

Hallo zusammen, Freunde!
* Dieser Artikel basiert auf dem offenen Workshop von REBRAIN & Yandex.Cloud. Wenn Sie lieber ein Video ansehen möchten, finden Sie es unter diesem Link —
Kürzlich hatten wir die Gelegenheit, Yandex.Cloud live zu testen. Da wir lange und intensiv testen wollten, entschieden wir uns sofort gegen die Idee, einfach einen WordPress-Blog mit einer Cloud-Datenbank zu starten – das wäre zu langweilig gewesen. Nach einigem Überlegen entschieden wir uns, eine Art Produktionsarchitektur für einen Dienst zur Erfassung und Analyse von Ereignissen in nahezu Echtzeit einzurichten.
Ich bin mir absolut sicher, dass die überwiegende Mehrheit der Online-Geschäfte (und nicht nur) in irgendeiner Form eine Menge Informationen über ihre Nutzer und deren Handlungen sammelt. Mindestens ist das notwendig, um bestimmte Entscheidungen zu treffen – zum Beispiel, wenn Sie ein Online-Spiel verwalten: Sie können Statistiken einsehen, auf welchem Level die Nutzer am häufigsten stecken bleiben und Ihr Spiel deinstallieren. Oder warum Nutzer Ihre Website verlassen, ohne etwas zu kaufen (Hallo, Yandex.Metrica).
Also, hier ist unsere Geschichte: wie wir eine Anwendung in Golang entwickelt, Kafka, RabbitMQ und Yandex Queue Service getestet, Datenstreaming in ein Clickhouse-Cluster implementiert und die Daten mit Yandex Datalens visualisiert haben. Natürlich wurde das Ganze durch infrastrukturelle Highlights wie Docker, Terraform, GitLab CI und natürlich Prometheus ergänzt. Los geht's!
Zunächst möchte ich klarstellen, dass wir alles nicht in einem Rutsch einrichten können – dafür benötigen wir mehrere Artikel in dieser Reihe. Ein paar Worte zur Struktur:
Teil 1 (den Sie gerade lesen). Wir werden die Anforderungen und die Architektur der Lösung festlegen und eine Anwendung in Golang schreiben.
Teil 2. Wir bringen unsere Anwendung in die Produktion, machen sie skalierbar und testen die Last.
Teil 3. Wir versuchen zu verstehen, warum wir Nachrichten im Puffer und nicht in Dateien speichern sollten, und vergleichen Kafka, RabbitMQ und den Yandex Queue Service miteinander.
Teil 4. Wir werden ein Clickhouse-Cluster einrichten, das Streaming implementieren, um Daten aus dem Puffer dorthin zu verschieben, und die Visualisierung in Datalens konfigurieren.
Teil 5. Wir bringen die gesamte Infrastruktur in den richtigen Zustand – wir richten CI/CD mit GitLab CI ein und integrieren Monitoring und Service Discovery mit Prometheus und Consul.
Anforderungen
Zuerst formulieren wir das technische Lastenheft – was genau wir am Ende erhalten möchten.
- Wir möchten einen Endpoint in der Form von events.kis.im (kis.im – eine Testdomain, die wir in allen Artikeln verwenden werden), der Events über HTTPS empfangen soll.
- Events sind einfache JSON-Daten im Format: {"event": "view", "os": "linux", "browser": "chrome"}. In der finalen Phase werden wir einige zusätzliche Felder hinzufügen, aber das wird nicht von großer Bedeutung sein. Wer möchte, kann auch auf Protobuf umswitchen.
- Der Service sollte in der Lage sein, 10.000 Events pro Sekunde zu verarbeiten.
- Es sollte die Möglichkeit geben, horizontal zu skalieren – einfach durch Hinzufügen neuer Instanzen zu unserer Lösung. Es wäre auch vorteilhaft, wenn wir die Front-End-Komponente in verschiedene Geolokationen auslagern könnten, um die Latenz bei Kundenanfragen zu verringern.
- Ausfallsicherheit. Die Lösung muss stabil genug sein und in der Lage, den Ausfall einzelner Komponenten (bis zu einem bestimmten Maß, versteht sich) zu überstehen.
Architektur von
Für solche Aufgaben gibt es bereits bewährte Architekturen, die effektives Skalieren ermöglichen. Das Bild zeigt ein Beispiel unserer Lösung.
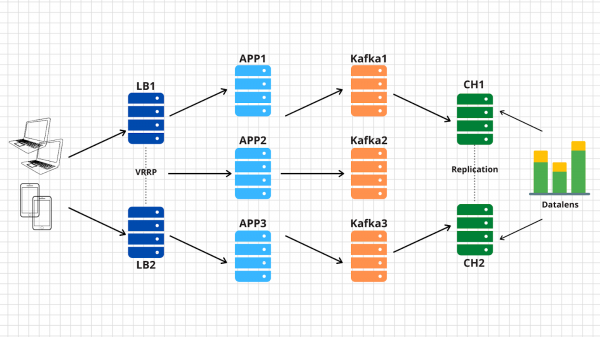
Also, was haben wir?
1. Auf der linken Seite sind unsere Geräte abgebildet, die verschiedene Ereignisse erzeugen, sei es das Erreichen von Leveln bei einem Spiel auf dem Smartphone oder das Erstellen einer Bestellung in einem Online-Shop über einen herkömmlichen Browser. Das Ereignis, wie in den Anforderungen beschrieben, ist ein einfaches JSON, das an unser Endpoint — events.kis.im — gesendet wird.
2. Die ersten beiden Server sind einfache Lastverteiler, deren Hauptaufgaben sind:
- Ständig verfügbar zu sein. Hierfür kann man beispielsweise keepalived nutzen, das die virtuelle IP im Falle von Problemen zwischen den Knoten umschaltet.
- TLS zu terminieren. Ja, die TLS-Terminierung werden wir genau auf diesen Servern durchführen. Erstens, um sicherzustellen, dass unsere Lösung den Anforderungen entspricht, und zweitens, um die Belastung durch das Einrichten einer verschlüsselten Verbindung von unseren Backend-Servern zu reduzieren.
- Eingehende Anfragen auf verfügbare Backend-Server zu balancieren. Das Schlüsselwort hier ist — verfügbar. Daraus ergibt sich, dass die Lastverteiler in der Lage sein müssen, unsere Server mit Anwendungen zu überwachen und den Datenverkehr nicht auf ausgefallene Knoten zu leiten.
3. Hinter unseren Load Balancern stehen Application-Server, auf denen eine recht einfache Anwendung läuft. Diese muss in der Lage sein, eingehende HTTP-Anfragen entgegenzunehmen, das empfangene JSON zu validieren und die Daten im Puffer zu speichern.
4. In der Diagramm fungiert Kafka als Puffer, wobei natürlich auch andere ähnliche Dienste auf diesem Niveau verwendet werden können. Kafka, RabbitMQ und YQS werden wir im dritten Artikel vergleichen.
5. Die vorletzte Station unserer Architektur ist ClickHouse – eine spaltenbasierte Datenbank, die es ermöglicht, riesige Datenmengen zu speichern und zu verarbeiten. Auf dieser Ebene müssen wir die Daten vom Puffer in das eigentliche Speichersystem übertragen (darüber wird im vierten Artikel geschrieben).
Dieses Schema erlaubt es uns, jede Schicht unabhängig horizontal zu skalieren. Haben die Backend-Server Schwierigkeiten – fügen wir zusätzliche hinzu, denn sie sind stateless Anwendungen, und das kann sogar automatisch erfolgen. Wenn der Puffer in Form von Kafka nicht ausreicht, fügen wir weitere Server hinzu und verteilen einige Partitionen unseres Topics darauf. Wenn ClickHouse nicht mithalten kann – das ist unmöglich 🙂, auch hier fügen wir Servers hinzu und sharden die Daten.
Übrigens, wenn Sie den optionalen Teil unseres Lastenhefts umsetzen möchten und eine Skalierung in verschiedenen Geolokationen vornehmen wollen, könnte es nicht einfacher sein:
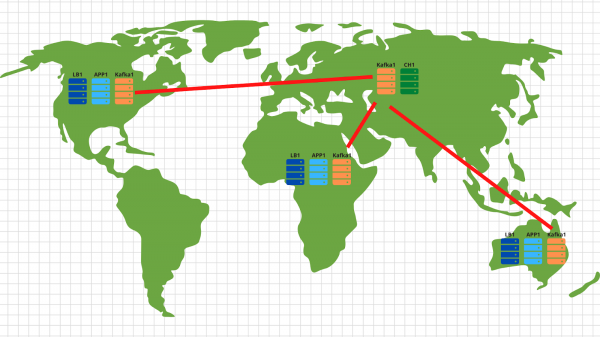
In jeder Geolokation setzen wir einen Load Balancer mit Anwendung und Kafka ein. Im Allgemeinen genügen 2 Anwendung-Server, 3 Kafka-Knoten und ein Cloud-Balancer, beispielsweise Cloudflare, der die Verfügbarkeit der Anwendungs-Knoten prüft und Anfragen geografisch basierend auf der ursprünglichen IP-Adresse des Kunden ausgleicht. So landen die von amerikanischen Kunden gesendeten Daten auf amerikanischen Servern, während die Daten aus Afrika auf afrikanischen Servern ankommen.
Anschließend wird es ganz einfach – wir verwenden das Mirror-Tool aus dem Kafka-Set und kopieren alle Daten aus den verschiedenen Standorten in unser zentrales Rechenzentrum, das sich in Russland befindet. Dort analysieren wir die Daten und speichern sie in Clickhouse zur späteren Visualisierung.
So, die Architektur ist geklärt – nun starten wir mit Yandex.Cloud!
Wir schreiben eine Anwendung
Bis wir zur Cloud gelangen, müssen wir zunächst etwas Geduld aufbringen und einen einfachen Service zur Verarbeitung eingehender Ereignisse entwickeln. Wir werden Golang verwenden, da es sich als hervorragende Sprache für die Erstellung von Netzwerkapplikationen bewährt hat.
Nach einer Stunde (vielleicht auch zwei) erhalten wir etwa Folgendes: .
Die wesentlichen Punkte, die hier hervorgehoben werden sollten:
1. Beim Start der Anwendung können zwei Flags angegeben werden. Eines steuert den Port, an dem wir eingehende HTTP-Anfragen abhören werden (-addr). Das zweite gibt die Adresse des Kafka-Servers an, zu dem wir unsere Ereignisse senden werden (-kafka):
addr = flag.String("addr", ":8080", "TCP-Adresse zum Abhören")
kafka = flag.String("kafka", "127.0.0.1:9092", "Kafka-Endpunkte")2. Die Anwendung verwendet die Bibliothek Sarama () zum Senden von Nachrichten an das Kafka-Cluster. Wir haben sofort Einstellungen vorgenommen, die auf maximale Verarbeitungsgeschwindigkeit ausgerichtet sind:
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForLocal
config.Producer.Compression = sarama.CompressionSnappy
config.Producer.Return.Successes = true3. Außerdem enthält unsere Anwendung einen Prometheus-Client, der verschiedene Metriken sammelt, wie:
- die Anzahl der Anfragen an unsere Anwendung;
- Anzahl der Fehler bei der Anfrageverarbeitung (POST-Anfrage kann nicht gelesen werden, beschädigtes JSON, kann nicht in Kafka schreiben);
- Verarbeitungszeit einer Anfrage vom Kunden, einschließlich der Zeit, die benötigt wird, um die Nachricht in Kafka zu schreiben.
4. Drei Endpunkte, die unsere Anwendung verarbeitet:
- /status — просто возвращаем ok, чтобы показать, что мы живы. Хотя можно и добавить некоторые проверки, типа доступности кафка кластера.
- /metrics — по этому url prometheus client будет возвращать собранные им метрики.
- /post — основной endpoint, куда будут приходить POST запросы с json внутри. Наше приложение проверяет json на валидность и если все ок — записывает данные в кафка-кластер.
Ich möchte anmerken, dass der Code nicht perfekt ist – er kann (und sollte!) verbessert werden. Zum Beispiel könnte man auf die Verwendung des integrierten net/http verzichten und auf das schnellere fasthttp umsteigen. Oder man könnte die Verarbeitungszeit und CPU-Ressourcen einsparen, indem man die Gültigkeitsprüfung von JSON auf einen späteren Zeitpunkt verschiebt – wenn die Daten aus dem Puffer in das ClickHouse-Cluster überführt werden.
Neben der Entwicklung haben wir auch sofort an unsere zukünftige Infrastruktur gedacht und entschieden, unsere Anwendung über Docker einzurichten. Das endgültige Dockerfile für den Aufbau der Anwendung ist – . Insgesamt ist es relativ einfach, der einzige Punkt, auf den ich hinweisen möchte, ist der Multistage-Build, der es ermöglicht, das endgültige Image unseres Containers zu verkleinern.
Die ersten Schritte in der Cloud
Zunächst registrieren wir uns bei . Nachdem Sie alle erforderlichen Felder ausgefüllt haben, wird ein Konto für Sie erstellt und Sie erhalten ein Guthaben in Höhe eines bestimmten Betrags, das Sie zur Testung der Cloud-Dienste verwenden können. Wenn Sie alle Schritte aus unserem Artikel wiederholen möchten, sollte dieses Guthaben ausreichen.
Nach der Registrierung wird Ihnen eine separate Cloud und ein Standardkatalog erstellt, in dem Sie mit der Erstellung von Cloud-Ressourcen beginnen können. Im Allgemeinen sieht die Ressourcenkonfiguration in Yandex.Cloud folgendermaßen aus:
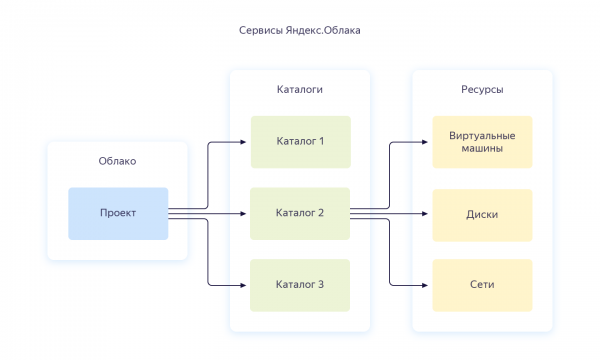
Mit einem Konto können Sie mehrere Clouds erstellen. Innerhalb der Cloud können verschiedene Kataloge für verschiedene Unternehmensprojekte angelegt werden. Genaueres dazu finden Sie in der Dokumentation — . Übrigens werde ich im weiteren Verlauf oft darauf verweisen. Als ich die gesamte Infrastruktur von Grund auf neu einrichtete, hat mir die Dokumentation mehr als einmal geholfen, daher empfehle ich, sie zu studieren.
Zur Verwaltung der Cloud können sowohl das Web-Interface als auch das Konsolen-Tool — yc verwendet werden. Die Installation erfolgt mit einem einzigen Befehl (für Linux und Mac OS):
curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bashWenn Ihr interner Sicherheitsexperte Bedenken wegen des Ausführens von Skripten aus dem Internet hat, können Sie zunächst das Skript öffnen und lesen. Zweitens führen wir es unter unserem eigenen Benutzer aus — ohne Root-Rechte.
Wenn Sie einen Client für Windows installieren möchten, können Sie die Anleitung verwenden. und dann yc init, um es vollständig einzurichten:
vozerov@mba:~ $ yc init
Willkommen! Dieser Befehl führt Sie durch den Konfigurationsprozess.
Bitte gehen Sie zu https://oauth.yandex.ru/authorize?response_type=token&client_id= um ein OAuth-Token zu erhalten.
Bitte geben Sie das OAuth-Token ein:
Bitte wählen Sie die zu verwendende Cloud aus:
[1] cloud-b1gv67ihgfu3bp (id = b1gv67ihgfu3bpt24o0q)
[2] fevlake-cloud (id = b1g6bvup3toribomnh30)
Bitte geben Sie Ihre numerische Auswahl ein: 2
Ihre aktuelle Cloud wurde auf 'fevlake-cloud' (id = b1g6bvup3toribomnh30) gesetzt.
Bitte wählen Sie den Ordner aus, den Sie verwenden möchten:
[1] default (id = b1g5r6h11knotfr8vjp7)
[2] Neuen Ordner erstellen
Bitte geben Sie Ihre numerische Auswahl ein: 1
Ihr aktueller Ordner wurde auf 'default' (id = b1g5r6h11knotfr8vjp7) gesetzt.
Möchten Sie eine Standard-Computing-Zone konfigurieren? [Y/n]
Welche Zone möchten Sie als Standard für das Profil verwenden?
[1] ru-central1-a
[2] ru-central1-b
[3] ru-central1-c
[4] Keine Standardzone festlegen
Bitte geben Sie Ihre numerische Auswahl ein: 1
Ihre standardmäßige Computing-Zone wurde auf 'ru-central1-a' gesetzt.
vozerov@mba:~ $Im Grunde genommen ist der Prozess nicht kompliziert — zuerst müssen Sie ein OAuth-Token für die Verwaltung der Cloud erhalten, dann die Cloud und den Ordner auswählen, den Sie verwenden möchten.
Wenn Sie mehrere Konten oder Ordner innerhalb eines Clouds haben, können Sie zusätzliche Profile mit separaten Einstellungen über yc config profile create erstellen und zwischen diesen wechseln.
Neben den oben genannten Methoden hat das Yandex.Cloud-Team ein sehr gutes zur Verwaltung von Cloud-Ressourcen entwickelt. Von meiner Seite habe ich ein Git-Repository vorbereitet, in dem ich alle Ressourcen beschrieben habe, die im Rahmen des Artikels erstellt werden — . Uns interessiert der Master-Zweig, lassen Sie uns diesen lokal klonen:
vozerov@mba:~ $ git clone https://github.com/rebrainme/yandex-cloud-events/ events
Klonen in 'events'...
remote: Objekte werden aufgelistet: 100, erledigt.
remote: Objekte zählen: 100% (100/100), erledigt.
remote: Objekte komprimieren: 100% (68/68), erledigt.
remote: Insgesamt 100 (Delta 37), 89 (Delta 26) erneut verwendet, pack-reused 0
Objekte empfangen: 100% (100/100), 25.65 KiB | 168.00 KiB/s, erledigt.
Deltas auflösen: 100% (37/37), erledigt.
vozerov@mba:~ $ cd events/terraform/Alle Hauptvariablen, die in Terraform verwendet werden, sind in der Datei main.tf aufgeführt. Für den Start erstellen wir in dem Ordner terraform die Datei private.auto.tfvars mit folgendem Inhalt:
# Yandex Cloud Oauth token
yc_token = ""
# Yandex Cloud ID
yc_cloud_id = ""
# Yandex Cloud folder ID
yc_folder_id = ""
# Default Yandex Cloud Region
yc_region = "ru-central1-a"
# Cloudflare email
cf_email = ""
# Cloudflare token
cf_token = ""
# Cloudflare zone id
cf_zone_id = ""Alle Variablen können aus yc config list entnommen werden, da wir das Konsolenprogramm bereits eingerichtet haben. Ich empfehle, private.auto.tfvars sofort in .gitignore aufzunehmen, um versehentlich nicht private Daten zu veröffentlichen.
In der Datei private.auto.tfvars haben wir auch die Daten von Cloudflare angegeben – zur Erstellung von DNS-Einträgen und zur Proxyierung der Hauptdomain events.kis.im auf unsere Server. Wenn Sie Cloudflare nicht verwenden möchten, entfernen Sie die Initialisierung des Cloudflare-Anbieters in main.tf sowie die Datei dns.tf, die für die Erstellung der benötigten DNS-Einträge verantwortlich ist.
In unserer Arbeit werden wir alle drei Methoden kombinieren – sowohl die Web-Oberfläche, die Konsolenanwendung als auch Terraform.
Virtuelle Netzwerke
Ehrlich gesagt könnte man diesen Schritt auch überspringen, da beim Erstellen einer neuen Cloud automatisch ein separates Netzwerk und drei Subnetze – eines für jede Verfügbarkeitszone – angelegt werden. Dennoch möchten wir für unser Projekt ein separates Netzwerk mit eigener Adressierung schaffen. Das allgemeine Netzwerkschema in Yandex.Cloud ist im folgenden Bild dargestellt (ehrlich gesagt entnommen von )
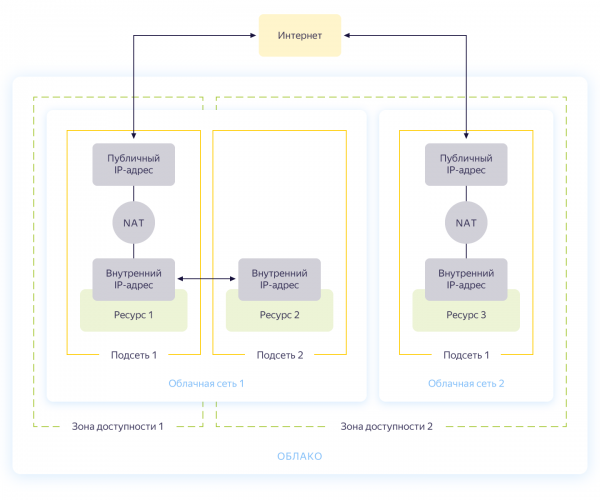
Sie erstellen also ein gemeinsames Netzwerk, innerhalb dessen Ressourcen miteinander kommunizieren können. Für jede Verfügbarkeitszone wird einSubnetz mit seiner eigenen Adressierung eingerichtet und mit dem gemeinsamen Netzwerk verbunden. Auf diese Weise können alle Cloud-Ressourcen innerhalb des Netzwerks kommunizieren, selbst wenn sie sich in unterschiedlichen Verfügbarkeitszonen befinden. Ressourcen, die mit verschiedenen Cloud-Netzwerken verbunden sind, können sich nur über externe Adressen sehen. Übrigens, wie dieser Prozess im Inneren funktioniert, .
Die Erstellung des Netzwerks ist in der Datei network.tf im Repository beschrieben. Dort erstellen wir ein gemeinsames privates Netzwerk internal und verbinden es mit drei Subnetzen in verschiedenen Verfügbarkeitszonen – internal-a (172.16.1.0/24), internal-b (172.16.2.0/24), internal-c (172.16.3.0/24).
Wir initialisieren Terraform und erstellen die Netzwerke:
vozerov@mba:~/events/terraform (master) $ terraform init
... übersprungen ...
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_vpc_subnet.internal-a -target yandex_vpc_subnet.internal-b -target yandex_vpc_subnet.internal-c
... übersprungen ...
Plan: 4 hinzuzufügende, 0 zu ändernde, 0 zu zerstörende.
Möchten Sie diese Aktionen ausführen?
Terraform wird die oben beschriebenen Aktionen ausführen.
Nur 'ja' wird akzeptiert, um die Genehmigung zu erteilen.
Geben Sie einen Wert ein: ja
yandex_vpc_network.internal: Erstelle...
yandex_vpc_network.internal: Erstellung abgeschlossen nach 3s [id=enp2g2rhile7gbqlbrkr]
yandex_vpc_subnet.internal-a: Erstelle...
yandex_vpc_subnet.internal-b: Erstelle...
yandex_vpc_subnet.internal-c: Erstelle...
yandex_vpc_subnet.internal-a: Erstellung abgeschlossen nach 6s [id=e9b1dad6mgoj2v4funog]
yandex_vpc_subnet.internal-b: Erstellung abgeschlossen nach 7s [id=e2liv5i4amu52p64ac9p]
yandex_vpc_subnet.internal-c: Noch in der Erstellung... [10s vergangen]
yandex_vpc_subnet.internal-c: Erstellung abgeschlossen nach 10s [id=b0c2qhsj2vranoc9vhcq]
Anwendung abgeschlossen! Ressourcen: 4 hinzugefügt, 0 geändert, 0 zerstört.Ausgezeichnet! Wir haben unser Netzwerk erstellt und sind nun bereit, unsere internen Dienste zu erstellen.
Erstellung virtueller Maschinen
Für die Testung der Anwendung werden zwei virtuelle Maschinen ausreichen – die erste benötigen wir zum Builden und Starten der Anwendung, die zweite für die Ausführung von Kafka, die wir zur Speicherung eingehender Nachrichten verwenden werden. Zusätzlich erstellen wir noch eine Maschine, auf der wir Prometheus zur Überwachung der Anwendung einrichten.
Die virtuellen Maschinen werden mit Ansible konfiguriert. Stellen Sie daher vor dem Start von Terraform sicher, dass Sie eine der neuesten Ansible-Versionen installiert haben. Installieren Sie auch die erforderlichen Rollen mit Ansible Galaxy:
vozerov@mba:~/events/terraform (master) $ cd ../ansible/
vozerov@mba:~/events/ansible (master) $ ansible-galaxy install -r requirements.yml
- cloudalchemy-prometheus (master) ist bereits installiert, wird übersprungen.
- cloudalchemy-grafana (master) ist bereits installiert, wird übersprungen.
- sansible.kafka (master) ist bereits installiert, wird übersprungen.
- sansible.zookeeper (master) ist bereits installiert, wird übersprungen.
- geerlingguy.docker (master) ist bereits installiert, wird übersprungen.
vozerov@mba:~/events/ansible (master) $Im Ansible-Ordner befindet sich ein Beispiel für die Konfigurationsdatei .ansible.cfg, die ich verwende. Das könnte nützlich sein.
Bevor Sie virtuelle Maschinen erstellen, stellen Sie sicher, dass der SSH-Agent läuft und Ihr SSH-Schlüssel hinzugefügt wurde, da Terraform sonst keine Verbindung zu den erstellten Maschinen herstellen kann. Ich bin natürlich auf einen Bug in OS X gestoßen: . Um ähnliche Probleme zu vermeiden, fügen Sie vor dem Start von Terraform eine kleine Variable in die Umgebungsvariablen ein:
vozerov@mba:~/events/terraform (master) $ export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YESIm Terraform-Ordner erstellen wir die erforderlichen Ressourcen:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_compute_instance.build -target yandex_compute_instance.monitoring -target yandex_compute_instance.kafka
yandex_vpc_network.internal: Aktualisiere den Zustand... [id=enp2g2rhile7gbqlbrkr]
data.yandex_compute_image.ubuntu_image: Aktualisiere den Zustand...
yandex_vpc_subnet.internal-a: Aktualisiere den Zustand... [id=e9b1dad6mgoj2v4funog]
Ein Ausführungsplan wurde erstellt und wird unten angezeigt.
Ressourcenschritte sind mit folgenden Symbolen angezeigt:
+ erstellen
... übersprungen ...
Plan: 3 hinzuzufügen, 0 zu ändern, 0 zu zerstören.
... übersprungen ...Wenn alles erfolgreich war (was der Fall sein sollte), haben wir drei virtuelle Maschinen:
- build — die Maschine für das Testen und Erstellen der Anwendung. Docker wurde automatisch durch Ansible installiert.
- monitoring — die Maschine für das Monitoring — hier sind Prometheus & Grafana installiert. Login / Passwort ist standardmäßig: admin / admin
- kafka — eine kleine Maschine mit installiertem Kafka, erreichbar über Port 9092.
Lassen Sie uns sicherstellen, dass alle vorhanden sind:
vozerov@mba:~/events (master) $ yc compute instance list
+----------------------+------------+---------------+---------+---------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+------------+---------------+---------+---------------+-------------+
| fhm081u8bkbqf1pa5kgj | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.35 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+------------+---------------+---------+---------------+-------------+ Die Ressourcen sind vorhanden, und wir können ihre IP-Adressen abrufen. Nachfolgend werde ich die IP-Adressen für die SSH-Verbindung und Testanwendungen verwenden. Wenn Sie ein Cloudflare-Konto haben, das mit Terraform verbunden ist, können Sie die neu erstellten DNS-Namen problemlos nutzen.
Übrigens erhält die virtuelle Maschine eine interne IP und einen internen DNS-Namen, sodass Sie innerhalb des Netzwerks auf die Server über ihre Namen zugreifen können:
ubuntu@build:~$ ping kafka.ru-central1.internal
PING kafka.ru-central1.internal (172.16.1.31) 56(84) bytes of data.
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=1 ttl=63 time=1.23 ms
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=2 ttl=63 time=0.625 ms
^C
--- kafka.ru-central1.internal ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.625/0.931/1.238/0.308 msDas wird nützlich sein, um der Anwendung den Endpoint für Kafka anzugeben.
Die Anwendung erstellen
Prima, die Server sind bereit, die Anwendung ist da – jetzt müssen wir sie nur noch erstellen und veröffentlichen. Dafür verwenden wir den herkömmlichen Docker-Befehl 'docker build', und als Speicher für die Images nutzen wir den Service von Yandex – den Container-Registry. Aber alles der Reihe nach.
Wir kopieren die Anwendung auf die Build-Maschine, loggen uns per SSH ein und erstellen das Image:
vozerov@mba:~/events/terraform (master) $ cd ..
vozerov@mba:~/events (master) $ rsync -av app/ ubuntu@84.201.132.3:app/
... übersprungen ...
Gesendet 3849 Bytes empfangen 70 Bytes 7838.00 Bytes/sec
Gesamtgröße ist 3644 Beschleunigung ist 0.93
vozerov@mba:~/events (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cd app
ubuntu@build:~/app$ sudo docker build -t app .
Sende Build-Kontext an Docker-Daemon 6.144kB
Schritt 1/9 : FROM golang:latest AS build
... übersprungen ...
Erfolgreich gebaut 9760afd8ef65
Erfolgreich getaggt app:latestDie Hälfte ist geschafft – jetzt können wir die Funktionsfähigkeit unserer Anwendung überprüfen, indem wir sie starten und an Kafka senden:
ubuntu@build:~/app$ sudo docker run --name app -d -p 8080:8080 app /app/app -kafka=kafka.ru-central1.internal:9092Von der lokalen Maschine aus kann ein Test-Event gesendet werden, um die Antwort zu überprüfen:vozerov@mba:~/events (master) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://84.201.132.3:8080/post HTTP/1.1 200 OK Content-Type: application/json Date: Mon, 13 Apr 2020 13:53:54 GMT Content-Length: 41 {"status":"ok","partition":0,"Offset":0} vozerov@mba:~/events (master) $
Die Anwendung hat erfolgreich gespeichert und die ID der Partition sowie den Offset angegeben, in den die Nachricht gelangte. Jetzt bleibt nur noch, ein Registry im Yandex.Cloud zu erstellen und unser Image dorthin hochzuladen (wie dies in drei Zeilen im registry.tf-Datei beschrieben ist). Wir erstellen den Speicher:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_container_registry.events
... übersprungen ...
Plan: 1 hinzuzufügen, 0 zu ändern, 0 zu löschen.
... übersprungen ...
Anwendung abgeschlossen! Ressourcen: 1 hinzugefügt, 0 geändert, 0 gelöscht.Es gibt mehrere Möglichkeiten zur Authentifizierung im Container-Registry – mittels OAuth-Token, IAM-Token oder Schlüssel des Dienstkontos. Mehr zu diesen Methoden finden Sie in der Dokumentation. . Wir werden den Schlüssel des Dienstkontos verwenden, also erstellen wir zunächst ein Konto:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_iam_service_account.docker -target yandex_resourcemanager_folder_iam_binding.puller -target yandex_resourcemanager_folder_iam_binding.pusher
... übersprungen ...
Anwendung abgeschlossen! Ressourcen: 3 hinzugefügt, 0 geändert, 0 gelöscht.Jetzt müssen wir einen Schlüssel dafür erstellen:
vozerov@mba:~/events/terraform (master) $ yc iam key create --service-account-name docker -o key.json
id: ajej8a06kdfbehbrh91p
service_account_id: ajep6d38k895srp9osij
created_at: "2020-04-13T14:00:30Z"
key_algorithm: RSA_2048Wir erhalten Informationen über die ID unseres Speichers, übertragen den Schlüssel und authentifizieren uns:
vozerov@mba:~/events/terraform (master) $ scp key.json ubuntu@84.201.132.3:
key.json 100% 2392 215.1KB/s 00:00
vozerov@mba:~/events/terraform (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cat key.json | sudo docker login --username json_key --password-stdin cr.yandex
WARNUNG! Ihr Passwort wird unverschlüsselt in /home/ubuntu/.docker/config.json gespeichert.
Konfigurieren Sie einen Credential Helper, um diese Warnung zu beseitigen. Siehe
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Anmeldung erfolgreich
ubuntu@build:~$Um das Image in das Repository hochzuladen, benötigen wir die ID des Container-Registrys, die wir mit dem Tool yc abrufen:
vozerov@mba:~ $ yc container registry get events
id: crpdgj6c9umdhgaqjfmm
folder_id:
name: events
status: AKTIV
created_at: "2020-04-13T13:56:41.914Z"Danach taggen wir unser Image mit einem neuen Namen und laden es hoch:
ubuntu@build:~$ sudo docker tag app cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
ubuntu@build:~$ sudo docker push cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
Der Push bezieht sich auf das Repository [cr.yandex/crpdgj6c9umdhgaqjfmm/events]
8c286e154c6e: Hochgeladen
477c318b05cb: Hochgeladen
beee9f30bc1f: Hochgeladen
v1: Digest: sha256:1dd5aaa9dbdde2f60d833be0bed1c352724be3ea3158bcac3cdee41d47c5e380 Größe: 946Wir können uns vergewissern, dass das Image erfolgreich hochgeladen wurde:
vozerov@mba:~/events/terraform (master) $ yc container repository list
+----------------------+-----------------------------+
| ID | NAME |
+----------------------+-----------------------------+
| crpe8mqtrgmuq07accvn | crpdgj6c9umdhgaqjfmm/events |
+----------------------+-----------------------------+Übrigens, wenn Sie das yc-Tool auf einer Linux-Maschine installieren, können Sie den Befehl verwenden
yc container registry configure-dockerum Docker einzurichten.
Fazit
Wir haben viel harte Arbeit geleistet und das Ergebnis ist:
- Wir haben die Architektur unseres zukünftigen Services entworfen.
- Wir haben eine Anwendung in Golang geschrieben, die unsere Geschäftslogik umsetzt.
- Wir haben sie gesammelt und in ein privates Container-Registry gepackt.
Im nächsten Teil gehen wir zu dem Interessanten über — wir bringen unsere Anwendung in die Produktion und testen die Belastung. Bleiben Sie dran!
Dieses Material ist in der Videoaufzeichnung des offenen Praktikums REBRAIN & Yandex.Cloud verfügbar: Wir nehmen 10.000 Anfragen pro Sekunde auf Yandex Cloud entgegen —
Wenn Sie interessiert sind, an solchen Online-Veranstaltungen teilzunehmen und Fragen in Echtzeit zu stellen, schließen Sie sich unserem.
Ein besonderes Dankeschön möchten wir Yandex.Cloud für die Möglichkeit aussprechen, eine solche Veranstaltung durchzuführen. Hier ist der Link zu ihnen —
Wenn Sie einen Umzug in die Cloud benötigen oder Fragen zu Ihrer Infrastruktur haben, .
P.S. Wir haben zwei kostenlose Audits pro Monat, vielleicht ist gerade Ihr Projekt dabei.
Quelle: habr.com
