

Diese Geschichte handelt davon, wie wir Container in unserer Produktumgebung nutzen, insbesondere unter Kubernetes. Der Artikel befasst sich mit dem Sammeln von Metriken und Logs von Containern sowie dem Erstellen von Images.

Wir sind ein Fintech-Unternehmen namens Exness, das Dienstleistungen für den Online-Handel und Fintech-Produkte für B2B und B2C entwickelt. In unserer Forschungs- und Entwicklungsabteilung gibt es viele verschiedene Teams, und der Entwicklungsbereich umfasst über 100 Mitarbeiter.
Wir sind das Team, das für die Plattform verantwortlich ist, die unseren Entwicklern das Sammeln und Ausführen von Code ermöglicht. Insbesondere sind wir für das Sammeln, Speichern und Bereitstellen von Metriken, Logs und Ereignissen aus Anwendungen verantwortlich. Derzeit verwalten wir etwa dreitausend Docker-Container in der Produktumgebung, unterstützen unser Big Data-Speicher mit 50 TB und bieten architektonische Lösungen, die um unsere Infrastruktur herum aufgebaut sind: Kubernetes, Rancher und verschiedene öffentliche Cloud-Anbieter.
Unsere Motivation
Was brennt? Niemand kann es beantworten. Wo ist der Brandherd? Schwer zu verstehen. Wann ist es in Brand geraten? Das lässt sich klären, aber nicht sofort.

Warum gibt es Container, die funktionieren, während andere ausfallen? Welcher Container ist dafür verantwortlich? Denn äußerlich sehen die Container gleich aus, aber jeder hat sein eigenes Neo im Inneren.

Unsere Entwickler sind kompetente Leute. Sie erstellen gute Dienste, die dem Unternehmen Gewinn bringen. Doch manchmal gibt es Probleme, wenn die Container mit den Anwendungen chaotisch werden. Ein Container verbraucht zu viel CPU, ein anderer die Netzwerkbandbreite, der dritte sorgt für I/O-Operationen, während der vierte völlig unklar ist, was er mit den Sockets anstellt. Das führt zu Ausfällen, und das Schiff sinkt.
Agenten
Um zu verstehen, was im Inneren passiert, haben wir beschlossen, Agenten direkt in den Containern zu installieren.

Diese Agenten sind Überwachungsprogramme, die sicherstellen, dass die Container sich in einem Zustand befinden, in dem sie sich nicht gegenseitig beschädigen. Die Agenten sind standardisiert, was es ermöglicht, einen einheitlichen Ansatz zur Wartung der Container zu gewährleisten.
In unserem Fall müssen die Agenten Protokolle im Standardformat bereitstellen, mit Tags und Drosselung. Sie müssen uns auch standardisierte Metriken liefern, die aus Sicht der Geschäftsanwendungen erweiterbar sind.
Unter Agenten versteht man auch Tools zur Nutzung und Wartung, die in verschiedenen Orchestrierungssystemen arbeiten können und verschiedene Images unterstützen (Debian, Alpine, CentOS usw.).
Schließlich müssen die Agents eine einfache CI/CD-Pipeline unterstützen, die Docker-Dateien umfasst. Andernfalls zerfällt das Schiff, weil die Container auf „schiefen“ Gleisen geliefert werden.
Der Prozess des Buildens und die Struktur des Ziel-Images
Um alles zu standardisieren und verwaltbar zu machen, ist es notwendig, einen bestimmten Standard-Build-Prozess einzuhalten. Daher haben wir beschlossen, Container mit Containern zu bauen — eine Art Rekursion.
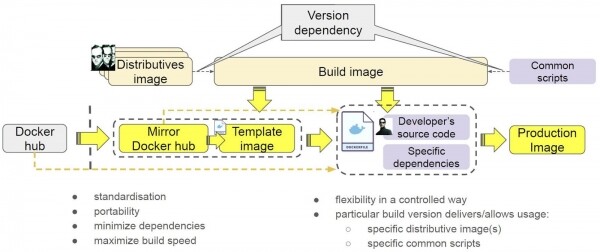
Hier werden die Container als durchgehende Umrisse dargestellt. Zudem haben wir beschlossen, Distributionen hineinzugeben, damit „das Leben nicht wie ein Himbeertraum aussieht“. Warum das gemacht wurde, erklären wir weiter unten.
Das Ergebnis ist ein Tool zum Bauen — ein Container einer bestimmten Version, der auf bestimmte Versionen von Distributionen und spezifische Versionen von Skripten verweist.
Wie wenden wir es an? Wir haben Docker Hub, in dem sich der Container befindet. Wir spiegeln ihn in unser System, um externe Abhängigkeiten zu vermeiden. Dabei entsteht ein Container, der gelb markiert ist. Wir erstellen eine Vorlage, um alle benötigten Distributionen und Skripte im Container zu installieren. Anschließend stellen wir ein betriebsbereites Image zusammen: Die Entwickler fügen ihren Code und spezielle Abhängigkeiten hinzu.
Was ist gut an diesem Ansatz?
- Erstens, vollständige Versionskontrolle der Build-Tools – einschließlich des Build-Containers, der Versionen von Skripten und Distributionen.
- Zweitens haben wir eine Standardisierung erreicht: Wir erstellen Vorlagen, Zwischen- und betriebsbereite Images auf die gleiche Weise.
- Drittens bieten Container uns Portabilität. Heute verwenden wir Gitlab, und morgen wechseln wir zu TeamCity oder Jenkins und können unsere Container genau so betreiben.
- Viertens, Minimierung der Abhängigkeiten. Wir haben bewusst Distributionen im Container platziert, da dies bedeutet, dass wir sie nicht jedes Mal aus dem Internet herunterladen müssen.
- Fünftens hat sich die Geschwindigkeit des Builds erhöht – die Verfügbarkeit von lokalen Kopien der Images ermöglicht es, keine Zeit mit dem Herunterladen zu verschwenden, da ein lokales Image vorhanden ist.
Anders ausgedrückt, haben wir einen kontrollierten und flexiblen Build-Prozess erreicht. Wir verwenden die gleichen Mittel, um alle Container mit vollständiger Versionskontrolle zu erstellen.
Wie unser Build-Verfahren funktioniert
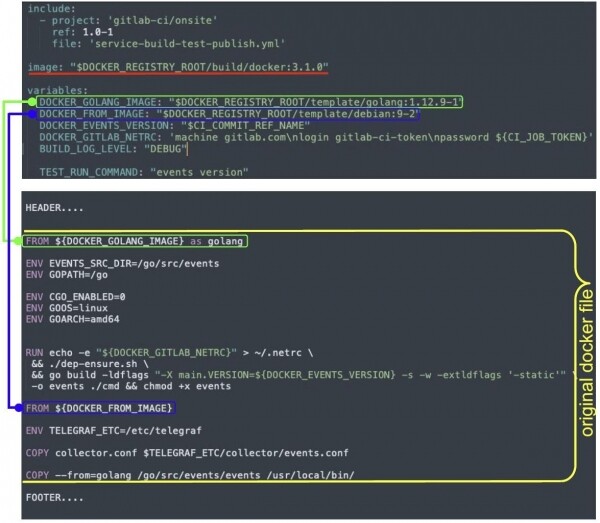
Der Build wird mit einem einzigen Befehl gestartet, der Prozess wird im Image ausgeführt (rot hervorgehoben). Der Entwickler hat eine Docker-Datei (gelb hervorgehoben), die wir rendern, wobei wir die Variablen durch Werte ersetzen. Gleichzeitig fügen wir Header und Footer hinzu – das sind unsere Agenten.
Der Header fügt Distributionen aus den entsprechenden Images hinzu. Der Footer installiert unsere Dienste, konfiguriert den Start der Arbeitslast, das Logging und andere Agenten, ersetzt den Entry-Point usw.
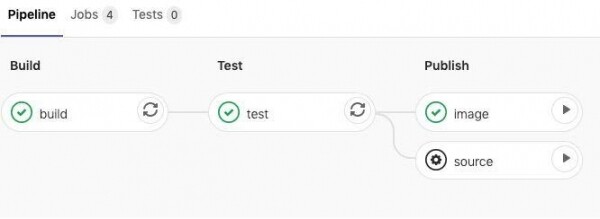
Wir haben lange überlegt, ob wir einen Supervisor einrichten sollen. Schließlich haben wir beschlossen, dass wir ihn benötigen. Wir haben S6 ausgewählt. Der Supervisor ermöglicht das Management des Containers: Er erlaubt den Zugriff auf den Container im Falle eines Absturzes des Hauptprozesses und ermöglicht die manuelle Steuerung des Containers, ohne ihn neu zu erstellen. Die Protokolle und Metriken sind Prozesse, die im Container ausgeführt werden. Auch diese müssen überwacht werden, und das erledigen wir mit Hilfe des Supervisors. Schließlich übernimmt S6 Aufgaben wie das Housekeeping, das Signalhandling und weitere Aufgaben.
Da wir verschiedene Orchestrierungssysteme verwenden, muss der Container nach dem Build und Start verstehen, in welcher Umgebung er sich befindet und entsprechend handeln. Zum Beispiel:
Das ermöglicht es uns, ein einzelnes Image zu erstellen und es in verschiedenen Orchestrierungssystemen auszuführen, wobei der Start die Besonderheiten dieses Orchestrierungssystems berücksichtigt.
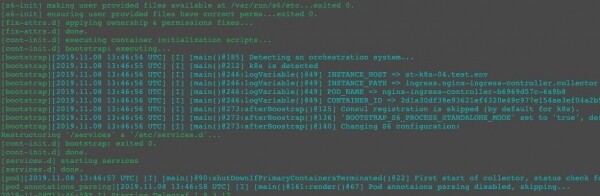
Für denselben Container erhalten wir unterschiedliche Prozessbäume in Docker und Kubernetes:
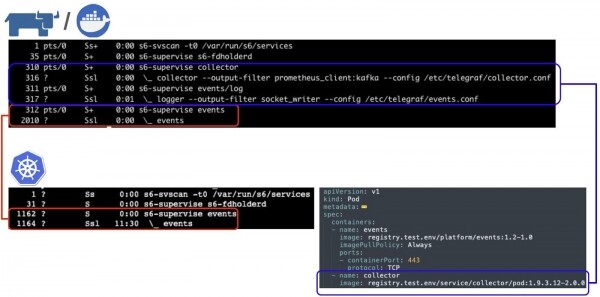
Die Nutzlast wird unter dem Supervisor S6 ausgeführt. Beachten Sie den Collector und Events – das sind unsere Agenten, die für Protokolle und Metriken zuständig sind. In Kubernetes sind sie nicht vorhanden, in Docker hingegen schon. Warum?
Wenn wir die Spezifikation eines Pods (im Folgenden Kubernetes-Pod) betrachten, sehen wir, dass der Container events in einem Pod ausgeführt wird, in dem ein separater Container collector vorhanden ist, der für das Sammeln von Metriken und Logs zuständig ist. Wir können die Möglichkeiten von Kubernetes nutzen: Container in einem Pod zu starten, in einem einheitlichen Prozess- und/oder Netzwerkraum. Tatsächlich können wir eigene Agents implementieren und verschiedene Funktionen ausführen. Und wenn dieser Container auch in Docker gestartet wird, erhält er dieselben Möglichkeiten, sodass er Logs und Metriken übertragen kann, da die Agents innerhalb des Containers ausgeführt werden.
Metriken und Logs
Die Übertragung von Metriken und Logs ist eine komplexe Aufgabe. Bei ihrer Lösung sind mehrere Aspekte zu berücksichtigen.
Die Infrastruktur wird für die Ausführung von Lasten und nicht für die massenhafte Lieferung von Logs erstellt. Das bedeutet, dass dieser Prozess mit minimalen Anforderungen an die Containerrressourcen umgesetzt werden sollte. Wir wollen unseren Entwicklern helfen: "Nehmt einen Docker Hub-Container, startet ihn, und wir können die Logs übertragen."
Der zweite Aspekt ist die Begrenzung des Log-Volumens. Wenn in mehreren Containern ein Anstieg des Log-Volumens auftritt (wenn eine Anwendung im Loop Stack-Traces ausgibt), erhöht sich die CPU-Belastung, die Bandbreite und die Log-Verarbeitungssysteme, was die Gesamtleistung des Hosts sowie andere Container auf dem Host beeinträchtigen kann, was manchmal zu einem "Ausfall" des Hosts führt.
Der dritte Aspekt ist, dass es wichtig ist, von Anfang an möglichst viele Methoden zur Metriksammlung zu unterstützen. Dazu gehören das Lesen von Dateien und das Abfragen von Prometheus-Endpunkten sowie die Nutzung spezifischer Anwendungsprotokolle.
Und der letzte Aspekt ist, dass der Ressourcenverbrauch minimiert werden muss.
Wir haben uns für die Open-Source-Lösung Telegraf entschieden, die in Go geschrieben ist. Dies ist ein universeller Connector, der über 140 Arten von Eingabekanälen (Input Plugins) und 30 Arten von Ausgangskanälen (Output Plugins) unterstützt. Wir haben ihn weiterentwickelt und zeigen jetzt, wie er bei uns am Beispiel von Kubernetes verwendet wird.
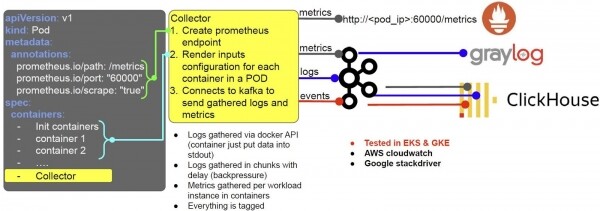
Angenommen, ein Entwickler setzt eine Last auf, und Kubernetes erhält eine Anfrage zur Erstellung eines Pods. In diesem Moment wird für jeden Pod automatisch ein Container mit dem Namen Collector erstellt (wir verwenden einen Mutation-Webhook). Collector ist unser Agent. Beim Start konfiguriert dieser Container sich für die Arbeit mit Prometheus und dem Log-Sammelsystem.
- Hierfür nutzt er die Annotations des Pods, und je nach deren Inhalt erstellt er beispielsweise einen Endpunkt für Prometheus;
- Basierend auf der Spezifikation des Pods und den spezifischen Container-Einstellungen entscheidet er, wie die Logs bereitgestellt werden.
Die Logs sammeln wir über die Docker API: Die Entwickler müssen sie nur in stdout oder stderr legen, der Collector kümmert sich dann darum. Die Logs werden chunkweise mit einer gewissen Verzögerung gesammelt, um eine mögliche Überlastung des Hosts zu verhindern.
Metriken werden für die Instanzen der Arbeitslast (Prozesse) in den Containern gesammelt. Alles wird mit Tags versehen: Namespace, Pod und so weiter, und dann in das Prometheus-Format konvertiert – und ist für die Erfassung verfügbar (außer für Logs). Außerdem senden wir Logs, Metriken und Ereignisse an Kafka und darüber hinaus:
- Logs sind in Graylog verfügbar (für die visuelle Analyse);
- Logs, Metriken und Ereignisse werden in Clickhouse zur langfristigen Speicherung gesendet.
Das gleiche gilt für AWS, wo wir Graylog mit Kafka durch Cloudwatch ersetzen. Die Logs werden dorthin gesendet, und es wird sehr bequem: direkt ersichtlich, zu welchem Cluster und Container sie gehören. Dasselbe gilt für Google Stackdriver. Unsere Architektur funktioniert sowohl lokal mit Kafka als auch in der Cloud.
Wenn wir kein Kubernetes mit Pods haben, wird es etwas komplizierter, funktioniert jedoch nach denselben Prinzipien.
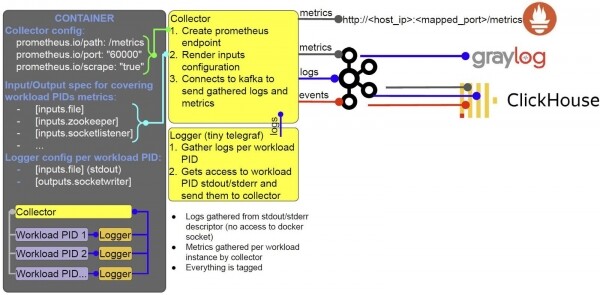
Im Container laufen dieselben Prozesse, die mit S6 orchestriert werden. Alle diese Prozesse sind innerhalb eines Containers gestartet.
Insgesamt
Wir haben eine umfassende Lösung zur Erstellung und Bereitstellung von Images mit Optionen zur Sammlung und Zustellung von Logs und Metriken entwickelt:
- Wir haben einen standardisierten Ansatz zur Erstellung von Images entwickelt und darauf basierende CI-Vorlagen erstellt.
- Die Datenagenten sind unsere Telegraf-Erweiterungen. Wir haben sie erfolgreich in der Produktion getestet.
- Wir verwenden Webhooks zur Mutation, um Container mit Agenten in Pods zu integrieren.
- Wir haben uns in das Kubernetes/Rancher-Ökosystem integriert.
- Wir können dieselben Container in verschiedenen Orchestrierungssystemen ausführen und das gewünschte Ergebnis erzielen.
- Wir haben eine vollständig dynamische Containerverwaltungsinfrastruktur erstellt.
Co-Autor: Ilja Prudnikov
Quelle: habr.com
