

Seien Sie vorsichtig bei Operationen, die Buffers mit sich bringen …
Anhand einer kleinen Anfrage betrachten wir einige universelle Ansätze zur Optimierung von Anfragen in PostgreSQL. Ob Sie sie verwenden möchten oder nicht — das bleibt Ihnen überlassen, aber es ist gut, sie zu kennen.
In zukünftigen Versionen von PG könnte sich die Situation mit der 'Intelligenz' des Planers ändern, aber für 9.4/9.6 sieht es ungefähr gleich aus, wie die Beispiele hier zeigen.
Ich nehme eine vollkommen reale Anfrage:
SELECT
TRUE
FROM
"Dokument" d
INNER JOIN
"DokumentErweiterung" doc_ex
USING("@Dokument")
INNER JOIN
"DokumentTyp" t_doc ON
t_doc."@DokumentTyp" = d."DokumentTyp"
WHERE
(d."Leistung3" = 19091 or d."Mitarbeiter" = 19091) AND
d."$Entwurf" IS NULL AND
d."Gelöscht" IS NOT TRUE AND
doc_ex."Zustand"[1] IS TRUE AND
t_doc."DokumentTyp" = 'Arbeitsplan'
LIMIT 1; zu den Namen von Tabellen und FeldernZu 'russischen' Bezeichnungen für Felder und Tabellen kann man unterschiedlich stehen, aber das ist Geschmackssache. Da keine ausländischen Entwickler haben und PostgreSQL uns erlaubt, auch mit Hieroglyphen zu benennen, wenn sie in Anführungszeichen stehen, bevorzugen wir es, Objekte eindeutig verständlich zu benennen, um Missverständnisse zu vermeiden.
Schauen wir uns den resultierenden Plan an:
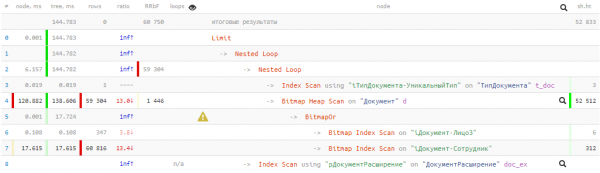
144 ms und fast 53K Buffers — das sind über 400 MB an Daten! Und wir haben Glück, wenn alle im Cache sind, wenn wir die Anfrage senden, sonst wird es beim Lesen von der Festplatte um ein Vielfaches länger.
Der Algorithmus ist das Wichtigste!
Um eine Anfrage zu optimieren, muss man zuerst verstehen, was sie überhaupt tun soll.
Lassen wir die Entwicklung der Datenbankstruktur vorerst außen vor und akzeptieren wir, dass wir relativ "günstig" die Anfrage umschreiben und/oder auf die Datenbank einige benötigte Indizes.
Also, die Anfrage:
— überprüft, ob es irgendein Dokument gibt
— im benötigten Zustand und bestimmter Art
— wo der Autor oder Ausführende der benötigte Mitarbeiter ist
JOIN + LIMIT 1
Häufig ist es für den Entwickler einfacher, eine Anfrage zu schreiben, bei der zuerst eine große Anzahl an Tabellen verbunden wird, und danach bleibt nur ein einziger Datensatz übrig. Aber einfacher für den Entwickler bedeutet nicht effektiver für die Datenbank.
In unserem Fall gab es nur 3 Tabellen – und welcher Effekt...
Lassen Sie uns zunächst die Verbindung zur Tabelle „TypDokument“ entfernen und der Datenbank mitteilen, dass der Eintragstyp bei uns einzigartig ist. (Das wissen wir, aber der Planer hat noch keine Ahnung):
WITH T AS (
SELECT
"@Dokumententyp"
FROM
"Dokumententyp"
WHERE
"Dokumententyp" = 'Arbeitsplan'
LIMIT 1
)
...
WHERE
d."Dokumententyp" = (TABELLE T)
...Ja, wenn die Tabelle/CTE aus einem einzigen Feld mit einer einzigen Zeile besteht, kann man in PG sogar so schreiben, anstatt
d."Dokumententyp" = (SELECT "@Dokumententyp" FROM T LIMIT 1)„Faule“ Berechnungen in PostgreSQL-Abfragen
BitmapOr vs UNION
In einigen Fällen wird uns der Bitmap Heap Scan sehr teuer zu stehen kommen — zum Beispiel in unserer Situation, wo eine beträchtliche Anzahl von Datensätzen unter die erforderliche Bedingung fällt. Das haben wir aufgrund von OR-Bedingungen, die sich in BitmapOr verwandelt haben-Operation im Plan.
Kehren wir zur ursprünglichen Aufgabe zurück — wir müssen den Datensatz finden, der dem entspricht irgendeinem der Bedingungen — das heißt, es ist nicht nötig, alle 59K Datensätze für beide Bedingungen zu durchsuchen. Es gibt einen Weg, eine Bedingung abzuarbeiten, und zum zweiten nur zu wechseln, wenn beim ersten nichts gefunden wurde.Uns hilft eine solche Konstruktion:
(
SELECT
...
LIMIT 1
)
UNION ALL
(
SELECT
...
LIMIT 1
)
LIMIT 1Das 'Externe' LIMIT 1 gewährleistet, dass die Suche mit dem ersten gefundenen Datensatz endet. Und wenn dieser bereits im ersten Block gefunden wird, wird die Ausführung des zweiten nicht erfolgen (wird niemals ausgeführt im Plan).
'Unter CASE verbergen' komplexe Bedingungen
Im ursprünglichen Abfrage gibt es einen äußerst unangenehmen Punkt – die Überprüfung des Zustands der verknüpften Tabelle 'DokumentErweiterung'. Unabhängig von der Richtigkeit der anderen Bedingungen im Ausdruck (zum Beispiel, d.'Entfernt' IST NICHT WAHR), wird diese Verbindung immer ausgeführt und 'verbraucht Ressourcen'. Mehr oder weniger werden verbraucht, hängt vom Umfang dieser Tabelle ab.
Es ist jedoch möglich, die Abfrage so zu modifizieren, dass die Suche nach dem verknüpften Datensatz nur dann erfolgt, wenn es tatsächlich notwendig ist:
SELECT
...
FROM
"Dokument" d
WHERE
... /*index cond*/ AND
CASE
WHEN "$Entwurf" IST NULL AND "Entfernt" IST NICHT WAHR THEN (
SELECT
"Zustand"[1] IST WAHR
FROM
"DokumentErweiterung"
WHERE
"@Dokument" = d."@Dokument"
)
END Da uns aus der verknüpften Tabelle keines der Felder für das Ergebnis benötigt wird, können wir den JOIN in eine Bedingung durch eine Unterabfrage verwandeln.
Lassen Sie die indizierbaren Felder im CASE «außen vor» und fügen Sie einfache Bedingungen in den WHEN-Block ein – jetzt wird die «schwere» Abfrage nur bei einem Übergang zu THEN ausgeführt.
Mein Nachname ist «Insgesamt»
Wir sammeln die resultierende Abfrage mit allen oben beschriebenen Mechanismen:
WITH T AS (
SELECT
"@Dokumenttyp"
FROM
"Dokumenttyp"
WHERE
"Dokumenttyp" = 'Arbeitsplan'
)
(
SELECT
TRUE
FROM
"Dokument" d
WHERE
("Person3", "Dokumenttyp") = (19091, (TABLE T)) AND
CASE
WHEN "$Entwurf" IS NULL AND "Gelöscht" IS NOT TRUE THEN (
SELECT
"Status"[1] IS TRUE
FROM
"Dokumenterweiterung"
WHERE
"@Dokument" = d."@Dokument"
)
END
LIMIT 1
)
UNION ALL
(
SELECT
TRUE
FROM
"Dokument" d
WHERE
("Dokumenttyp", "Mitarbeiter") = ((TABLE T), 19091) AND
CASE
WHEN "$Entwurf" IS NULL AND "Gelöscht" IS NOT TRUE THEN (
SELECT
"Status"[1] IS TRUE
FROM
"Dokumenterweiterung"
WHERE
"@Dokument" = d."@Dokument"
)
END
LIMIT 1
)
LIMIT 1;Passen Sie die Indizes an
Ein geübtes Auge hat bemerkt, dass die indizierbaren Bedingungen in den UNION-Teilblöcken geringfügig variieren – das liegt daran, dass wir bereits geeignete Indizes in der Tabelle haben. Falls nicht, wäre es ratsam, sie zu erstellen: Dokument(Gesicht3, Dokumententyp) und Dokument(Dokumententyp, Mitarbeiter).
über die Anordnung der Felder in ROW-BedingungenAus Sicht des Planers kann man natürlich auch schreiben (A, B) = (constA, constB), und (B, A) = (constB, constA). Aber bei der Aufnahme in der Reihenfolge der Felder im Index, ist eine solche Abfrage einfach leichter zu debuggen.
Was steht an?
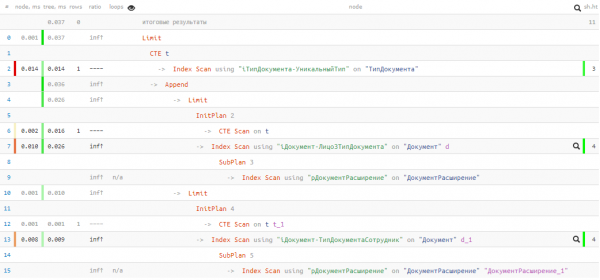
Leider hatten wir Pech, und im ersten UNION-Block wurde nichts gefunden, daher wurde der zweite tatsächlich ausgeführt. Selbst dabei — nur 0,037 ms und 11 Buffers!
Wir haben die Abfrage beschleunigt und die 'Datenübertragung' im Speicher um einige Tausend Mal reduziert, indem wir recht einfache Methoden verwendet haben — ein gutes Ergebnis bei wenig Copy-Paste. 🙂
Quelle: habr.com
