

Ich lade Sie ein, sich mit der Auswertung des Berichts von Nikolai Samokhvalov "Industrieller Ansatz zur Optimierung von PostgreSQL: Experimente mit Datenbanken" vertraut zu machen.
Sind 25% für shared_buffers viel oder wenig? Oder genau richtig? Wie können Sie feststellen, ob diese – recht veraltete – Empfehlung für Ihren speziellen Fall geeignet ist?
Es ist an der Zeit, sich dem Thema der Parametrierung von postgresql.conf "ernsthaft" zu widmen. Nicht mit blindem "Autotuning" oder veralteten Ratschlägen aus Artikeln und Blogs, sondern basierend auf:
- streng kontrollierten Experimenten mit Datenbanken, die automatisiert, in großer Anzahl und unter Bedingungen durchgeführt werden, die möglichst nah an "realistischen" Szenarien sind.
- einem tiefen Verständnis der Funktionsweise von Datenbankmanagementsystemen und Betriebssystemen.
Mit Nancy CLI (), werden wir ein konkretes Beispiel betrachten – die berühmten shared_buffers – in verschiedenen Situationen, in unterschiedlichen Projekten und versuchen herauszufinden, wie wir die optimale Einstellung für unsere Infrastruktur, Datenbank und Last finden können.

Es wird um Experimente mit Datenbanken gehen. Dies ist eine Geschichte, die nun schon etwas mehr als ein halbes Jahr andauert.

Ein bisschen zu mir: Ich habe über 14 Jahre Erfahrung mit Postgres. Ich habe mehrere Unternehmen im Bereich soziale Netzwerke gegründet. Überall kam Postgres zum Einsatz und wird nach wie vor verwendet.
Die RuPostgres-Gruppe hat auf Meetup den 2. Platz weltweit belegt. Wir nähern uns allmählich 2.000 Mitgliedern. RuPostgres.org.
Ich bin bei verschiedenen Konferenzen, einschließlich Highload, für Datenbanken verantwortlich, insbesondere für Postgres seit der Gründung.

In den letzten Jahren habe ich meine Praxis im Postgres-Consulting in 11 Zeitzonen von hier aus wieder aufgenommen.

Als ich das vor einigen Jahren gemacht habe, hatte ich eine längere Pause von der aktiven praktischen Arbeit mit Postgres, wahrscheinlich seit 2010. Ich war überrascht, wie wenig sich der Arbeitsalltag eines DBA verändert hat und wie viel man immer noch manuelle Arbeit aufbringen muss. Sofort dachte ich, dass hier etwas nicht stimmt, und dass man alles viel mehr automatisieren sollte.
Da das alles remote war, waren die meisten Kunden in der Cloud. Vieles war daher offensichtlich bereits automatisiert. Dazu später mehr. Das führte zu der Idee, dass es eine Reihe von Tools, also eine Art Plattform, geben sollte, die fast alle DBA-Aktivitäten automatisiert, um viele Datenbanken zu verwalten.

In diesem Bericht wird es nicht gehen:
- „Silberne Kugeln“ und Aussagen wie – stellen Sie 8 GB oder 25 % shared_buffers ein, und alles wird gut. Über shared_buffers wird es nicht so viel geben.
- Hochleistungs-Infrastruktur.

Was passiert?
- Es werden Optimierungsprinzipien vorgestellt, die wir anwenden und weiterentwickeln. Zudem entstehen verschiedene Ideen auf unserem Weg sowie diverse Werkzeuge, die größtenteils in Open Source entwickelt werden. Das Fundament ist also Open Source. Darüber hinaus ist die gesamte Kommunikation und Ticketvergabe fast ausschließlich Open Source. Sie können verfolgen, was wir aktuell tun, was im nächsten Release kommt usw.
- Außerdem wird es einige Erfahrungen mit der Anwendung dieser Prinzipien und Werkzeuge in Unternehmen geben, von kleinen Startups bis hin zu großen Firmen.

Wie entwickelt sich das alles?

Die Hauptaufgabe eines DBAs besteht, neben der Erstellung von Instanzen und dem Deployment von Backups, auch darin, Engpässe zu identifizieren und die Leistung zu optimieren.
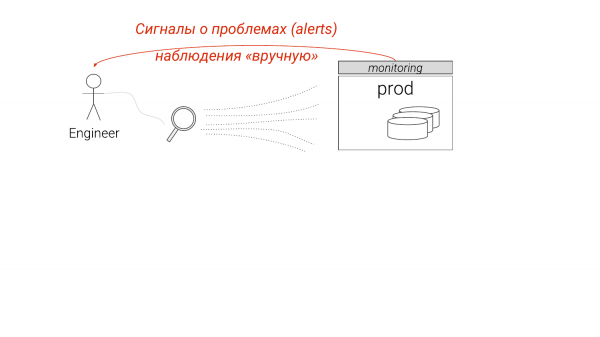
Aktuell ist es so organisiert: Wir betrachten die Überwachung, erkennen, dass uns einige Details fehlen. Dann beginnen wir, tiefer zu graben, oft manuell, und verstehen, was wir damit tun müssen.
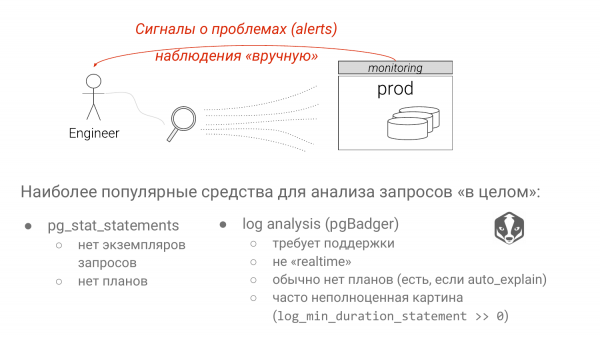
Dabei gibt es zwei Ansätze. Pg_stat_statements – die Standardlösung zur Identifizierung langsamer Anfragen. Und die Log-Analyse von Postgres mithilfe von pgBadger.
Jeder Ansatz hat erhebliche Nachteile. Der erste Ansatz ignoriert alle Parameter. Und wenn wir die Gruppen SELECT * FROM table WHERE die Spalte gleich dem Zeichen „?“ oder „$“ betrachten, beginnend mit Version Postgres 10, wissen wir nicht, ob es sich um einen Index-Scan oder einen Seq-Scan handelt. Es hängt stark von dem Parameter ab. Wenn man einen seltenen Wert einsetzt, wird es ein Index-Scan sein. Setzt man einen Wert ein, der 90 % der Tabelle ausmacht, wird es offensichtlich ein Seq-Scan, da Postgres die Statistiken kennt. Und das ist ein großes Manko von pg_stat_statements, obwohl daran gearbeitet wird.
Die größte Schwäche der Log-Analyse ist, dass Sie normalerweise nicht „log_min_duration_statement = 0“ einstellen können. Darüber werden wir ebenfalls sprechen. Folglich sehen Sie nicht das gesamte Bild. Eine Abfrage, die sehr schnell ist, kann enorme Ressourcen verbrauchen, aber Sie werden sie nicht sehen, da sie unter Ihrem Schwellenwert liegt.
Wie gehen DBAs mit den gefundenen Problemen um?
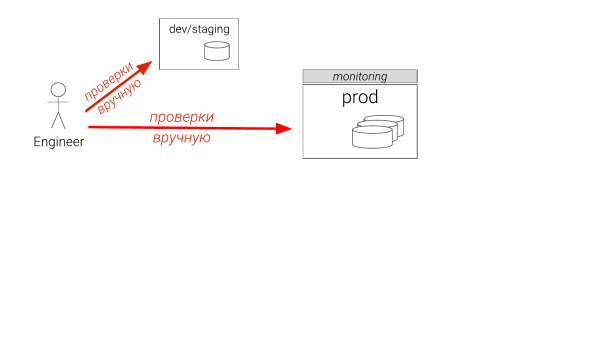
Zum Beispiel haben wir ein Problem festgestellt. Was wird normalerweise gemacht? Wenn Sie ein Entwickler sind, arbeiten Sie an einem bestimmten Instance, die nicht wirklich groß ist. Wenn Sie ein DBA sind, haben Sie eine Staging-Umgebung. Und die kann nur eine sein. Sie ist aber schon ein halbes Jahr alt. Und jetzt denken Sie daran, in die Produktion zu gehen. Selbst erfahrene DBAs überprüfen schließlich auch in der Produktion, auf einer Replik. Oft wird ein temporärer Index erstellt, um sicherzustellen, dass dieser hilft. Dann wird er wieder entfernt und den Entwicklern übergeben, damit sie ihn in die Migrationsdateien einfügen können. Solche Dinge passieren derzeit, und das ist bedauerlich.
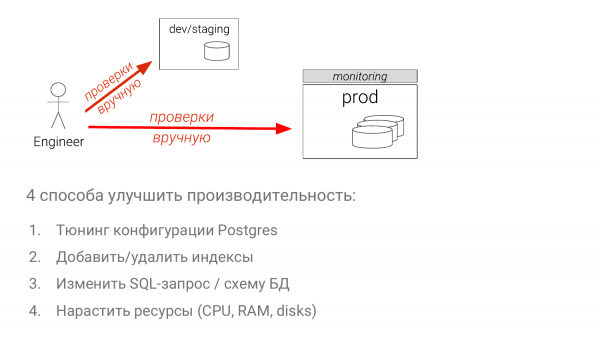
- Konfigurationen optimieren.
- Das Set von Indizes optimieren.
- Die SQL-Abfrage selbst ändern (das ist der komplizierteste Weg).
- Ressourcen hinzufügen (der einfachste Weg in den meisten Fällen).

Es gibt sehr viele Aspekte. Es gibt viele Funktionen in Postgres. Man muss viel wissen. Viele Indizes in Postgres, auch dank der Organisatoren dieser Konferenz. All das muss man wissen, und genau das lässt Nicht-DBAs glauben, dass DBAs mit schwarzer Magie arbeiten. Das bedeutet, man muss mindestens 10 Jahre lernen, um das alles richtig zu verstehen.
Ich bin ein Kämpfer gegen diese schwarze Magie. Ich möchte alles so gestalten, dass Technologie im Vordergrund steht und nicht Intuition.
Beispiele aus dem Leben

Das habe ich mindestens in zwei Projekten beobachtet, darunter mein eigenes. Ein weiterer Blogbeitrag berichtet uns, dass der Wert von 1.000 für default_statistict_target gut ist. Gut, lassen Sie uns das in der Produktion ausprobieren.

Und hier sind wir, zwei Jahre später mit unserem Tool, indem wir Experimente an den Datenbanken durchführen, über die wir heute sprechen. Wir können vergleichen, was war und was geworden ist.
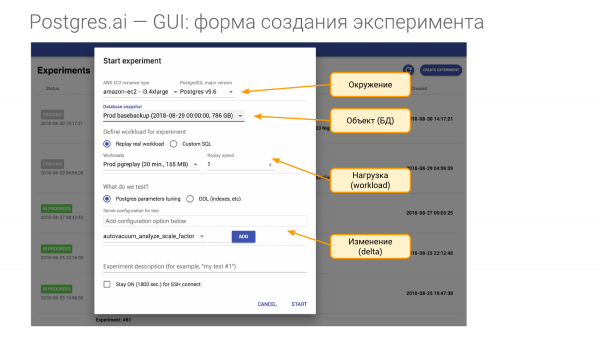
Und dafür müssen wir ein Experiment erstellen. Es besteht aus vier Teilen.
- Der erste Teil ist die Umgebung. Wir brauchen die Hardware. Und wenn ich zu einem Unternehmen komme und einen Vertrag abschließe, sage ich, dass ich die gleiche Hardware wie in der Produktion möchte. Für jeden Ihrer Master benötige ich mindestens eine solche Hardware. Entweder ist es eine VM-Instanz bei Amazon oder Google, oder ich benötige genau diese Hardware. Das heißt, ich möchte die Umgebung nachbauen. Und unter Umgebung verstehen wir die Hauptversion von Postgres.
- Der zweite Teil ist das Objekt unserer Untersuchungen. Das ist die Datenbank. Sie kann auf verschiedene Arten erstellt werden. Ich zeige Ihnen, wie.
- Der dritte Teil ist die Last. Das ist der komplexeste Punkt.
- Und der vierte Teil ist das, was wir überprüfen, das heißt, womit wir vergleichen werden. Angenommen, wir können in der Konfiguration einen oder mehrere Parameter ändern oder einen Index erstellen usw.
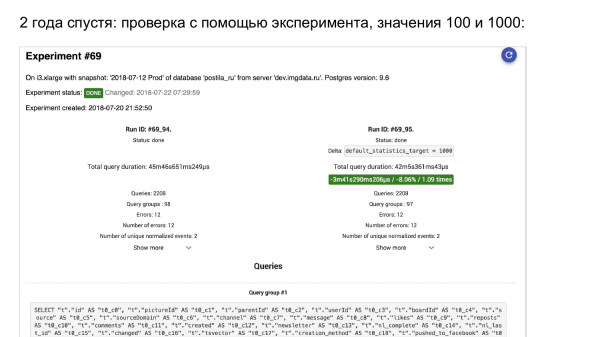
Wir starten das Experiment. Hier ist pg_stat_statements. Links sehen wir, wie es war. Rechts sehen wir, wie es geworden ist.
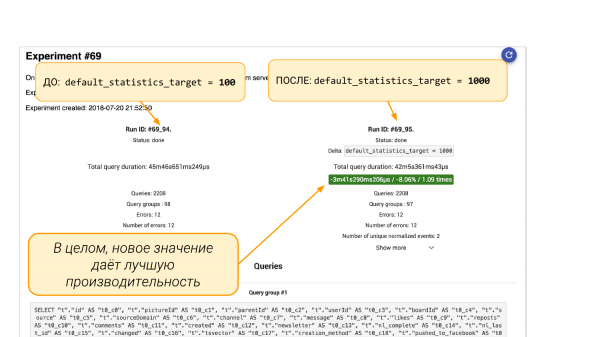
Links default_statistics_target = 100, rechts = 1 000. Wir sehen, dass uns das geholfen hat. Insgesamt hat es um 8 % verbessert.
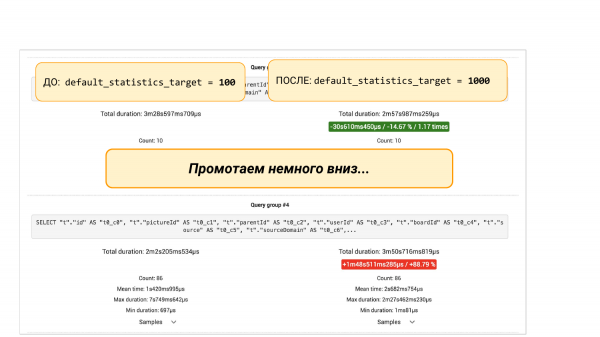
Wenn wir nach unten scrollen, finden wir Gruppen von Abfragen aus pgBadger oder pg_stat_statements. Es gibt zwei Möglichkeiten. Wir sehen, dass eine bestimmte Abfrage um 88 % gesunken ist. Hier ist bereits der ingenieurtechnische Ansatz. Wir können tiefer graben, weil es interessant ist, warum sie gesunken ist. Wir müssen verstehen, was mit den Statistiken war. Warum mehr Buckets in den Statistiken schlechtere Ergebnisse bringen.
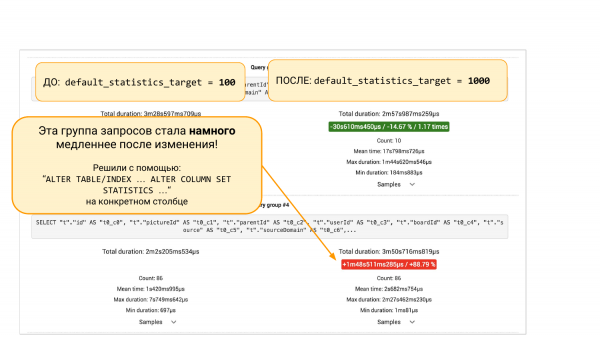
Alternativ können wir auch nicht weiter graben, sondern "ALTER TABLE … ALTER COLUMN" verwenden, um ihm wieder 100 Buckets in den Statistiken dieser Spalte zu geben. Mit einem weiteren Experiment können wir uns davon überzeugen, dass dieser Fix geholfen hat. Das ist der ingenieurtechnische Ansatz, der uns hilft, das Gesamtbild zu sehen und Entscheidungen auf der Grundlage von Daten und nicht von Intuition zu treffen.


Einige Beispiele aus anderen Bereichen. In den Tests gibt es bereits seit vielen Jahren CI-Tests. Und kein vernünftiges Projekt wird heutzutage ohne automatisierte Tests auskommen.
In anderen Branchen, wie der Luftfahrt oder dem Automobilbau, haben wir auch die Möglichkeit, Experimente durchzuführen, wenn wir die Aerodynamik testen. Wir werden nichts direkt vom Entwurf in den Weltraum schicken oder ein Fahrzeug sofort auf die Straße bringen. Zum Beispiel gibt es einen Windkanal.
Aus den Beobachtungen anderer Branchen können wir Rückschlüsse ziehen.

Zunächst einmal haben wir eine spezielle Umgebung. Sie ähnelt der Produktionsumgebung, ist aber nicht identisch. Ihr Hauptmerkmal ist, dass sie kostengünstig, wiederholbar und maximal automatisiert sein sollte. Außerdem müssen spezielle Werkzeuge für eine detaillierte Analyse zur Verfügung stehen.
Wahrscheinlich haben wir, wenn wir das Flugzeug starten und fliegen, weniger Möglichkeiten, jede Millimeterfläche des Flügels zu untersuchen, als wir das in einem Windkanal tun könnten. Wir haben mehr Mittel für die Diagnose. Wir können uns erlauben, mehr schweres Equipment anzubringen, das wir uns während des Flugs nicht leisten können. Genauso ist es mit Postgres. In einigen Fällen können wir vollständiges Logging der Anfragen während der Experimente aktivieren. Und das möchten wir in der Produktion nicht tun. Vielleicht werden wir das sogar über auto_explain aktivieren.
Und wie ich bereits sagte, bedeutet ein hoher Automatisierungsgrad, dass wir einen Knopf gedrückt und alles wiederholt haben. So sollte es sein, um viele Experimente durchzuführen und um das Ganze im Fluss zu halten.
Nancy CLI – das Fundament des "Datenbanklabors"

Und hier haben wir so etwas geschaffen. Das heißt, ich habe im Juni, vor fast einem Jahr, über diese Ideen gesprochen. Und wir haben bereits die sogenannte Nancy CLI als Open Source. Das ist das Fundament, um ein Datenbanklabor aufzubauen.
— Das ist Open Source, auf GitLab. Sie können es sich ansehen und ausprobieren. Ich habe den Link in den Folien eingefügt. Darauf können Sie klicken und dann wird es verfügbar sein. in allen Parametern.
Natürlich gibt es vieles, was sich noch in der Entwicklung befindet. Es gibt eine Vielzahl von Ideen. Aber das hier ist bereits etwas, das wir praktisch jeden Tag anwenden. Und wenn uns die Idee kommt – was wäre, wenn wir 40.000.000 Zeilen löschen, und wir stoßen auf IO-Probleme, dann können wir Experimente durchführen und genauer ansehen, was passiert, um zu verstehen, wie wir das direkt in der laufenden Umgebung beheben können. Das heißt, wir führen Experimente durch. Zum Beispiel justieren wir etwas und schauen, was am Ende dabei herauskommt. Und wir machen das nicht in der Produktionsumgebung. Das ist der Kern der Idee.
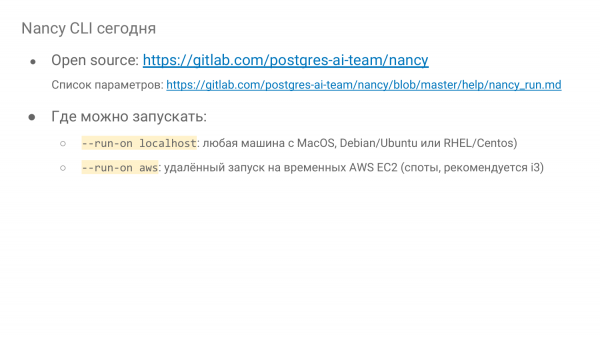
Wo kann das funktionieren? Das kann lokal funktionieren, das heißt, man kann es überall machen, sogar auf einem MacBook starten. Man benötigt Docker, und los geht’s. Man kann das in einem beliebigen Server-Instance oder einer virtuellen Maschine, wo auch immer, starten.
Sie haben auch die Möglichkeit, remote auf Amazon EC2-Instanzen in Spot-Pools zu arbeiten. Das ist eine großartige Gelegenheit. Zum Beispiel haben wir gestern mehr als 500 Experimente auf einer i3-Instanz durchgeführt, von der kleinsten bis hin zur i3-16-xlarge. Uns hat das Ganze 64 Dollar gekostet. Jedes Experiment dauerte 15 Minuten. Dank der Nutzung von Spot-Instanzen ist das sehr kostengünstig – mit einem Rabatt von 70 % und der sekundengenauen Abrechnung von Amazon. Sie können dabei sehr viel erreichen. Sie können echte Forschungen durchführen.
Drei Hauptversionen von Postgres werden unterstützt. Es ist nicht allzu schwierig, alte Versionen und auch die neue 12. Version zu integrieren.

Wir können das Objekt auf drei verschiedene Arten definieren. Das sind:
- Dump/sql-Datei.
- Die Hauptmethode ist das Klonen des PGDATA-Verzeichnisses. In der Regel wird es von einem Backup-Server genommen. Wenn Sie qualifizierte binäre Backups haben, können Sie Klone von dort erstellen. Wenn Sie Cloud-Dienste nutzen, wird dies automatisch von einem Cloud-Anbieter wie Amazon oder Google erledigt. Dies ist der wichtigste Weg, um Klone in einer realen Produktionsumgebung zu erstellen. So gehen wir dabei vor.
- Die letzte Methode eignet sich für Untersuchungen, wenn das Ziel besteht, zu verstehen, wie etwas in Postgres funktioniert. Das ist pgbench. Sie können es mit pgbench generieren. Es gibt einfach die Option „db-pgbench“. Sie geben den gewünschten Scale an. Und alles wird in der Cloud generiert, wie beschrieben.

Und die Last:
- Die Last können wir in einem einzelnen SQL-Thread ausführen. Das ist die einfachste Methode.
- Alternativ können wir die Last emulieren. Und zuerst können wir sie folgendermaßen emulieren. Wir müssen alle Logs sammeln. Und das ist schmerzhaft. Ich werde Ihnen zeigen, warum. Und mit Hilfe von pgreplay, das in Nancy integriert ist, spielen wir diese Logs ab.
- Oder eine andere Option. Die sogenannte handgefertigte Last, die wir mit einem gewissen Aufwand erstellen. Dabei analysieren wir unsere aktuelle Last auf dem Produktionssystem und extrahieren die meistgenutzten Anfragen. Und mit pgbench können wir diese Last im Labor emulieren.

- Alternativ müssen wir eine SQL-Anweisung ausführen, d.h. wir überprüfen eine Migration, erstellen einen Index, führen ANALYZE aus. Und wir schauen, was vor und nach dem Vacuum war. Im Grunde genommen, jede SQL-Anweisung.
- Wir ändern in der Konfiguration einen oder mehrere Parameter. Wir können zum Beispiel anfordern, dass 100 Werte in Amazon für unsere Terabyte-Datenbank überprüft werden. Nach ein paar Stunden erhalten Sie das Ergebnis. In der Regel dauert das Bereitstellen einer Terabyte-Datenbank einige Stunden. In der Entwicklung gibt es jedoch einen Patch, mit dem eine Serie möglich ist, d.h. Sie können dieselben pgdata auf demselben Server nacheinander verwenden und überprüfen. Postgres wird neu gestartet, die Caches werden zurückgesetzt. Und Sie können die Last testen.

- Es kommt ein Verzeichnis an, in dem viele verschiedene Dateien enthalten sind, angefangen bei Snapshots pg.stat***. Besonders interessant sind pg_stat_statements und pg_stat_kcache. Das sind zwei Erweiterungen, die die Anfragen analysieren. pg_stat_bgwriter enthält nicht nur Statistiken über pgwriter, sondern auch über Checkpoints und wie die Backends schmutzige Buffer verdrängen. Es ist sehr interessant, sich das anzusehen. Beispielsweise ist es spannend zu beobachten, wie viel dort verdrängt wurde, wenn wir shared_buffers konfigurieren.
- Auch die Logs von Postgres kommen an. Zwei Logs – das Vorbereitungsprotokoll und das Protokoll zur Ausführung der Last.
- Eine relativ neue Funktion sind die FlameGraphs.
- Wenn Sie pgreplay oder pgbench zur Lastwiedergabe verwendet haben, wird dessen Ausgabe wie gewohnt angezeigt. Sie werden Latenz und TPS sehen können. So können Sie verstehen, wie sie dies wahrgenommen haben.
- Systeminformationen.
- Grundlegende Überprüfungen von CPU und IO. Dies ist besonders für Amazon EC2-Instanzen relevant, wo Sie einen Stream von 100 identischen Instanzen starten möchten und dabei 100 verschiedene Läufe durchführen. So haben Sie insgesamt 10.000 Experimente. Sie müssen sicherstellen, dass Ihnen kein fehlerhafter Instance begegnet, der möglicherweise bereits von jemand anderem stark genutzt wird. Auf diesem Server könnten andere aktiv sein, was Ihre verfügbaren Ressourcen verringert. Solche Ergebnisse sollten Sie besser ablehnen. Mit sysbench von Alexey Kopytov führen wir mehrere kurze Tests durch, die Ihnen dabei helfen, CPU- und IO-Verhalten zu vergleichen.

Welche technischen Herausforderungen gibt es bei verschiedenen Unternehmen?

Angenommen, wir möchten eine reale Last mithilfe von Logs wiederholen. Das ist eine hervorragende Idee, wenn dies mit dem Open Source pgreplay gemacht wird. Wir verwenden dieses Tool. Damit es jedoch gut funktioniert, müssen Sie das vollständige Logging von Anfragen mit Parametern und Timing aktivieren.
Es gibt einige Schwierigkeiten bezüglich der Dauer und des Zeitstempels. Lassen Sie uns diese Details beiseitelegen. Die Hauptfrage ist: Können Sie sich das leisten oder nicht?

Das Problem ist, dass es möglicherweise nicht verfügbar ist. Sie müssen zunächst verstehen, welcher Datenstrom in das Protokoll geschrieben wird. Wenn Sie pg_stat_statements haben, können Sie mit dieser Abfrage (der Link wird in den Folien verfügbar sein) herausfinden, wie viele Bytes ungefähr pro Sekunde geschrieben werden.
Wir betrachten die Länge der Abfrage. Wir ignorieren die Tatsache, dass es keine Parameter gibt, aber wir wissen die Länge der Abfrage und wie oft sie pro Sekunde ausgeführt wurde. So können wir schätzen, wie viele Bytes pro Sekunde ungefähr anfallen. Wir könnten uns um das Doppelte irren, aber die Größenordnung werden wir auf diese Weise definitiv verstehen.
Wir können sehen, dass diese Abfrage 802 Mal pro Sekunde ausgeführt wird. Und wir sehen, dass bytes_per_sec – etwa 300 kB/s geschrieben werden. Und in der Regel können wir uns einen solchen Datenstrom leisten.

Aber! Es gibt verschiedene Protokollierungssysteme. Standardmäßig verwenden viele Menschen in der Regel "syslog".
Und wenn Sie syslog haben, könnte es so aussehen. Wir werden pgbench verwenden, das Abfragen protokollieren und sehen, was dabei herauskommt.
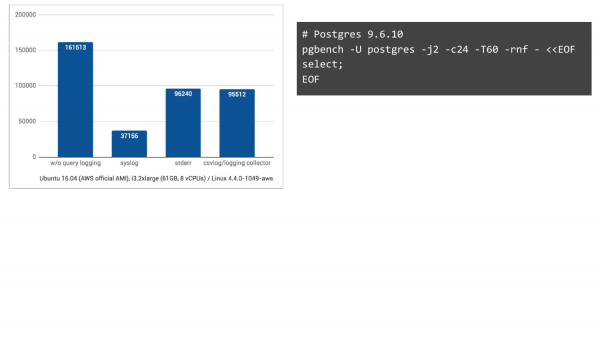
Ohne Protokollierung – das ist die linke Spalte. Wir hatten 161.000 TPS. Mit Syslog – in Ubuntu 16.04 auf Amazon erhalten wir 37.000 TPS. Wenn wir jedoch zu zwei anderen Protokollierungsarten wechseln, verbessert sich die Situation erheblich. Das heißt, wir erwarteten, dass es schlechter wird, aber nicht so stark.
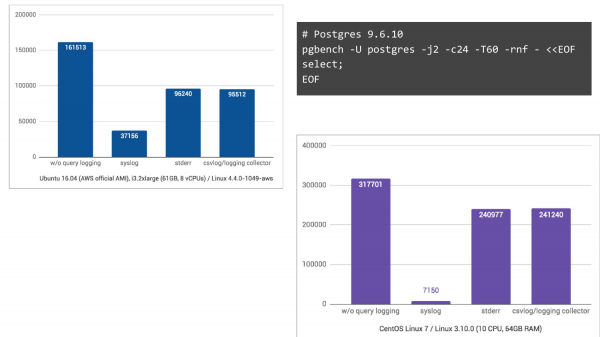
Und auf CentOS 7, wo journald noch mitwirkt und die Protokolle in ein binäres Format für eine einfachere Suche umwandelt usw., ist es wirklich katastrophal, wir fallen um das 44-fache in den TPS.
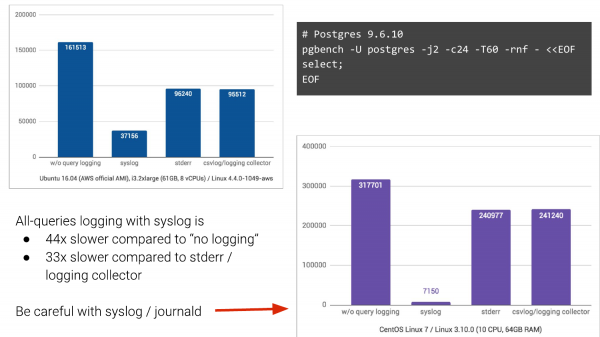
Und das ist etwas, womit die Leute leben müssen. Oft ist es in Unternehmen, insbesondere in großen, sehr schwierig, das zu ändern. Wenn Sie von Syslog wegkommen können, dann ziehen Sie bitte in Erwägung, es zu tun.

- Bewerten Sie IOPS und Schreibfluss.
- Überprüfen Sie Ihr Protokollierungssystem.
- Wenn die prognostizierte Last übermäßig hoch ist, ziehen Sie in Betracht, ein Sampling zu verwenden.

Wir haben pg_stat_statements. Wie ich bereits sagte, es muss unbedingt vorhanden sein. Wir können jede Gruppe von Abfragen auf spezielle Weise in eine Datei beschreiben. Und dann können wir eine sehr nützliche Funktion in pgbench nutzen – die Möglichkeit, mehrere Dateien mit der Option „-f“ zu übergeben.
Er versteht viel von „-f“. Und man kann mit „@“ am Ende angeben, wie viel jedes File beitragen soll. Das heißt, wir können sagen, dass dieses in 10 % der Fälle ausgeführt wird, und jenes in 20 %. Das bringt uns näher an das, was wir in der Produktion sehen.

Wie erfahren wir, was in der Produktion läuft? Welche Teile gehören dazu? Dazu müssen wir kurz abschweifen. Wir haben ein weiteres Produkt. . Es ist ebenfalls eine Open-Source-Datenbank, die wir nun aktiv weiterentwickeln.
Es entstand aus einem anderen Grund: Das Monitoring reicht oft nicht aus. Das heißt, Sie kommen, schauen sich die Datenbank an, sehen die bestehenden Probleme und machen in der Regel einen Health-Check. Wenn Sie ein erfahrener DBA sind, führen Sie den Health-Check durch. Sie überprüfen die Nutzung der Indizes usw. Wenn Sie OKmeter haben, dann ist das ausgezeichnet. Es ist ein großartiges Monitoring-Tool für Postgres. OKmeter.io – bitte installieren Sie es, es ist wirklich hervorragend. Es ist kostenpflichtig.
Wenn Sie es nicht haben, dann gibt es in der Regel nicht viel. Im Monitoring gibt es normalerweise nur CPU, IO und das mit Vorbehalten, und das war's. Aber wir brauchen mehr. Wir müssen sehen, wie der Autovacuum funktioniert, wie der Checkpoint arbeitet, im IO müssen wir Checkpoint, bgwriter und die Backends voneinander unterscheiden usw.
Das Problem ist, dass große Unternehmen nicht in der Lage sind, schnell etwas umzusetzen. Sie können OKmeter nicht einfach schnell kaufen. Vielleicht kaufen sie es in sechs Monaten. Sie können auch keine Pakete schnell installieren.
Und so entstand die Idee, ein spezielles Werkzeug zu entwickeln, das keine Installation benötigt. Das heißt, Sie müssen überhaupt nichts auf die Produktionsumgebung installieren. Sie installieren es auf Ihrem Laptop oder auf einem Überwachungsserver, von dem aus Sie es starten. Es wird vieles analysieren: das Betriebssystem, das Dateisystem und PostgreSQL selbst, indem es einige leichte Abfragen durchführt, die Sie direkt auf der Produktion ausführen können, ohne dass etwas ausfällt.
Wir haben es Postgres-checkup genannt. Medizinisch gesehen ist es eine regelmäßige Gesundheitsprüfung. Im Automobilbereich wäre es wie eine Inspektion. Man bringt sein Auto alle sechs Monate oder einmal im Jahr zur Inspektion, je nach Marke. Aber machen Sie eine Inspektion für Ihre Datenbank? Machen Sie regelmäßig eine tiefgreifende Analyse? Das sollten Sie tun. Wenn Sie Backups machen, sollten Sie auch einen Checkup durchführen; das ist nicht weniger wichtig.
Wir haben ein solches Werkzeug. Es hat vor etwa drei Monaten aktiv begonnen, sich zu entwickeln. Es ist noch jung, aber es bietet bereits viele Funktionen.

Wir erstellen die einflussreichsten Abfragesets – Bericht K003 im Postgres-Checkup
Es gibt eine Gruppe von Berichten K. Derzeit sind es drei Berichte. Und es gibt den Bericht K003. Dort befindet sich die Spitze von pg_stat_statements, sortiert nach total_time.
Wenn wir die Abfragesets nach total_time sortieren, sehen wir an der Spitze eine Gruppe, die unser System am stärksten belastet, d. h. sie verbraucht die meisten Ressourcen. Warum nenne ich es Abfragesets? Weil wir die Parameter ausgeschlossen haben. Es sind keine Einzelfragen mehr, sondern Abfragesets, d. h. sie sind abstrahiert.
Wenn wir von oben nach unten optimieren, entlasten wir unsere Ressourcen und verschieben den Zeitpunkt, an dem ein Upgrade erforderlich wird. Das ist ein sehr guter Weg, um Geld zu sparen.
Vielleicht ist das nicht der beste Ansatz in Bezug auf die Benutzerfreundlichkeit, da wir möglicherweise seltene, aber frustrierende Fälle übersehen, in denen jemand 15 Sekunden gewartet hat. Diese sind insgesamt so selten, dass wir sie nicht wahrnehmen, aber wir kümmern uns um die Ressourcen.

Was ist in dieser Tabelle passiert? Wir haben zwei Snapshots erstellt. Postgres_checkup wird Ihnen die Delta für jede Metrik liefern: für total-time, calls, rows, shared_blks_read usw. Alles, Delta wurde berechnet. Bei pg_stat_statements gibt es ein großes Problem: Es erinnert sich nicht, wann es zurückgesetzt wurde. Während pg_stat_database sich daran erinnert, hat pg_stat_statements keine Erinnerung. Sie sehen dort die Zahl 1.000.000, aber woher wir sie gezählt haben, wissen wir nicht.
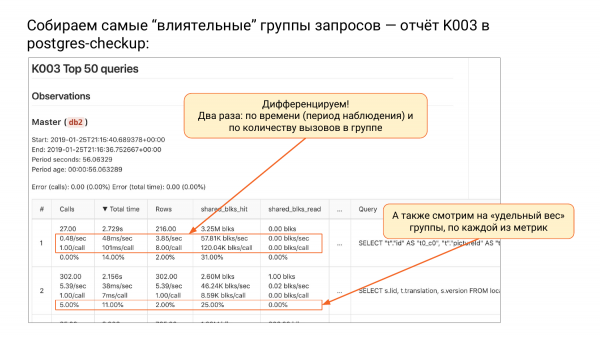
Hier wissen wir es, hier haben wir zwei Snapshots. Wir wissen, dass das Delta in diesem Fall 56 Sekunden betrug. Ein sehr kurzer Zeitraum. Nach total_time sortiert. Und dann können wir differenzieren, d.h. wir teilen alle Metriken durch die Dauer. Wenn wir jede Metrik durch die Dauer teilen, erhalten wir die Anzahl der Aufrufe pro Sekunde.
Die nächste Metrik, die mir am besten gefällt, ist total_time per second. Sie wird in Sekunden gemessen, d.h. wie viele Sekunden unser System für die Ausführung dieser Gruppe von Anfragen pro Sekunde benötigt hat. Wenn Sie dort mehr als eine Sekunde pro Sekunde sehen, bedeutet das, dass Sie mehr als einen Kern benötigen. Das ist eine sehr gute Metrik. Sie können verstehen, dass dieser Kollege beispielsweise mindestens drei Kerne benötigt.
Das ist unser Know-how, so etwas habe ich nirgendwo gesehen. Beachten Sie - es ist eine sehr einfache Sache - Sekunde für Sekunde. Manchmal, wenn Ihre CPU 100 % erreicht, kann es auch eine halbe Stunde pro Sekunde sein, d.h. Sie haben eine halbe Stunde nur mit dieser Anfrage verbracht.
Als nächstes sehen wir die Rows pro Sekunde. Wir wissen, wie viele Zeilen pro Sekunde zurückgegeben wurden.
Und dann gibt es auch eine interessante Sache. Wie viele Shared Buffers pro Sekunde wir aus den Shared Buffers gelesen haben. Die Hits waren bereits dort, und die Zeilen haben wir entweder aus dem Betriebssystem-Cache oder von der Festplatte genommen. Die erste Variante ist schnell, die zweite kann schnell sein, muss es aber nicht, das hängt von der Situation ab.
Und die zweite Möglichkeit der Differenzierung besteht darin, die Anzahl der Anfragen in dieser Gruppe zu teilen. In der zweiten Spalte haben Sie immer eine Anfrage geteilt durch Anfragen. Und dann wird es interessant - wie viele Millisekunden waren in dieser Anfrage. Wir wissen, wie sich diese Anfrage im Durchschnitt verhält. Für jede Anfrage benötigten wir 101 Millisekunden. Das ist eine traditionelle Metrik, die wir zur Verständigung benötigen.
Wie viele Zeilen jede Abfrage im Durchschnitt zurückgegeben hat. Wir sehen, dass diese Gruppe im Durchschnitt 8 zurückgibt. Wie viel durchschnittlich aus dem Cache genommen und gelesen wurde. Wir sehen, dass alles hervorragend zwischengespeichert ist. Komplett Treffer für die erste Gruppe.
Die vierte Zeile in jeder Zeile gibt an, wie viel Prozent vom Gesamtergebnis stammen. Wir haben Aufrufe, sagen wir, in 1.000.000. Und wir können verstehen, welchen Beitrag diese Gruppe leistet. In diesem Fall sehen wir, dass die erste Gruppe einen Beitrag von weniger als 0,01 % leistet. Das heißt, sie ist so langsam, dass wir sie im Gesamtbild nicht sehen. Die zweite Gruppe macht hingegen 5 % der Aufrufe aus. Das heißt, 5 % aller Aufrufe entfallen auf die zweite Gruppe.
Auch bei total_time ist es interessant. Für die erste Gruppe von Anfragen haben wir 14 % der gesamten Arbeitszeit aufgewendet. Für die zweite Gruppe waren es 11 % usw.
Ich werde nicht ins Detail gehen, aber es gibt Feinheiten. Wir geben einen Fehler oben aus, weil wir beim Vergleich feststellen können, dass Snapshots sich verschieben können, d. h. einige Anfragen können wegfallen und in der zweiten bereits nicht mehr vorhanden sein, während andere neu auftauchen können. Und wir berechnen dort den Fehler. Wenn Sie 0 sehen, ist das gut. Das bedeutet, dass es keine Fehler gibt. Wenn die Fehlerrate bis zu 20 % beträgt, ist das in Ordnung.

Jetzt kehren wir zu unserem Thema zurück. Wir müssen die Workloads gestalten. Wir gehen von oben nach unten, bis wir 80 % oder 90 % erreichen. Üblicherweise sind das 10-20 Gruppen. Dann erstellen wir Dateien für pgbench und verwenden dabei Zufallswerte. Manchmal klappt das leider nicht. In Postgres 12 werden wir bessere Möglichkeiten haben, diesen Ansatz zu nutzen.
Auf diese Weise erreichen wir 80-90 % der Gesamtzeit. Was kommt nach dem „@“? Wir schauen uns die Aufrufe an, sehen uns die Prozentsätze an und erkennen, dass wir hier einen bestimmten Prozentsatz erreichen müssen. Aus diesen Prozentsätzen können wir ableiten, wie wir jede der Dateien ausbalancieren. Danach verwenden wir pgbench und legen los.
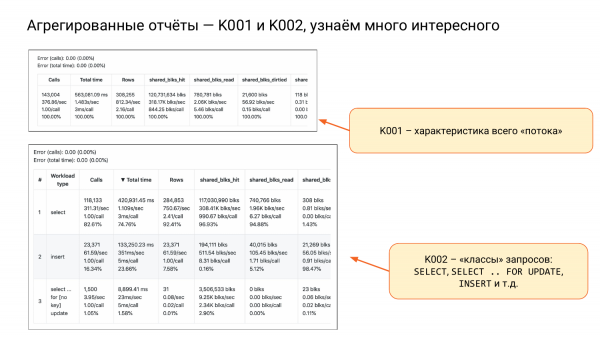
Wir haben außerdem K001 und K002.
K001 ist eine große Zeile mit vier Unterzeilen. Das ist das Merkmal unserer gesamten Last. Schauen Sie sich die zweite Spalte und die zweite Unterzeile an. Wir sehen, dass es ungefähr 1,5 Sekunden pro Sekunde dauert, d.h. wenn wir zwei Kerne haben, wird es gut sein. Wir werden etwa 75 % Auslastung haben, und das wird funktionieren. Wenn wir 10 Kerne haben, können wir uns ganz entspannt zurücklehnen. So können wir die Ressourcen bewerten.
K002 – das nenne ich Anfrageklassen, also SELECT, INSERT, UPDATE, DELETE, sowie SELECT FOR UPDATE, da dieser sperrt.
Hier können wir festhalten, dass SELECT-Abfragen 82 % aller Aufrufe ausmachen, aber nur 74 % der gesamten Zeit beanspruchen. Das bedeutet, sie werden häufig aufgerufen, verbrauchen aber weniger Ressourcen.
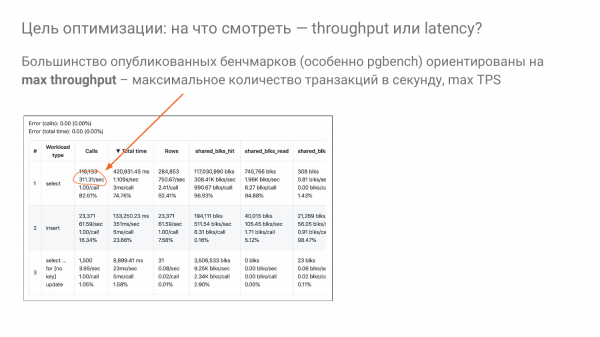
Kommen wir zurück zur Frage: „Wie wählen wir die richtigen shared_buffers aus?“. Ich beobachte, dass die meisten Benchmarks darauf basieren, zu ermitteln, welche Durchsatzrate erreicht wird, also wie hoch die Durchsatzkapazität ist. Diese wird normalerweise in TPS oder QPS gemessen.
Wir versuchen, mit den Tuning-Parametern möglichst viele Transaktionen pro Sekunde aus der Maschine herauszuholen. Hier sind es genau 311 pro Sekunde für SELECT.

Aber niemand fährt mit dem Auto mit voller Geschwindigkeit zur Arbeit und wieder nach Hause. Das wäre dumm. Gleiches gilt für Datenbanken. Wir sollten nicht mit voller Geschwindigkeit fahren, und tatsächlich tut das niemand. Niemand lebt in einer Produktionsumgebung mit 100 % CPU-Last. Auch wenn vielleicht jemand das tut, ist das nicht optimal.
Die Idee ist, dass wir normalerweise etwa 20 % der Möglichkeiten ausnutzen und idealerweise nicht über 50 %. Dabei versuchen wir, die Reaktionszeit für unsere Benutzer zu optimieren. Das heißt, wir müssen unsere Einstellungen so anpassen, dass die Latenz bei 20 % Geschwindigkeit minimal bleibt, um es vereinfacht auszudrücken. Das ist ein Ansatz, den wir auch in unseren Experimenten nutzen möchten.
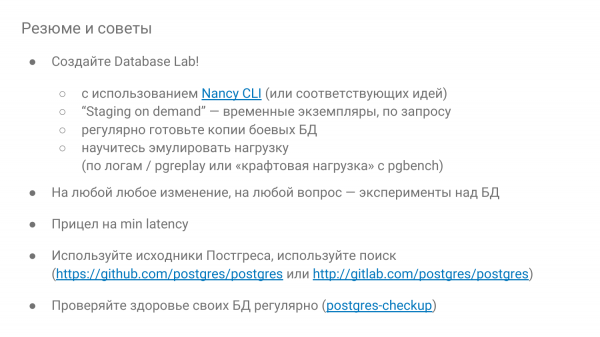
Und abschließend ein paar Empfehlungen:
- Stellen Sie unbedingt einen Database Lab ein.
- Machen Sie es nach Möglichkeit on demand, sodass es für eine gewisse Zeit bereitgestellt wird – spielen Sie herum und werfen Sie es anschließend weg. Wenn Sie Cloud-Dienste haben, ist das selbstverständlich, d. h. haben Sie viel Kapazität.
- Seien Sie neugierig. Und wenn etwas nicht stimmt, überprüfen Sie es mit Experimenten, um zu sehen, wie es sich verhält. Nancy kann genutzt werden, um sich selbst zu schulen und zu prüfen, wie die Datenbank funktioniert.
- Zielen Sie auf eine minimale Reaktionszeit.
- Scheuen Sie sich nicht, mit den Postgres-Quellcodes zu arbeiten. Wenn Sie mit den Quellcodes arbeiten, sollten Sie Englisch verstehen. Dort gibt es viele Kommentare, die alles erklären.
- Überprüfen Sie regelmäßig die Gesundheit der Datenbank, mindestens alle drei Monate manuell oder mit Postgres-checkup.

Fragen
Vielen Dank! Sehr interessantes Thema.
Zwei Dinge.
Ja, zwei Stück. Aber ich habe nicht ganz verstanden. Wenn wir mit Nancy arbeiten, können wir nur einen Parameter ändern oder eine ganze Gruppe?
Wir haben einen Delta-Konfigurator. Sie können dort beliebig viele Parameter gleichzeitig ändern. Aber man muss verstehen, dass es schwierig ist, korrekte Schlüsse zu ziehen, wenn man zu viele Änderungen vornimmt.
Ja. Warum habe ich das gefragt? Weil es schwierig ist, Experimente durchzuführen, wenn man nur einen Parameter hat. Man ändert ihn, schaut, wie es funktioniert, setzt ihn fest und beginnt dann mit dem nächsten.
Es ist möglich, mehrere Parameter gleichzeitig zu ändern, aber das hängt von der Situation ab. Es ist jedoch besser, eine Idee zu testen. Gestern hatten wir eine ähnliche Situation. Wir hatten zwei Konfigurationen und konnten nicht verstehen, warum es einen großen Unterschied gab. Die Idee war, die Dichotomie zu verwenden, um schrittweise zu verstehen, was der Unterschied ist. Man kann die Hälfte der Parameter zuerst gleich machen, dann ein Viertel usw. Alles ist flexibel.
Und ich habe noch eine Frage. Das Projekt ist jung und entwickelt sich. Ist die Dokumentation bereits fertig und gibt es eine detaillierte Beschreibung?
Ich habe dort einen speziellen Link zur Beschreibung der Parameter gesetzt. Das ist vorhanden. Aber vieles fehlt noch. Ich suche Gleichgesinnte und finde sie, wenn ich auftritt. Das ist richtig spannend. Einige arbeiten bereits mit mir zusammen, andere haben geholfen und etwas gemacht. Wenn Sie an diesem Thema interessiert sind, geben Sie bitte Feedback – was fehlt noch?
Sobald wir das Labor eingerichtet haben, könnte es Rückmeldungen geben. Mal sehen. Danke!
Hallo! Vielen Dank für den Vortrag! Ich habe gesehen, dass es Unterstützung für Amazon gibt. Ist eine Unterstützung für GSP geplant?
Das ist eine gute Frage. Wir haben damit begonnen und derzeit pausiert, da wir Kosten sparen möchten. Das bedeutet, dass wir Unterstützung durch das Ausführen auf localhost haben. Sie können selbst eine Instanz erstellen und lokal arbeiten. Übrigens, so machen wir es. Ich mache es im Getlab auch, dort auf GSP. Aber wir sehen momentan keinen Sinn darin, eine solche Orchestrierung durchzuführen, da Google keine günstigen Spot-Instanzen hat. Es gibt ??? Instanzen, aber mit Einschränkungen. Erstens erhalten Sie immer nur einen Rabatt von 70 %, und die Preisgestaltung ist nicht flexibel. Bei Spot-Instanzen erhöhen wir den Preis um 5–10 %, um die Wahrscheinlichkeit zu verringern, dass sie uns abziehen. Das heißt, bei Spot-Instanzen sparen Sie, aber sie können jederzeit weggenommen werden. Wenn Sie die Preise etwas höher als die anderen ansetzen, werden Sie später unweigerlich ausgeschlossen. Bei Google ist die Spezifikationen ganz anders. Zudem gibt es ein sehr ungünstiges Limit – die Instanzen leben nur 24 Stunden. Manchmal möchten wir jedoch 5 Tage lang ein Experiment durchführen. Bei Spot-Instanzen ist das möglich, diese können manchmal monatelang bestehen bleiben.
Hallo! Vielen Dank für Ihren Vortrag! Sie haben das Thema Checkup angesprochen. Wie berechnen Sie die Fehler in den stat_statements?
Das ist eine sehr gute Frage. Ich kann das sehr ausführlich zeigen und erläutern. Kurz gesagt, wir beobachten, wie sich die Gruppensätze entwickelt haben: wie viele weggefallen sind und wie viele neue entstanden sind. Anschließend betrachten wir zwei Metriken: total_time und calls, weshalb es dort zwei Fehler gibt. Außerdem analysieren wir den Beitrag der betroffenen Gruppen. Es gibt zwei Untergruppen: die, die weggegangen sind, und die, die neu hinzugekommen sind. Wir schauen uns an, welchen Einfluss sie auf das Gesamtbild haben.
Haben Sie keine Bedenken, dass dies zwischen den Snapshots zwei- oder dreimal abgebrochen wird?
Das heißt, sie haben sich neu registriert oder wie?
Zum Beispiel wurde diese Anfrage einmal verdrängt, dann kam sie zurück und wurde erneut verdrängt, dann kam sie wieder und wurde wieder verdrängt. Und Sie haben da etwas berechnet, aber wo ist das alles?
Gute Frage, das sollten wir uns anschauen.
Ich habe etwas Ähnliches gemacht. Einfacher, natürlich, ich habe es alleine gemacht. Aber ich musste zurücksetzen, stat_statements zurücksetzen und mich auf den Snapshot konzentrieren, bei dem es weniger als einen bestimmten Anteil war, sodass ich trotzdem nicht das Maximum erreicht habe, was stat_statements ansammeln kann. Und ich gehe davon aus, dass wahrscheinlich nichts verdrängt wurde.
Ja, ja.
Aber ich verstehe nicht, wie ich das anders zuverlässig machen kann.
Leider erinnere ich mich nicht genau, ob wir dort den Anfrage-Text oder den queryid mit pg_stat_statements verwenden und uns darauf beziehen. Wenn wir uns auf queryid beziehen, vergleichen wir theoretisch vergleichbare Dinge.
Nein, er kann zwischen den Snapshots mehrmals verdrängt werden und wieder zurückkommen.
Mit dieser ID?
Ja.
Wir werden das untersuchen. Gute Frage. Es muss geprüft werden. Aber zunächst sehen wir entweder 0…
Natürlich ist das ein seltener Fall, aber ich war überrascht zu erfahren, dass stat_statements dort verdrängt werden kann.
In Pg_stat_statements kann es viele Dinge geben. Wir haben festgestellt, dass, wenn track_utility = on ist, auch Ihre Sets verfolgt werden.
Ja, natürlich.
Und wenn Sie Java Hibernate verwenden, das zufällig ist, beginnt es, die Hashtabelle zu sperren. Und sobald Sie eine sehr belastete Anwendung deaktivieren, haben Sie 50-100 Gruppen. Und dort ist alles mehr oder weniger stabil. Eine der Methoden, um damit umzugehen, besteht darin, pg_stat_statements.max zu erhöhen.
Ja, aber man muss wissen, wie viel. Man sollte es irgendwie im Auge behalten. Genau das mache ich. Das heißt, ich habe pg_stat_statements.max. Und ich schaue, dass ich im Moment des Snapshots etwa 70 % nicht erreicht habe. In Ordnung, das bedeutet, wir haben nichts verloren. Also machen wir einen Reset. Und sammeln erneut. Wenn im nächsten Snapshot weniger als 70 % sind, dann haben wir wahrscheinlich wieder nichts verloren.
Ja. Standardmäßig sind es jetzt 5.000. Und das reicht vielen aus.
Normalerweise – ja.
Video:

P.S. Ich möchte hinzufügen, dass, wenn in Postgres vertrauliche Daten vorhanden sind, die nicht in die Testumgebung gelangen dürfen, man nutzen kann . Das Schema sieht ungefähr folgendermaßen aus:
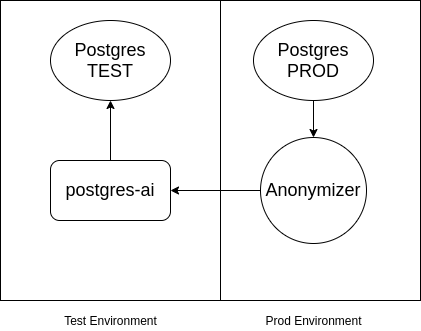
Quelle: habr.com
