


Am 8. April auf der Konferenz , im Rahmen der Sektion „DevOps und Betrieb“ präsentierten drei Mitarbeiter des Unternehmens „Flant“ den Vortrag „Erweiterung und Ergänzung von Kubernetes“. Darin erläutern wir zahlreiche Situationen, in denen wir die Möglichkeiten von Kubernetes erweitern und ergänzen wollten, für die wir jedoch keine fertige und einfache Lösung finden konnten. Die notwendigen Lösungen sind in Form von Open Source-Projekten entstanden, denen auch dieser Vortrag gewidmet ist.
Traditionell freuen wir uns, (50 Minuten, deutlich informativer als der Artikel) sowie eine schriftliche Zusammenfassung zu präsentieren. Los geht's!
Kern und Erweiterungen in K8s
Kubernetes verändert die Branche und etablierte Ansätze im Management:
- Dank seiner Abstraktionen, agieren wir nicht mehr mit Begriffen wie Konfigurationseinstellungen oder dem Ausführen von Befehlen (Chef, Ansible…), sondern nutzen Container-Gruppierungen, Dienste usw.
- Wir können Anwendungen vorbereiten, ohne uns über die Feinheiten der konkreten Plattform, auf der sie betrieben werden, Gedanken zu machen: Bare Metal, Cloud eines Anbieters usw.
- Mit K8s sind diese Möglichkeiten zugänglicher denn je geworden. beste Praktiken für die Infrastrukturorganisation: Skalierungstechniken, Selbstheilung, Ausfallsicherheit usw.
Allerdings ist nicht alles so reibungslos: Mit Kubernetes kommen auch neue Herausforderungen.
Kubernetes nicht ist ein Kombi, der alle Probleme aller Benutzer löst. Kern Kubernetes kümmert sich nur um die grundlegenden Funktionen, die in jedem Cluster vorhanden sind:
Im Kern von Kubernetes wird eine grundlegende Set an Primitiven definiert – zur Gruppierung von Containern, Verkehrsmanagement usw. Darüber haben wir in .
Andererseits bietet K8s großartige Möglichkeiten zur Erweiterung der verfügbaren Funktionen, die helfen, auch andere – spezifische – Anforderungen der Benutzer zu erfüllen. Die Ergänzungen in Kubernetes werden von den Cluster-Administratoren verwaltet, die alles Notwendige installieren und konfigurieren müssen, damit ihr Cluster die passende Form annimmt [um ihre spezifischen Aufgaben zu lösen]. Was sind das für Ergänzungen? Lassen Sie uns einige Beispiele betrachten.
Beispiele für Ergänzungen
Nachdem wir Kubernetes eingerichtet haben, könnten wir überrascht sein, dass das Netzwerk, das für die Kommunikation von Pods sowohl innerhalb als auch zwischen Knoten erforderlich ist, nicht von selbst funktioniert. Der Kubernetes-Kern garantiert nicht die erforderlichen Verbindungen — stattdessen definiert er die Netzwerk schnittstelle () für Drittanbieter-Plugins. Wir müssen eines dieser Plugins installieren, das für die Netzwerkkonfiguration verantwortlich sein wird.
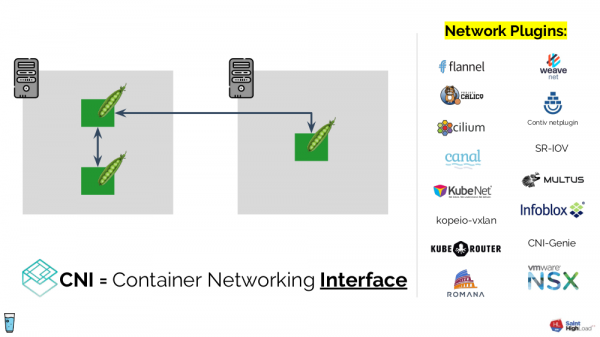
Ein naher Vergleich sind Lösungen für die Datenspeicherung (lokale Festplatte, Netzwerk-Blockgerät, Ceph…). Ursprünglich waren sie im Kern integriert, aber mit dem Erscheinen von ändert sich die Situation zu der bereits beschriebenen: In Kubernetes ist die Schnittstelle vorhanden, und ihre Implementierung erfolgt über Drittanbieter-Module.
Weitere Beispiele sind:
- Ingress-Controller (eine Übersicht finden Sie in der ).
- :

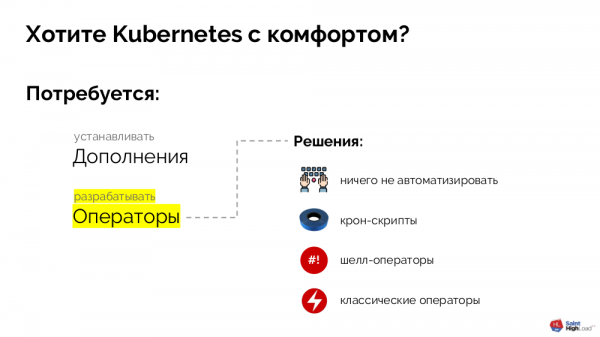
- — ist eine ganze Klasse von Erweiterungen (zu denen auch der erwähnte cert-manager gehört), die Primitive und Controller definieren. Ihre Funktionsweise ist nur durch unsere Vorstellungskraft begrenzt und ermöglicht es, fertige Infrastrukturkomponenten (z. B. Datenbanksysteme) in Primitive umzuwandeln, mit denen es sich viel einfacher arbeiten lässt (als mit einer Sammlung von Containern und deren Konfigurationen). Es gibt eine riesige Anzahl von Operatoren — viele davon sind zwar noch nicht produktionsbereit, aber das ist nur eine Frage der Zeit:
- Metriken — eine weitere Illustration, wie in Kubernetes die Schnittstelle (Metrics API) von der Implementierung (drittanbieter Erweiterungen wie der Prometheus-Adapter, Datadog Cluster-Agent…) getrennt wurde.
- Für Überwachung und Statistik, wo in der Praxis nicht nur benötigt werden , sondern auch kube-state-metrics, node-exporter usw.

Und das ist längst nicht die vollständige Liste der Erweiterungen… Zum Beispiel installieren wir in der Firma „Flant“ mittlerweile 29 Erweiterungen (insgesamt erzeugen sie 249 Kubernetes-Objekte). Anders gesagt, wir sehen das Leben des Clusters ohne Erweiterungen nicht.
Automatisierung
Operatoren sind entwickelt worden, um alltägliche Routineaufgaben zu automatisieren, mit denen wir täglich konfrontiert sind. Hier sind einige praktische Beispiele, für die es eine ausgezeichnete Lösung ist, einen Operator zu schreiben:
- Es gibt ein privates (d.h. ein Login erforderndes) Registry mit Images für Anwendungen. Es wird vorausgesetzt, dass jedem Pod ein spezielles Secret zugeordnet wird, das die Authentifizierung im Registry ermöglicht. Unsere Aufgabe besteht darin, sicherzustellen, dass sich dieses Secret im Namespace befindet, damit die Pods die Images herunterladen können. Es kann sehr viele Anwendungen geben (jede davon benötigt ein Secret), und es ist auch sinnvoll, die Secrets regelmäßig zu aktualisieren, sodass eine manuelle Verteilung der Secrets nicht in Frage kommt. Hier kommt der Operator ins Spiel: Wir erstellen einen Controller, der darauf wartet, dass der Namespace erscheint, und bei diesem Ereignis das Secret in den Namespace hinzufügt.
- Standardmäßig ist der Internetzugang von Pods blockiert. Manchmal ist dieser jedoch erforderlich: Es ist sinnvoll, dass der Zugriff auf einfache Weise gewährt wird, ohne spezifische Kenntnisse zu benötigen, zum Beispiel durch das Vorhandensein eines bestimmten Labels im Namespace. Wie kann uns hier ein Operator helfen? Es wird ein Controller erstellt, der auf das Erscheinen des Labels im Namespace wartet und die entsprechenden Regeln für den Internetzugang hinzufügt.
- Ähnliche Situation: Angenommen, wir müssen einem Knoten ein bestimmtes hinzufügen, wenn er ein entsprechendes Label (mit einem bestimmten Präfix) hat. Die Handlungen des Operators sind offensichtlich...
In jedem Cluster müssen routinemäßige Aufgaben erledigt werden, und der richtige Weg, dies zu tun, ist durch die Verwendung von Operatoren.
Zusammenfassend haben wir zu dem Schluss gekommen, dass ein angenehmes Arbeiten in Kubernetes erfordert: a) Erweiterungen zu installieren, b) Operatoren zu entwickeln (um alltägliche Administrationsaufgaben zu lösen).
Wie schreibt man einen Operator für Kubernetes?
Im Grunde ist das Schema einfach:
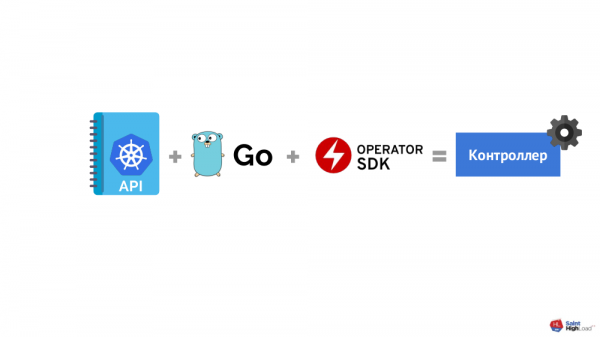
… aber hier stellt sich heraus, dass:
- Die Kubernetes API ist eine ziemlich komplexe Angelegenheit, die viel Zeit zur Einarbeitung benötigt;
- Programmierung ist nicht für jeden geeignet (die Programmiersprache Go wurde als bevorzugt gewählt, da es ein spezielles Framework dafür gibt — );
- Die Situation ist mit dem Framework selbst ähnlich.
Fazit: Um einen Controller (Operator) zu schreiben, muss man beträchtliche Ressourcen aufwenden um das Fachwissen zu erlernen. Dies wäre gerechtfertigt für „große“ Operatoren — zum Beispiel für die Datenbank MySQL. Aber wenn wir uns an die oben beschriebenen Beispiele erinnern (das Bereitstellen von Secrets, der Internetzugang für Pods…), die ebenfalls korrekt umgesetzt werden sollen, erkennen wir, dass der Aufwand die derzeit benötigten Ergebnisse übersteigt:

Es entsteht also ein Dilemma: viel Ressourcen investieren und das richtige Werkzeug für das Schreiben von Operatoren erwerben oder „traditionell“ (aber schnell) handeln. Um einen Kompromiss zwischen diesen Extremen zu finden, haben wir unser Projekt geschaffen: (siehe auch seine auf Habré).
Shell-Operator
Wie funktioniert er? Im Cluster gibt es einen Pod, in dem sich das Go-Binärprogramm mit dem Shell-Operator befindet. Daneben wird eine Sammlung von Hooks (mehr dazu — siehe unten). Der Shell-Operator abonniert bestimmte Ereignisse Im Kubernetes API gibt es Ereignisse, die das entsprechende Hooks auslösen.
Wie versteht der Shell-Operator, welche Hooks bei welchen Ereignissen ausgelöst werden sollen? Diese Information wird vom Hook selbst an den Shell-Operator übermittelt und dies geschieht sehr einfach.
Ein Hook ist ein Bash-Skript oder eine andere ausführbare Datei, die ein einziges Argument unterstützt. --config und gibt als Antwort JSON zurück. Letzteres bestimmt, welche Objekte von Interesse sind und auf welche Ereignisse (für diese Objekte) reagiert werden soll:

Ich werde die Implementierung des Shell-Operators anhand eines unserer Beispiele verdeutlichen – die Bereitstellung von Geheimnissen für den Zugriff auf ein privates Registry mit Anwendungs-Images. Dieser Prozess besteht aus zwei Schritten.
Praxis: 1. Wir schreiben einen Hook
Zuerst verarbeiten wir im Hook --config, und geben an, dass uns Namespaces interessieren, insbesondere – deren Erstellungszeitpunkt:
[[ $1 == "--config" ]] ; then
cat << EOF
{
"onKubernetesEvent": [
{
"kind": "namespace",
"event": ["add"]
}
]
}
EOF
…Wie wird die Logik aussehen? Auch das ist recht einfach:
…
else
createdNamespace=$(jq -r '.[0].resourceName' $BINDING_CONTEXT_PATH)
kubectl create -n ${createdNamespace} -f - << EOF
Kind: Secret
...
EOF
fi Im ersten Schritt erfahren wir, welcher Namespace erstellt wurde, und im zweiten Schritt erstellen wir über kubectl ein Geheimnis für diesen Namensraum.
Praxis: 2. Ein Image erstellen
Es bleibt, den erstellten Hook an den shell-operator zu übergeben — wie macht man das? Der shell-operator wird als Docker-Image bereitgestellt, daher besteht unsere Aufgabe darin, den Hook in ein spezielles Verzeichnis in diesem Image hinzuzufügen:
FROM flant/shell-operator:v1.0.0-beta.1
ADD my-handler.sh /hooksJetzt bleibt nur noch, ihn zu erstellen und hochzuladen:
$ docker build -t registry.example.com/my-operator:v1 .
$ docker push registry.example.com/my-operator:v1Der letzte Schritt ist, das Image im Cluster zu deployen. Dazu schreiben wir Deployment:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: my-operator
spec:
template:
spec:
containers:
- name: my-operator
image: registry.example.com/my-operator:v1 # 1
serviceAccountName: my-operator # 2Dabei sind zwei Punkte zu beachten:
- die Angabe des gerade erstellten Images;
- es handelt sich um eine systemtechnische Komponente, die (mindestens) die Berechtigungen benötigt, um sich für Ereignisse in Kubernetes anzumelden und um Secrets nach Namespaces zu verteilen, daher erstellen wir für den Hook ein ServiceAccount (und eine Reihe von Regeln).
Das Ergebnis ist — wir haben unser Problem auf native Kubernetes-Art gelöst, indem wir einen Operator zum Verteilen von Secrets erstellt haben.
Weitere Möglichkeiten des shell-operators
Um die Objekte des von Ihnen ausgewählten Typs, mit denen der Hook arbeiten wird, einzuschränken, können diese gefiltert werden., indem nach bestimmten Labels (oder durch matchExpressions):
"onKubernetesEvent": [
{
"selector": {
"matchLabels": {
"foo": "bar",
},
"matchExpressions": [
{
"key": "allow",
"operation": "In",
"values": ["wan", "warehouse"],
},
],
}
…
}
]Vorgesehen ein Deduplication-Mechanismus, der — mithilfe eines jq-Filters — große JSON-Objekte in kleine umwandelt, wobei nur die Parameter bleiben, deren Änderungen wir verfolgen möchten.
Bei der Anrufung des Hooks übergibt der Shell-Operator Daten über das Objekt, die für beliebige Zwecke verwendet werden können.
Ereignisse, die die Hooks auslösen, sind nicht auf Kubernetes-Ereignisse beschränkt: der Shell-Operator unterstützt auch zeitgesteuerte Hooks analog zu crontab in einem traditionellen Scheduler, sowie ein spezielles Ereignis onStartup. All diese Ereignisse können kombiniert und demselben Hook zugewiesen werden.
Und noch zwei Besonderheiten des Shell-Operators:
- Er arbeitet asynchronSeit dem Eintreffen eines Ereignisses in Kubernetes (z. B. der Erstellung eines Objekts) können auch andere Ereignisse im Cluster aufgetreten sein (z. B. das Löschen desselben Objekts), die in Hooks berücksichtigt werden müssen. Wenn ein Hook mit einem Fehler ausgeführt wird, wird er standardmäßig wiederholt aufgerufen bis er erfolgreich abgeschlossen ist (dieses Verhalten kann geändert werden).
- Er exportiert Metriken für Prometheus, mit denen festgestellt werden kann, ob der Shell-Operator funktioniert, die Anzahl der Fehler pro Hook ermittelt und die aktuelle Größe der Warteschlange erfahren werden kann.
Zusammenfassend zu diesem Teil des Berichts:
Installation von Erweiterungen
Für eine komfortable Arbeit mit Kubernetes wurde auch die Notwendigkeit der Installation von Erweiterungen angesprochen. Darüber werde ich am Beispiel des Weges unseres Unternehmens erzählen, wie wir das derzeit umsetzen.
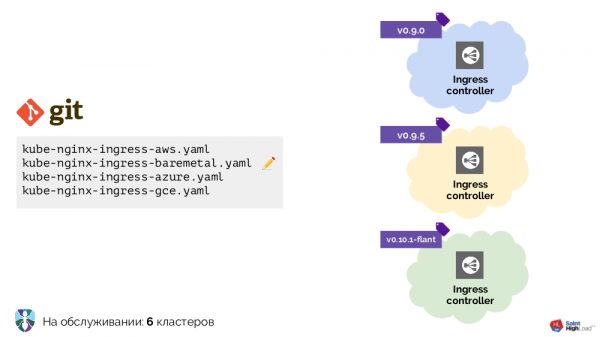
Wir haben mit Kubernetes angefangen, indem wir mehrere Cluster hatten, in denen Ingress die einzige Erweiterung war. In jeden Cluster musste er unterschiedlich installiert werden, daher haben wir mehrere YAML-Konfigurationen für verschiedene Umgebungen erstellt: Bare Metal, AWS…
Die Anzahl der Cluster nahm zu – und damit auch die Anzahl der Konfigurationen. Darüber hinaus haben wir diese Konfigurationen verbessert, wodurch sie ziemlich heterogen wurden:
Um alles in Ordnung zu bringen, haben wir mit einem Skript begonnen (install-ingress.sh), das den Typ des Clusters als Argument nahm, in das wir deployen wollten, die benötigte YAML-Konfiguration generierte und diese in Kubernetes ausrollte.
Kurz gesagt, unser weiterer Weg und die damit verbundenen Gedanken waren wie folgt:
- Zum Arbeiten mit YAML-Konfigurationen benötigt man einen Template-Generator (in den frühen Phasen war das ein einfaches sed);
- Mit der wachsenden Anzahl von Clustern entstand die Notwendigkeit für automatisierte Updates (die früheste Lösung war, das Skript in Git zu legen, es über cron zu aktualisieren und auszuführen);
- Ein ähnliches Skript wurde für Prometheus benötigt (
install-prometheus.sh), es ist jedoch bemerkenswert, dass es viel mehr Eingabedaten erfordert, sowie deren Speicherung (idealerweise zentralisiert und im Cluster), wobei einige Daten (Passwörter) automatisch generiert werden konnten: - Das Risiko, etwas Falsches auf einer wachsenden Anzahl von Clustern auszurollen, stieg ständig, weshalb wir erkannten, dass die Installer (d.h. zwei Skripte: eines für Ingress und eines für Prometheus) Staging benötigten (mehrere Branches in Git, mehrere cron-Jobs zur Aktualisierung in den jeweiligen: stabilen oder Test-Clustern);
- mit
kubectl applyEs wurde schwierig zu arbeiten, da es nicht deklarativ ist und nur Objekte erstellen kann, aber keine Entscheidungen über deren Status treffen oder sie löschen kann; - es fehlten einige Funktionen, die wir zu diesem Zeitpunkt noch nicht implementiert hatten:
- vollständige Kontrolle über das Ergebnis der Clusteraktualisierungen,
- automatische Bestimmung bestimmter Parameter (Eingaben für Installationsskripte) basierend auf Daten, die aus dem Cluster gewonnen werden können (Discovery),
- eine logische Weiterentwicklung in Form von Continuous Discovery.

Alle diese Erfahrungen haben wir in einem anderen unserer Projekte umgesetzt — .
Addon-Operator
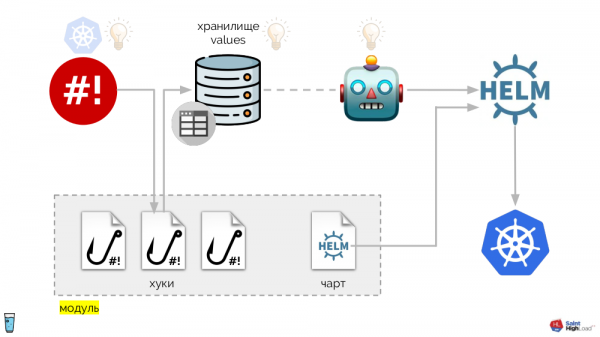
Dessen Grundlage ist der bereits erwähnte Shell-Operator. Das gesamte System sieht folgendermaßen aus:
Zu den Hooks des Shell-Operators werden hinzugefügt:
- Werte-Speicher,
- Helm-Chart,
- eine Komponente, die den Werte-Speicher überwacht und — im Falle von Veränderungen — Helm auffordert, das Chart neu auszuspielen.

So können wir auf ein Ereignis in Kubernetes reagieren, einen Hook auslösen und aus diesem Hook Änderungen im Speicher vornehmen, nach denen das Chart neu ausgerollt wird. In dem resultierenden Schema heben wir eine Reihe von Hooks und das Chart in eine Komponente hervor, die wir "Modul" nennen. Modul:
Es können zahlreiche Module vorhanden sein, zu denen wir globale Hooks, ein globales Werte-Repository und eine Komponente hinzufügen, die dieses globale Repository überwacht.
Jetzt, wenn in Kubernetes etwas passiert, können wir mit einem globalen Hook darauf reagieren und etwas im globalen Repository ändern. Diese Änderung wird bemerkt und löst die Einführung aller Module im Cluster aus:
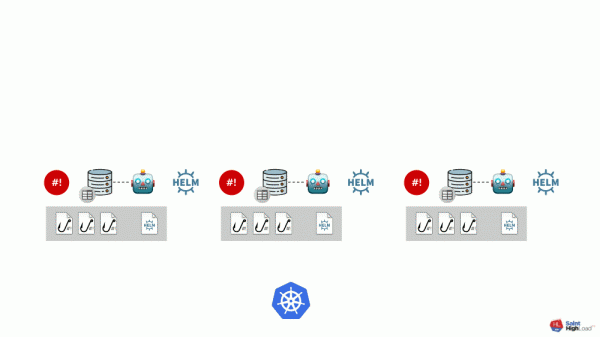
Dieses Schema erfüllt alle vorher genannten Anforderungen für die Installation von Add-ons:
- Die Template-Verwaltung und Deklarativität wird von Helm übernommen.
- Die Frage des automatischen Updates wird durch einen globalen Hook gelöst, der regelmäßig ins Registry schaut und, falls ein neues System-Image vorhanden ist, dieses neu ausrollt (also "sich selbst").
- Die Speicherung der Einstellungen im Cluster erfolgt über ConfigMap, in dem die primären Daten für die Speicher (beim Start werden sie in die Speicher geladen) aufgezeichnet werden.
- Die Probleme der Passwortgenerierung, Discovery und Continuous Discovery werden durch Hooks gelöst.
- Das Staging wird durch Tags erreicht, die Docker standardmäßig unterstützt.
- Die Kontrolle des Ergebnisses erfolgt durch Metriken, anhand derer wir den Status verstehen können.
Das gesamte System ist als ein einziges Go-Binärprogramm implementiert, das den Namen addon-operator trägt. Dadurch wirkt das Schema übersichtlicher:
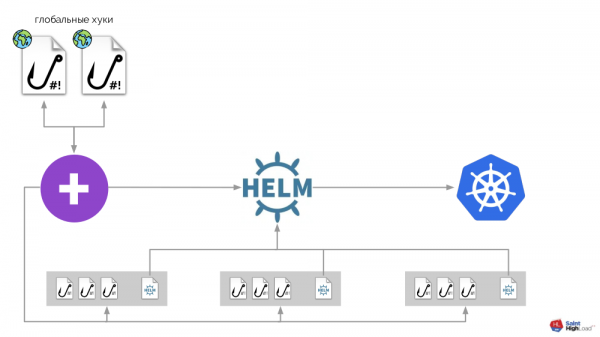
Die Hauptkomponente in diesem Schema ist eine Sammlung von Modulen (in grau am unteren Rand hervorgehoben). Nun können wir mit geringem Aufwand ein Modul für die gewünschte Erweiterung schreiben und sind zuversichtlich, dass es in jeden Cluster installiert wird, aktualisiert wird und auf die erforderlichen Ereignisse im Cluster reagiert.
Flant verwendet in über 70 Kubernetes-Clustern. Der aktuelle Status ist Alpha-Version. Derzeit bereiten wir die Dokumentation vor, um die Beta-Version herauszubringen; bis dahin sind im Repository , auf deren Grundlage Sie Ihr eigenes addon erstellen können.
Woher bekommt man die Module für den addon-operator? Die Veröffentlichung unserer Bibliothek ist der nächste Schritt für uns, den wir für den Sommer planen.
Videos und Folien
Video vom Vortrag (~50 Minuten):

Präsentation des Vortrags:
P.S.
Weitere Vorträge in unserem Blog:
- «»; (Dmitry Stolyarov; 8. November 2018 auf HighLoad++);
- «»; (Dmitry Stolyarov; 28. Mai 2018 auf der RootConf);
- «»; (Dmitry Stolyarov; 7. November 2017 auf HighLoad++);
- «»; (Dmitry Stolyarov; 6. Juni 2017 auf RootConf).
Vielleicht interessieren Sie auch die folgenden Publikationen:
- «».
Quelle: habr.com
