

Dieser Beitrag ist entstanden, da unser Team viele Gespräche mit Kunden über die Entwicklung von Anwendungen auf Kubernetes und die spezifischen Anforderungen dieser Entwicklung auf OpenShift hatte.

Wir beginnen normalerweise mit der These, dass Kubernetes einfach Kubernetes ist, während OpenShift eine Kubernetes-Plattform ist, ähnlich wie Microsoft AKS oder Amazon EKS. Jede dieser Plattformen hat ihre eigenen Vorteile, die auf bestimmte Zielgruppen ausgerichtet sind. Im Anschluss fließt das Gespräch dann oft in einen Vergleich der Stärken und Schwächen der jeweiligen Plattformen.
Im Großen und Ganzen dachten wir darüber nach, diesen Beitrag mit einem Fazit zu schreiben wie: „Egal, wo man den Code ausführt – auf OpenShift, AKS, EKS oder auf einem beliebigen benutzerdefinierten Kubernetes (wir nennen es mal KUK) – es ist wirklich einfach, egal wo.“ (Um es kurz zu machen, nennen wir es KUK) – das gilt sowohl dort als auch da.
Anschließend wollten wir ein einfaches „Hello World“-Beispiel nehmen, um zu zeigen, was die Gemeinsamkeiten und Unterschiede zwischen KUK und der Red Hat OpenShift Container Platform (im Folgenden OCP oder einfach OpenShift) sind.
Während des Schreibens dieses Beitrags ist uns aufgefallen, dass wir uns so sehr an OpenShift gewöhnt haben, dass wir gar nicht bemerken, wie es sich zu einer beeindruckenden Plattform entwickelt hat, die weit mehr ist als nur eine Kubernetes-Distribution. Wir nehmen die Reife und Benutzerfreundlichkeit von OpenShift als selbstverständlich hin und übersehen dabei seine Brillanz.
Es ist Zeit für eine aktive Auseinandersetzung, und jetzt werden wir schrittweise den Einsatz unseres "Hello World" sowohl in KUK als auch in OpenShift vergleichen, und das möglichst objektiv (mit vielleicht gelegentlichen persönlichen Einschätzungen zum Thema). Wenn Sie an einer rein subjektiven Meinung zu diesem Thema interessiert sind, können Sie sie . In diesem Beitrag werden wir uns auf Fakten und nur auf Fakten konzentrieren.
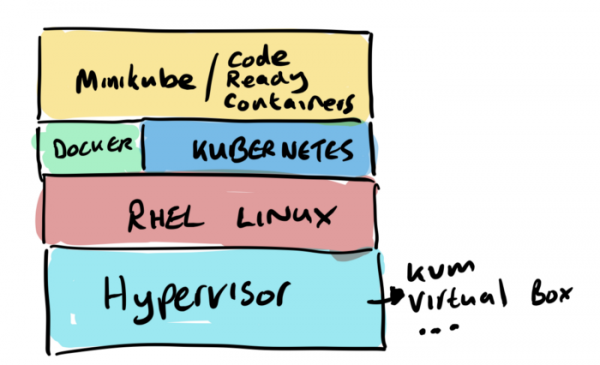
Cluster
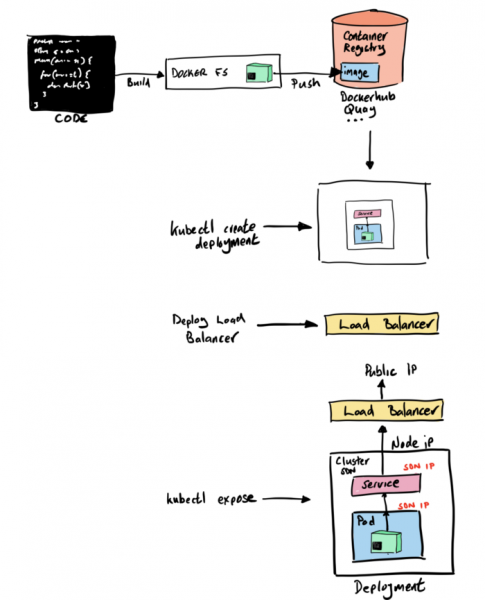
Für unser "Hello World" benötigen wir also Cluster. Um keine Kosten für Server, Register, Netzwerke, Datenübertragungen usw. zu verursachen, sagen wir sofort "nein" zu öffentlich zugänglichen Clouds. Somit wählen wir einen einfachen Single-Node-Cluster auf (für KUK) und (für den OpenShift-Cluster). Beide Optionen sind tatsächlich einfach zu installieren, benötigen jedoch eine erhebliche Menge an Ressourcen auf Ihrem Laptop.
Build auf KUK
Also, legen wir los.
Schritt 1 – Erstellen unseres Container-Images
Beginnen wir damit, unser 'Hello World' auf minikube bereitzustellen. Dazu benötigen Sie:
- 1. Installiertes Docker.
- 2. Installiertes Git.
- 3. Installiertes Maven (in diesem Projekt wird tatsächlich der mvnw-Binary verwendet, daher ist dies nicht unbedingt erforderlich).
- 4. Den Quellcode selbst, d.h. ein Klon des Repositories
Als Nächstes müssen wir ein Quarkus-Projekt erstellen. Keine Sorge, wenn Sie noch nie mit der Website Quarkus.io gearbeitet haben – es ist ganz einfach. Wählen Sie einfach die Komponenten aus, die Sie im Projekt verwenden möchten (RestEasy, Hibernate, Amazon SQS, Camel usw.), und Quarkus konfiguriert automatisch das Maven-Archetyp und stellt alles auf GitHub bereit. Das bedeutet, dass es nur ein Mausklick benötigt – und schon ist es fertig. Dafür lieben wir Quarkus.
Der einfachste Weg, unser 'Hello World' in ein Container-Image zu packen, besteht darin, die quarkus-maven-Erweiterungen für Docker zu verwenden, die die gesamte notwendigen Schritte erledigen. Mit der Einführung von Quarkus wurde es wirklich einfach: Fügen Sie die Erweiterung container-image-docker hinzu und Sie können Images mit Maven-Befehlen erstellen.
./mvnw quarkus:add-extension -Dextensions="container-image-docker"
Und schließlich erstellen wir unser Image mit Maven. Unser Quellcode wird somit zu einem einsatzbereiten Container-Image, das bereits in einer Container-Laufzeitumgebung gestartet werden kann.
./mvnw -X clean package -Dquarkus.container-image.build=true
Das ist alles, jetzt können wir den Container mit dem Befehl docker run starten und unseren Service auf Port 8080 mappen, um darauf zugreifen zu können.
docker run -i --rm -p 8080:8080 gcolman/quarkus-hello-world

Nachdem die Container-Instanz gestartet ist, müssen wir nur noch mit dem Befehl curl überprüfen, dass unser Service funktioniert:
![]()
Alles funktioniert also, und es war tatsächlich ganz einfach.
Schritt 2 – Wir schicken unseren Container in das Container-Image-Repository
Bis jetzt wird das von uns erstellte Image lokal in unserem lokalen Container-Repository gespeichert. Wenn wir dieses Image in unserer Kubernetes-Umgebung verwenden möchten, müssen wir es in ein anderes Repository hochladen. In Kubernetes gibt es dafür keine eigenen Funktionen, deshalb werden wir Docker Hub verwenden. Erstens, weil es kostenlos ist, und zweitens, weil das fast jeder so macht.
Das ist auch sehr einfach, und man benötigt dazu nur ein Konto bei Docker Hub.
Also, lassen Sie uns Docker Hub einrichten und unser Image dorthin hochladen.
Schritt 3 – Kubernetes starten
Es gibt viele Möglichkeiten, eine Kubernetes-Konfiguration für den Start unseres 'Hello World' zu erstellen, aber wir verwenden die einfachste, denn wir sind so...
Zunächst starten wir den Minikube-Cluster:
minikube start
Schritt 4 – Unsere Container-Image bereitstellen
Jetzt müssen wir unseren Code und das Container-Image in Kubernetes-Konfigurationen umwandeln. Mit anderen Worten, wir benötigen eine Pod- und Deployment-Definition, die auf unser Container-Image bei Docker Hub verweist. Eine der einfachsten Möglichkeiten, dies zu tun, besteht darin, den Befehl 'create deployment' auszuführen und auf unser Image zu verweisen:
kubectl create deployment hello-quarkus --image=gcolman/quarkus-hello-world:1.0.0-SNAPSHOT
Mit diesem Befehl haben wir Kubernetes angewiesen, eine Deployment-Konfiguration zu erstellen, die die Pod-Spezifikation für unser Container-Image enthalten sollte. Dieser Befehl wendet auch diese Konfiguration auf unseren Minikube-Cluster an und erstellt ein Deployment, das unser Container-Image herunterlädt und das Pod im Cluster startet.
Schritt 5 – Zugriffsberechtigungen für unseren Service einrichten
Jetzt, da wir unser Container-Image bereitgestellt haben, ist es an der Zeit zu überlegen, wie wir den externen Zugriff auf diesen RESTful-Service konfigurieren, der letztendlich in unserem Code programmiert ist.
Hier gibt es viele Möglichkeiten. Zum Beispiel können wir den Befehl expose verwenden, um automatisch die entsprechenden Kubernetes-Komponenten wie Services und Endpoints zu erstellen. Genau das werden wir tun, indem wir den Befehl expose für unser Deployment-Objekt ausführen:
kubectl expose deployment hello-quarkus — type=NodePort — port=8080
Lassen Sie uns einen Moment bei der Option „— type“ des Befehls expose innehalten.
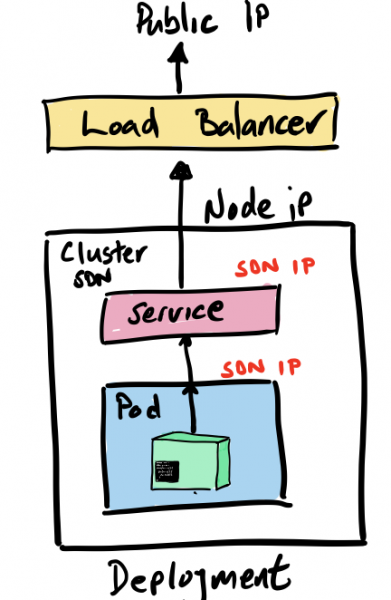
Wenn wir expose ausführen und die notwendigen Komponenten erstellen, um unseren Service zu starten, müssen wir unter anderem sicherstellen, dass wir von außen auf den Service hello-quarkus zugreifen können, der sich innerhalb unseres softwaredefinierten Netzwerks befindet. Der Parameter type ermöglicht es uns, Dinge wie Load-Balancer zu erstellen und zu verbinden, um den Verkehr in dieses Netzwerk zu leiten.
Indem wir beispielsweise type=LoadBalancer, initialisieren wir automatisch einen Load-Balancer in der öffentlichen Cloud, der eine Verbindung zu unserem Kubernetes-Cluster herstellt. Das ist natürlich großartig, aber man muss verstehen, dass eine solche Konfiguration stark an eine bestimmte öffentliche Cloud gebunden ist und es schwieriger sein wird, sie zwischen Kubernetes-Instanzen in verschiedenen Umgebungen zu migrieren.
In unserem Beispiel type=NodePort, das heißt, der Zugriff auf unseren Dienst erfolgt über die IP-Adresse des Knotens und die Portnummer. Diese Option ermöglicht es, keine öffentlichen Clouds zu nutzen, erfordert jedoch einige zusätzliche Schritte. Zuerst benötigen wir einen eigenen Lastenausgleichsmechanismus, weshalb wir einen NGINX-Load-Balancer in unserem Cluster bereitstellen werden.
Schritt 6 – Lastenausgleichsmechanismus einrichten
Minikube bietet eine Reihe von Plattformfunktionen, die das Erstellen der benötigten Komponenten für den externen Zugriff erleichtern, wie z.B. Ingress-Controller. Minikube wird mit dem Nginx-Ingress-Controller geliefert, und wir müssen ihn nur aktivieren und konfigurieren.
minikube addons enable ingress
Jetzt erstellen wir mit nur einem Befehl einen Nginx-Ingress-Controller, der innerhalb unseres Minikube-Clusters läuft:
ingress-nginx-controller-69ccf5d9d8-j5gs9 1/1 Running 1 33m
Schritt 7 – Ingress konfigurieren
Jetzt müssen wir den Nginx-Ingress-Controller so einstellen, dass er Anfragen an hello-quarkus verarbeitet.

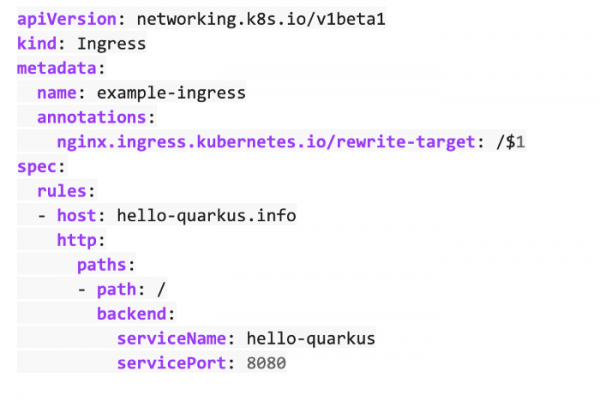
Und schließlich müssen wir diese Konfiguration anwenden.
kubectl apply -f ingress.yml
![]()
Da wir das alles auf unserem Computer machen, fügen wir einfach die IP-Adresse unseres Knotens in die Datei /etc/hosts ein, um HTTP-Anfragen an unser Minikube an den NGINX-Load-Balancer zu leiten.
192.168.99.100 hello-quarkus.info
Alles klar, unser minikube-Service ist jetzt über den Nginx Ingress-Controller extern erreichbar.
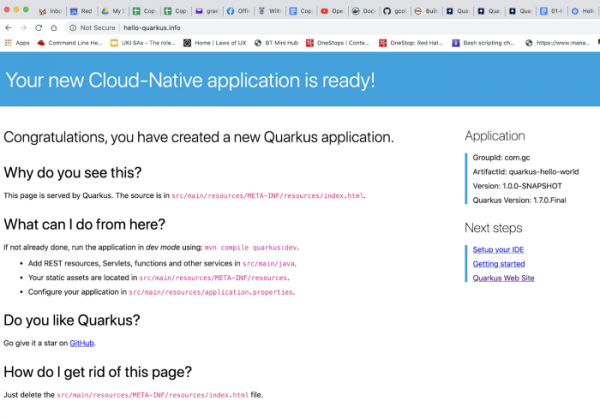
Na, das war doch einfach, oder? Oder nicht ganz?
Starten auf OpenShift (Code Ready Containers)
Jetzt schauen wir uns an, wie das Ganze auf der Red Hat OpenShift Container Platform (OCP) funktioniert.
Wie bei minikube wählen wir das Szenario mit einem einzelnen OpenShift-Cluster in Form von Code Ready Containers (CRC). Früher bekannt als minishift basierend auf dem OpenShift Origin-Projekt, ist dies jetzt CRC und baut auf der Red Hat OpenShift Container Platform auf.
Hier können wir uns nicht zurückhalten und müssen sagen: „OpenShift ist großartig!“
Ursprünglich dachten wir, dass die Entwicklung auf OpenShift sich nicht von der Entwicklung auf Kubernetes unterscheidet. Im Grunde genommen ist das auch richtig. Doch während wir diesen Beitrag schrieben, erinnerten wir uns daran, wie viele unnötige Schritte nötig sind, wenn man kein OpenShift hat, und deshalb ist es, um es nochmal zu sagen, großartig. Wir lieben es, wenn alles einfach ist, und wie viel einfacher unser Beispiel im Vergleich zu minikube auf OpenShift bereitgestellt und gestartet wird, hat uns motiviert, diesen Beitrag zu schreiben.
Lassen Sie uns den Prozess durchgehen und sehen, was wir tun müssen.
In unserem Beispiel mit minikube haben wir mit Docker begonnen... Stopp, wir benötigen Docker nicht mehr auf der Maschine.
Und lokale git benötigen wir nicht.
Und Maven ist nicht erforderlich.
Und es ist nicht nötig, das Container-Image manuell zu erstellen.
Und wir müssen kein Container-Image-Repository suchen.
Und es ist nicht erforderlich, einen Ingress-Controller zu installieren.
Und wir müssen auch den Ingress nicht konfigurieren.
Haben Sie es verstanden? Um unsere Anwendung in OpenShift bereitzustellen und zu starten, brauchen wir nichts davon. Der gesamte Prozess sieht wie folgt aus.
Schritt 1 – Starten Sie Ihren OpenShift-Cluster
Wir verwenden Code Ready Containers von Red Hat, das im Grunde das gleiche wie Minikube ist, jedoch mit einem vollwertigen ein-Knoten-Openshift-Cluster.
crc start
Schritt 2 – Bauen und Bereitstellen der Anwendung im OpenShift-Cluster
Gerade in diesem Schritt zeigt sich die Einfachheit und Benutzerfreundlichkeit von OpenShift in vollem Umfang. Wie in allen Kubernetes-Distributionen haben wir viele Möglichkeiten, eine Anwendung im Cluster auszuführen. Und wie im Fall von KUK wählen wir absichtlich die einfachste.
OpenShift wurde immer als Plattform zum Erstellen und Ausführen von Containeranwendungen konzipiert. Der Aufbau von Containern war schon immer ein wesentlicher Bestandteil dieser Plattform, weshalb es hier viele zusätzliche Kubernetes-Ressourcen für die entsprechenden Aufgaben gibt.
Wir werden den OpenShift-Prozess Source 2 Image (S2I) verwenden, der mehrere verschiedene Möglichkeiten bietet, um unseren Quellcode (Code oder Binärdateien) in ein Container-Image zu verwandeln, das im OpenShift-Cluster läuft.
Dazu benötigen wir zwei Dinge:
- Unseren Quellcode in einem Git-Repository.
- Ein Builder-Image, auf dessen Basis die Erstellung erfolgt.
Es gibt viele solcher Images, sowohl von Red Hat als auch von der Community unterstützt, und wir werden das OpenJDK-Image verwenden, da ich ein Java-Anwendung erstellen möchte.
Die S2I-Erstellung kann sowohl über die grafische Konsole von OpenShift Developer als auch über die Kommandozeile gestartet werden. Wir verwenden den Befehl new-app und geben an, wo das Builder-Image und unser Quellcode zu finden sind.
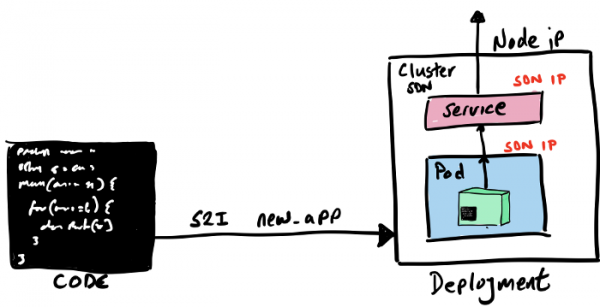
oc new-app registry.access.redhat.com/ubi8/openjdk-11:latest~https://github.com/gcolman/quarkus-hello-world.git
Alles klar, unsere Anwendung ist erstellt. Währenddessen hat der S2I-Prozess die folgenden Dinge ausgeführt:
- Ich habe einen Service-Build-Pod für verschiedene Aufgaben im Zusammenhang mit der Anwendungserstellung erstellt.
- Ich habe die OpenShift Build-Konfiguration erstellt.
- Ich habe das Builder-Image im internen Docker-Registry von OpenShift heruntergeladen.
- Ich habe 'Hello World' in ein lokales Repository geklont.
- Ich habe gesehen, dass ein Maven-POM vorhanden ist, und daher habe ich die Anwendung mit Maven kompiliert.
- Ich habe ein neues Container-Image erstellt, das die kompilierte Java-Anwendung enthält, und dieses Image im internen Container-Registry gespeichert.
- Ich habe ein Kubernetes-Deployment mit den Spezifikationen für den Pod, den Service usw. erstellt.
- Ich habe das Deployment des Container-Images gestartet.
- Ich habe den Service-Build-Pod entfernt.
In dieser Liste gibt es viele Punkte, aber das Wichtigste ist, dass der gesamte Build ausschließlich innerhalb von OpenShift stattfindet, das interne Docker-Registry befindet sich innerhalb von OpenShift, und der Build-Prozess erstellt alle Kubernetes-Komponenten und startet sie im Cluster.
Wenn man die Ausführung von S2I in der Konsole visuell verfolgt, kann man sehen, wie der Build-Pod bei der Ausführung des Builds gestartet wird.

Lassen Sie uns nun die Protokolle des Builder-Pods betrachten: Zuerst sieht man, wie Maven seine Arbeit erledigt und die Abhängigkeiten für den Build unserer Java-Anwendung herunterlädt.
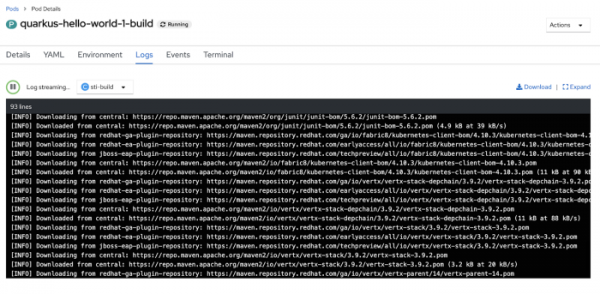
Nachdem der Maven-Build abgeschlossen ist, wird das Container-Image gebaut und anschließend in das interne Repository hochgeladen.
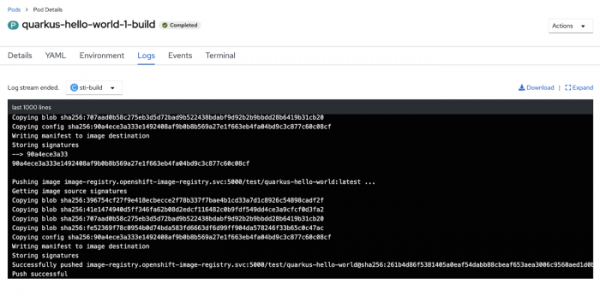
Der gesamte Build-Prozess ist nun abgeschlossen. Lassen Sie uns sicherstellen, dass die Pods und Services unserer Anwendung im Cluster gestartet wurden.
oc get service
![]()
Das war's. Und das mit nur einem Befehl. Jetzt müssen wir nur noch diesen Service für den externen Zugriff verfügbar machen.
Schritt 3 – Den Service für den externen Zugriff freigeben
Wie beim KUB benötigt auch unser „Hello World“ auf der OpenShift-Plattform einen Router, um den externen Datenverkehr zu den Services im Cluster zu leiten. In OpenShift ist dies ganz einfach. Erstens ist im Cluster standardmäßig die Routing-Komponente HAProxy installiert (diese kann gegen NGINX ausgetauscht werden). Zweitens gibt es spezielle, anpassbare Ressourcen, die als Routes bezeichnet werden und an die Ingress-Objekte im klassischen Kubernetes erinnern (tatsächlich haben die OpenShift-Routes das Design der Ingress-Objekte beeinflusst, die nun ebenfalls in OpenShift verwendet werden können). Für unser „Hello World“ und in vielen anderen Fällen reicht jedoch der Standard-Route ohne weitere Anpassungen aus.
Um einen routbaren FQDN für „Hello World“ zu erstellen (ja, OpenShift hat seinen eigenen DNS für die Namensweiterleitung von Diensten), führen wir einfach ein Expose für unseren Dienst aus:
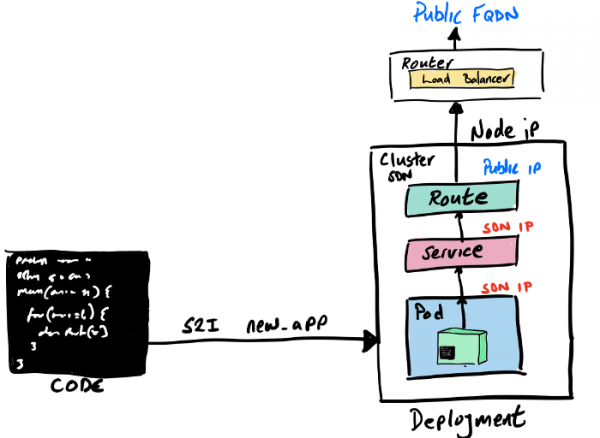
oc expose service quarkus-hello-world
Wenn wir uns die gerade erstellte Route ansehen, finden wir den FQDN und weitere Routing-Informationen:
oc get route
![]()
Und schließlich rufen wir unseren Dienst im Browser auf:

Das war wirklich einfach!
Wir lieben Kubernetes und alles, was diese Technologie ermöglicht, und wir schätzen Einfachheit und Benutzerfreundlichkeit. Kubernetes wurde entwickelt, um den Betrieb von verteilten, skalierbaren Containern erheblich zu vereinfachen, aber um Anwendungen jetzt einzuführen, reicht diese Einfachheit oft nicht aus. Hier kommt OpenShift ins Spiel, das mit der Zeit geht und Kubernetes anbietet, das in erster Linie auf Entwickler ausgerichtet ist. Es wurde ein erheblicher Aufwand betrieben, um die OpenShift-Plattform speziell auf Entwickler zuzuschneiden, einschließlich der Erstellung von Werkzeugen wie S2I, ODI, dem Entwicklerportal, dem OpenShift Operator Framework, der Integration mit IDEs, Entwicklertoolskatalogen, der Helm-Integration, Monitoring und vielen weiteren.
Wir hoffen, dass dieser Artikel für Sie interessant und nützlich war. Weitere Ressourcen, Materialien und andere nützliche Dinge zur Entwicklung auf der OpenShift-Plattform finden Sie im Portal .
Quelle: habr.com
