

In diesem Frühjahr fanden wir uns in einer sehr unterhaltsamen Situation wieder. Aufgrund der Pandemie wurde klar, dass wir unsere Sommerkonferenzen online abhalten mussten. Um dies jedoch qualitativ hochwertig zu gestalten, genügten uns die verfügbaren Softwarelösungen nicht, wir mussten unsere eigene schreiben. Und dafür hatten wir drei Monate Zeit.
Es ist offensichtlich, dass dies spannende drei Monate waren. Aber von außen ist es nicht ganz klar: Was genau ist eigentlich eine Plattform für Online-Konferenzen? Aus welchen Teilen setzt sie sich zusammen? Daher habe ich auf der letzten Sommerkonferenz DevOops einige Fragen an die Personen gerichtet, die für diese Aufgabe verantwortlich waren:
- Nikolai Moltschanov — Technischer Direktor der JUG Ru Group;
- Wladimir Krasilschik — pragmatischer Java-Programmierer, der sich mit Backend beschäftigt (Sie haben vielleicht auch seine Vorträge auf unseren Java-Konferenzen gesehen);
- Artem Nikonych — verantwortlich für unseren gesamten Videostreaming.
Übrigens werden wir bei den Herbst-Winter-Konferenzen eine verbesserte Version derselben Plattform verwenden — viele Hubschreiber werden also ebenfalls Nutzer sein.
Gesamtbild
— Wie war die Zusammensetzung des Teams?
Nikolai Moltschanov: Wir haben einen Analysten, einen Designer, einen Tester, drei Frontend-Entwickler und einen Backend-Entwickler. Und natürlich einen T-shaped Spezialisten!
— Wie sah der Prozess insgesamt aus?
Nikolaj: Bis Mitte März waren wir für den Online-Betrieb überhaupt nicht bereit. Am 15. März begann dann das gesamte Online-Geschäft. Wir haben einige Repositories angelegt, die grundlegende Architektur geplant, diskutiert und alles innerhalb von drei Monaten umgesetzt.
Natürlich durchliefen wir die klassischen Phasen: Planung, Architektur, Auswahl der Funktionen, Abstimmung über diese Funktionen, deren Richtlinien, Design, Entwicklung und Tests. Am 6. Juni haben wir alles live geschaltet auf . Dafür hatten wir insgesamt 90 Tage.
— Haben wir es geschafft, das zu erreichen, was wir uns vorgenommen hatten?
Nikolaj: Da wir jetzt online an der DevOops-Konferenz teilnehmen — haben wir es geschafft. Ich habe mich persönlich verpflichtet, den Kunden ein Tool zur Verfügung zu stellen, mit dem sie eine Konferenz online durchführen können.
Die Aufgabe lautete: Geben Sie uns ein Werkzeug, mit dem wir unsere Konferenzen an die Ticketinhaber übertragen können.
Die gesamte Planung war in mehrere Phasen unterteilt, und alle Funktionen (etwa 30 globale) wurden in 4 Kategorien eingeteilt:
- die wir unbedingt machen werden (ohne sie können wir nicht leben),
- die wir als nächstes angehen werden,
- die wir niemals machen werden,
- und die wir niemals, niemals machen werden.
Alle Funktionen aus den ersten beiden Kategorien haben wir umgesetzt.
— Ich weiß, dass insgesamt 600 JIRA-Tickets angelegt wurden. In drei Monaten habt ihr 13 Mikrosysteme entwickelt, und ich vermute, dass sie nicht nur in Java geschrieben sind. Ihr habt verschiedene Technologien verwendet, zwei Kubernetes-Cluster in drei Verfügbarkeitszonen eingerichtet und 5 RTMP-Streams in Amazon bereitgestellt.
Lassen Sie uns nun jede Komponente des Systems einzeln betrachten.
Streaming
— Fangen wir damit an, wenn wir bereits ein Video-Bild haben, das an verschiedene Dienste übermittelt wird. Artyom, erzähl uns, wie dieses Streaming abläuft?
Artyom Nikонов: Das Gesamtschema sieht so aus: Kamera -> unser Steuerpult -> lokaler RTMP-Server -> Amazon -> Videoplayer. Mehr dazu auf Habré im Juni geschrieben.
Es gibt grundsätzlich zwei globale Ansätze, wie man das machen kann: entweder mit Hardware oder auf Basis von Softwarelösungen. Wir haben uns für den Weg der Software entschieden, da dies bei entfernten Sprecherinnen und Sprechern einfacher ist. Nicht immer ist es möglich, ein Gerät zu einem Sprecher im Ausland zu bringen, während die Installation von Software für den Sprecher einfacher und zuverlässiger erscheint.
Im Hinblick auf die Hardware verfügen wir über eine bestimmte Anzahl von Kameras (in unseren Studios und bei entfernten Sprechern) sowie über eine Reihe von Regiepulten im Studio, die manchmal während des Live-Streams direkt unter dem Tisch repariert werden müssen.
Die Signale von diesen Geräten gelangen in Computer mit Capture-, Ein- und Ausgangskarten sowie Soundkarten. Dort werden die Signale gemischt und in Layouts zusammengestellt:

Beispiel eines Layouts mit 4 Sprechern

Beispiel eines Layouts mit 4 Sprechern
Ein kontinuierlicher Live-Stream wird mithilfe von drei Computern sichergestellt: Es gibt einen Hauptcomputer und zwei, die abwechselnd arbeiten. Der erste Computer behandelt den ersten Vortrag, der zweite — die Pause, dann der erste — den nächsten Vortrag, der zweite — die nächste Pause und so weiter. Der Hauptcomputer mischt den ersten mit dem zweiten.
So entsteht eine Art Dreieck, und im Falle eines Ausfalls eines dieser Knoten können wir schnell und ohne Qualitätsverlust weiterhin Inhalte an die Kunden liefern. Eine solche Situation hatten wir. In der ersten Woche der Konferenzen haben wir eine Maschine repariert, ein- und ausgeschaltet. Es scheint, dass die Leute mit unserer Ausfallsicherheit zufrieden sind.
Die Streams von den Computern gelangen dann auf einen lokalen Server, der zwei Aufgaben hat: die RTMP-Streams zu routen und ein Backup zu erstellen. So haben wir mehrere Aufnahmepunkte. Dann werden die Videoströme an einen Teil unseres Systems gesendet, der auf den SaaS-Diensten von Amazon basiert. Wir nutzen , S3, CloudFront.
Nikolaj: Was passiert, bevor die Videos zu den Zuschauern gelangen? Ihr müsst es doch irgendwie schneiden?
Artyom: Wir komprimieren das Video von unserer Seite, senden es zu MediaLive. Dort starten wir die Transcoder. Sie transkodieren das Video in Echtzeit in mehrere Auflösungen, damit die Leute es auf ihren Handys, über eine schlechte Internetverbindung im Ferienhaus usw. anschauen können. Dann werden diese Streams in zerteilt, so funktioniert das Protokoll . Im Frontend geben wir eine Playlist aus, die auf diese Chunks verweist.
— Verwenden wir eine Auflösung von 1080p?
Artyom: In der Breite entspricht unser 1080p-Video 1920 Pixeln, aber in der Höhe ist es etwas weniger, das Bild ist länger gestreckt — dafür gibt es spezielle Gründe.
Player
— Artyom hat beschrieben, wie das Video in die Streams gelangt, wie es auf verschiedene Playlists für unterschiedliche Bildschirmauflösungen verteilt und in Chunks unterteilt wird, bevor es im Player angezeigt wird. Kolya, erzähl jetzt, was dieser Player ist, wie er den Stream verarbeitet und warum HLS?
Nikolaj: Wir haben einen Player, den alle Teilnehmer der Konferenz beobachten.
Im Grunde ist es eine Wrapper-Bibliothek , auf der viele andere Player basieren. Aber wir benötigten eine sehr spezifische Funktionalität: die Möglichkeit, zurückzuspulen und zu markieren, an welcher Stelle sich die Person befindet, welcher Vortrag sie sich gerade ansieht. Außerdem brauchten wir eigene Layouts, Logos und alles andere, was wir integriert haben. Daher haben wir beschlossen, unsere eigene Bibliothek (eine Wrapper über HLS) zu erstellen und dies in die Website zu integrieren.
Das ist die grundlegende Funktionalität, die daher fast als erste umgesetzt wurde. Darum herum hat sich dann alles andere entwickelt.
Tatsächlich erhält der Player über die Authentifizierung vom Backend eine Playlist mit Links zu den Chunks, die mit Zeit und Qualität verknüpft sind, lädt die benötigten herunter und zeigt sie dem Benutzer an, während er dabei eine gewisse "Magie" entfaltet.
Beispiel eines Zeitplans
— Direkt im Player ist ein Button integriert, um den Zeitplan aller Vorträge anzuzeigen…
Nikolaj: Ja, wir haben sofort das Problem der Benutzernavigation angegangen. Mitte April haben wir entschieden, dass wir nicht jede unserer Konferenzen auf einer separaten Website streamen werden, sondern alles auf einer einzigen Plattform zusammenfassen. So können Inhaber eines Full Pass-Tickets frei zwischen verschiedenen Konferenzen wechseln: sowohl dem Live-Stream als auch den Aufzeichnungen vergangener Veranstaltungen.
Um es den Nutzern zu erleichtern, sich im aktuellen Stream zu bewegen und zwischen den Tracks zu wechseln, haben wir den Button "Gesamter Stream" und horizontale Karten für die Vorträge erstellt, um zwischen Tracks und Vorträgen zu wechseln. Dort gibt es Steuerungsoptionen von der Tastatur.
— Gab es technische Schwierigkeiten dabei?
Nikolaj: Es gab Probleme mit der Scroll-Leiste, auf der die Anfangspunkte der verschiedenen Vorträge markiert sind.
— Habt ihr diese Markierungen auf der Scroll-Leiste umgesetzt, bevor YouTube etwas Ähnliches gemacht hat?
Artyom: Damals war das bei ihnen noch in der Beta-Phase. Es scheint eine ziemlich komplexe Funktion zu sein, da sie diese teilweise im letzten Jahr bei Nutzern getestet haben. Jetzt ist sie endlich im Verkauf.
Nikolaj: Wir haben das tatsächlich schneller in den Verkauf gebracht. Um ganz ehrlich zu sein, hinter dieser einfachen Funktion steckt eine riesige Menge an Backend, Frontend, Berechnungen und Mathematik im Player.
Frontend
Lassen Sie uns klären, wie die Inhalte, die wir anzeigen (Berichtskarte, Sprecher, Website, Zeitplan), ins Frontend gelangen?
Wladimir Krasyllschik: Wir haben mehrere interne IT-Systeme. Es gibt ein System, in dem alle Berichte und Sprecher erfasst sind. Es gibt einen Prozess, bei dem der Redner an der Konferenz teilnimmt. Der Sprecher reicht einen Antrag ein, das System erfasst diesen, danach gibt es einen gewissen Pipeline-Prozess, durch den der Bericht erstellt wird.
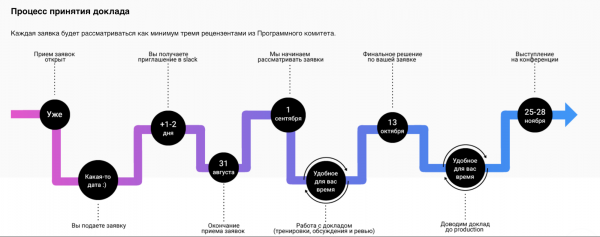
So sieht der Sprecher die Pipeline.
Dieses System ist unsere interne Entwicklung.
Aus den einzelnen Berichten muss ein Zeitplan erstellt werden. Wie bekannt ist, handelt es sich dabei um ein NP-schweres Problem, aber wir lösen es irgendwie. Dazu starten wir eine andere Komponente, die den Zeitplan erstellt und ihn in den externen Cloud-Dienst Contentful integriert. Dort erscheint alles in Form einer Tabelle, die die Konferenztage, die Zeitfenster an diesen Tagen und in den Zeitfenstern – Präsentationen, Pausen oder Sponsoraktivitäten – enthält. Der Inhalt, den wir sehen, befindet sich also in einem externen Dienst. Unsere Aufgabe ist es, diesen Inhalt auf die Website zu bringen.
Auf den ersten Blick scheint die Website lediglich eine Seite mit einem Player zu sein, und es ist nichts dabei. Außer, dass es nicht so einfach ist. Das Backend, das hinter dieser Seite steht, greift auf Contentful zu, holt dort den Zeitplan ab, erstellt einige Objekte und sendet diese an das Frontend. Über eine Websocket-Verbindung, die jeder Kunde unserer Plattform herstellt, senden wir aktualisierte Informationen zum Zeitplan vom Backend direkt an das Frontend.
Echter Fall: Der Sprecher hat während der Konferenz den Job gewechselt. Wir müssen ihm das Firmen-Label anpassen. Wie geschieht das im Backend? Über Websockets wird eine Aktualisierung an alle Clients gesendet, und dann aktualisiert das Frontend selbstständig die Timeline. Dieser Prozess läuft nahtlos ab. Die Kombination aus unserem Cloud-Service und mehreren Komponenten ermöglicht es uns, all diese Inhalte zu erstellen und dem Frontend zur Verfügung zu stellen.
Nikolaj: Hier ist es wichtig zu klären, dass unsere Website nicht nur eine klassische SPA-Anwendung ist. Es ist sowohl eine gerenderte als auch eine gebaute Website. Tatsächlich sieht Google diese Seite als gerendertes HTML. Das ist gut für SEO und für die Bereitstellung von Inhalten an den Benutzer. Er muss nicht auf 1,5 Megabyte JavaScript warten, um die Seite zu sehen; er sieht sofort die gerenderte Seite, und Sie spüren das jedes Mal, wenn Sie zwischen den Präsentationen wechseln. Alles geschieht in einer halben Sekunde, da die Inhalte bereits bereitgestellt und am richtigen Ort abgelegt sind.
— Lassen Sie uns die oben genannten Punkte zusammenfassen, indem wir die Technologien auflisten. Tёma hat erklärt, dass wir 5 Amazon-Streams haben, über die wir Video und Audio liefern. Dort verwenden wir Bash-Skripte, um sie zu starten und zu konfigurieren...
Artyom: Das erfolgt über die AWS-API, wo es noch viele andere technische Begleitdienste gibt. Wir haben unsere Aufgaben so aufgeteilt, dass ich Inhalte aufliefern kann an , während Frontend- und Backend-Entwickler diese abholen. Wir verfügen über einige eigene Anbindungen zur Vereinfachung der Bereitstellung von Inhalten, die wir später in 4K erstellen usw. Aufgrund der engen Zeitvorgaben haben wir praktisch alles auf Basis von AWS realisiert.
— Anschließend gelangt alles in den Player über das Backend-System. Unser Player nutzt TypeScript, React, Next.js. Und im Backend haben wir mehrere Dienste in C#, Java, Spring Boot und Node.js. Alles wird mithilfe von Kubernetes bereitgestellt, unter Verwendung der Infrastruktur von Yandex.Cloud.
Ich möchte außerdem anmerken, dass es mir, als ich mich mit der Plattform vertraut machen musste, nicht schwer fiel: Alle Repositories sind auf GitLab, alles ist gut benannt, es gibt Tests und Dokumentation. Das heißt, selbst im Intensivbetrieb wurde auf solche Aspekte geachtet.
Geschäftsrestriktionen und Analytik
— Wir haben uns auf die geschäftlichen Anforderungen von 10.000 Nutzern konzentriert. Nun ist es an der Zeit, über die geschäftlichen Einschränkungen zu sprechen, mit denen wir konfrontiert waren. Wir mussten eine hohe Last garantieren und die Einhaltung des Datenschutzgesetzes sicherstellen. Was gab es noch?
Nikolaj: Ursprünglich basierten wir auf den Anforderungen an das Video. Das Wichtigste war die verteilte Speicherung von Videos weltweit für eine schnelle Bereitstellung an den Kunden. Weitere Anforderungen waren eine 1080p Auflösung und die Möglichkeit, zurückzuspulen, was viele andere Anbieter im Live-Modus nicht implementiert haben. Später fügten wir die Funktion hinzu, die Wiedergabegeschwindigkeit auf 2x zu erhöhen, mit der man "aufschließen" und die Konferenz in Echtzeit weiterverfolgen kann. Außerdem entwickelte sich währenddessen eine Funktionalität zur Zeitachsenmarkierung. Darüber hinaus mussten wir ausfallsicher sein und eine Last von 10.000 Verbindungen bewältigen. Betrachtet man den Backend-Bereich, bedeutet das etwa 10.000 Verbindungen multipliziert mit 8 Anfragen bei jedem Seiten-Refresh. Das sind bereits 80.000 RPS/Sekunde. Eine erhebliche Menge.
— Gab es auch Anforderungen an eine "virtuelle Ausstellung" mit Online-Ständen der Partner?
Nikolaj: Ja, das musste ziemlich schnell und universell erledigt werden. Wir hatten bis zu 10 Partnerunternehmen für jede Konferenz, und deren Seiten mussten innerhalb einer Woche oder zwei gestaltet werden. Dabei unterscheidet sich der Inhalt etwas im Format. Es wurde jedoch ein bestimmter Template-Generator erstellt, der diese Seiten in Echtzeit zusammenstellt, praktisch ohne weitere Entwicklungsbeteiligung.
— Es gab auch Anforderungen an die Echtzeit-Analyse der Ansichten und Statistiken. Ich weiß, dass wir dafür Prometheus verwenden. Können Sie genauer erzählen, welche Anforderungen wir in Bezug auf die Analyse erfüllen und wie dies umgesetzt wird?
Nikolaj: Ursprünglich hatten wir marketingtechnische Anforderungen an die Datenerhebung für A/B-Tests und zur Informationssammlung, um zu verstehen, wie wir dem Kunden zukünftig die besten Inhalte liefern können. Es gibt auch Anforderungen für bestimmte Analysen zu Partneraktivitäten und die Analysen, die Sie sehen (Besucherzähler). Alle Informationen werden in Echtzeit gesammelt.
Diese Informationen können wir sogar in aggregierter Form bereitstellen, z. B. wie viele Menschen dich zu einem bestimmten Zeitpunkt angesehen haben. Dabei werden jedoch zur Einhaltung des Gesetzes Nr. 152 die persönlichen Daten und der Zugang zum persönlichen Bereich nicht verfolgt.
Die Plattform verfügt bereits über Marketinginstrumente sowie unsere Metriken zur Messung der Benutzeraktivität in Echtzeit (wer zu welchem Zeitpunkt die Präsentation angesehen hat), um Besuchsgrafiken zu erstellen. Diese Daten werden für Forschungen genutzt, die helfen, zukünftige Konferenzen zu verbessern.
Betrug
— Haben wir Anti-Betrugs-Mechanismen?
Nikolaj: Aufgrund der strengen zeitlichen Vorgaben wurde von Anfang an nicht die Strategie verfolgt, unnötige Verbindungen sofort zu blockieren. Wenn zwei Benutzer dasselbe Konto verwendeten, konnten sie den Inhalt ansehen. Aber wir wissen, wie viele gleichzeitige Ansichten von einem Konto aus stattfanden. Einige besonders hartnäckige Übeltäter wurden gesperrt.
Wladimir: Man muss sagen, einer der gesperrten Benutzer hat verstanden, warum das passiert ist. Er kam, entschuldigte sich und versprach, ein Ticket zu kaufen.
— Damit dies alles funktioniert, müssen Sie alle Nutzer vom Eintritt bis zum Austritt vollständig nachverfolgen und immer wissen, was sie tun. Wie funktioniert dieses System?
Wladimir: Ich möchte über die Analytik und die Statistiken sprechen, die wir dann analysieren, um den Erfolg des Vortrags zu bewerten oder die wir später unseren Partnern bereitstellen können. Alle Kunden sind über eine WebSocket-Verbindung mit einem bestimmten Backend-Cluster verbunden. Dort steht . Jeder Kunde sendet in regelmäßigen Abständen Informationen darüber, was er tut und welchen Track er sich ansieht. Diese Informationen werden dann zügig durch Hazelcast-Jobs aggregiert und an alle zurückgesendet, die diese Tracks gerade ansehen. Wir sehen in der Ecke, wie viele Menschen gerade mit uns zusammen sind.

Diese Informationen werden auch in gespeichert und wandern in unser Datenspeicher, aus dem wir interessantere Diagramme erstellen können. Es stellt sich die Frage: Wie viele einzigartige Nutzer haben diesen Vortrag gesehen? Wir gehen zu , wo die Pings aller Personen, die über die ID dieses Vortrags gekommen sind, gesammelt werden. Wir aggregieren die einzigartigen Nutzer und können jetzt verstehen.
Nikolaj: Aber gleichzeitig erhalten wir auch Echtzeitdaten von Prometheus. Er ist auf alle Kubernetes-Dienste und Kubernetes selbst eingestellt. Er sammelt alles, und mit Grafana können wir in Echtzeit beliebige Diagramme erstellen.
Wladimir: Einerseits laden wir das für die weitere Verarbeitung im OLAP-Stil hoch. Das OLTP-Anwendungssystem lädt all dies in Prometheus, Grafana, und die Diagramme stimmen sogar überein!
— Das ist der Fall, bei dem die Diagramme übereinstimmen.
Dynamische Änderungen
— Erzählen Sie, wie dynamische Änderungen ausgerollt werden: Wenn ein Vortrag 6 Minuten vor Beginn abgesagt wird, welche Handlungsfolge gibt es? Welcher Pipeline wird aktiviert?
Wladimir: Die Pipeline ist sehr bedingt. Es gibt mehrere Möglichkeiten. Die erste ist, dass das Programm zur Planung des Zeitplans aktiviert wird und diesen ändert. Der geänderte Zeitplan wird in Contentful hochgeladen. Danach versteht das Backend, dass es Änderungen zu dieser Konferenz in Contentful gibt, übernimmt das und baut neu auf. Alles wird zusammengestellt und über Websocket gesendet.
Die zweite Möglichkeit ist, wenn alles ganz schnell abläuft: Der Redakteur ändert die Informationen in Contentful manuell (den Link zu Telegram, die Präsentation des Referenten usw.) und dieselbe Logik wird aktiviert wie beim ersten Mal.
Nikolaj: Alles geschieht ohne ein Neuladen der Seite. Alle Änderungen erfolgen nahtlos für den Kunden. Das gilt auch für den Wechsel der Vorträge. Wenn die Zeit gekommen ist, ändert sich der Vortrag und das Interface.
Wladimir: Ebenso die Zeitmarken für den Beginn der Vorträge in der Timeline. Am Anfang ist nichts vorhanden. Wenn man mit der Maus über den roten Balken fährt, erscheinen zu einem bestimmten Zeitpunkt, dank des Regisseurs der Übertragung, die Zeitmarken. Der Regisseur setzt den richtigen Beginn der Übertragung, das Backend erfasst diese Änderung, berechnet entsprechend dem Zeitplan der Konferenz die Start- und Endzeit der Vorträge und sendet diese an unsere Kunden, die das Interface zeichnen. Jetzt kann der Nutzer problemlos zu Beginn und Ende des Vortrags navigieren. Das war eine wichtige Geschäftsanforderung, sehr praktisch und nützlich. Man spart Zeit, um den genauen Beginn des Vortrags zu finden. Wenn wir die Vorschau erstellen, wird es wirklich großartig sein.
Deployment
— Ich würde gerne etwas zum Deployment fragen. Kolja und das Team haben zu Beginn viel Zeit damit verbracht, die gesamte Infrastruktur einzurichten, in der alles bereitgestellt wird. Erzähl mir, aus welchen Komponenten besteht das alles?
Nikolaj: Zu Beginn hatten wir die Anforderung, das Produkt technisch so weit wie möglich von einem bestimmten Anbieter zu abstrahieren. Es passte nicht wirklich, spezifische Terraform-Skripte für AWS, Yandex oder Azure zu erstellen. Wir mussten damals woanders hinziehen.
In den ersten drei Wochen suchten wir ständig einen Weg, wie wir es am besten umsetzen können. Letztendlich haben wir festgestellt, dass Kubernetes in diesem Fall unsere beste Lösung ist, da es automatisch skalierbare Dienste sowie Rollouts ermöglicht und fast alle Dienste sofort verfügbar sind. Natürlich mussten wir alle Dienste auf die Arbeit mit Kubernetes und Docker schulen, und das Team musste ebenfalls lernen.
Wir haben zwei Cluster: einen Test- und einen Produktionscluster. Diese sind hinsichtlich Hardware und Einstellungen völlig identisch. Wir implementieren Infrastruktur als Code. Alle Dienste werden über automatisierte Pipelines in drei Umgebungen aus Feature-Branches, aus Master-Branches und aus Test-Branches aus GitLab bereitgestellt. Das ist maximal in GitLab integriert und arbeitet nahtlos mit Elastic und Prometheus zusammen.
Wir können schnell Änderungen in jede Umgebung ausrollen (Backend innerhalb von 10 Minuten, Frontend innerhalb von 5 Minuten) mit allen Tests, Integrationen, dem Start funktionaler Tests sowie Integrationstests in der Testumgebung. Außerdem testen wir Belastungstests, um sicherzustellen, dass wir im Produktionsumfeld das Gleiche erhalten.
Zu den Tests
— Sie testen fast alles, es ist schwer zu glauben, wie gründlich Sie das umgesetzt haben. Können Sie etwas über die Tests im Backend erzählen: Wie umfassend ist die Abdeckung, welche Tests werden durchgeführt?
Wladimir: Es gibt zwei Arten von Tests. Die ersten sind Kompontententests. Tests der gesamten Spring-Anwendung und Datenbank in . Dies prüft die hochgradig geschäftskritischen Szenarien. Ich teste keine Funktionen, sondern konzentriere mich nur auf größere Abläufe. Beispielsweise wird im Test der Login-Prozess eines Benutzers emuliert, einschließlich der Abfrage von Tickets, die er erwerben kann, sowie des Zugriffs auf Streaming-Inhalte. Sehr nachvollziehbare Benutzer-Szenarien.
Ähnliches wird in sogenannten Integrationstests umgesetzt, die tatsächlich in der Umgebung laufen. Wenn ein neuer Deployment in die Produktion erfolgt, werden in der Produktion auch echte Basisszenarien ausgeführt. Das umfasst den gleichen Login, Ticketanfragen, Zugriffsanforderungen an CloudFront, sowie die Überprüfung, ob der Stream tatsächlich mit meinen Berechtigungen verbunden ist, und die Prüfung der Regieoberfläche.
Aktuell habe ich etwa 70 Komponententests und rund 40 Integrationstests im Einsatz. Die Abdeckung liegt sehr nahe bei 95 %. Bei den Komponententests, bei den Integrationstests ist es etwas weniger, da dort einfach nicht so viele notwendig sind. Angesichts der Codegenerierung im Projekt ist das ein sehr guter Wert. Es gab keinen anderen Weg, um das, was wir in drei Monaten erreicht haben, zu realisieren. Hätten wir manuell getestet und die Funktionen an unsere Testerin übergeben, während sie Fehler gefunden und uns zur Behebung zurückgeschickt hätte, wäre dieser gesamte Prozess des Code-Debuggings sehr lange gedauert und wir hätten keine Fristen einhalten können.
Nikolaj: Um eine Regression auf der gesamten Plattform bei einer Änderung einer Funktion durchzuführen, müsste man zwei Tage lang überall herumklicken.
Wladimir: Es ist also ein großer Erfolg, dass, wenn ich eine Funktion schätze, ich sage, dass ich 4 Tage für zwei einfache Features und 1 Websocket brauche, Kola zustimmt. Er ist bereits daran gewöhnt, dass in diesen 4 Tagen 2 Arten von Tests eingeplant sind und es wahrscheinlich danach funktionieren wird.
Nikolaj: Ich habe auch 140 Tests geschrieben: Komponenten- und Funktionstests, die dasselbe tun. Alle Szenarien werden sowohl in der Produktion, im Test als auch in der Entwicklung getestet. Außerdem haben wir kürzlich grundlegende UI-Funktionstests eingeführt. Damit decken wir die grundlegendsten Funktionen ab, die fehleranfällig sein könnten.
Wladimir: Natürlich sollte ich über Lasttests sprechen. Wir mussten die Plattform unter einer nahezu realistischen Last testen, um zu verstehen, was mit Rabbit und den JVMs passiert und wie viel Speicher tatsächlich benötigt wird.
— Ich weiß nicht genau, ob wir etwas auf der Streaming-Seite testen, aber ich erinnere mich, dass es Probleme mit den Transcodern gab, als wir Meetups gemacht haben. Haben wir die Streams getestet?
Artyom: Wir haben iterativ getestet und Meetups organisiert. Bei der Organisation der Meetups gab es etwa 2300 JIRA-Tickets. Das waren lediglich Standardaufgaben, die das Team erledigt hat, um die Meetups durchzuführen. Wir haben Teile der Plattform auf eine separate Seite für die Meetups übertragen, um die sich Kirill Tolkatschew kümmerte.).
Um ehrlich zu sein, gab es keine größeren Probleme. Nur ein paar Mal hatten wir Fehler mit dem Caching in CloudFront, die wir relativ schnell beheben konnten — wir haben einfach die Richtlinien neu konfiguriert. Die meisten Fehler traten jedoch aufgrund menschlicher Faktoren in den Streaming-Systemen auf der Plattform auf.
Während der Konferenzen mussten wir mehrere Exporteure schreiben, um mehr Hardware und Dienstleistungen abzudecken. Manchmal mussten wir unsere eigenen Lösungen nur für die Metriken entwickeln. Die Welt der AV (Audio-Video) Hardware ist nicht gerade rosig — du hast irgendeine „API“ von Geräten, auf die du keinen Einfluss nehmen kannst. Und es ist alles andere als sicher, dass du die Informationen bekommst, die du benötigst. Hardware-Anbieter sind wirklich langsam, und es ist nahezu unmöglich, das Gewünschte von ihnen zu bekommen. Insgesamt über 100 Geräte, sie liefern nicht, was du brauchst, und du schreibst seltsame und überflüssige Exporteure, mit denen man das System zumindest irgendwie debuggen kann.
Ausrüstung
— Ich erinnere mich, wie wir vor Beginn der Konferenzen teilweise weiteres Equipment angeschafft haben.
Artyom: Wir haben Computer, Laptops und Akkublock-Einheiten gekauft. Momentan können wir 40 Minuten ohne Strom überbrücken. Im Juni gab es starke Gewitter in St. Petersburg — so hatten wir tatsächlich einen Stromausfall. Gleichzeitig kommen mehrere Anbieter mit Glasfaserverbindungen aus verschiedenen Punkten zu uns. Das waren wirklich 40 Minuten Downtime des Gebäudes, währenddessen das Licht brennt, der Ton und die Kameras funktionieren usw.
— Mit dem Internet haben wir eine ähnliche Geschichte. Im Büro, in dem sich unsere Studios befinden, haben wir eine robuste Netzwerkverbindung zwischen den Etagen gezogen.
Artyom: Wir haben 20 GBit Glasfaser zwischen den Etagen. Auf den Etagen haben wir teilweise Glasfaser, teilweise nicht, aber es gibt auf jeden Fall weniger als Gigabit-Verbindungen – wir nutzen diese, um zwischen den Tracks der Konferenz Videos zu übertragen. Es ist sehr praktisch, mit unserer eigenen Infrastruktur zu arbeiten; bei Offline-Konferenzen gelingt das so selten.
— Noch bevor ich bei der JUG Ru Group arbeitete, sah ich, wie über Nacht Hardware für Offline-Konferenzen aufgestellt wird, wo ein großer Monitor mit allen Metriken, die Sie in Grafana visualisieren, zu sehen ist. Jetzt haben wir auch einen Hauptsitz, in dem das Entwicklungsteam sitzt, das während der Konferenz Bugs behebt und neue Features entwickelt. Zudem gibt es ein Überwachungssystem, das auf einen großen Bildschirm projiziert wird. Artem, Kolya und andere Kollegen sitzen und passen darauf auf, dass alles stabil läuft und gut funktioniert.
Kuriositäten und Probleme
— Sie haben gut erklärt, dass wir Streaming mit Amazon haben, es gibt einen Web-Player, alles ist in verschiedenen Programmiersprachen geschrieben, es wird Redundanz gewährleistet und andere geschäftliche Anforderungen werden erfüllt. Zudem gibt es ein Kundenportal, das für juristische und natürliche Personen unterstützt wird, und wir können uns über OAuth 2.0 integrieren. Es gibt Anti-Fraud-Maßnahmen und Benutzersperrungen. Wir können Änderungen dynamisch ausrollen, weil wir das gut gemacht haben, und gleichzeitig wird alles getestet.
Ich würde gern mehr darüber erfahren, welche Kuriositäten auftraten, als etwas gestartet werden sollte. Gab es seltsame Situationen, als Sie das Backend oder Frontend entwickelt haben, und es kam zu einem Chaos, bei dem Sie nicht wussten, was zu tun ist?
Wladimir: Ich glaube, das passierte nur in den letzten drei Monaten. Jeden Tag. Wie Sie sehen können, sind mir alle Haare ausgegangen.

Wladimir Krasilshchik nach 3 Monaten, in denen es zu einem Chaos kam und niemand wusste, was zu tun ist.
Jeden Tag gab es solche Momente, in denen man sich die Haare raufen oder erkennen musste, dass man allein ist und niemand sonst helfen kann. Unser erstes großes Event war TechTrain. Am 6. Juni um 2 Uhr morgens war unsere Produktionsumgebung noch nicht eingerichtet, das machte Kolya. Und das Benutzerkonto funktionierte nicht, genauso wenig wie der Authentifizierungsserver über OAuth 2.0. Wir verwandelten es in einen OAuth 2.0-Anbieter, um es mit der Plattform zu verbinden. Ich arbeitete wahrscheinlich bereits 18 Stunden am Stück, starrte auf den Bildschirm und sah nichts, verstand nicht, warum es nicht funktionierte, während Kolya aus der Ferne meinen Code überprüfte, nach einem Bug in der Spring-Konfiguration suchte, ihn fand, und das Benutzerkonto auch in der Produktion funktionierte.
Nikolaj: Eine Stunde vor dem Release fand TechTrain statt.
Hier haben sich viele Sterne zusammengefügt. Wir hatten extrem viel Glück, denn wir hatten einfach ein großartiges Team, und alle waren von der Idee begeistert, online zu gehen. Die ganze Zeit über, in diesen drei Monaten, ließ uns der Gedanke, dass wir „YouTube machen“, nicht los. Ich erlaubte mir nicht, die Haare zu raufen, sondern sagte allen, dass alles klappen würde, denn tatsächlich war alles schon lange durchdacht.
Zur Leistung
— Können Sie sagen, wie viele Personen maximal gleichzeitig auf der Website waren? Gab es Leistungsprobleme?
Nikolaj: Leistungsprobleme, wie bereits erwähnt, gab es keine. Die maximale Anzahl an Personen, die an einem Vortrag teilgenommen haben, waren 1300, und das war bei Heisenbug.
— Gab es Probleme mit der lokalen Vorschau? Und ist es möglich, eine technische Beschreibung mit Diagrammen zu erstellen, wie das alles funktioniert?
Nikolaj: Wir werden später einen Artikel darüber schreiben.
Es ist sogar möglich, Streams lokal zu debuggen. Sobald die Konferenzen begannen, wurde es sogar einfacher, da es Produktions-Streams gab, die wir ständig ansehen konnten.
Wladimir: Wie ich verstehe, haben Frontend-Entwickler lokal mit Mockups gearbeitet, und da die Deploy-Zeit für den Frontend-Dev auch nicht lange ist (5 Minuten), gibt es keine Probleme mit den Zertifikaten.
— Alles wird getestet, debugged, sogar lokal. Also werden wir einen Artikel mit allen technischen Details schreiben, zeigen und alles mit Diagrammen erklären, wie es gemacht wurde.
Wladimir: Sie werden es übernehmen und wiederholen können.
— In 3 Monaten.
Zusammenfassung
— Alles, was beschrieben wurde, klingt großartig, wenn man bedenkt, dass es von einem kleinen Team in drei Monaten umgesetzt wurde.
Nikolaj: Ein großes Team hätte das nicht geschafft. Aber eine kleine Gruppe von Menschen, die eng und gut miteinander kommunizieren und sich einigen können, könnte es tun. Sie haben keine Widersprüche, die Architektur wurde in zwei Tagen entworfen, finalisiert und hat sich im Wesentlichen nicht verändert. Es gibt eine sehr strenge Strukturierung der eingehenden Geschäftsanforderungen in Bezug auf das Anhäufen von Funktionsanfragen und Änderungen.
— Was stand auf Ihrer Liste der nächsten Aufgaben, nachdem die Sommerkonferenzen bereits stattgefunden haben?
Nikolaj: Zum Beispiel die Untertitel. Laufende Texte im Video, Pop-ups an bestimmten Stellen des Videos, abhängig vom gezeigten Inhalt. Wenn der Redner beispielsweise eine Frage an das Publikum stellen möchte, erscheint eine Umfrage auf dem Bildschirm, die anschließend an ihn zurückgesendet wird, basierend auf den Ergebnissen der Abstimmung. Eine Art soziale Aktivität in Form von Likes, Herzchen und Bewertungen während der Präsentation selbst, sodass man in der richtigen Sekunde Feedback geben kann, ohne später auf Rückmeldeformulare abzulenken. So dachte ich ursprünglich.
Zusätzlich zu der gesamten Plattform, abgesehen von Streaming und Konferenzen, gibt es auch den Zustand nach der Konferenz. Dazu gehören Playlists (einschließlich benutzerdefinierter), möglicherweise Inhalte von über vergangenen Konferenzen, integriert, markiert und für die Benutzer zugänglich sowie auf unserer Website sichtbar.).
— Vielen Dank für eure Antworten!
Falls unter den Lesern jemand auf unseren Sommerkonferenzen war — teilt eure Eindrücke vom Player und der Übertragung. Was war angenehm, was hat genervt, was wünscht ihr euch für die Zukunft?
Wenn die Plattform euer Interesse geweckt hat und ihr sie "in Aktion" sehen wollt — wir setzen sie wieder ein bei unseren . Es gibt eine ganze Reihe davon, sodass sicher eine passende für euch dabei ist.
Quelle: habr.com
