

Es gibt gelegentlich die Notwendigkeit für Entwickler, eine Reihe von Parametern oder sogar eine gesamte Auswahl in die Anfrage zu übergeben. Manchmal findet man sehr seltsame Lösungen für dieses Problem.
Lass uns „von hinten“ beginnen und betrachten, was man vermeiden sollte, warum und wie es besser gemacht werden kann.
Die direkte „Einfügung“ von Werten in den Anfragekörper
sieht normalerweise ungefähr so aus:
query = "SELECT * FROM tbl WHERE id = " + value… oder so:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)Über diese Methode wurde viel gesagt, geschrieben und Es gibt ausreichend Informationen darüber:

Fast immer ist dies ein direkter Weg zu SQL-Injektionen und zusätzlicher Belastung der Geschäftslogik, die gezwungen ist, die Zeichenfolge Ihrer Anfrage „zusammenzukleben“.
Dieser Ansatz kann nur teilweise gerechtfertigt sein, wenn es notwendig ist, Partitionierung
in PostgreSQL 10 und früheren Versionen zu verwenden, um einen effizienteren Plan zu erhalten. In diesen Versionen wird die Liste der gescannten Partitionen noch ohne Berücksichtigung übergebener Parameter nur auf Grundlage des Anfragekörpers bestimmt.
Nutzung Platzhalter VORBEREITETEN ANFRAGEN
Variable Anzahl von Argumenten
Probleme werden auf uns warten, wenn wir eine vorher unbekannte Anzahl von Argumenten übergeben möchten:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...Wenn wir die Abfrage so belassen, werden wir zwar vor potenziellen Injektionen geschützt, aber wir müssen dennoch die Abfrage für jede Variante der Anzahl der Argumente zusammenführen/parsen. Das ist schon besser, als dies jedes Mal zu tun, aber wir können auch darauf verzichten.Es reicht aus, nur ein Parameter zu übergeben, der
die serialisierte Darstellung eines Arrays ... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}':
Der einzige Unterschied besteht darin, dass wir das Argument explizit in den erforderlichen Arraytyp umwandeln müssen. Aber das ist kein Problem, da wir bereits wissen, wohin wir adressieren.Übertragung von Auswahl (Matrix)
Normalerweise handelt es sich um verschiedene Möglichkeiten, Datensätze zur einmaligen Einfügung in die Datenbank zu übergeben:
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...Neben den oben beschriebenen Problemen mit der 'Neuzuweisung' der Abfrage kann dies auch zu Speichermangel und einem Serverabsturz führen. Der Grund ist einfach – die Argumente PG reservieren zusätzlichen Speicher, während die Anzahl der Datensätze nur durch die Anforderungen der Geschäftslogik begrenzt ist. In besonders kritischen Fällen haben wir gesehen, dass 'numerische' Argumente über $9000 nicht so gehandhabt werden sollten.
Lass uns die Abfrage umschreiben und dabei bereits eine 'zweistufige' Serialisierung:
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Ja, im Fall von 'komplexen' Werten innerhalb des Arrays müssen diese in Anführungszeichen gesetzt werden.
Es ist klar, dass auf diese Weise eine Auswahl mit einer beliebigen Anzahl von Feldern 'entfaltet' werden kann.
unnest, unnest, …
Gelegentlich gibt es Varianten, die anstelle eines 'Arrays von Arrays' mehrere 'Array-Spalten' übermitteln, von denen ich sprach. :
SELECT
unnest($1::text[]) k
, unnest($2::integer[]) v;Bei dieser Methode kann man leicht, wenn man bei der Generierung der Wertelisten für verschiedene Spalten einen Fehler macht, ganz unerwartete Ergebnisse erhalten, die auch von der Version des Servers abhängen:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |JSON
Bereits ab Version 9.3 hat PostgreSQL vollständige Funktionen zur Arbeit mit dem json-Typ eingeführt. Wenn Sie also die Eingabeparameter im Browser definieren, können Sie sie direkt dort erstellen. json-Objekt für SQL-Abfragen:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'Für frühere Versionen kann derselbe Ansatz verwendet werden für each(hstore), allerdings kann die korrekte „Verwaltung“ mit der Escape-Sequenzierung komplexer Objekte in hstore Probleme bereiten.
json_populate_recordset
Wenn Sie im Voraus wissen, dass die Daten aus dem „Eingangs“-json-Array zur Befüllung einer Tabelle verwendet werden, können Sie beim „Dereferenzieren“ der Felder und der Typkonvertierung erheblich sparen, indem Sie die Funktion json_populate_recordset verwenden:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);json_to_recordset
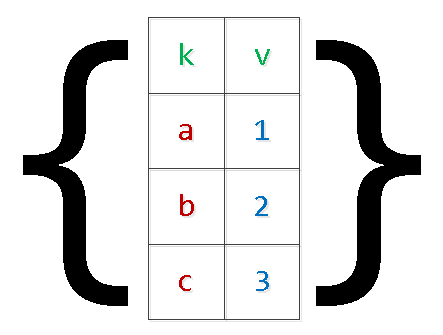
Diese Funktion „entrollt“ einfach das übergebene Array von Objekten in die Abfrage, ohne sich auf das Tabellenformat zu stützen:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2TEMPORARY TABLE
Wenn das Datenvolumen in der übertragenden Auswahl jedoch sehr groß ist, ist es schwierig und manchmal sogar unmöglich, es in einem einzigen serialisierten Parameter zu speichern, da dies einmalig eine große Menge an Speicherplatz benötigt. Beispielsweise müssen Sie lange einen großen Datensatz zu Ereignissen aus einem externen System sammeln und möchten ihn dann einmalig auf der Datenbankseite verarbeiten.
In diesem Fall ist die beste Lösung die Verwendung von :
CREATE TEMPORARY TABLE tbl(k text, v integer);
...
INSERT INTO tbl(k, v) VALUES($1, $2); -- viele, viele Male wiederholen
...
-- hier machen wir etwas Nützliches mit der gesamten Tabelle
Diese Methode ist besonders für die seltene Übertragung großer Volumina geeignet von Daten.
In Bezug auf die Beschreibung der Struktur Ihrer Daten unterscheidet sich eine temporäre Tabelle von einer "gewöhnlichen" nur durch ein Merkmal in der Systemtabelle pg_class, sondern in pg_type, pg_depend, pg_attribute, pg_attrdef, … — und sonst durch nichts.
Deshalb erzeugt eine solche Tabelle in Web-Systemen mit vielen kurzlebigen Verbindungen bei jeder Verbindung neue Systemeinträge, die mit der Schließung der Verbindung zur Datenbank gelöscht werden. Letztlich, Die unkontrollierte Nutzung von TEMP TABLE führt zu einer "Aufblähung" der Tabellen im pg_catalog und verlangsamt viele Operationen, die sie nutzen.
Natürlich lässt sich dem mit einem regelmäßigen VACUUM FULL über die Systemkatalogtabellen entgegenwirken.
Sitzungsvariablen
Angenommen, die Datenverarbeitung aus dem vorherigen Fall ist mit einem SQL-Befehl recht komplex, aber wir möchten sie häufig durchführen. Das heißt, wir möchten die prozedurale Verarbeitung in , aber die Datenübertragung über temporäre Tabellen wäre zu teuer.
Wir können auch keine $n-Parameter für die Übergabe an einen anonymen Block verwenden. Wir können jedoch auf Sitzungsvariablen und die Funktion current_setting.
bis zur Version 9.2 war es erforderlich, zuvor einen custom_variable_classes für „eigene“ Sitzungsvariablen zu konfigurieren. In den aktuellen Versionen kann man jedoch etwa so schreiben:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3In anderen unterstützten prozeduralen Sprachen kann man auch andere Lösungen finden.
Kennen Sie weitere Methoden? Teilen Sie sie in den Kommentaren mit!
Quelle: habr.com
