHLEN
id
AUS
prnt
))
)
AUSWÄHLEN
knoten.rec
, prnt.chld
AUS
prnt
JOIN
knoten
ON (knoten.rec).id = prnt.id
)
)
AUSWÄHLEN
unnest(string_to_array(chld, ',')::integer[]) leaf
, (rec).*
AUS
Baum; 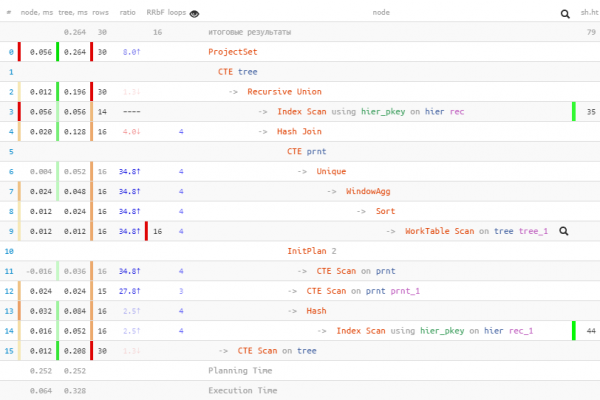
Quelle: habr.com
