

Hinweis zur Übersetzung: Dies ist eine Übersetzung eines öffentlichen Post-Mortems aus dem Ingenieurbereich von Preply. . Darin wird ein Problem mit conntrack in einem Kubernetes-Cluster beschrieben, das zu teilweisen Ausfällen einiger Produktionsdienste führte.
Dieser Artikel könnte hilfreich sein für diejenigen, die mehr über Post-Mortems erfahren möchten oder potenzielle DNS-Probleme in der Zukunft vermeiden möchten.

Das ist nicht DNS.
Es kann nicht DNS sein.
Es war DNS.
Ein wenig über Post-Mortems und Prozesse bei Preply.
Das Post-Mortem beschreibt einen Ausfall oder ein Ereignis in der Produktion. Das Post-Mortem enthält eine Chronologie der Ereignisse, eine Beschreibung der Auswirkungen auf die Nutzer, die Grundursache, die ergriffenen Maßnahmen und die gewonnenen Erkenntnisse.
In unseren wöchentlichen Meetings bei Pizza im Kreis des technischen Teams teilen wir verschiedene Informationen. Ein wichtiger Bestandteil dieser Meetings sind die Post-Mortems, die oft von einer Präsentation mit Folien und einer gründlicheren Analyse des aufgetretenen Vorfalls begleitet werden. Auch wenn wir nach den Post-Mortems nicht „Applaus“ geben, bemühen wir uns, eine „schuldlose“ Kultur zu fördern (). Wir glauben, dass das Schreiben und Teilen von Post-Mortems uns (und nicht nur uns) helfen kann, ähnliche Vorfälle in der Zukunft zu vermeiden, weshalb wir sie auch teilen.
Die Personen, die in den Vorfall verwickelt sind, sollten das Gefühl haben, dass sie ihn im Detail beschreiben können, ohne Angst vor Bestrafung oder Vergeltung zu haben. Kein Vorwurf! Das Schreiben eines Post-Mortems ist keine Bestrafung, sondern eine Lernmöglichkeit für das gesamte Unternehmen.
DNS-Probleme in Kubernetes. Post-Mortem
Lieber Tagebuch, 28.02.2020
Autoren: Amet U., Andrey S., Igor K., Alexey P.
Status: Abgeschlossen
Zusammenfassung: Teilweise DNS-Unerreichbarkeit (26 Minuten) für einige Dienste im Kubernetes-Cluster
Auswirkungen: 15.000 Ereignisse für die Dienste A, B und C verloren
Ursache: Kube-Proxy konnte den alten Eintrag in der Conntrack-Tabelle nicht korrekt löschen, weshalb einige Dienste weiterhin versuchten, sich mit nicht existierenden Pods zu verbinden.
E0228 20:13:53.795782 1 proxier.go:610] Failed to delete kube-system/kube-dns:dns endpoint connections, error: error deleting conntrack entries for UDP peer {100.64.0.10, 100.110.33.231}, error: conntrack command returned: ...Auslöser: Aufgrund der niedrigen Last im Kubernetes-Cluster reduzierte der CoreDNS-Autoscaler die Anzahl der Pods im Deployment von drei auf zwei.
Die Lösung: Ein weiterer Anwendungs-Deployment hat die Erstellung neuer Nodes initiiert, der CoreDNS-Autoscaler hat zusätzliche Pods hinzugefügt, um den Cluster zu bedienen, was eine Neuschreibung der Conntrack-Tabelle zur Folge hatte.
Erkennung: Das Prometheus-Monitoring hat eine hohe Anzahl von 5xx-Fehlern für die Dienste A, B und C festgestellt und einen Alarm für die Bereitschaftsingenieure ausgelöst.

5xx-Fehler in Kibana
Aktionen
Aktion
Typ
Verantwortlicher
Ziel
Autoscaler für CoreDNS deaktivieren
verhindert.
Amet U.
DEVOPS-695
Caching-DNS-Server einrichten
verringern.
Max V.
DEVOPS-665
Conntrack-Monitoring konfigurieren
verhindert.
Amet U.
DEVOPS-674
Erlernte Lektionen
Was gut gelaufen ist:
- Das Monitoring hat zuverlässig funktioniert. Die Reaktion war schnell und gut organisiert.
- Wir haben bei den Nodes keine Limits erreicht.
Was nicht gestimmt hat:
- Die tatsächliche Hauptursache bleibt weiterhin unbekannt, ähnelt einem im Conntrack.
- Alle Maßnahmen beheben nur die Symptome, nicht die Hauptursache (Bug).
- Wir wussten, dass wir früher oder später Probleme mit DNS haben könnten, haben jedoch die Aufgaben nicht priorisiert.
Wo wir Glück hatten:
- Ein weiterer Deployment hat den CoreDNS-Autoscaler ausgelöst, der die Conntrack-Tabelle neu geschrieben hat.
- Dieser Bug hat nur einige Dienste betroffen.
Chronologie (EET)
Zeit
Aktion
22:13
Der CoreDNS-Autoscaler hat die Anzahl der Pods von drei auf zwei reduziert.
22:18
Die Bereitschaftsingenieure erhielten Anrufe vom Überwachungssystem.
22:21
Die Bereitschaftsingenieure begannen, die Ursache der Fehler zu klären.
22:39
Die Bereitschaftsingenieure begannen, einen der letzten Dienste auf die vorherige Version zurückzusetzen.
22:40
5xx-Fehler traten nicht mehr auf, die Situation stabilisierte sich.
- Zeit bis zur Entdeckung: 4 Minuten
- Zeit bis zur Durchführung von Maßnahmen: 21 Minuten
- Zeit bis zur Behebung: 1 Minute
Zusätzliche Informationen
- [INFO] 10.1.28.1:52495 - 2606 "A IN mrkaran.hello.svc.cluster.local. udp 49 false 512" NXDOMAIN qr,aa,rd 142 0.000524939s [INFO] 10.1.28.1:59287 - 57522 "A IN mrkaran.svc.cluster.local. udp 43 false 512" NXDOMAIN qr,aa,rd 136 0.000368277s [INFO] 10.1.28.1:53086 - 4863 "A IN mrkaran.cluster.local. udp 39 false 512" NXDOMAIN qr,aa,rd 132 0.000355344s [INFO] 10.1.28.1:56863 - 41678 "A IN mrkaran. udp 25 false 512" NXDOMAIN qr,rd,ra 100 0.034629206s
I0228 20:13:53.507780 1 event.go:221] Event(v1.ObjectReference{Kind:"Deployment", Namespace:"kube-system", Name:"coredns", UID:"2493eb55-3dc0-11ea-b3a2-02bb48f8c230", APIVersion:"apps/v1", ResourceVersion:"132690686", FieldPath:""}): Typ: 'Normal' Grund: 'ScalingReplicaSet' Replikatensatz coredns-6cbb6646c9 auf 2 heruntergeskaliert. - Links zu Kibana (weggelassen), Grafana (weggelassen)
Um die CPU-Nutzung zu minimieren, verwendet der Linux-Kernel eine Technik namens conntrack. Kurz gesagt, es handelt sich um ein Dienstprogramm, das eine Liste von NAT-Einträgen in einer speziellen Tabelle speichert. Wenn das nächste Paket aus demselben Pod an denselben Pod gesendet wird wie zuvor, wird die Ziel-IP-Adresse nicht neu berechnet, sondern aus der conntrack-Tabelle entnommen.
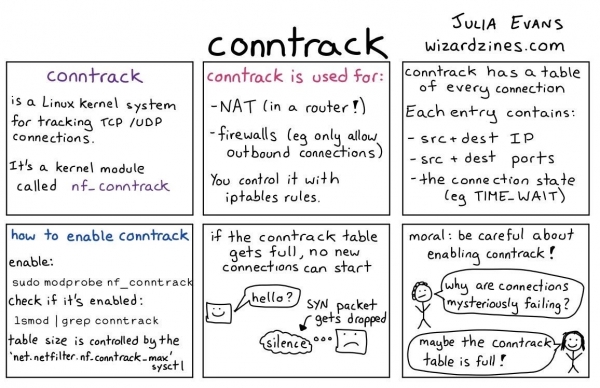
Wie conntrack funktioniert.
Ergebnisse
Dies war ein Beispiel für eines unserer Post-Mortems mit einigen nützlichen Links. In diesem Artikel teilen wir Informationen, die für andere Unternehmen hilfreich sein könnten. Deshalb scheuen wir uns nicht, Fehler zu machen, und genau deshalb machen wir eines unserer Post-Mortems öffentlich. Hier sind noch einige interessante öffentliche Post-Mortems:
- GitLab:
- Dropbox:
- Spotify:
- Viele weitere aus und Repository
- Außerdem öffentlichem Post-Mortem mit dem SRE-Buch
Quelle: habr.com
