


Viele glauben, dass es ausreicht, die Anwendung auf Kubernetes zu migrieren (entweder mit Helm oder manuell) – und alles wird gut. Doch es ist nicht ganz so einfach.
Der Befehl Übersetzt von DevOps-Ingenieur Julian Gindi. Er erläutert die Herausforderungen, mit denen sein Unternehmen während der Migration konfrontiert war, damit Sie nicht dieselben Fehler machen.
Schritt eins: Pod-Anfragen und Limits konfigurieren
Lassen Sie uns mit der Einrichtung einer sauberen Umgebung beginnen, in der unsere Pods laufen werden. Kubernetes ist exzellent im Planen von Pods und im Umgang mit Fehlerszenarien. Doch es stellte sich heraus, dass der Scheduler manchmal Probleme hat, einen Pod bereitzustellen, wenn er Schwierigkeiten hat abzuschätzen, wie viele Ressourcen er für einen reibungslosen Betrieb benötigt. Hier kommen die Ressourcennachfragen und Limits ins Spiel. Es gibt viele Diskussionen über den besten Ansatz zur Konfiguration von Anfragen und Limits. Manchmal scheint es eher Kunst als Wissenschaft zu sein. Hier ist unser Ansatz.
Pod-Anfragen sind die Hauptwerte, die vom Scheduler für die optimale Platzierung des Pods verwendet werden.
Von : In der Filterphase wird eine Menge von Knoten bestimmt, auf denen Pods eingeplant werden können. Zum Beispiel überprüft der Filter PodFitsResources, ob ausreichend Ressourcen auf dem Knoten vorhanden sind, um die spezifischen Anforderungen des Pods zu erfüllen.
Wir verwenden die Anwendungsanfragen, um zu bewerten, wie viele Ressourcen tatsächlich für die ordnungsgemäße Funktion der Anwendung benötigt werden. Dadurch kann der Scheduler die Knoten realistisch anordnen. Ursprünglich wollten wir die Anfragen mit einem Puffer festlegen, um sicherzustellen, dass genügend Ressourcen für jeden Pod zur Verfügung stehen, bemerkten jedoch, dass die Planungszeit erheblich anstieg und einige Pods nicht vollständig eingeplant wurden, als hätten sie keine Ressourcennachfragen erhalten.
In diesem Fall "drückte" der Scheduler häufig Pods hinaus und konnte sie nicht erneut planen, da die Steuerungsebene nicht wusste, wie viele Ressourcen die Anwendung benötigen würde, was ein Schlüsselfaktor im Planungsalgorithmus darstellt.
Limits für Pods sind eine klarere Begrenzung für einen Pod. Es handelt sich um die maximale Menge an Ressourcen, die der Cluster dem Container zuweisen wird.
Noch einmal, aus : Wenn für einen Container ein Limits von 4 GiB an Arbeitsspeicher festgelegt ist, wird kubelet (und die Container-Runtime) ihn zwangsweise einhalten. Die Runtime lässt es dem Container nicht zu, mehr Ressourcen als das festgelegte Limit zu verwenden. Beispielsweise beendet der Kernel den Prozess im Container mit einem „Out of Memory“-Fehler (OOM), wenn dieser versucht, mehr als den erlaubten Arbeitsspeicher zu verwenden.
Ein Container kann immer mehr Ressourcen nutzen, als in der Ressourcennachfrage angegeben, aber niemals mehr als das, was im Limit festgelegt ist. Es ist schwierig, diesen Wert richtig zu bestimmen, aber er ist sehr wichtig.
Idealerweise möchten wir, dass die Ressourcenanforderungen des Pods während des Lebenszyklus des Prozesses variieren, ohne andere Prozesse im System zu stören – dies ist das Ziel der Limitsetzung.
Leider kann ich keine konkreten Vorgaben machen, welche Werte festgelegt werden sollten, aber wir halten uns an folgende Richtlinien:
- Mit einem Lasttestinstrument simulieren wir das Basisverkehrsniveau und überwachen die Ressourcennutzung des Pods (Speicher und CPU).
- Wir setzen die Pod-Anforderungen auf einen willkürlich niedrigen Wert (mit Ressourcengrenzen, die etwa fünfmal so hoch sind wie die Anforderungen) und beobachten. Wenn die Anforderungen zu niedrig sind, kann der Prozess nicht gestartet werden, was häufig zu mysteriösen Laufzeitfehlern in Go führt.
Ich möchte darauf hinweisen, dass höhere Ressourcengrenzen die Planung erschweren, da der Pod einen Zielknoten mit ausreichenden verfügbaren Ressourcen benötigt.
Stellen Sie sich eine Situation vor, in der Sie einen leichtgewichtigen Webserver mit einem sehr hohen Ressourcengrenzwert haben, z. B. 4 GB RAM. Wahrscheinlich muss dieser Prozess horizontal skaliert werden, und jedes neue Modul muss auf einem Knoten mit mindestens 4 GB verfügbarem RAM geplant werden. Wenn ein solcher Knoten nicht existiert, muss der Cluster einen neuen Knoten einführen, um diesen Pod zu verarbeiten, was einige Zeit in Anspruch nehmen kann. Es ist wichtig, eine minimale Differenz zwischen den Ressourcenausforderungen und den Grenzen zu erreichen, um ein schnelles und reibungsloses Skalieren zu gewährleisten.
Schritt zwei: Konfiguration der Liveness- und Readiness-Tests
Dies ist ein weiteres wichtiges Thema, das häufig in der Kubernetes-Community diskutiert wird. Es ist entscheidend, die Konzepte von Liveness- und Readiness-Tests gut zu verstehen, da sie Mechanismen für den stabilen Betrieb von Software bereitstellen und Downtime minimieren. Allerdings können sie die Leistung Ihrer Anwendung erheblich beeinträchtigen, wenn sie nicht richtig konfiguriert sind. Nachfolgend finden Sie eine kurze Zusammenfassung, was beide Tests sind.
Liveness zeigt, ob der Container läuft. Wenn er fehlschlägt, beendet kubelet den Container, und die Restart-Policy wird aktiviert. Wenn der Container keinen Liveness-Test hat, wird der Standardstatus als Erfolg betrachtet — so steht es in .
Liveness-Tests sollten kostengünstig sein, das bedeutet, dass sie nicht viele Ressourcen verbrauchen dürfen, weil sie häufig ausgeführt werden und Kubernetes informieren sollen, dass die Anwendung läuft.
Wenn Sie den Parameter auf jede Sekunde setzen, fügt das eine Anfrage pro Sekunde hinzu, daher sollten Sie beachten, dass zusätzliche Ressourcen benötigt werden, um diesen Traffic zu verarbeiten.
In unserem Unternehmen überprüfen Liveness-Tests die Hauptkomponenten der Anwendung, selbst wenn die Daten (z. B. aus einer entfernten Datenbank oder dem Cache) nicht vollständig verfügbar sind.
Wir haben in den Anwendungen einen Endpunkt für die "Betriebsbereitschaft" eingerichtet, der einfach den HTTP-Statuscode 200 zurückgibt. Dies zeigt an, dass der Prozess läuft und Anfragen bearbeiten kann (aber noch keinen Traffic).
Probe Readiness zeigt an, ob der Container bereit ist, Anfragen zu bearbeiten. Wenn die Readiness-Probe fehlschlägt, entfernt der Endpoint-Controller die IP-Adresse des Pods aus den Endpunkten aller Dienste, die mit diesem Pod verbunden sind. Dies wird auch in der Kubernetes-Dokumentation erwähnt.
Readiness-Proben benötigen mehr Ressourcen, da sie so im Backend ausgeführt werden müssen, dass sie die Bereitschaft der Anwendung zur Annahme von Anfragen anzeigen.
In der Community gibt es viele Diskussionen darüber, ob man direkt auf die Datenbank zugreifen sollte. Angesichts der Kosten (Überprüfungen erfolgen häufig, können jedoch angepasst werden) haben wir entschieden, dass für einige Anwendungen die Bereitschaft zur Bearbeitung des Traffics nur dann zählt, wenn sichergestellt ist, dass Einträge aus der Datenbank zurückgegeben werden. Gut durchdachte Bereitschaftsprüfungen haben ein höheres Verfügbarkeitsniveau gewährleistet und Ausfallzeiten während der Bereitstellung beseitigt.
Wenn Sie sich entscheiden, eine Datenbankabfrage zur Überprüfung der Bereitschaft Ihrer Anwendung durchzuführen, stellen Sie sicher, dass sie so kostengünstig wie möglich ist. Nehmen wir diese Abfrage:
SELECT small_item FROM table LIMIT 1Hier ist ein Beispiel, wie wir diese beiden Werte in Kubernetes einstellen:
livenessProbe:
httpGet:
path: /api/liveness
port: http
readinessProbe:
httpGet:
path: /api/readiness
port: http periodSeconds: 2
Es können einige zusätzliche Konfigurationsparameter hinzugefügt werden:
initialDelaySeconds— wie viele Sekunden zwischen dem Start des Containers und dem Beginn des Probe-Starts vergehen.periodSeconds— der Warteintervall zwischen den Probeläufen.timeoutSeconds— die Anzahl der Sekunden, nach deren Ablauf der Pod als fehlerhaft angesehen wird. Normaler Timeout.failureThreshold— die Anzahl der Testfehler, bevor ein Neustartsignal an den Pod gesendet wird.successThreshold— die Anzahl erfolgreicher Prüfungen, die erforderlich ist, bevor der Pod in den Bereitstellungszustand übergeht (nach einem Fehler, wenn der Pod gestartet oder wiederhergestellt wird).
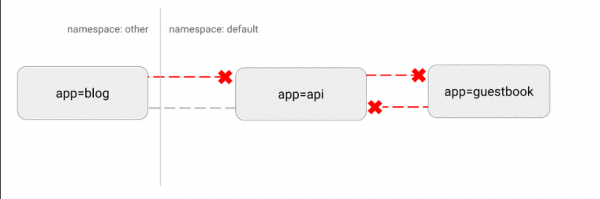
Schritt drei: Konfiguration der standardmäßigen Netzwerkrichtlinien für den Pod
In Kubernetes gibt es eine „flache“ Netzwerktopologie, in der sich standardmäßig alle Pods direkt untereinander verbinden. In einigen Fällen kann dies unerwünscht sein.
Ein potenzielles Sicherheitsproblem besteht darin, dass ein Angreifer eine verwundbare Anwendung nutzen könnte, um Verkehr an alle Pods im Netzwerk zu senden. Wie in vielen Bereichen der Sicherheit gilt hier das Prinzip der geringsten Privilegien. Idealerweise sollten Netzwerkrichtlinien eindeutig angeben, welche Verbindungen zwischen Pods erlaubt sind und welche nicht.
Zum Beispiel zeigt die folgende einfache Richtlinie, die gesamten eingehenden Verkehr für einen bestimmten Namensraum verbietet:
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
Visualisierung dieser Konfiguration:
(https://miro.medium.com/max/875/1*-eiVw43azgzYzyN1th7cZg.gif)
Mehr Details .
Schritt vier: Nicht-standardverhalten mit Hooks und Init-Containern
Eine unserer Hauptaufgaben war es, Deployments in Kubernetes ohne Ausfallzeiten für Entwickler zu gewährleisten. Dies gestaltet sich schwierig, da es zahlreiche Möglichkeiten zum Beenden von Anwendungen und zur Freigabe genutzter Ressourcen gibt.
Besondere Schwierigkeiten entstanden mit . Wir stellten fest, dass bei der sequenziellen Bereitstellung dieser Pods die aktiven Verbindungen unterbrochen wurden, bevor sie erfolgreich abgeschlossen waren.
Nach umfangreichen Recherchen im Internet stellte sich heraus, dass Kubernetes nicht wartet, bis die Nginx-Verbindungen erschöpft sind, bevor es das Pod beendet. Mit Hilfe des Pre-Stop-Hooks implementierten wir diese Funktionalität und beseitigten damit vollständig die Ausfallzeiten:
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
Aber nginx-killer.sh:
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
done
Eine weitere äußerst nützliche Paradigme ist die Verwendung von Init-Containern zur Verarbeitung des Starts spezifischer Anwendungen. Dies ist besonders hilfreich, wenn Sie einen ressourcenintensiven Datenbankmigrationprozess haben, der vor dem Start der Anwendung durchgeführt werden muss. Für diesen Prozess können Sie auch ein höheres Ressourcenkontingent angeben, ohne ein solches Limit für die Hauptanwendung festzulegen.
Ein weiteres gängiges Schema besteht darin, im Init-Container auf Geheimnisse zuzugreifen, die diese Anmeldedaten dem Hauptmodul bereitstellen und so unbefugten Zugriff auf die Geheimnisse aus dem eigentlichen Anwendungsmodul verhindern.
Wie üblich aus der Dokumentation zitiert: Init-Container führen benutzerdefinierten Code oder Dienstprogramme sicher aus, die andernfalls die Sicherheit des Anwendungscontainerbildes beeinträchtigen würden. Durch die getrennte Speicherung unnötiger Werkzeuge reduzieren Sie die Angriffsfläche des Anwendungscontainerbildes.
Schritt fünf: Kernkonfiguration
Zuletzt möchten wir eine fortgeschrittene Technik vorstellen.
Kubernetes ist eine äußerst flexible Plattform, die es Ihnen erlaubt, Workloads nach Ihren Vorstellungen zu verwalten. Wir verfügen über eine Vielzahl von hochleistungsfähigen Anwendungen, die extrem ressourcenintensiv sind. Nach umfangreichen Lasttests haben wir festgestellt, dass eine dieser Anwendungen Schwierigkeiten hat, den erwarteten Datenverkehr zu bewältigen, wenn die Standard-Kubernetes-Einstellungen angewendet werden.
Kubernetes ermöglicht jedoch das Starten eines privilegierten Containers, der die Kernelparameter nur für einen bestimmten Pod ändert. Dies haben wir verwendet, um die maximale Anzahl an offenen Verbindungen zu ändern:
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "sysctl -w net.core.somaxconn=32768"]
Dies ist eine fortgeschrittenere Technik, die oft nicht erforderlich ist. Sollte Ihre Anwendung jedoch mit einer hohen Last kämpft, können Sie versuchen, einige dieser Parameter anzupassen. Weitere Informationen zu diesem Prozess und wie Sie verschiedene Werte einstellen können, finden Sie wie immer .
Zusammenfassung
Obwohl Kubernetes wie eine sofort einsatzbereite Lösung erscheinen mag, sind einige wesentliche Schritte notwendig, um den reibungslosen Betrieb der Anwendungen sicherzustellen.
Während der gesamten Migration zu Kubernetes ist es wichtig, dem „Zyklus des Lasttests“ zu folgen: Sie starten die Anwendung, testen sie unter Last, beobachten die Metriken und das Verhalten beim Skalieren, passen die Konfiguration basierend auf diesen Daten an und wiederholen dann diesen Zyklus.
Bewerten Sie realistisch den erwarteten Datenverkehr und versuchen Sie, über diese Schätzung hinauszugehen, um zu sehen, welche Komponenten zuerst ausfallen. Mit einem solchen iterativen Ansatz könnte es genügen, nur einige der empfohlenen Maßnahmen zu befolgen. Es könnte jedoch auch eine gründlichere Anpassung erforderlich sein.
Stellen Sie sich immer folgende Fragen:
- Wie viel Ressourcen verbrauchen die Anwendungen und wie wird sich dieser Bedarf ändern?
- Was sind die tatsächlichen Anforderungen an das Skalieren? Wie viel Verkehr wird die Anwendung im Durchschnitt verarbeiten? Und wie sieht es mit dem Spitzendatenverkehr aus?
- Wie oft benötigt der Dienst horizontale Skalierung? Wie schnell müssen neue Pods bereitgestellt werden, um den Traffic zu bewältigen?
- Wie korrekt wird die Arbeit der Pods beendet? Ist dies überhaupt erforderlich? Kann ein Deployment ohne Downtime erreicht werden?
- Wie können Sicherheitsrisiken minimiert und Schäden durch kompromittierte Pods begrenzt werden? Gibt es Dienste mit Berechtigungen oder Zugängen, die nicht benötigt werden?
Kubernetes bietet eine außergewöhnliche Plattform, die es ermöglicht, bewährte Praktiken für die Bereitstellung von Tausenden von Diensten im Cluster zu nutzen. Dennoch sind nicht alle Anwendungen gleich. Manchmal erfordert die Implementierung ein wenig mehr Aufwand.
Glücklicherweise bietet Kubernetes die erforderlichen Anpassungen, um alle technischen Ziele zu erreichen. Durch die Kombination aus Ressourcenauslastungsanforderungen und -limits, Liveness- und Readiness-Probes, Init-Containern, Netzwerk-Richtlinien und benutzerdefinierter Kernel-Konfiguration können Sie hohe Leistung bei gleichzeitiger Fehlertoleranz und schneller Skalierbarkeit erzielen.
Weitere Leseempfehlungen:
- .
- .
- .
Quelle: habr.com
