

Vor einigen Tagen fand die statt. Die Leute von JUG.ru Group hatten Traumsprecher eingeladen (Leslie Lamport! Cliff Click! Martin Kleppmann!) und widmeten zwei Tage den Themen verteilte Systeme und Berechnungen. Kontur war einer der drei Partner der Konferenz. Wir hatten am Stand Gespräche, erzählten von unseren verteilten Speicherlösungen, spielten Bingo und lösten Aufgaben.
Dieser Beitrag ist eine Analyse der Aufgaben am Kontur-Stand, verfasst von einem der Autoren. Wer bei Hydra war, hat einen Grund, schöne Erinnerungen wachzurufen. Wer nicht da war, hat die Chance, seine grauen Zellen zu aktivieren. big O-Notation.
Es gab sogar Teilnehmer, die das Flipchart in Folien zerlegten, um ihre Lösung aufzuschreiben. Ich mache keinen Scherz — sie haben ein solches Stapel Papier zur Überprüfung abgegeben:

Es gab insgesamt drei Aufgaben:
- zum Wählen von Replikaten nach Gewicht zur Lastenverteilung
- zur Sortierung der Ergebnisse einer Abfrage an einer In-Memory-Datenbank
- zur Übertragung des Zustands in einem verteilten System mit Ringtopologie
Aufgabe 1. ClusterClient
Es war erforderlich, einen Algorithmus für die effektive Auswahl von K aus N gewichteten Replikaten eines verteilten Systems vorzuschlagen:
Ihr Team hat die Aufgabe, eine Client-Bibliothek für einen massiv verteilten Cluster von N Knoten zu entwickeln. Diese Bibliothek verfolgt verschiedene Metadaten, die mit den Knoten verbunden sind (z. B. deren Latenzen, 4xx/5xx-Antwortraten usw.) und weist ihnen Fließkomma-Gewichte W1..WN zu. Um die gleichzeitige Ausführungsstrategie zu unterstützen, sollte die Bibliothek in der Lage sein, K von N Knoten zufällig auszuwählen – die Auswahlchance sollte proportional zum Gewicht eines Knotens sein.
Schlagen Sie einen Algorithmus vor, um Knoten effizient auszuwählen. Schätzen Sie die rechnerische Komplexität mit der Big-O-Notation.
Warum ist alles auf Englisch?
Weil in dieser Form die Teilnehmer der Konferenz damit konfrontiert wurden und weil Englisch die offizielle Sprache von Hydra war. So sahen die Aufgabenstellungen aus:

Nehmen Sie Papier und Stift, denken Sie nach, eilen Sie nicht sofort zu den Spoilern 🙂
Lösungsanalyse (Video)
Beginn um 5:53, insgesamt 4 Minuten:

So haben die Jungs mit dem Flipchart ihre Lösung präsentiert:

Lösungsanalyse (Text)
Eine mögliche Lösung besteht darin, die Gewichte aller Replikate zu summieren, eine Zufallszahl zwischen 0 und der Summe aller Gewichte zu generieren und dann das i-te Replikat auszuwählen, sodass die Summe der Gewichte der Replikate von 0 bis (i-1) kleiner ist als die Zufallszahl, während die Summe der Gewichte von 0 bis i größer ist. Auf diese Weise kann ein Replikat ausgewählt werden. Um das nächste auszuwählen, muss das gesamte Verfahren wiederholt werden, ohne das gewählte Replikat zu berücksichtigen. Bei diesem Algorithmus beträgt die Komplexität der Auswahl eines Replikats O(N), während die Komplexität für die Auswahl von K Replikaten O(N·K) ~ O(N²) beträgt.
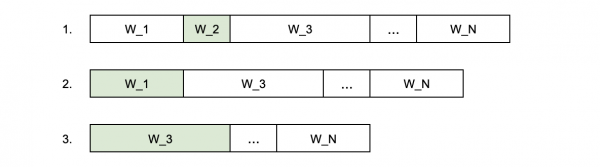
Eine quadratische Komplexität ist problematisch, doch sie lässt sich verbessern. Dafür bauen wir für die Gewichtsummen. Es entsteht ein Baum mit einer Tiefe von lg N, dessen Blätter die Gewichte der Replikate darstellen, während die anderen Knoten die Teilsummen bis zur Gesamtsumme aller Gewichte im Wurzelknoten enthalten. Anschließend generieren wir eine Zufallszahl von 0 bis zur Gesamtsumme der Gewichte, finden das i-te Replikat, entfernen es aus dem Baum und wiederholen das Verfahren, um die verbleibenden Replikate zu suchen. Mit diesem Algorithmus wird die Komplexität zum Erstellen des Baums O(N), die Komplexität zum Finden des i-ten Replikats und dessen Entfernung aus dem Baum O(lg N), und die Komplexität zur Auswahl von K Replikaten beträgt O(N + K lg N) ~ O(N lg N).
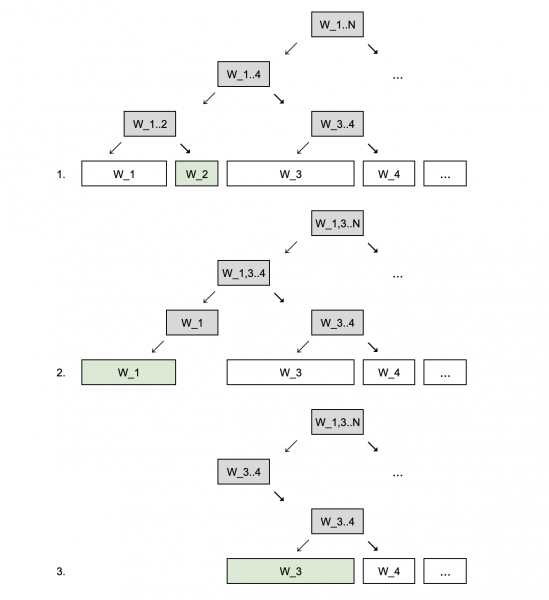
Die linear-logarithmische Komplexität ist angenehmer als die quadratische, insbesondere für große K.
Genau dieser Algorithmus der ClusterClient-Bibliothek aus dem Projekt „“. (Dort wird der Baum in O(N lg N) aufgebaut, aber dies hat keinen Einfluss auf die endgültige Komplexität des Algorithmus.)
Aufgabe 2. Zebra
Es sollte ein Algorithmus zur effizienten Sortierung von Dokumenten im Speicher nach einem beliebigen, nicht indizierten Feld vorgeschlagen werden:
Ihr Team hat die Aufgabe, eine partitionierte, im Speicher befindliche Dokumentendatenbank zu entwickeln. Eine häufige Arbeitslast wäre die Auswahl der besten N Dokumente, die nach einem beliebigen (nicht indizierten) numerischen Feld aus einer Sammlung der Größe M (normalerweise N < 100 << M) sortiert sind. Eine etwas weniger häufige Arbeitslast wäre die Auswahl der besten N, nachdem die obersten S Dokumente übersprungen wurden (S ~ N).
Schlagen Sie einen Algorithmus vor, um solche Anfragen effizient auszuführen. Schätzen Sie die Berechnungskomplexität mithilfe der großen O-Notation für den Durchschnitts- und den schlimmsten Fall.
Lösungsanalyse (Video)
Beginn bei 34:50, insgesamt 6 Minuten:
Lösungsanalyse (Text)
Die Lösung liegt auf der Hand: Alle Dokumente sortieren (zum Beispiel mit ), dann N+S Dokumente nehmen. In diesem Fall beträgt die durchschnittliche Sortierkomplexität O(M lg M), im schlimmsten Fall O(M²).
Offensichtlich ist es ineffizient, alle M Dokumente zu sortieren, nur um dann einen kleinen Teil davon zu entnehmen. Um nicht alle Dokumente zu sortieren, eignet sich der Algorithmus , der N+S benötigte Dokumente auswählt (diese können mit jedem Algorithmus sortiert werden). In diesem Fall wird die Komplexität im Durchschnitt auf O(M) reduziert, während der schlimmste Fall gleich bleibt.
Es kann jedoch noch effizienter sein – nutzen Sie den Algorithmus . In diesem Fall werden die ersten N+S Dokumente in einem Min- oder Max-Heap (je nach Sortierrichtung) abgelegt, und jedes nachfolgende Dokument wird mit der Wurzel des Baumes verglichen, wo das aktuell minimale oder maximale Dokument enthalten ist, und wird bei Bedarf in den Baum hinzugefügt. In diesem Fall ist die Komplexität im schlimmsten Fall, wenn der Baum ständig neu aufgebaut werden muss – O(M lg M), die durchschnittliche Komplexität bleibt bei O(M), wie beim Einsatz von Quickselect.
Heap Streaming erweist sich jedoch als effizienter, da in der Praxis die meisten Dokumente verworfen werden können, ohne den Heap neu zu strukturieren, nach einem einzigen Vergleich mit dessen Wurzelelement. Diese Sortierung ist in der dokumentenbasierten In-Memory-Datenbank Zebra implementiert, die von Kontur entwickelt und genutzt wird.
Aufgabe 3. Zustandswechsel
Es sollte der effizienteste Algorithmus für Zustandsverschiebungen vorgeschlagen werden:
Ihr Team hat die Aufgabe, einen eleganten Zustandsübergmechanismus für ein verteiltes Cluster von N Knoten zu entwickeln. Der Zustand des i-ten Knotens sollte an den (i+1)-ten Knoten übertragen werden, während der Zustand des N-ten Knotens an den ersten Knoten übergeben werden soll. Die einzige unterstützte Operation ist der Zustandswechsel, bei dem zwei Knoten ihre Zustände atomar austauschen. Es ist bekannt, dass ein Zustandswechsel M Millisekunden dauert. Jeder Knoten kann zu jedem Zeitpunkt an einem einzigen Zustandswechsel teilnehmen.
Wie lange dauert es, die Zustände aller Knoten in einem Cluster zu übertragen?
Lösungsanalyse (Text)
Die Lösung auf der Oberfläche: den Zustand des ersten und zweiten Elements tauschen, dann den ersten mit dem dritten, dann mit dem vierten und so weiter. Nach jedem Tausch wird der Zustand eines Elements an der richtigen Position landen. Es müssen O(N) Vertauschungen vorgenommen werden, was O(N·M) Zeit in Anspruch nehmen wird.
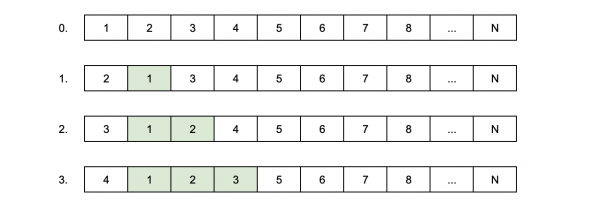
Lineare Zeit ist zu lang, daher kann man die Zustände der Elemente paarweise tauschen: den ersten mit dem zweiten, den dritten mit dem vierten und so weiter. Nach jedem Tausch wird der Zustand jedes zweiten Elements an der richtigen Position landen. Es müssen O(lg N) Vertauschungen vorgenommen werden, was O(M lg N) Zeit in Anspruch nehmen wird.
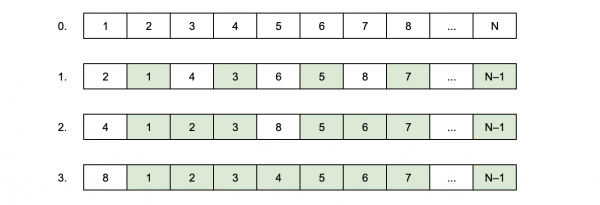
Es ist jedoch möglich, den Shift noch effizienter zu gestalten – nicht in linearer, sondern in konstanter Zeit. Dafür muss im ersten Schritt der Zustand des ersten Elements mit dem letzten, des zweiten mit dem vorletzten und so weiter getauscht werden. Der Zustand des letzten Elements befindet sich dann an der gewünschten Position. Jetzt muss der Zustand des zweiten Elements mit dem letzten, des dritten mit dem vorletzten und so weiter getauscht werden. Nach dieser Runde des Tauschens befinden sich alle Elemente an den richtigen Positionen. Insgesamt werden O(2M) ~ O(1) Tauschvorgänge durchgeführt.
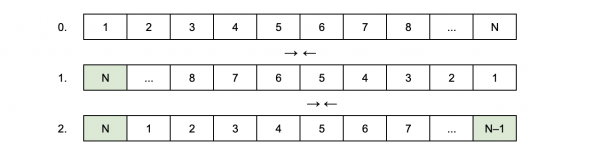
Eine solche Lösung wird einen Mathematiker, der sich noch erinnert, dass eine Drehung die Komposition zweier Achsenspiegelungen ist, nicht überraschen. Übrigens lässt sie sich trivial für einen Shift nicht nur um eine, sondern um K < N Positionen verallgemeinern. (Schreiben Sie in die Kommentare, wie genau.)
Hat Ihnen diese Aufgaben gefallen? Kennen Sie andere Lösungen? Teilen Sie sie in den Kommentaren.
Hier sind einige nützliche Links zum Schluss:
- erfahren Sie mehr über bei Kontur
- sehen Sie sich die Aufzeichnungen interner über verteilte Systeme
- sehen Sie sich die Videovortragsreihe «»
- abonnieren Sie unseren
Quelle: habr.com
