

Tausende von Vertriebsleitern im ganzen Land dokumentieren in täglich zehntausende Kontakte — Interaktionen mit potenziellen oder bereits bestehenden Kunden. Um diesen Kunden zu finden, muss man zuerst suchen, und das vorzugsweise sehr schnell. Dies erfolgt meist über den Namen.
Es ist also wenig überraschend, dass ich bei einer erneuten Analyse der "schweren" Anfragen in einer der am stärksten belasteten Datenbanken — unserem eigenen , "an der Spitze" eine Anfrage für die "schnelle" Suche nach Namen für die Unternehmensprofile entdeckte.
Darüber hinaus ergab eine weitere Untersuchung ein interessantes Beispiel zuerst der Optimierung, dann der Verschlechterung der Leistung der Anfrage durch die fortlaufende Bearbeitung vieler Teams, die alle nur das Beste wollten.
0: Was wollte der Benutzer?
 [КДПВ ]
[КДПВ ]
Was versteht der Benutzer normalerweise, wenn er von einer "schnellen" Suche nach Namen spricht? Es handelt sich in den seltensten Fällen um eine "ehrliche" Suche nach einem Teilstring wie ... LIKE '%Rose%' — denn dann erscheinen nicht nur 'Roselia' und 'Geschäft Rose', sondern auch 'DieRose' . Es ist sehr praktisch, wenn alles an einem Ort ist. Dadurch können unsere Spezialisten bei Problemen schnell helfen. 'Das Haus des Weihnachtsmannes'.
Der Benutzer geht im Alltagsleben davon aus, dass Sie ihm bereitwillig eine Suche am Anfang des Wortes anbieten im Titel und ihm relevantere Ergebnisse anzeigen, die mit "beginnt mit" dem eingegebenen Wort übereinstimmen. Und das tun Sie praktisch sofort — während der Eingabe.
1: Einschränkungen der Aufgabe
Und erst recht wird niemand bewusst 'rose shop' eingeben,damit Sie für jedes Wort nach einem Präfix suchen müssen. Nein, es ist viel einfacher für den Benutzer, auf den schnellen Vorschlag für das letzte Wort zu reagieren, als absichtlich "unvollständig" mit den vorherigen zu sein — schauen Sie, wie das jeder Suchmaschine funktioniert.
Im Allgemeinen der richtige sind die Anforderungen an die Aufgabe zu formulieren — mehr als die Hälfte der Lösung. Manchmal kann eine sorgfältige Analyse des Use Cases .
Was macht also der abstrakte Entwickler?
1.0: externe Suchmaschine
Oh, die Suche ist kompliziert, ich möchte mich damit überhaupt nicht beschäftigen — lassen Sie uns das DevOps-Team damit beauftragen! Lassen Sie sie uns ein externes Suchsystem auf Basis der Datenbank einrichten: Sphinx, ElasticSearch,…
Eine funktionale, wenn auch arbeitsintensive Lösung in Bezug auf Synchronisation und Aktualität. Doch in unserem Fall ist dies nicht nötig, da die Suche ausschließlich innerhalb der Daten jedes einzelnen Kontos erfolgt. Und die Daten sind stark veränderlich – selbst wenn der Manager jetzt einen Datensatz hinzugefügt hat, 'Rosenladen', kann es in 5-10 Sekunden sein, dass er sich daran erinnert, eine E-Mail-Adresse vergessen zu haben und diese finden und korrigieren möchte.
Deshalb – lassen Sie uns direkt in der Datenbank suchen. Zum Glück ermöglicht es uns PostgreSQL, dies zu tun, und nicht nur auf eine Weise – die werden wir auch betrachten.
1.1: „echte“ Teilzeichenfolge
Wir hängen uns an das Wort „Teilzeichenfolge“. Gerade für die indizierte Suche nach Teilzeichenfolgen (und sogar mittels regulärer Ausdrücke!) gibt es ein ausgezeichnetes ! Allerdings muss das Ergebnis dann richtig sortiert werden.
Lassen Sie uns zur Vereinfachung ein solches Modell verwenden:
CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);Wir laden 7,8 Millionen Datensätze realer Organisationen hoch und indizieren:
CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);Lassen Sie uns die ersten 10 Datensätze für die Teilzeichenfolgensuche finden:
WÄHLEN
*
VON
firmen
WO
lower(name) ~ ('(^|s)' || 'rоза')
BESTELLEN NACH
lower(name) ~ ('^' || 'rоза') DESC -- zuerst "anfangend mit"
, lower(name) -- der Rest alphabetisch
LIMIT 10;
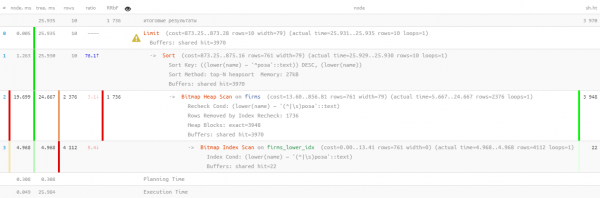
Naja, so ist das… 26ms, 31MB gelesene Daten und über 1,7K gefilterte Datensätze — für 10 Suchanfragen. Die Overheads sind zu groß, gibt es keine effizientere Möglichkeit?
1.2: Textsuche? Das ist doch FTS!
Tatsächlich bietet PostgreSQL eine sehr leistungsfähige (Full Text Search), einschließlich der Möglichkeit der Präfixsuche. Eine großartige Option, sogar ohne zusätzliche Erweiterungen! Lassen Sie uns das ausprobieren:
INDEX ERSTELLEN IN firmen USING gin(to_tsvector('simple'::regconfig, lower(name)));WÄHLEN
*
VON
firmen
WO
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', 'rоза:*')
BESTELLEN NACH
lower(name) ~ ('^' || 'rоза') DESC
, lower(name)
LIMIT 10; 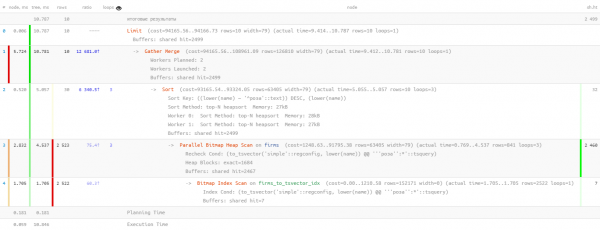
Hier hat uns die Parallelisierung der Abfrageausführung etwas geholfen, wodurch die Zeit auf 11msreduziert wurde. Und wir mussten auch 1,5-mal weniger lesen — insgesamt 20MB. Je weniger wir lesen, desto besser, denn je größer das Volumen, das wir durchlesen, desto höher ist die Wahrscheinlichkeit eines Cache-Misses, und jede zusätzlich vom Speicher gelesene Datenseite stellt potenzielle „Bremsen“ für die Abfrage dar.
1.3: Doch LIKE?
Jeder vorherige Vorschlag ist gut, aber wenn wir ihn hunderttausend Mal am Tag ausführen, wird das schon umfangreicher. 2 TB an gelesenen Daten. Im besten Fall erfolgt dies aus dem Speicher, aber wenn wir Pech haben, muss es sogar von der Festplatte kommen. Versuchen wir also, es kleiner zu machen.
Lassen Sie uns daran denken, dass der Benutzer zuerst sehen möchte die, die mit „…“ beginnen. Das ist doch ein klassischer Fall von mit Hilfe von text_pattern_ops! Und nur wenn uns bis zu 10 gefundene Datensätze „fehlen“, müssen wir sie mit FTS-Suche nachlesen:
CREATE INDEX ON firms(lower(name) text_pattern_ops);SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('rose' || '%')
LIMIT 10; 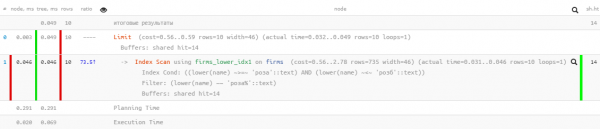
Ausgezeichnete Werte — nur 0,05 ms und etwas mehr als 100 KB gelesen! Nur wir haben die Sortierung nach Namen, vergessen, damit der Benutzer sich nicht in den Ergebnissen verliert:
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('rose' || '%')
ORDER BY
lower(name)
LIMIT 10; 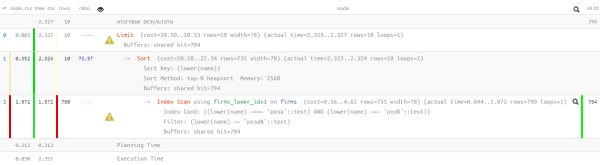
Oh, das sieht schon nicht mehr so schön aus — es gibt zwar einen Index, aber die Sortierung ignoriert ihn… Es ist natürlich schon um ein Vielfaches effizienter als die vorherige Variante, aber…
1.4: „mit Feile nachbessern“
Es gibt doch einen Index, der es ermöglicht, sowohl im Bereich zu suchen als auch die Sortierung ordentlich zu nutzen — ein normaler B-Baum!
CREATE INDEX ON firms(lower(name));Die Anfrage muss nur manuell erstellt werden:
SELECT
*
FROM
firms
WHERE
lower(name) >= 'rose' AND
lower(name) <= ('rose' || chr(65535)) -- für UTF8, für einbyteige - chr(255)
ORDER BY
lower(name)
LIMIT 10; 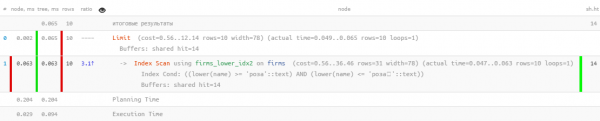
Ausgezeichnet – die Sortierung funktioniert und der Ressourcenverbrauch bleibt "mikroskopisch". tausendmal effizienter als "reines" FTS! Es bleibt, alles in eine Anfrage zu vereinen:
(
SELECT
*
FROM
firms
WHERE
lower(name) >= 'rose' AND
lower(name) <= ('rose' || chr(65535)) -- für UTF8, für einbyteige Kodierungen - chr(255)
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', 'rose:*') AND
lower(name) NOT LIKE ('rose' || '%') -- "beginnend mit" haben wir bereits oben gefunden
ORDER BY
lower(name) ~ ('^' || 'rose') DESC -- verwenden Sie dieselbe Sortierung, um NICHT den btree-Index zu verwenden
, lower(name)
LIMIT 10
)
LIMIT 10; Ich möchte darauf hinweisen, dass die zweite Unterabfrage nur ausgeführt wird wenn die erste weniger als erwartet zurückgibt zuletzt LIMIT Anzahl der Zeilen. Über diese Art der Abfrageoptimierung habe ich .
Ja, wir haben nun gleichzeitig einen btree und gin auf der Tabelle, trotzdem kam statistisch heraus, dass weniger als 10% der Abfragen die Ausführung des zweiten Blocks erreichen.. Das heißt, bei diesen typischen, im Voraus bekannten Einschränkungen für die Aufgabe konnten wir den gesamten Ressourcenverbrauch des Servers nahezu um das Tausendfache reduzieren!
1.5*: kommen wir ohne Feilen aus
Höher LIKE uns hat die falsche Sortierung behindert. Aber sie kann 'auf den richtigen Weg' gebracht werden durch die Angabe des USING-Operators:
Standardmäßig wird unterstellt
ASC. Darüber hinaus kann der Name eines spezifischen Sortieroperators in der Anweisung angegeben werdenUSING. Der Sortieroperator muss ein Mitglied der 'kleiner als' oder 'größer als' Familie von B-Baum-Operatoren sein.ASCentspricht normalerweiseUSING <undDESCentspricht normalerweiseUSING >.
In unserem Fall ist 'kleiner' das ~<~:
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('rose' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10; 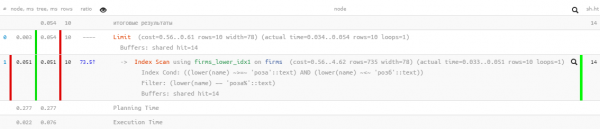
2: wie Anfragen 'verderben'
Jetzt lassen wir unsere Anfrage 'ziehen' ein halbes Jahr bis ein Jahr und stellen mit Erstaunen fest, dass sie wieder 'in den TOP' ist mit den Werten des gesamten täglichen 'Pufferns' des Speichers (buffers shared hit) bei 5.5TB — das heißt noch mehr, als es ursprünglich war.
Natürlich ist unser Geschäft gewachsen und die Last hat zugenommen, aber nicht so sehr! Das bedeutet, hier stimmt etwas nicht — lassen Sie uns das klären.
2.1: Geburt des Paging
Irgendwann hatte ein anderes Entwicklerteam den Wunsch, die Möglichkeit zu schaffen, aus der schnellen Zeilenansicht in das Register mit denselben, aber erweiterten Ergebnissen zu „springen“. Und welches Register kommt ohne Seitenavigation aus? Lassen Sie uns das hinzufügen!
( ... LIMIT + 10)
UNION ALL
( ... LIMIT + 10)
LIMIT 10 OFFSET ;Jetzt konnte der Entwickler ohne großen Aufwand das Suchergebnisregister mit einer Art „Seitenladung“ anzeigen.
Natürlich, tatsächlich, wird für jede nachfolgende Seite mehr und mehr Daten gelesen (alles von der letzten Anfrage, das wir weglassen, plus der benötigte „Rest“) – das ist also ein klares Antipattern. Besser wäre es, die Suche in der nächsten Iteration vom im Interface gespeicherten Schlüssel zu starten, aber dazu mehr ein anderes Mal.
2.2: der Wunsch nach Exotik
Irgendwann wünschte sich der Entwickler, die Ergebnismenge mit Daten aus einer anderen Tabelle zu variieren, wofür die gesamte vorherige Anfrage in eine CTE gesendet wurde:
WITH q AS (
...
LIMIT + 10
)
SELECT
*
, (SELECT ...) sub_query -- eine Abfrage zu der verknüpften Tabelle
FROM
q
LIMIT 10 OFFSET ;Und selbst so ist es nicht schlecht, da die geschachtelte Anfrage nur für 10 zurückgegebene Datensätze berechnet wird, wenn nicht…
2.3: DISTINCT ist sinnlos und erbarmungslos
Irgendwo im Verlauf dieser Evolution ging aus dem 2. Unterabfrage etwas verloren NOT LIKE Bedingung. Es ist klar, dass danach UNION ALL beginnt es damit, einige Datensätze doppelt zurückzugeben — zuerst gefunden durch den Anfang des Strings und dann noch einmal — durch den Anfang des ersten Wortes dieses Strings. Im Extremfall könnten alle Datensätze der 2. Unterabfrage mit den Datensätzen der ersten übereinstimmen.
Was macht der Entwickler, anstatt die Ursache zu suchen?.. Keine Frage!
- erweitern wir die Größe der ursprünglichen Stichproben
- wir wenden DISTINCT an, damit nur Einzelinstanzen jeder Zeile entstehen
WITH q AS (
( ... LIMIT + 10)
UNION ALL
( ... LIMIT + 10)
LIMIT + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET ;Das heißt, es ist klar, dass das Ergebnis letztlich genau dasselbe ist, aber die Chance, im 2. Unterabfrage CTE «durchzufallen», ist erheblich gestiegen, und ohne das, es wird offensichtlich mehr gelesen.
Aber das ist nicht das größte Problem. Da der Entwickler gebeten hat, nicht nach bestimmten, sondern nach allen Feldern auszuwählen DISTINCT Datensätze, werden automatisch auch das Feld sub_query — das Ergebnis der Unterabfrage — einbezogen. Jetzt, um dies auszuführen Aufzeichnungen, sodass das Feld sub_query — das Ergebnis der Unterabfrage — automatisch dorthin gelangt. Jetzt, um dies auszuführen DISTINCT, musste die Basis bereits erfüllen nicht 10 Unterabfragen, sondern alle + 10!
2.4: Kooperation steht über allem!
So lebten die Entwickler — sorglos, denn im Register fehlte es den Usern offensichtlich an Geduld, um N auf signifikante Werte zu „drehen“ angesichts der chronischen Verzögerungen beim Abrufen jeder nächsten „Seite“.
Bis Entwickler aus einer anderen Abteilung kamen und sich dazu entschlossen, diese praktische Methode zu nutzen für die iterative Suche – das bedeutet, wir nehmen einen Abschnitt aus einer Auswahl, filtern nach zusätzlichen Bedingungen, zeichnen das Ergebnis auf, dann den nächsten Abschnitt (was in unserem Fall durch die Erhöhung von N erreicht wird), und so weiter, bis der Bildschirm gefüllt ist.
Insgesamt erreichte N fast 17K , und innerhalb von 24 Stunden wurden „in Kette“ nicht weniger als 4K solcher Abfragen ausgeführt. Die letzten dieser wurden bereits mit1GB RAM bei jeder Iteration gescannt. Vollständige Heimautomatisierung im Neubau. Fortsetzung…
Gesamt

Quelle: habr.com
