

Der CAP-Satz ist das Fundament der Theorie verteilter Systeme. Die Debatten darüber ebbten jedoch nie ab: Die Definitionen sind nicht kanonisch und es gibt keinen strengen Beweis... Dennoch verstehen wir intuitiv, fest im gesunden Menschenverstand™ zu stehen, dass der Satz gültig ist.

Das Einzige, was nicht offensichtlich ist, ist die Bedeutung des Buchstabens „P“. Wenn ein Cluster partitioniert wird, entscheidet es, ob es nicht antworten soll, bis ein Quorum erreicht ist, oder ob es die verfügbaren Daten bereitstellt. Je nach Ergebnis dieser Entscheidung wird das System entweder als CP oder AP klassifiziert. Cassandra kann beispielsweise je nach Konfiguration des Clusters oder den Parametern jeder einzelnen Anfrage sowohl so als auch so agieren. Aber wenn das System nicht „P“ ist und es hat sich partitioniert, was dann?
Die Antwort auf diese Frage ist etwas überraschend: Ein CA-Cluster kann sich nicht partitionieren.
Was für ein Cluster ist das, das sich nicht partitionieren kann?
Ein essentielles Merkmal eines solchen Clusters ist ein gemeinsames Datenspeichersystem. In den meisten Fällen bedeutet dies die Anbindung über SAN, was den Einsatz von Clusterlösungen auf große Unternehmen beschränkt, die in der Lage sind, eine SAN-Infrastruktur zu unterhalten. Damit mehrere Server mit denselben Daten arbeiten können, ist ein Cluster-Dateisystem erforderlich. Solche Dateisysteme sind im Portfolio von HPE (CFS), Veritas (VxCFS) und IBM (GPFS) enthalten.
Oracle RAC
Die Option Real Application Cluster wurde erstmals 2001 mit der Veröffentlichung von Oracle 9i eingeführt. In so einem Cluster arbeiten mehrere Instanzen Server mit derselben Datenbank.
Oracle kann sowohl mit einem Cluster-Dateisystem als auch mit seiner eigenen Lösung – ASM, Automatic Storage Management – arbeiten.
Jede Instanz führt ihr eigenes Protokoll. Eine Transaktion wird von einer Instanz ausgeführt und protokolliert. Im Falle eines Ausfalls einer Instanz liest einer der verbleibenden Knotens im Cluster (Instanzen) sein Protokoll und stellt die verlorenen Daten wieder her – so wird die Verfügbarkeit sichergestellt.
Alle Instanzen unterstützen einen eigenen Cache, und dieselben Seiten (Blöcke) können gleichzeitig in den Caches mehrerer Instanzen gespeichert sein. Darüber hinaus, wenn eine Instanz eine bestimmte Seite benötigt und diese im Cache einer anderen Instanz vorhanden ist, kann sie diese über den Mechanismus der Cache-Fusion von ihrem 'Nachbarn' abrufen, anstatt von der Festplatte zu lesen.
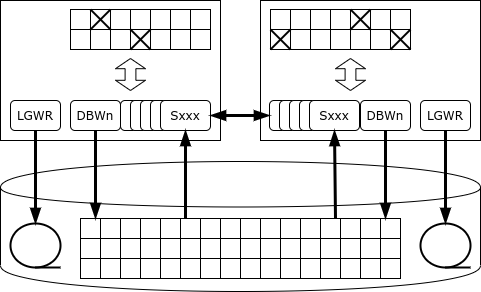
Was passiert jedoch, wenn eine der Instanzen die Daten ändern muss?
Das Besondere an Oracle ist, dass es keinen separaten Locking-Service gibt: Wenn der Server eine Zeile sperren möchte, wird der Sperreintrag direkt auf der Speicherseite platziert, auf der sich die zu sperrende Zeile befindet. Dieser Ansatz macht Oracle zum Leistungs champion unter den monolithischen Datenbanken: Der Locking-Service wird niemals zum engsten Flaschenhals. In einer Clusterkonfiguration kann jedoch eine solche Architektur zu intensivem Netzwerkverkehr und gegenseitigen Sperren führen.
Sobald ein Datensatz gesperrt wird, informiert die Instanz alle anderen Instanzen darüber, dass die Seite, auf der dieser Datensatz gespeichert ist, im exklusiven Modus belegt ist. Wenn eine andere Instanz den Datensatz auf derselben Seite ändern möchte, muss sie warten, bis die Änderungen auf der Seite festgeschrieben sind, sprich, die Informationen über die Änderung im Log auf der Festplatte gespeichert sind (währenddessen kann die Transaktion fortgesetzt werden). Es kann auch vorkommen, dass die Seite nacheinander von mehreren Instanzen geändert wird, und dann muss beim Schreiben der Seite auf die Festplatte ermittelt werden, bei welcher Instanz die aktuelle Version dieser Seite gespeichert ist.
Zufällige Aktualisierungen derselben Seiten über verschiedene Knoten im RAC führen zu einem drastischen Leistungsabfall der Datenbank – bis zu dem Punkt, dass die Leistung des Clusters geringer sein kann als die Leistung einer einzelnen Instanz.
Die korrekte Nutzung von Oracle RAC beinhaltet die physische Aufteilung von Daten (z. B. durch den Mechanismus von partitionierten Tabellen) und den Zugriff auf jede Gruppe von Partitionen über einen dedizierten Knoten. Das Hauptziel von RAC ist nicht die horizontale Skalierung, sondern die Gewährleistung von Ausfallsicherheit.
Wenn ein Knoten auf das Heartbeat-Signal nicht mehr reagiert, initiiert der Knoten, der dies zuerst feststellt, ein Verfahren zur Abstimmung auf der Festplatte. Wenn der ausgefallene Knoten auch hier nicht registriert ist, übernimmt einer der Knoten die Verantwortung für die Datenwiederherstellung:
- „friert“ alle Seiten ein, die sich im Cache des ausgefallenen Knotens befanden;
- liest die Protokolle (Redo) des ausgefallenen Knotens und wendet die darin aufgezeichneten Änderungen erneut an, wobei geprüft wird, ob andere Knoten aktuellere Versionen der geänderten Seiten haben;
- stellt unvollendete Transaktionen zurück.
Um den Wechsel zwischen Knoten zu erleichtern, gibt es in Oracle das Konzept des Services – einer virtuellen Instanz. Eine Instanz kann mehrere Services bedienen, und ein Service kann zwischen Knoten umziehen. Eine Anwendungsinstanz, die einen bestimmten Teil der Datenbank (z. B. eine Kundengruppe) bedient, arbeitet mit einem Service, während der Service, der für diesen Teil der Datenbank zuständig ist, bei einem Ausfall des Knotens auf einen anderen Knoten wechselt.
IBM Pure Data Systems for Transactions
Die Clusterlösung für Datenbanksysteme wurde 2009 im Portfolio des Blauen Giganten eingeführt. Ideologisch ist sie der Nachfolger des Parallel Sysplex-Clusters, der auf 'gewöhnlicher' Hardware basiert. 2009 wurde das Produkt DB2 pureScale veröffentlicht, das ein Softwarepaket darstellt, und 2012 bietet IBM ein software-hardware Paket (Appliance) unter dem Namen Pure Data Systems for Transactions an. Verwechseln Sie dies nicht mit Pure Data Systems for Analytics, das einfach nur ein umbenanntes Netezza ist.
Die Architektur von pureScale ähnelt auf den ersten Blick Oracle RAC: Auch hier sind mehrere Knoten an ein gemeinsames Speichersystem angeschlossen, und auf jedem Knoten läuft eine eigene Instanz des DBMS mit ihren eigenen Speicherbereichen und Transaktionsprotokollen. Im Gegensatz zu Oracle verfügt DB2 jedoch über einen dedizierten Lock-Service, der durch eine Gruppe von Prozessen db2LLM* repräsentiert wird. In einer Cluster-Konfiguration wird dieser Service auf einen separaten Knoten verlagert, der im Parallel Sysplex als Coupling Facility (CF) und in Pure Data als PowerHA bezeichnet wird.
PowerHA bietet folgende Dienste an:
- Lock-Manager;
- Globaler Puffer-Cache;
- Bereich für Interprozesskommunikation.
Für die Datenübertragung von PowerHA zu den DB-Knoten und zurück wird der Remote Access Memory genutzt, weshalb der Cluster-Interconnect das RDMA-Protokoll unterstützen muss. PureScale kann sowohl Infiniband als auch RDMA über Ethernet verwenden.
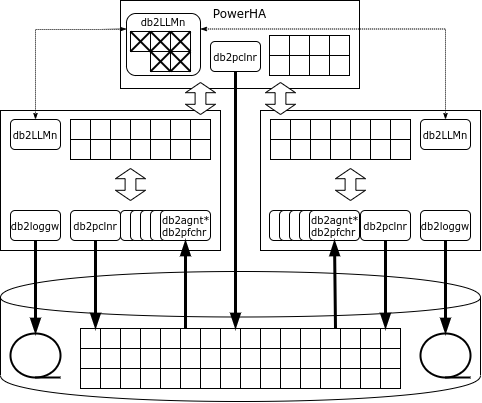
Wenn ein Knoten eine Seite benötigt und diese nicht im Cache vorhanden ist, fordert der Knoten die Seite im globalen Cache an, und nur wenn diese auch dort nicht vorhanden ist, wird sie von der Festplatte gelesen. Im Gegensatz zu Oracle erfolgt die Anfrage nur an PowerHA und nicht an benachbarte Knoten.
Wenn eine Instanz eine Zeile ändern möchte, sperrt sie diese exklusiv und die Seite, auf der sich die Zeile befindet, im Shared-Modus. Alle Sperren werden im globalen Sperrmanager registriert. Wenn die Transaktion abgeschlossen ist, sendet der Knoten eine Nachricht an den Sperrmanager, der die geänderte Seite in den globalen Cache kopiert, die Sperren aufhebt und die geänderte Seite in den Caches anderer Knoten ungültig macht.
Wenn die Seite, auf der sich die änderbare Zeile befindet, bereits gesperrt ist, wird der Sperrmanager die geänderte Seite aus dem Speicher des Knotens lesen, der die Änderungen vorgenommen hat, die Sperre aufheben, die geänderte Seite in den Caches anderer Knoten ungültig machen und die Seitenverriegelung an den anfragenden Knoten zurückgeben.
„Dirty“, also geänderte, Seiten können sowohl von einem normalen Knoten als auch von PowerHA (castout) auf die Festplatte geschrieben werden.
Wenn einer der Knoten von pureScale ausfällt, ist die Wiederherstellung auf die Transaktionen beschränkt, die zum Zeitpunkt des Ausfalls noch nicht abgeschlossen waren: Seiten, die von diesem Knoten in den abgeschlossenen Transaktionen geändert wurden, sind im globalen Cache auf PowerHA vorhanden. Der Knoten wird in einer reduzierten Konfiguration auf einem der Cluster-Server neu gestartet, rollt die nicht abgeschlossenen Transaktionen zurück und löst die Sperren auf.
PowerHA läuft auf zwei Servern, wobei der primäre Knoten seinen Zustand synchron repliziert. Bei einem Ausfall des primären Knotens setzt das PowerHA-Cluster den Betrieb mit dem Backup-Knoten fort.
Natürlich wird die Gesamtleistung des Clusters höher sein, wenn auf einen Satz von Daten über einen Knoten zugegriffen wird. PureScale kann sogar erkennen, dass ein bestimmter Datenbereich von einem Knoten bearbeitet wird, und in diesem Fall werden alle Sperren, die sich auf diesen Bereich beziehen, lokal von dem Knoten ohne Kommunikation mit PowerHA bearbeitet. Sobald die Anwendung jedoch versucht, auf diese Daten über einen anderen Knoten zuzugreifen, wird die zentralisierte Bearbeitung der Sperren wieder aufgenommen.
Interne IBM-Tests mit einer Last, die aus 90 % Lese- und 10 % Schreibvorgängen besteht, was sehr gut einer realen industriellen Last entspricht, zeigen eine nahezu lineare Skalierung bis zu 128 Knoten. Leider werden die Testbedingungen nicht offengelegt.
HPE NonStop SQL
Eine eigene hochverfügbare Plattform bietet auch Hewlett-Packard Enterprise an. Dies ist die NonStop-Plattform, die 1976 von Tandem Computers auf den Markt gebracht wurde. Im Jahr 1997 wurde das Unternehmen von Compaq übernommen, welches 2002 wiederum in Hewlett-Packard eingegliedert wurde.
NonStop wird eingesetzt, um kritische Anwendungen zu entwickeln – beispielsweise HLR oder die Verarbeitung von Bankkarten. Die Plattform wird als Hard- und Softwarekomplex (Appliance) geliefert, der Rechenknoten, ein Speichersystem und Kommunikationsgeräte umfasst. Das ServerNet (in modernen Systemen Infiniband) dient sowohl dem Austausch zwischen den Knoten als auch dem Zugriff auf das Speichersystem.
In den frühen Versionen des Systems wurden proprietäre Prozessoren verwendet, die synchron zueinander arbeiteten: Alle Operationen wurden synchron von mehreren Prozessoren ausgeführt, und sobald ein Prozessor einen Fehler hatte, schaltete er sich ab, während der andere weiterarbeitete. Später wechselte das System zu handelsüblichen Prozessoren (zunächst MIPS, dann Itanium und schließlich x86), und es kamen andere Mechanismen zur Synchronisierung zum Einsatz:
- Nachrichtenaustausch: Jeder Systemprozess verfügt über einen Schattenprozess, der regelmäßig Nachrichten über seinen Status vom aktiven Prozess erhält; bei einem Ausfall des Hauptprozesses beginnt der Schattenprozess ab dem Punkt, der durch die letzte Nachricht bestimmt wurde;
- Abstimmung: Das Speichersystem verfügt über eine spezielle Hardwarekomponente, die mehrere identische Anfragen entgegennimmt und diese nur dann bearbeitet, wenn die Anfragen übereinstimmen; anstelle von physischer Synchronisation arbeiten die Prozessoren asynchron, und die Ergebnisse ihrer Arbeit werden nur zu Eingabe-/Ausgabezeiten verglichen.
Seit 1987 läuft auf der NonStop-Plattform ein relationales DBMS – zunächst SQL/MP und später SQL/MX.
Die gesamte Datenbank wird in Teile untergliedert, wobei jeder Teil von einem eigenen Data Access Manager (DAM) verwaltet wird. Dieser sorgt für die Datenspeicherung, das Caching und das Locking-Verfahren. Die Datenverarbeitung erfolgt durch Executor Server Processes, die auf denselben Knoten wie die entsprechenden Datenmanager arbeiten. Der SQL/MX Scheduler verteilt die Aufgaben zwischen den Ausführenden und fasst die Ergebnisse zusammen. Für konsistente Änderungen wird das Zwei-Phasen-Commit-Protokoll verwendet, das von der TMF-Bibliothek (Transaction Management Facility) bereitgestellt wird.
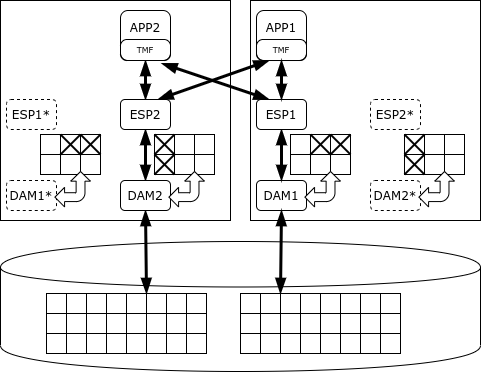
NonStop SQL kann Prozesse priorisieren, sodass lange analytische Abfragen die Ausführung von Transaktionen nicht beeinträchtigen. Ihre Hauptfunktion besteht jedoch in der Verarbeitung kurzer Transaktionen und nicht in der Analyse. Der Entwickler garantiert eine Verfügbarkeit des NonStop-Clusters auf dem Level von fünf Neunen, was nur fünf Minuten Ausfallzeit pro Jahr bedeutet.
SAP HANA
Die erste stabile Version des DBMS HANA (1.0) wurde im November 2010 veröffentlicht, und das SAP ERP-Paket ist seit Mai 2013 auf HANA umgestiegen. Die Plattform basiert auf lizenzierten Technologien: TREX Suchmaschine (für die Suche in Spaltenspeichern), P*TIME DBMS und MAX DB.
Der Begriff „HANA“ ist ein Akronym für High performance ANalytical Appliance. Diese Datenbank wird in Form von Code geliefert, der auf beliebigen x86-Servern betrieben werden kann, jedoch sind industrielle Installationen nur auf zertifizierten Geräten zulässig. Es gibt Lösungen von HP, Lenovo, Cisco, Dell, Fujitsu, Hitachi und NEC. Einige Konfigurationen von Lenovo erlauben sogar den Betrieb ohne SAN – der GPFS-Cluster auf lokalen Festplatten fungiert als gemeinsamer Speicher.
Im Gegensatz zu den oben genannten Plattformen ist HANA eine In-Memory-Datenbank, das heißt, das Primärdatenbild wird im Arbeitsspeicher gespeichert, und auf der Festplatte werden nur Journale und gelegentliche Snapshots zur Wiederherstellung im Falle eines Ausfalls gespeichert.
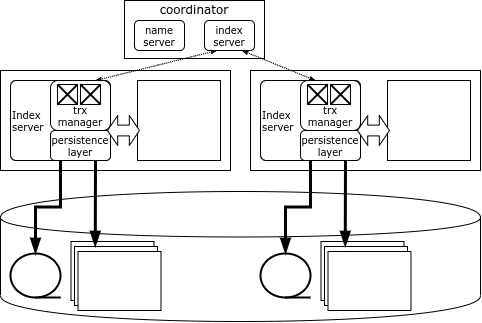
Jeder Knoten im HANA-Cluster ist für seinen eigenen Datenbereich verantwortlich, und die Datenkarte wird in einer speziellen Komponente – dem Name Server, die sich auf dem Koordinationsknoten befindet, gespeichert. Die Daten werden zwischen den Knoten nicht dupliziert. Informationen über Sperren werden ebenfalls auf jedem Knoten gespeichert, jedoch gibt es im System einen globalen Mutually Blocking Detector.
Der HANA-Client lädt beim Verbinden mit dem Cluster dessen Topologie und kann anschließend direkt auf jeden Knoten zugreifen, abhängig von den benötigten Daten. Wenn eine Transaktion nur auf Daten eines einzelnen Knotens zugreift, kann sie lokal von diesem Knoten ausgeführt werden. Bei Änderungen an Daten mehrerer Knoten wendet sich der initiierende Knoten an den Koordinator-Knoten, der die verteilte Transaktion eröffnet und koordiniert und diese mithilfe eines optimierten Zwei-Phasen-Commit-Protokolls festschreibt.
Der Koordinator-Knoten ist redundant, sodass bei einem Ausfall des Koordinators sofort ein Backup-Knoten die Funktion übernimmt. Tritt jedoch ein Ausfall bei einem Knoten mit Daten auf, ist der einzige Weg, um auf diese Daten zuzugreifen, den Knoten neu zu starten. In der Regel wird in HANA-Clustern ein Reserve-Server bereitgehalten, um den ausgefallenen Knoten so schnell wie möglich neu zu starten.
Quelle: habr.com
