

Diese beiden modischen Begriffe aus der Data Science verwirren viele Menschen. Data Mining wird oft falsch verstanden als das bloße Extrahieren und Abrufen von Daten, dabei ist es weitaus komplexer. In diesem Beitrag klären wir die Missverständnisse rund um Mining und untersuchen den Unterschied zwischen Data Mining und Data Extraction.
Was ist Data Mining?
Data Mining, auch genannt Wissensentdeckung in Datenbanken (KDD), ist eine Methode, die häufig verwendet wird, um große Datenmengen mithilfe statistischer und mathematischer Methoden zu analysieren, um verborgene Muster oder Trends zu identifizieren und daraus Wert zu schöpfen.
Was kann mit Data Mining erreicht werden?
Durch die Automatisierung des Prozesses Datenbanken durchsuchen und verborgene Muster effizient aufdecken. Für Unternehmen wird Data Mining häufig verwendet, um Muster und Zusammenhänge in Daten zu erkennen, die helfen, fundierte Geschäftsentscheidungen zu treffen.
Anwendungsbeispiele
Nachdem Data Mining in den 1990er Jahren weit verbreitet wurde, begannen Unternehmen aus einer Vielzahl von Branchen, einschließlich Einzelhandel, Finanzen, Gesundheitswesen, Transport, Telekommunikation, E-Commerce usw., Methoden des Data Mining zu nutzen, um aus Daten Informationen zu gewinnen. Data Mining kann dabei helfen, Kunden zu segmentieren, Betrug aufzudecken, Verkaufsprognosen zu erstellen und vieles mehr.
- Kundensegmentierung
Durch die Analyse von Kundendaten und das Erkennen von Merkmalen zielgerichteter Kunden können Unternehmen diese in eine separate Gruppe einordnen und spezielle Angebote erstellen, die ihren Bedürfnissen entsprechen. - Warenkorbanalyse
Diese Methode basiert auf der Theorie, dass, wenn Sie eine bestimmte Gruppe von Produkten kaufen, Sie mit hoher Wahrscheinlichkeit eine andere Gruppe von Produkten ebenfalls kaufen werden. Ein bekanntes Beispiel: Wenn Väter Windeln für ihre Babys kaufen, kaufen sie in der Regel auch Bier zusammen mit den Windeln. - Verkaufsprognose
Das mag wie eine Analyse eines Marktportfolios erscheinen, aber dieses Mal wird die Datenanalyse verwendet, um vorherzusagen, wann ein Käufer das Produkt in Zukunft erneut kaufen wird. Zum Beispiel kauft ein Trainer eine Dose Protein, die für 9 Monate reichen sollte. Der Laden, der dieses Protein verkauft, plant, in 9 Monaten ein neues herauszubringen, damit der Trainer es erneut kauft. - Betrugserkennung
Data Mining hilft beim Bau von Modellen zur Betrugserkennung. Durch das Sammeln von Mustern betrügerischer und wahrer Berichte erhalten Unternehmen die Möglichkeit zu bestimmen, welche Transaktionen verdächtig sind. - Mustererkennung in der Produktion
In der verarbeitenden Industrie wird Data Mining verwendet, um bei der Gestaltung von Systemen zu helfen, indem Zusammenhänge zwischen der Produktarchitektur, den Profilen und den Bedürfnissen der Kunden aufgedeckt werden. Data Mining kann auch die Entwicklungszeiten und Kosten für Produkte vorhersagen.
Und das sind nur einige Einsatzszenarien für Data Mining.
Schritte im Data Mining
Data Mining ist ein umfassender Prozess, der das Sammeln, Auswählen, Bereinigen, Umwandeln und Extrahieren von Daten umfasst, um Muster zu bewerten und letztendlich Wert zu schöpfen.
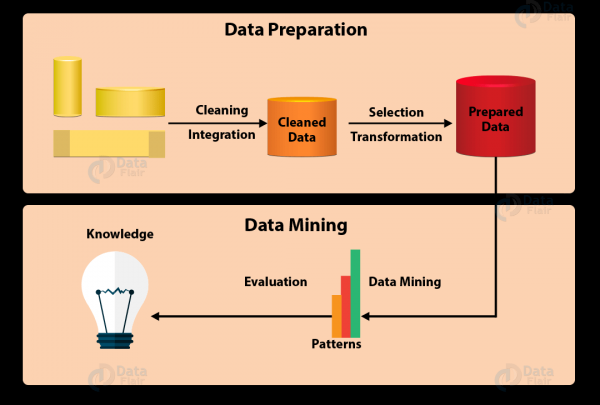
In der Regel lässt sich der gesamte Data-Mining-Prozess auf 7 Phasen zusammenfassen:
- Datenbereinigung
In der realen Welt werden Daten nicht immer bereinigt und strukturiert. Oft sind sie unordentlich, unvollständig und können Fehler enthalten. Um sicherzustellen, dass das Ergebnis des Data Mining genau ist, müssen die Daten zunächst bereinigt werden. Zu den Methoden der Bereinigung gehören das Ausfüllen fehlender Werte, automatische und manuelle Kontrollen usw. - Datenintegration
In dieser Phase werden Daten aus verschiedenen Quellen extrahiert, kombiniert und integriert. Quellen können Datenbanken, Textdateien, Tabellen, Dokumente, mehrdimensionale Datenarrays, das Internet usw. sein. - Datenauswahl
In der Regel sind nicht alle integrierten Daten für das Data Mining erforderlich. Die Datenauswahl ist die Phase, in der aus einer großen Datenbank nur die nützlichen Daten ausgewählt und extrahiert werden. - Datenumwandlung
Nach der Auswahl der Daten werden sie in geeignete Formate für das Data Mining umgewandelt. Dieser Prozess umfasst Normalisierung, Aggregation, Generalisierung usw. - Intelligente Datenanalyse
Hier kommt der wichtigste Teil des Data Mining ins Spiel – die Anwendung intelligenter Methoden zur Entdeckung von Mustern. Der Prozess beinhaltet Regression, Klassifikation, Prognose, Clusteranalyse, Assoziationsstudien und vieles mehr. - Modellbewertung
Diese Phase zielt darauf ab, potenziell nützliche, leicht verständliche Muster sowie Muster zu identifizieren, die Hypothesen bestätigen. - Wissen präsentieren
In der abschließenden Phase werden die gewonnenen Informationen ansprechend visualisiert unter Verwendung von Methoden zur Wissenspräsentation und Visualisierung.
Nachteile des Data Mining
- Hohe Investitionen an Zeit und Aufwand
Da die Datenextraktion ein langwieriger und komplexer Prozess ist, erfordert sie viel Arbeit von produktiven und qualifizierten Fachleuten. Experten für Datenanalyse können leistungsstarke Tools zur Datenextraktion nutzen, benötigen jedoch Fachkräfte, um die Daten vorzubereiten und die Ergebnisse zu verstehen. Daher kann die Verarbeitung aller Informationen einige Zeit in Anspruch nehmen. - Datenschutz und Datensicherheit
Da die Datenextraktion Informationen über Kunden durch Marktforschungsmethoden sammelt, kann sie die Privatsphäre der Nutzer verletzen. Darüber hinaus können Hacker auf Daten zugreifen, die in Datenextraktionssystemen gespeichert sind. Dies stellt eine Bedrohung für die Datensicherheit der Kunden dar. Wenn gestohlene Daten missbraucht werden, kann dies anderen leicht schaden.
Oben finden Sie eine kurze Einführung in die Datenextraktion. Wie bereits erwähnt, umfasst die Datenextraktion den Prozess der Sammlung und Integration von Daten, zu dem auch der Prozess der Datenextraktion selbst gehört. In diesem Fall kann man mit Sicherheit sagen, dass die Datenextraktion Teil eines langwierigen Prozesses der Datenextraktion sein kann.
Was ist Datenextraktion?
Auch bekannt als „Webdatenextraktion“ und „Web-Scraping“ bezeichnet dieser Prozess das Herausziehen von Daten aus (in der Regel unstrukturierten oder schlecht strukturierten) Datenquellen in zentralisierte Ablageorte für die Speicherung oder weitere Verarbeitung. Zu den unstrukturierten Datenquellen gehören insbesondere Webseiten, E-Mails, Dokumente, PDF-Dateien, gescannte Texte, Mainframe-Berichte, Banddateien, Anzeigen usw. Die zentralisierten Speicher können lokal, cloudbasiert oder hybrid sein. Es ist wichtig zu beachten, dass die Datenaus extraction keine Verarbeitung oder andere Analysen umfasst, die später stattfinden können.
Was kann mit Data Extraction gemacht werden?
Die Ziele der Datenaus extraction lassen sich hauptsächlich in drei Kategorien unterteilen.
- Archivierung
Die Datenaus extraction kann Daten aus physischen Formaten - Bücher, Zeitungen, Rechnungen - in digitale Formate wie Datenbanken für die Speicherung oder Sicherung umwandeln. - Datenformatänderung
Wenn Sie Daten von Ihrer aktuellen Website auf eine neue, sich in der Entwicklungsphase befindliche Website übertragen möchten, können Sie die Daten von Ihrer eigenen Website durch Extraktion sammeln. - Datenanalyse
Zusätzliche Analysen der extrahierten Daten sind weit verbreitet, um ein besseres Verständnis zu erlangen. Dies könnte ähnlich erscheinen wie Datenanalyse im Data Mining, jedoch ist die Datenanalyse das Ziel der Extraktion und nicht Teil davon. Darüber hinaus erfolgt die Datenanalyse auf eine andere Weise. Ein Beispiel dafür ist, dass Betreiber von Online-Shops Informationen über Produkte von E-Commerce-Websites wie Amazon extrahieren, um die Wettbewerbstrategien in Echtzeit zu überwachen. Wie beim Data Mining ist auch die Datenauswertung ein automatisierter Prozess mit vielen Vorteilen. Früher mussten Menschen Daten manuell von einem Ort zum anderen kopieren und einfügen, was sehr zeitaufwendig war. Die Datenauswertung beschleunigt die Erfassung und erhöht erheblich die Genauigkeit der extrahierten Daten.
Einige Anwendungsbeispiele für die Datenauswertung
Ähnlich wie Data Mining wird die Datenextraktion in verschiedenen Branchen weit verbreitet eingesetzt. Neben der Preisüberwachung im E-Commerce kann die Datenextraktion auch bei der Eigenforschung, Nachrichtenaggregation, Marketing, in der Immobilienbranche, im Reise- und Tourismussektor, in der Beratung, im Finanzwesen und vielen weiteren Bereichen helfen.
- Lead-Generierung
Unternehmen können Daten aus Verzeichnissen wie Yelp, Crunchbase, Yellowpages extrahieren und Leads zur Geschäftsentwicklung generieren. Sehen Sie sich das Video unten an, um zu erfahren, wie Sie Daten aus Yellowpages mit Hilfe von . - Inhalts- und Nachrichtenaggregation
Aggregierende Content-Websites können regelmäßige Datenströme aus mehreren Quellen erhalten und ihre Seiten aktuell halten. - Sentiment-Analyse
Nach der Extraktion von Bewertungen, Kommentaren und Feedback aus sozialen Medien wie Instagram und Twitter können Fachkräfte die zugrunde liegenden Ansichten analysieren und Einblicke gewinnen, wie eine Marke, ein Produkt oder ein Phänomen wahrgenommen wird.
Schritte zur Datenextraktion
Die Datenextraktion ist der erste Schritt in ETL (Extract, Transform, Load: Extrahieren, Transformieren, Laden) und ELT (Extrahieren, Laden und Transformieren). ETL und ELT sind wesentliche Bestandteile einer umfassenden Datenintegrationsstrategie. Mit anderen Worten, die Datenextraktion kann Teil des Datenabbaus sein.
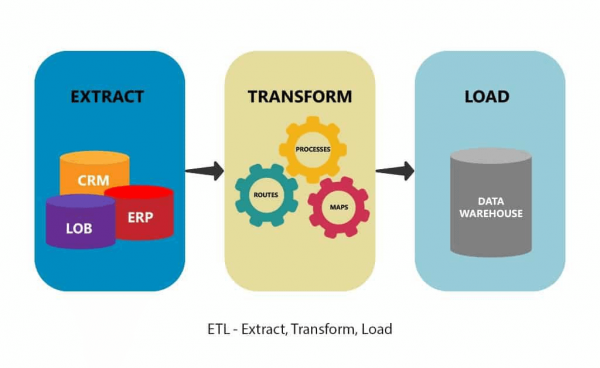
Extrahieren, Transformieren, Laden
Während das Data Mining die Beschaffung von Informationen aus großen Datenmengen umfasst, ist die Datenextraktion ein deutlich kürzerer und einfacherer Prozess. Er lässt sich auf drei Schritte reduzieren:
- Datenquelle auswählen
Wählen Sie die Quelle aus, aus der Sie Daten extrahieren möchten, zum Beispiel eine Website. - Daten sammeln
Schicken Sie eine "GET"-Anfrage an die Website und analysieren Sie das zurückgegebene HTML-Dokument mit Programmiersprachen wie Python, PHP, R, Ruby usw. - Datenspeicherung
Speichern Sie die Daten in Ihrer lokalen Datenbank oder in einer Cloud-Speicherung für zukünftige Verwendung. Wenn Sie ein erfahrener Programmierer sind, erscheinen Ihnen die oben genannten Schritte möglicherweise einfach. Wenn Sie jedoch nicht programmieren, gibt es einen schnelleren Weg — verwenden Sie Datenextraktionstools, wie zum Beispiel . Datenextraktionstools, ebenso wie Data-Mining-Tools, sind darauf ausgelegt, Energie zu sparen und die Datenverarbeitung für alle zu vereinfachen. Diese Tools sind nicht nur kosteneffektiv, sondern auch anfängerfreundlich. Sie ermöglichen es den Nutzern, Daten innerhalb weniger Minuten zu sammeln, sie in der Cloud zu speichern und in viele Formate zu exportieren: Excel, CSV, HTML, JSON oder in Datenbanken über API.
Nachteile der Datenextraktion
- Serverausfall
Bei der Datenextraktion in großem Maßstab kann der Webserver der Zielseite überlastet werden, was zu einem Serverausfall führen kann. Dies schadet den Interessen des Webseiteninhabers. - IP-Sperre
Wenn eine Person zu häufig Daten sammelt, können Websites ihre IP-Adresse sperren. Die Ressource kann die IP-Adresse vollständig blockieren oder den Zugriff einschränken, wodurch die Daten unvollständig werden. Um Daten zu extrahieren und eine Sperre zu vermeiden, sollte dies mit moderater Geschwindigkeit und unter Anwendung einiger Anti-Blockierungsmethoden erfolgen. - Rechtsprobleme
Das Extrahieren von Daten aus dem Web bewegt sich in einer Grauzone, was die Legalität betrifft. Große Seiten wie LinkedIn und Facebook geben in ihren Nutzungsbedingungen klar an, dass jede automatische Datenerhebung verboten ist. Zwischen diesen Unternehmen gab es zahlreiche Klagen aufgrund von Bot-Aktivitäten.
Die wichtigsten Unterschiede zwischen Data Mining und Data Extraction
- Data Mining wird auch als Wissenserkennung in Datenbanken, Wissensextraktion, Daten-/Musteranalyse, Informationssammlung bezeichnet. Data Extraction wird synonym verwendet mit Web-Datenextraktion, Web-Crawling, Datensammlung und so weiter.
- Forschungen im Bereich Data Mining basieren hauptsächlich auf strukturierten Daten, während bei der Datenextraktion diese meist aus unstrukturierten oder schlecht strukturierten Quellen stammen.
- Ziel des Data Mining ist es, Daten für die Analyse nützlicher zu machen. Data Extraction hingegen ist das Sammeln von Daten an einem Ort, wo sie gespeichert oder verarbeitet werden können.
- Die Analyse beim Data Mining basiert auf mathematischen Methoden zur Identifizierung von Mustern oder Trends. Data Extraction beruht auf Programmiersprachen oder Tools zur Datenextraktion, die nutzt werden, um Quellen zu durchforsten.
- Ziel des Data Mining ist es, Fakten zu finden, die zuvor unbekannt oder ignoriert wurden, während sich die Data Extraction mit vorhandenen Informationen befasst.
- Data Mining ist komplexer und erfordert größere Investitionen in die Schulung von Personen. Data Extraction kann mit dem richtigen Werkzeug äußerst einfach und kosteneffizient sein.
Wir helfen Anfängern, sich im Datenverkehr nicht zu verlieren. Speziell für die Habr-Gemeinschaft haben wir einen Promo-Code erstellt HABR, der zusätzliche 10% Rabatt auf den im Banner angegebenen Rabatt gewährt.
Weitere Kurse
Empfohlene Artikel
Quelle: habr.com
