

Hinweis.: Die Autorin dieses Materials ist Cindy Sridharan, eine Ingenieurin bei imgix, die sich mit API-Entwicklung und insbesondere mit dem Testen von Microservices beschäftigt. In diesem Artikel teilt sie ihre umfassende Perspektive zu den aktuellen Herausforderungen der verteilten Tracing-Technologie, wo ihr zufolge ein Mangel an wirklich effektiven Werkzeugen zur Lösung relevanter Probleme besteht.
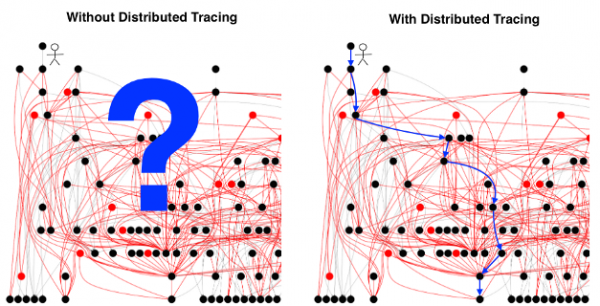
[Die Abbildung stammt aus über verteiltes Tracing.]
Es wird angenommen, dass schwierig zu implementieren ist und die Ergebnisse Die Schwierigkeiten beim Tracing werden durch zahlreiche Gründe erklärt, wobei häufig auf den hohen Aufwand verwiesen wird, der erforderlich ist, um jedes Systemkomponente so zu konfigurieren, dass die entsprechenden Header mit jeder Anfrage übertragen werden. Auch wenn dieses Problem tatsächlich besteht, kann es keineswegs als unüberwindbar bezeichnet werden. Es erklärt zudem nicht, warum Entwickler Tracing (selbst wenn es bereits aktiv ist) nicht besonders schätzen.
Die größte Herausforderung bei verteiltem Tracing liegt nicht in der Datensammlung, der Standardisierung von Verteilungsformaten und der Darstellung von Ergebnissen, noch darin, festzustellen, wann, wo und wie Abtastungen durchgeführt werden. Ich möchte keineswegs als trivial diese 'Usability-Probleme' darstellen – tatsächlich gibt es bedeutende technische und (wenn wir wirklich Open-Source-Standards und -Protokolle betrachten) politische Herausforderungen, die überwunden werden müssen, damit diese Probleme als gelöst gelten können. Endbenutzererfahrung
nichts Wesentliches ändern wird. Das Tracing könnte weiterhin wenig praktische Vorteile in den häufigsten Debugging-Szenarien bieten – selbst nachdem es implementiert wurde. Solch ein unähnliches TracingVerteiltes Tracing umfasst mehrere auseinanderliegende Komponenten:
Ausstattung von Anwendungen und Middleware mit Kontrollmitteln;
Übertragung des verteilten Kontexts;
- Sammlung von Traces;
- Speicherung von Traces;
- deren Abruf und Visualisierung.
- хранение трассировок;
- их извлечение и визуализация.
Viele Diskussionen über verteilte Tracing-Methoden erweisen sich als um die Betrachtung dieser als eine Art unärer Operation, deren einzige Absicht darin besteht, die vollständige Diagnose des Systems zu unterstützen. Dies hängt stark damit zusammen, wie sich historisch das Verständnis für verteilte Tracing-Methoden entwickelt hat. In , als die Quellcodes von Zipkin veröffentlicht wurden, wurde erwähnt, dass es [Zipkin] Twitter schneller macht. Die ersten kommerziellen Angebote zur Tracing-Methodik wurden ebenfalls als .
Hinweis.: Damit der folgende Text besser aufgenommen wird, definieren wir zwei grundlegende Begriffe gemäß :
- Span ist das grundlegende Element des verteilten Tracings. Es beschreibt einen bestimmten Arbeitsablauf (z. B. eine Datenbankanfrage) mit einem Namen, Zeitstempel für den Beginn und das Ende, Tags, Logs und Kontext.
- Spans enthalten in der Regel Verweise auf andere Spans, was das Zusammenführen mehrerer Spans in Trace ermöglicht — eine Visualisierung des Lebenszyklus einer Anfrage während ihrer Bewegung durch ein verteiltes System.
Trace-Daten enthalten äußerst wertvolle Informationen, die bei Aufgaben wie: Produktionstests, Durchführung von Notfallwiederherstellungstests, Fehlerinjektionstests usw. helfen können. Tatsächlich nutzen bereits einige Unternehmen das Trace für solche Zwecke. Beginnen wir damit, dass noch weitere Anwendungen hat, über das bloße Übertragen von Spans in das Speichersystem hinaus:
- Beispielsweise Uber die Ergebnisse von Traces, um Test- und Produktionsverkehr zu unterscheiden.
- Facebook Trace-Daten zur Analyse des kritischen Pfades und um den Verkehr während regelmäßiger Notfallwiederherstellungstests umzuleiten.
- Auch das soziale Netzwerk Jupyter-Notebooks, die es Entwicklern ermöglichen, beliebige Anfragen auf den Ergebnissen von Traces auszuführen.
- Befürworter (Lineage Driven Failure Injection) verteilte Traces für Fehlerinjektionstests.
Keiner der oben genannten Ansätze gehört vollständig zum Szenario Debugging, bei dem der Ingenieur versucht, ein Problem zu lösen, indem er sich die Trace ansieht.
Wenn es allerdings zum Debugging-Szenario kommt, bleibt das primäre Interface das Diagramm Traceview (obwohl einige sie auch nennen „Gantt-Diagramm“ oder „Kaskadendiagramm“). Darunter Traceview habe ich alle Spans und zugehörigen Metadaten, die zusammen einen Trace bilden. Jedes Open-Source-Trace-System sowie jede kommerzielle Trace-Lösung bietet ein Traceview Benutzeroberfläche zur Visualisierung, Detaillierung und Filterung von Traces.
Das Problem mit allen Trace-Systemen, mit denen ich bisher in Kontakt gekommen bin, ist, dass die finale Visualisierung (Trace-View) fast vollständig die Eigenschaften des Trace-Generierungsprozesses widerspiegelt. Selbst wenn alternative Visualisierungen angeboten werden: Intensitätskarten (Heatmaps), Servicetopologien, Verzögerungshistogramme (Latency) – am Ende führen sie alle zu Traceview.
Früher habe ich dass die meisten „Innovationen“ im Bereich Traceing hinsichtlich UI/UX anscheinend auf zusätzlicher Metadaten in den Trace, das Einfügen von Informationen mit hoher Kardinalität (High-Cardinality) oder die Möglichkeit zur Detaillierung bestimmter Spans oder zur Durchführung von Abfragen beschränkt sind. zwischen- und innerhalb-traceverwendet. Traceview bleibt das Hauptmittel zur Visualisierung. Solange diese Situation bestehen bleibt, wird verteilte Nachverfolgung (im besten Fall) den vierten Platz als Debugging-Tool einnehmen, hinter Metriken, Logs und Stack-Traces und im schlimmsten Fall zu einer nutzlosen Geld- und Zeitverschwendung führen.
Das Problem mit Traceview
Zweck Traceview ist, ein vollständiges Bild der Bewegung einer einzelnen Anfrage durch alle relevanten Komponenten des verteilten Systems zu liefern. Einige fortschrittlichere Nachverfolgungssysteme ermöglichen die Detaillierung einzelner Spans und die zeitliche Aufschlüsselung. innerhalb eines Prozesses (wenn Spans funktionale Grenzen haben).
Die grundlegende Voraussetzung für die Architektur von Mikrodiensten ist die Idee, dass die organisatorische Struktur mit den Bedürfnissen des Unternehmens wächst. Befürworter von Mikrodiensten behaupten, dass die Verteilung verschiedener Geschäftsaufgaben auf separate Dienste es kleinen, autonomen Entwicklerteams ermöglicht, den gesamten Lebenszyklus dieser Dienste zu kontrollieren, wodurch sie unabhängig diese Dienste erstellen, testen und bereitstellen können. Ein Nachteil dieser Verteilung ist jedoch, dass Informationen darüber, wie jeder Dienst mit anderen interagiert, verloren gehen. In diesem Zusammenhang wird verteiltes Tracing zu einem unverzichtbaren Werkzeug für Debugging komplexe Interaktionen zwischen Diensten.
Wenn Sie wirklich , dann kann kein Mensch das gesamte Bild überblicken. In der Tat ist die Entwicklung eines Werkzeugs auf der Annahme, dass dies überhaupt möglich ist, eine Art Antipattern (eine ineffektive und unproduktive Herangehensweise). Idealerweise benötigt man ein Werkzeug, das hilft, den Suchbereich einzugrenzen., damit die Ingenieure sich auf Teilmengen von Metriken (Diensten/Nutzern/Hosts usw.) konzentrieren können, die für das betreffende Problemszenario relevant sind. Bei der Ursachenklärung müssen die Ingenieure nicht verstehen, was in allen Diensten gleichzeitig, da eine solche Anforderung der Grundidee der Microservice-Architektur widerspräche.
Traceview hingegen ist genau das. Ja, einige Trace-Systeme bieten komprimierte Traceviews an, wenn die Anzahl der Spans in einem Trace so groß ist, dass sie nicht in einer einzigen Visualisierung dargestellt werden können. Aufgrund des großen Informationsvolumens, das selbst in einer solchen reduzierten Visualisierung enthalten ist, müssen die Ingenieure dennoch filtern , indem sie manuell die Auswahl auf eine Gruppe von Dienste-Quellen von Problemen einschränken. Leider sind Maschinen in diesem Bereich deutlich schneller als Menschen, weniger fehleranfällig und ihre Ergebnisse sind reproduzierbarer.
Ein weiterer Grund, warum ich die Traceview-Methode als unpassend empfinde, ist, dass sie sich schlecht für die Hypothesengestützte Fehlersuche eignet. Debugging ist im Kern iterativ Ein Prozess, der mit einer Hypothese beginnt, gefolgt von der Überprüfung verschiedener Beobachtungen und Fakten, die aus dem System über verschiedene Vektoren gesammelt wurden, sowie Schlussfolgerungen/Verallgemeinerungen und einer weiteren Bewertung der Richtigkeit der Hypothese.
Möglichkeit schnell und kostengünstig Hypothesen zu testen und das mentale Modell entsprechend zu verbessern, ist ein grundlegendes Element der Fehlerbehebung. Jedes Debugging-Tool sollte interaktiv sein und den Suchraum eingrenzen oder, im Falle einer falschen Spur, dem Benutzer ermöglichen, zurückzukehren und sich auf einen anderen Bereich des Systems zu konzentrieren. Das ideale Tool wird dies vorausschauend, indem es sofort die Aufmerksamkeit des Benutzers auf potenziell problematische Bereiche lenkt.
Leider Traceview kann man es nicht als ein Tool mit interaktivem Interface bezeichnen. Das Beste, was man bei seiner Nutzung hoffen kann, ist, eine gewisse Quelle erhöhter Latenzen zu entdecken und alle möglichen Tags und Logs, die damit verbunden sind, zu überprüfen. Das hilft dem Ingenieur nicht, um Muster im Verkehr zu identifizieren, wie die Spezifik von Verzögerungsverteilungen, oder Korrelationen zwischen verschiedenen Messungen zu entdecken. kann helfen, einige dieser Probleme zu umgehen. Tatsächlich für erfolgreiche Analysen unter Verwendung von maschinellem Lernen zur Identifizierung anomaler Spans und zur Identifizierung einer Teilmenge von Tags, die mit anomalen Verhaltensmustern verbunden sein könnten. Dennoch habe ich bislang keine überzeugenden Visualisierungen von Erkenntnissen gesehen, die mit maschinellem Lernen oder Datenanalyse auf Spans angewendet wurden, die signifikant von Traceview oder DAG (gerichtetem azyklischen Grafen) abweichen.
Spans sind zu niedrig-levelig
Das grundlegende Problem mit Traceview ist, dass Spans als zu niedrig-levelige Primitiven sowohl für die Analyse von Latenzen als auch für die Ursachenanalyse gelten. Es ist, als würde man einzelne Prozessorbefehle analysieren, um eine Ausnahme zu beheben, obwohl es viel höherstufige Werkzeuge wie Backtrace gibt, die deutlich einfacher zu bedienen sind.
Darüber hinaus wage ich zu behaupten: Idealerweise benötigen wir überhaupt kein vollständiges Bild Das Problem, das während des Lebenszyklus einer Anfrage auftritt, wird durch moderne Trace-Tools dargestellt. Stattdessen ist eine Form der höheren Abstraktion erforderlich, die Informationen darüber enthält, was schiefgelaufen ist (analog zu einem Backtrace), zusammen mit einem gewissen Kontext. Anstatt den gesamten Trace zu betrachten, bevorzuge ich es, nur den Teil, in dem etwas Interessantes oder Ungewöhnliches passiert. Momentan erfolgt die Suche manuell: Der Ingenieur erhält den Trace und analysiert die Spans selbst auf der Suche nach etwas Interessantem. Der Ansatz, bei dem Menschen auf Spans in einzelnen Traces starren, in der Hoffnung, verdächtige Aktivitäten zu entdecken, ist absolut nicht skalierbar (insbesondere, wenn sie alle Metadaten, die in verschiedenen Spans kodiert sind, wie Span-ID, RPC-Methode, Dauer des Spans, Logs, Tags usw., verarbeiten müssen).
Alternativen zu Traceview
Die Ergebnisse der Traceroute sind am hilfreichsten, wenn sie so visualisiert werden, dass sie ein komplexes Verständnis darüber vermitteln, was in den miteinander verbundenen Teilen des Systems geschieht. Solange dies nicht gegeben ist, bleibt der Debugging-Prozess weitgehend träge und hängt von der Fähigkeit des Benutzers ab, die richtigen Korrelationen zu erkennen, die passenden Teile des Systems zu überprüfen oder Puzzlestücke zusammenzufügen – im Gegensatz zu Werkzeug, was dem Benutzer hilft, diese Hypothesen zu formulieren.
Ich bin kein Grafikdesigner und kein UX-Experte, möchte jedoch im folgenden Abschnitt einige Ideen teilen, wie solche Visualisierungen aussehen könnten.
Fokus auf spezifische Dienste
In einem Umfeld, in dem die Branche sich um die Konzepte , scheint es sinnvoll, dass einzelne Teams in erster Linie die Übereinstimmung ihrer Dienste mit diesen Zielen überwachen. Daraus folgt, dass serviceorientierte Visualisierungen am besten für solche Teams geeignet sind.
Traces, insbesondere ohne Sampling, sind eine Fundgrube an Informationen über jede Komponente eines verteilten Systems. Diese Informationen können an einen intelligenten Prozessor weitergegeben werden, der sie den Nutzern bereitstellt. serviceorientiert Funde. Sie können im Voraus erkannt werden – noch bevor der Benutzer die Traces betrachtet:
- Histogramme zur Verteilung von Latenzen nur für stark auffällige Anfragen (Outlier-Anfragen);
- Histogramme zur Verteilung von Latenzen für Fälle, in denen die SLO-Ziele des Services nicht erreicht werden;
- Die "häufigsten", "interessantesten" und "seltsamsten" Tags in Anfragen, die am häufigsten wiederholt werden.;
- Aufschlüsselung von Latenzen für Fälle, in denen Abhängigkeiten des Services die festgelegten SLO-Ziele nicht erreichen;
- Aufschlüsselung der Latenzen nach verschiedenen nachgelagerten Services.
Auf einige dieser Fragen können integrierte Metriken einfach keine Antworten geben, was die Benutzer zwingt, die Spans genauer zu betrachten. Am Ende haben wir ein äußerst benutzerfeindliches System.
Vor diesem Hintergrund stellt sich die Frage: Wie steht es um komplexe Interaktionen zwischen diversen Services, die von unterschiedlichen Teams gesteuert werden? Ist das nicht... Traceview wird nicht als das geeignetste Werkzeug angesehen, um eine solche Situation zu beleuchten?
Mobile Entwickler, Betreiber von stateless Services, Anbieter von verwalteten stateful Services (wie Datenbanken) und Plattforminhaber könnten an einer anderen Darstellung verteilten Systeme interessiert sein; Traceview es ist eine zu universelle Lösung für diese grundlegend unterschiedlichen Bedürfnisse. Selbst in einer sehr komplexen Microservices-Architektur benötigen Servicenutzer keine tiefen Kenntnisse über mehr als zwei oder drei Upstream- und Downstream-Services. Im Wesentlichen genügt es in den meisten Szenarien, die Fragen bezüglich eines begrenzten Satzes von Services zu beantworten..
Es ähnelt dem Betrachten eines kleinen Subsets von Services durch eine Lupe, um eine gründliche Analyse durchzuführen. Dies ermöglicht es dem Benutzer, dringlichere Fragen über die komplexe Interaktion zwischen diesen Services und ihren unmittelbaren Abhängigkeiten zu stellen. Es ist vergleichbar mit einem Backtrace in der Welt der Services, wo der Ingenieur weiß, was nicht nur, was geschieht, sondern auch eine Vorstellung von dem hat, was in den umliegenden Services vor sich geht, um zu verstehen, das.
Mein vorgeschlagener Ansatz steht im völligen Gegensatz zu dem „Top-Down“-Ansatz, der auf Traceview basiert, bei dem die Analyse am gesamten Trace beginnt und dann schrittweise zu einzelnen Spans übergeht. Im Gegensatz dazu beginnt der „Bottom-Up“-Ansatz mit der Analyse eines kleinen Bereichs, der der potenziellen Ursache des Vorfalls nahe ist, und erweitert den Suchraum bei Bedarf (möglicherweise unter Einbeziehung anderer Teams zur Analyse eines breiteren Spektrums von Diensten). Der zweite Ansatz eignet sich besser, um erste Hypothesen schnell zu überprüfen. Nach dem Erhalt konkreter Ergebnisse kann man zu einer gezielteren und detaillierteren Analyse übergehen.
Aufbau der Topologie
Dienstspezifische Ansichten können unglaublich nützlich sein, wenn der Benutzer weiß, welcher Dienst oder welche Gruppe von Diensten für die erhöhten Latenzen verantwortlich ist oder die Quelle der Fehler darstellt. In einem komplexen System kann es jedoch während eines Ausfalls eine nicht triviale Aufgabe sein, den störenden Dienst zu identifizieren, insbesondere wenn keine Fehlermeldungen von den Diensten eingegangen sind.
Der Aufbau einer Diensttopologie kann erheblich dabei helfen, herauszufinden, welcher Dienst einen Anstieg der Fehlerraten oder eine Zunahme der Latenz zeigt, die zu einer spürbaren Verschlechterung der Dienstleistung führen. Wenn ich von der Konstruktion einer Topologie spreche, meine ich nicht eine Dienstkarte, die jeden vorhandenen Dienst im System anzeigt und bekannt ist durch ihre . Eine solche Darstellung ist nicht besser als ein Traceview basierend auf einem gerichteten azyklischen Graphen. Stattdessen würde ich mir wünschen, eine dynamisch generierte Diensttopologie, die auf bestimmten Attributen wie Fehlerhäufigkeit, Antwortzeit oder einem beliebigen vom Benutzer festgelegten Parameter basiert, der hilft, die Situation mit spezifischen verdächtigen Diensten zu klären.
Lassen Sie uns ein Beispiel betrachten. Stellen wir uns eine hypothetische Nachrichten-Website vor. Der Dienst der Startseite (front page) stellt eine Verbindung zu Redis, einem Empfehlungssystem, einem Werbeservice und einem Videoservice her. Der Videoservice bezieht Videos von S3, während die Metadaten aus DynamoDB stammen. Das Empfehlungssystem holt die Metadaten aus DynamoDB, lädt Daten aus Redis und MySQL und sendet Nachrichten an Kafka. Der Werbeservice erhält Daten aus MySQL und sendet Nachrichten an Kafka.
Nachfolgend sehen Sie eine schematische Darstellung dieser Topologie (diese Topologie wird von vielen kommerziellen Programmen zur Verfolgung erstellt). Sie kann hilfreich sein, um die Abhängigkeiten der Dienste zu verstehen. Allerdings während Debugging, wenn ein bestimmter Dienst (nehmen wir den Videoservice) eine erhöhte Antwortzeit aufweist, ist eine solche Topologie nicht besonders nützlich.
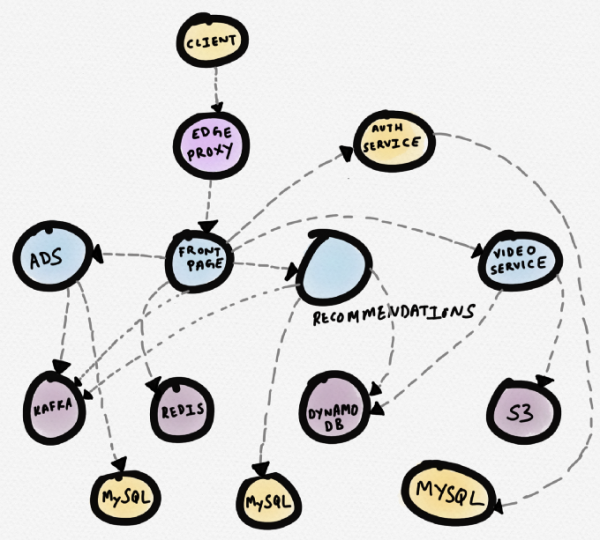
Das Diagramm der Dienste einer hypothetischen Nachrichtenwebsite
Wäre besser geeignet als das unten dargestellte Diagramm. Darauf ist der betroffene Dienst (Video) im Zentrum abgebildet. Der Benutzer bemerkt ihn sofort. Aus dieser Visualisierung wird deutlich, dass der Videoservice anomales Verhalten zeigt, weil die Antwortzeit von S3 erhöht ist, was die Ladegeschwindigkeit eines Teils der Startseite beeinflusst.
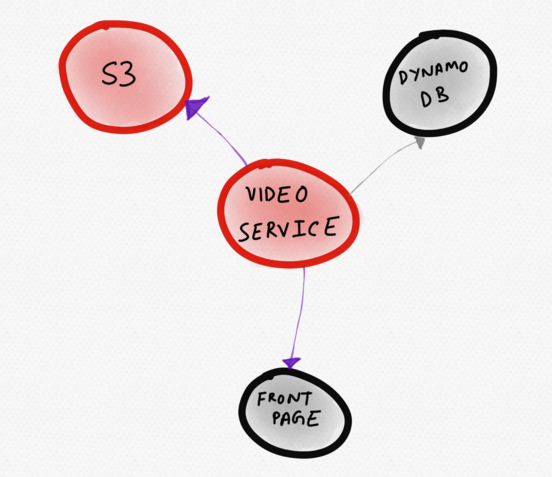
Dynamische Topologie, die nur „interessante“ Dienste anzeigt
Dynamisch generierte Topologieschemata können in elastischen, automatisierbaren Infrastrukturen effizienter sein als statische Dienstkarten. Die Möglichkeit, Service-Topologien zu vergleichen und gegenüberzustellen, ermöglicht es dem Benutzer, relevantere Fragen zu stellen. Präzisere Fragen zum System führen mit höherer Wahrscheinlichkeit zu einem besseren Verständnis der Funktionsweise des Systems.
Vergleichende Darstellung
Eine weitere nützliche Visualisierung ist die vergleichende Darstellung. Derzeit sind Traces nicht besonders gut für den Seitenvergleich geeignet, weshalb sie normalerweise verglichen werden Spans. Die Grundidee dieses Artikels ist, dass Spans zu niedrigstufig sind, um die wertvollsten Informationen aus den Trace-Ergebnissen zu extrahieren.
Der Vergleich von zwei Traces erfordert keine grundlegend neuen Visualisierungen. Tatsächlich reicht etwas Einfaches wie ein Histogramm aus, das dieselben Informationen wie Traceview darstellt. Erstaunlicherweise kann diese einfache Methode oft viel aufschlussreicher sein als die isolierte Betrachtung zweier Traces. Noch wirkungsvoller wäre die Möglichkeit zu visualisieren den Vergleich der Traces insgesamt. Es wäre äußerst hilfreich zu sehen, wie eine kürzlich implementierte Änderung der Datenbankkonfiguration mit aktivierter GC (Garbage Collection) die Reaktionszeit eines Downstream-Dienstes über einen Zeitraum von mehreren Stunden beeinflusst. Wenn das, was ich hier beschreibe, wie eine A/B-Analyse der Auswirkungen infrastruktureller Änderungen in einer Vielzahl von Diensten unter Verwendung der Tracing-Ergebnisse scheint, sind Sie der Wahrheit nicht allzu weit entfernt.
Fazit
Ich zweifle nicht an der Nützlichkeit der Trace-Analyse. Ich bin fest davon überzeugt, dass es keine andere Methode gibt, um so reichhaltige, zufällige und kontextuelle Daten zu sammeln wie die, die in einem Trace enthalten sind. Dennoch glaube ich auch, dass alle Trace-Tools diese Daten äußerst ineffizient nutzen. Solange die Trace-Tools in der Darstellung von Traceviews gefangen sind, werden sie in ihrer Fähigkeit eingeschränkt sein, den wertvollen Informationen, die aus den Trace-Daten extrahiert werden können, vollumfänglich zu nutzen. Zudem besteht die Gefahr, dass sich eine sehr unfreundliche und nicht intuitive Benutzeroberfläche entwickelt, die die Fähigkeit des Nutzers, Fehler in der Anwendung zu beheben, stark einschränkt.
Das Debuggen komplexer Systeme ist selbst mit den neuesten Tools äußerst schwierig. Die Werkzeuge müssen dem Entwickler helfen, Hypothesen zu formulieren und zu überprüfen, indem sie aktiv bereitgestellt werden. relevante Informationen bereitzustellen, indem sie Ausreißer identifizieren und Besonderheiten in der Verteilung von Verzögerungen erfassen. Damit die Nachverfolgung zu einem bevorzugten Werkzeug für Entwickler wird, um Störungen in Produktionsumgebungen zu beheben oder Probleme zu lösen, die mehrere Dienste betreffen, sind originelle Benutzeroberflächen und Visualisierungen erforderlich, die weitgehend der mentalen Modellierung von Entwicklern entsprechen, die diese Dienste erstellen und betreiben.
Es sind erhebliche geistige Anstrengungen erforderlich, um ein System zu entwerfen, das verschiedene Signale, die in den Nachverfolgungsergebnissen verfügbar sind, auf eine Weise darstellt, die für die Analyse und Schlussfolgerungen optimiert ist. Es ist notwendig zu überlegen, wie die Topologie des Systems während der Fehlersuche so abstrahiert werden kann, dass sie den Benutzern hilft, blinde Flecken zu überwinden, ohne in einzelne Traces oder Spans schauen zu müssen.
Wir benötigen gute Möglichkeiten zur Abstraktion und zur Schichtung (insbesondere im UI). Solche, die gut in einen hypothesengestützten Debugging-Prozess integriert werden können, bei dem iterativ Fragen gestellt und Hypothesen überprüft werden können. Sie lösen nicht automatisch alle Probleme mit der Beobachtbarkeit, helfen den Nutzern jedoch, ihre Intuition zu verfeinern und durchdachten Fragen zu formulieren. Ich rufe zu einem reflektierteren und innovativeren Ansatz im Bereich der Visualisierung auf. Hier gibt es echte Chancen, den Horizont zu erweitern.
P.S. vom Übersetzer
Lesen Sie auch in unserem Blog:
- «»;
- «»;
- «».
Quelle: habr.com
