

Die Übersetzung des Artikels wurde speziell für die Studierenden des Kurses erstellt. .

In den letzten Wochen haben wir in ein binäres Streaming-Format aufgenommen und damit das bereits bestehende Format für Random Access/IPC ergänzt. Wir haben Implementierungen in Java und C++ sowie Bindungen für Python. In diesem Artikel erläutere ich, wie das Format funktioniert und zeige, wie man eine sehr hohe Datenübertragungsrate für DataFrames in pandas erreichen kann.
Streaming von Spalten-Daten
Eine häufige Frage, die ich von Arrow-Nutzern erhalte, betrifft die hohen Kosten für die Übertragung großer tabellarischer Datensätze von einem zeilen- oder aufzeichnungenorientierten Format in ein spaltenorientiertes Format. Bei mehrgigabyte großen Datensätzen kann das Transponieren im Speicher oder auf der Festplatte eine enorme Herausforderung darstellen.
Für das Streaming von Daten, unabhängig davon, ob die Ursprungsdaten zeilen- oder spaltenbasiert sind, besteht eine der Möglichkeiten darin, kleine Pakete von Zeilen zu senden, von denen jedes eine spaltenorientierte Anordnung enthält.
In Apache Arrow wird eine Kollektion von spaltenbasierten Arrays im Speicher, die einen Tabellenteil repräsentiert, als Record Batch bezeichnet. Um eine einheitliche Datenstruktur in Form einer logischen Tabelle darzustellen, können mehrere Record Batches zusammengeführt werden.
Im bestehenden Random-Access-Dateiformat schreiben wir Metadaten, die das Tabellenschema und die Positionen der Blöcke am Ende der Datei enthalten, was es Ihnen ermöglicht, jeden Record Batch oder jede Spalte aus dem Datensatz extrem kostengünstig auszuwählen. Im Streaming-Format senden wir eine Reihe von Nachrichten: das Schema, gefolgt von einem oder mehreren Record Batches.
Verschiedene Formate sehen ungefähr so aus, wie auf diesem Bild dargestellt:
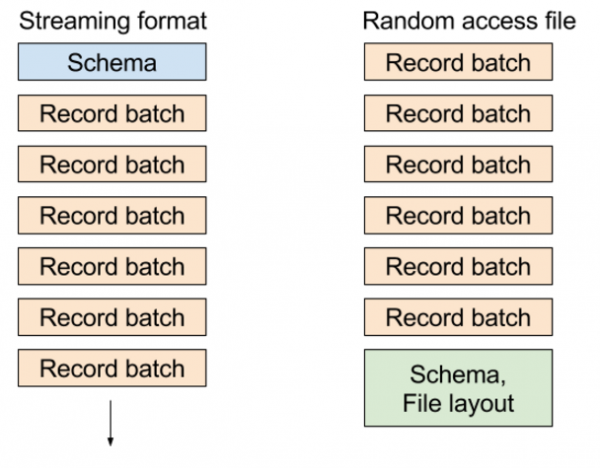
Datenstreaming in PyArrow: Anwendungen
Um Ihnen zu zeigen, wie das funktioniert, werde ich ein Beispiel-Dataset erstellen, das einen einzelnen Streaming-Chuck darstellt:
import time
import numpy as np
import pandas as pd
import pyarrow as pa
def generate_data(total_size, ncols):
nrows = int(total_size / ncols / np.dtype('float64').itemsize)
return pd.DataFrame({
'c' + str(i): np.random.randn(nrows)
for i in range(ncols)
}) Angenommen, wir möchten 1 GB Daten aufzeichnen, die aus 1 MB großen Chunks bestehen, insgesamt also 1024 Chunks. Zuerst erstellen wir einen Datenrahmen mit einer Größe von 1 MB und 16 Spalten:
KILOBYTE = 1 << 10
MEGABYTE = KILOBYTE * KILOBYTE
DATA_SIZE = 1024 * MEGABYTE
NCOLS = 16
df = generate_data(MEGABYTE, NCOLS) Dann konvertiere ich sie in pyarrow.RecordBatch:
batch = pa.RecordBatch.from_pandas(df) Jetzt erstelle ich einen Ausgabestrom, der in den Arbeitsspeicher schreibt und erstelle StreamWriter:
sink = pa.InMemoryOutputStream()
stream_writer = pa.StreamWriter(sink, batch.schema)Jetzt werden wir 1024 Chunks aufzeichnen, die insgesamt 1 GB an Datensatz ergeben:
for i in range(DATA_SIZE // MEGABYTE):
stream_writer.write_batch(batch)Da wir im RAM geschrieben haben, können wir den gesamten Stream in einem Puffer erhalten:
In [13]: source = sink.get_result()
In [14]: source
Out[14]:
In [15]: source.size
Out[15]: 1074750744 Da sich diese Daten im Speicher befinden, ist das Lesen von Arrow-Record-Paketen eine Zero-Copy-Operation. Ich öffne StreamReader und lese die Daten in pyarrow.Table, und konvertiere sie dann in DataFrame pandas:
In [16]: reader = pa.StreamReader(source)
In [17]: table = reader.read_all()
In [18]: table
Out[18]:
In [19]: df = table.to_pandas()
In [20]: df.memory_usage().sum()
Out[20]: 1073741904Das ist alles gut und schön, aber Sie haben vielleicht Fragen. Wie schnell passiert das? Wie wirkt sich die Chunk-Größe auf die Leistung beim Abrufen von DataFrames in pandas aus?
Leistung des Datenstreamings
Mit abnehmender Chunk-Größe steigen die Kosten für die Rekonstruktion eines kontinuierlichen DataFrame aus pandas aufgrund ineffizienter Cache-Zugriffsschemata. Es gibt auch einige Overhead-Kosten beim Arbeiten mit C++-Datenstrukturen, Arrays und deren Speicherm Puffern.
Für 1 MB, wie oben angegeben, erhält man auf meinem Laptop (Quad-Core Xeon E3-1505M):
In [20]: %timeit pa.StreamReader(source).read_all().to_pandas()
10 Schleifen, beste von 3: 129 ms pro SchleifeDas ergibt eine effektive Bandbreite von 7,75 Gb/s, um ein 1 GB DataFrame aus 1024 Chunks von 1 MB wiederherzustellen. Was passiert, wenn wir größere oder kleinere Chunks verwenden? Hier sind die Ergebnisse:
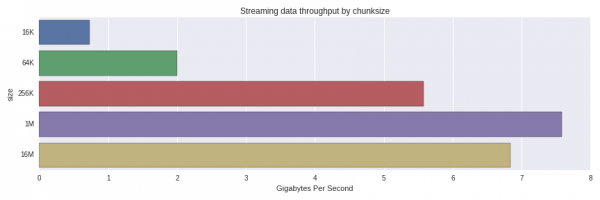
Die Leistung sinkt erheblich von 256K auf 64K Chunks. Es hat mich überrascht, dass 1 MB Chunks schneller verarbeitet wurden als 16 MB. Eine genauere Untersuchung wäre sinnvoll, um festzustellen, ob dies eine normale Verteilung ist oder ob noch andere Faktoren eine Rolle spielen.
In der aktuellen Implementierung des Formats werden die Daten grundsätzlich nicht komprimiert, weshalb die Größe im Speicher und "in den Leitungen" etwa gleich ist. In Zukunft könnte eine Kompression eine zusätzliche Option werden.
Zusammenfassung
Das Streaming von spaltenbasierten Daten kann eine effiziente Methode sein, um große Datensätze in spaltenorientierte Analysetools wie pandas zu übertragen, indem kleine Chunks verwendet werden. Datenservices, die auf zeilenorientierte Speicher zugreifen, können kleine Daten-Chunks übermitteln und transponieren, was für den L2- und L3-Cache Ihrer CPU vorteilhafter ist.
Vollständiger Code
import time
import numpy as np
import pandas as pd
import pyarrow as pa
def generate_data(total_size, ncols):
nrows = total_size / ncols / np.dtype('float64').itemsize
return pd.DataFrame({
'c' + str(i): np.random.randn(nrows)
for i in range(ncols)
})
KILOBYTE = 1 << 10
MEGABYTE = KILOBYTE * KILOBYTE
DATA_SIZE = 1024 * MEGABYTE
NCOLS = 16
def get_timing(f, niter):
start = time.clock_gettime(time.CLOCK_REALTIME)
for i in range(niter):
f()
return (time.clock_gettime(time.CLOCK_REALTIME) - start) / NITER
def read_as_dataframe(klass, source):
reader = klass(source)
table = reader.read_all()
return table.to_pandas()
NITER = 5
results = []
CHUNKSIZES = [16 * KILOBYTE, 64 * KILOBYTE, 256 * KILOBYTE, MEGABYTE, 16 * MEGABYTE]
for chunksize in CHUNKSIZES:
nchunks = DATA_SIZE // chunksize
batch = pa.RecordBatch.from_pandas(generate_data(chunksize, NCOLS))
sink = pa.InMemoryOutputStream()
stream_writer = pa.StreamWriter(sink, batch.schema)
for i in range(nchunks):
stream_writer.write_batch(batch)
source = sink.get_result()
elapsed = get_timing(lambda: read_as_dataframe(pa.StreamReader, source), NITER)
result = (chunksize, elapsed)
print(result)
results.append(result)Quelle: habr.com
